






目录
一、背景
当代,人们的时间越来越碎片化。为了了解书籍的质量和大众的喜好,选择优质且受大众推捧的书籍,我们借助了爬虫工具爬取了豆瓣读书网站的1000本书籍,运用bs4模块中的BeautifulSoup方法进行了数据的初步过滤并且将数据存入csv文件和数据库中,而且还借助了腾讯的cos服务存入云服务器,然后采用pandas模块读入csv文件进行数据分析,得到评价人数由高到低基础上评分由高到低的top50,最后采用pyecharts进行数据的可视化
二、实验步骤
1、采集数据
这里将使用python中的requests模块中的get方法,对url中的数据进行下载,本地进行过滤分析。这部分代码经常使用,可以尝试封装
import time
import requests
def download(url) -> str:
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0"
}
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
time.sleep(1)
return response.text其中的hearders字段为了避免以代理为判断的反爬虫机制,可以认为指定用户代理
2、数据过滤
根据需要的字段,分析网页代码,过滤出需要的数据信息,这里过滤出来的是书名、评分、评价人数
books_info = []
# 获取豆瓣读书文学tag网页数据
for i in range(50):
url = f"https://book.douban.com/tag/%E6%96%87%E5%AD%A6?start={i*20}&type=T"
html = download(url)
# 将获取到的网页数据转换为python类方便filter
bs = BeautifulSoup(html, "lxml")
book_list = bs.find_all("li", {"class": "subject-item"})
for book in book_list:
book_info = []
book_title = "".join(book.find_all("a")[1].text.strip().split())
rates = book.find("div", {"class": "star clearfix"}).find_all("span")
if len(rates) > 1:
book_rate = book.find("div", {"class": "star clearfix"}).find_all("span")[1].string
rate_nums = book.find("div", {"class": "star clearfix"}).find_all("span")[2].string.strip().strip("(").split("人")[0]
rate_nums = int(rate_nums)
else:
book_rate = None
rate_nums = 0
sql = "INSERT INTO book_info(书名, 评分, 评价人数) VALUES(:book_title, :book_rate, :rate_nums)"
con.execute(text(sql), {"book_title": book_title, "book_rate": book_rate, "rate_nums": rate_nums})
con.commit()
book_info.append(book_title)
book_info.append(book_rate)
book_info.append(rate_nums)
books_info.append(book_info)3、将数据存入csv文件
with open("books_info.csv", 'w+', newline="", encoding="utf8") as file:
writer = csv.writer(file)
writer.writerow(["书名", "评分", "评价人数"])
writer.writerows(books_info)4、将数据存入数据库
将数据存入我们的数据库,这里使用的是sqlalchemy模块
from sqlalchemy import create_engine, text
USER = "root"
HOST = "192.168.56.128"
PASSWD = "123456"
PORT = "3306"
DBNAME = "douban"
DB_URI = f"mysql+pymysql://{USER}:{PASSWD}@{HOST}:{PORT}/{DBNAME}?charset=utf8"
# 创建数据库引擎
engin = create_engine(DB_URI)
# 创建连接,相当于pymysql中的cursor
con = engin.connect()
# 创建数据表
sql = text("DROP TABLE IF EXISTS book_info")
con.execute(sql)
sql = """CREATE TABLE book_info(
书名 TEXT NOT NULL,
评分 CHAR(20),
评价人数 INT)DEFAULT CHARSET=utf8"""
con.execute(text(sql))
sql = "INSERT INTO book_info(书名, 评分, 评价人数) VALUES(:book_title, :book_rate, :rate_nums)"
con.execute(text(sql), {"book_title": book_title, "book_rate": book_rate, "rate_nums": rate_nums})
con.commit()创建数据库连接,使用数据库中的douban库,新建book_info的表。注意需要设置默认字符集为utf8,否则存入书名的时候会出现乱码。然后编写sql语句进行数据写入,注意写入数据之后要提交事务
5、将csv文件存入腾讯cos服务
使用腾讯的cos服务,需要导入官方提供的模块
from qcloud_cos import CosConfig
from qcloud_cos import CosS3Client
# 正常情况日志级别使用 INFO,需要定位时可以修改为 DEBUG,此时 SDK 会打印和服务端的通信信息
logging.basicConfig(level=logging.INFO, stream=sys.stdout)
# 1. 设置用户属性, 包括 secret_id, secret_key, region 等。Appid 已在 CosConfig 中移除,请在参数 Bucket 中带上 Appid。Bucket 由 BucketName-Appid 组成
secret_id = "使用自己的认证id" # 用户的 SecretId,建议使用子账号密钥,授权遵循最小权限指引,降低使用风险。子账号密钥获取可参见 https://cloud.tencent.com/document/product/598/37140
secret_key = "使用自己的认证密码" # 用户的 SecretKey,建议使用子账号密钥,授权遵循最小权限指引,降低使用风险。子账号密钥获取可参见 https://cloud.tencent.com/document/product/598/37140
region = 'ap-shanghai' # 替换为用户的 region,已创建桶归属的 region 可以在控制台查看,https://console.cloud.tencent.com/cos5/bucket
# COS 支持的所有 region 列表参见 https://cloud.tencent.com/document/product/436/6224
token = None # 如果使用永久密钥不需要填入 token,如果使用临时密钥需要填入,临时密钥生成和使用指引参见 https://cloud.tencent.com/document/product/436/14048
scheme = 'https' # 指定使用 http/https 协议来访问 COS,默认为 https,可不填
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, Token=token, Scheme=scheme)
client = CosS3Client(config)
bucket = '填写自己的存储桶的名字'
# 使用高级接口上传一次,不重试,此时没有使用断点续传的功能
# 将生成的csv文件上传到cos
response = client.upload_file(
Bucket=bucket,
Key="books_info.csv",
LocalFilePath="./books_info.csv",
EnableMD5=False,
progress_callback=None
)
6、运用pandas模块分析数据
我们之前创建了csv文件,正好可以读入csv文件中的数据,进行数据的分析,这里我们使用的交互式计算环境jupyter notebook,因为其执行之后可以立即看到执行结果,方便我们进行数据分析
import pandas as pd
df = pd.read_csv("./books_info.csv")
# 将不存在评价的数据字段填充为0
df.fillna({"评分": 0}, inplace=True)
# 依据评价人数基础上对评分进行排序,都是由高到低,最后取得前30行数据
df = df.sort_values(by=["评价人数","评分"], ascending=[False,False])
columns_to_check = ["评价人数","评分"] # 指定需要检查的列
df = df.drop(df[(df[columns_to_check] == 0).any(axis=1)].index)
df = df.head(30)7、数据的可视化
这里我们使用的是pyecharts模块,对于我们刚刚分析出来的数据进行可视化
生成饼图
from pyecharts.globals import ThemeType
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add(
"",
[
list(z)
for z in zip(
df["书名"],df["评价人数"]
)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="书籍评价人数分布"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}:({d}%)"))
)
c.render_notebook()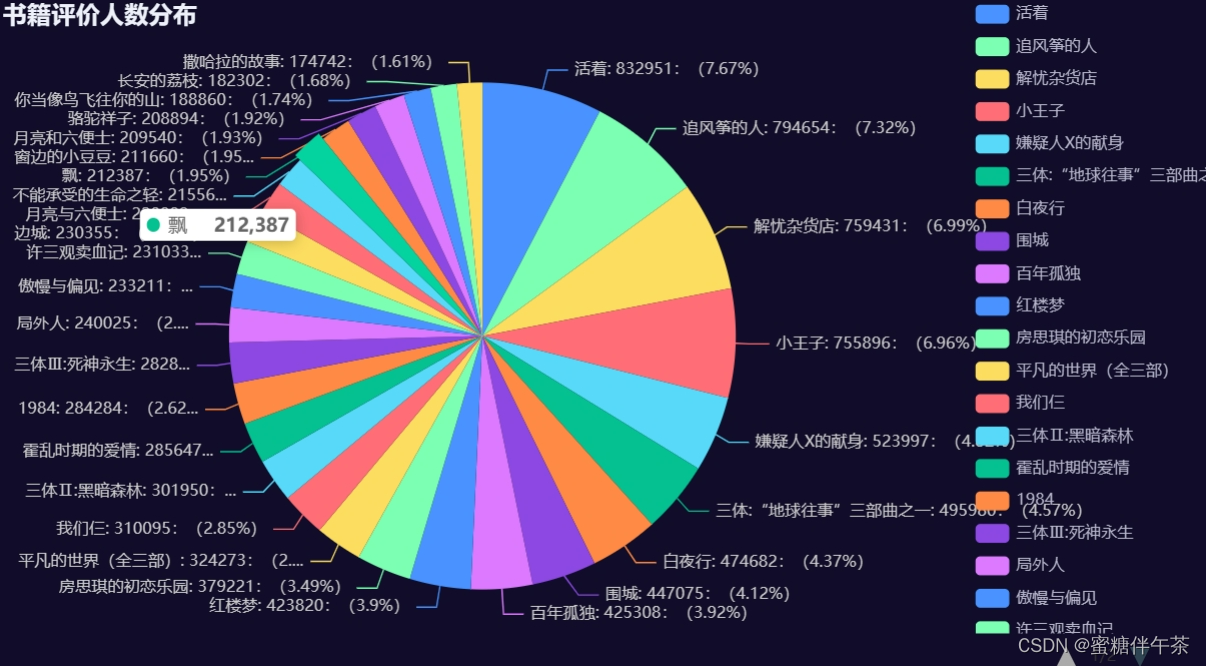
生成柱状图
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.globals import ThemeType
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK, width="10000px"))
.add_xaxis(list(df["书名"]))
.add_yaxis("评分", list(df["评分"]))
.set_global_opts(
title_opts=opts.TitleOpts(
title="书籍评分榜",
pos_left="center",
pos_top="10"),
legend_opts=opts.LegendOpts(pos_left="right"))
)
bar.render_notebook()由于图形过于庞大,这里就不进行展示了
三、完整代码
pycharm:
download模块
import time
import requests
def download(url) -> str:
headers = {
"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0"
}
response = requests.get(url, headers=headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
time.sleep(1)
return response.text main模块
import csv
import sys
import logging
from download import download
from bs4 import BeautifulSoup
from qcloud_cos import CosConfig
from qcloud_cos import CosS3Client
from sqlalchemy import create_engine, text
USER = "root"
HOST = "192.168.56.128"
PASSWD = "123456"
PORT = "3306"
DBNAME = "douban"
DB_URI = f"mysql+pymysql://{USER}:{PASSWD}@{HOST}:{PORT}/{DBNAME}?charset=utf8"
# 创建数据库引擎
engin = create_engine(DB_URI)
# 创建连接,相当于pymysql中的cursor
con = engin.connect()
# 创建数据表
sql = text("DROP TABLE IF EXISTS book_info")
con.execute(sql)
sql = """CREATE TABLE book_info(
书名 TEXT NOT NULL,
评分 CHAR(20),
评价人数 INT)DEFAULT CHARSET=utf8"""
con.execute(text(sql))
# 正常情况日志级别使用 INFO,需要定位时可以修改为 DEBUG,此时 SDK 会打印和服务端的通信信息
logging.basicConfig(level=logging.INFO, stream=sys.stdout)
# 1. 设置用户属性, 包括 secret_id, secret_key, region 等。Appid 已在 CosConfig 中移除,请在参数 Bucket 中带上 Appid。Bucket 由 BucketName-Appid 组成
secret_id = "填写自己的认证id" # 用户的 SecretId,建议使用子账号密钥,授权遵循最小权限指引,降低使用风险。子账号密钥获取可参见 https://cloud.tencent.com/document/product/598/37140
secret_key = "填写自己的认证密钥" # 用户的 SecretKey,建议使用子账号密钥,授权遵循最小权限指引,降低使用风险。子账号密钥获取可参见 https://cloud.tencent.com/document/product/598/37140
region = 'ap-shanghai' # 替换为用户的 region,已创建桶归属的 region 可以在控制台查看,https://console.cloud.tencent.com/cos5/bucket
# COS 支持的所有 region 列表参见 https://cloud.tencent.com/document/product/436/6224
token = None # 如果使用永久密钥不需要填入 token,如果使用临时密钥需要填入,临时密钥生成和使用指引参见 https://cloud.tencent.com/document/product/436/14048
scheme = 'https' # 指定使用 http/https 协议来访问 COS,默认为 https,可不填
config = CosConfig(Region=region, SecretId=secret_id, SecretKey=secret_key, Token=token, Scheme=scheme)
client = CosS3Client(config)
books_info = []
# 获取豆瓣读书文学tag网页数据
for i in range(50):
url = f"https://book.douban.com/tag/%E6%96%87%E5%AD%A6?start={i*20}&type=T"
html = download(url)
# 将获取到的网页数据转换为python类方便filter
bs = BeautifulSoup(html, "lxml")
book_list = bs.find_all("li", {"class": "subject-item"})
for book in book_list:
book_info = []
book_title = "".join(book.find_all("a")[1].text.strip().split())
rates = book.find("div", {"class": "star clearfix"}).find_all("span")
if len(rates) > 1:
book_rate = book.find("div", {"class": "star clearfix"}).find_all("span")[1].string
rate_nums = book.find("div", {"class": "star clearfix"}).find_all("span")[2].string.strip().strip("(").split("人")[0]
rate_nums = int(rate_nums)
else:
book_rate = None
rate_nums = 0
sql = "INSERT INTO book_info(书名, 评分, 评价人数) VALUES(:book_title, :book_rate, :rate_nums)"
con.execute(text(sql), {"book_title": book_title, "book_rate": book_rate, "rate_nums": rate_nums})
con.commit()
book_info.append(book_title)
book_info.append(book_rate)
book_info.append(rate_nums)
books_info.append(book_info)
with open("books_info.csv", 'w+', newline="", encoding="utf8") as file:
writer = csv.writer(file)
writer.writerow(["书名", "评分", "评价人数"])
writer.writerows(books_info)
bucket = '填写自己的存储桶名字'
# 使用高级接口上传一次,不重试,此时没有使用断点续传的功能
# 将生成的csv文件上传到cos
response = client.upload_file(
Bucket=bucket,
Key="books_info.csv",
LocalFilePath="./books_info.csv",
EnableMD5=False,
progress_callback=None
)jupyter notebook:
import pandas as pd
df = pd.read_csv("./books_info.csv")
df.fillna({"评分": 0}, inplace=True)
df = df.sort_values(by=["评价人数","评分"], ascending=[False,False])
columns_to_check = ["评价人数","评分"] # 指定需要检查的列
df = df.drop(df[(df[columns_to_check] == 0).any(axis=1)].index)
df = df.head(30)
from pyecharts.globals import ThemeType
from pyecharts import options as opts
from pyecharts.charts import Pie
from pyecharts.faker import Faker
c = (
Pie(init_opts=opts.InitOpts(theme=ThemeType.DARK))
.add(
"",
[
list(z)
for z in zip(
df["书名"],df["评价人数"]
)
],
center=["40%", "50%"],
)
.set_global_opts(
title_opts=opts.TitleOpts(title="书籍评价人数分布"),
legend_opts=opts.LegendOpts(type_="scroll", pos_left="80%", orient="vertical"),
)
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}:({d}%)"))
)
c.render_notebook()
from pyecharts.charts import Bar
from pyecharts import options as opts
from pyecharts.globals import ThemeType
bar = (
Bar(init_opts=opts.InitOpts(theme=ThemeType.CHALK, width="10000px"))
.add_xaxis(list(df["书名"]))
.add_yaxis("评分", list(df["评分"]))
.set_global_opts(
title_opts=opts.TitleOpts(
title="书籍评分榜",
pos_left="center",
pos_top="10"),
legend_opts=opts.LegendOpts(pos_left="right"))
)
bar.render_notebook()














 872
872

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









