







程序的编译
1. 程序的翻译环境和执行环境
在ANSI C的任何一种实现中,存在两个不同的环境。
- 翻译环境,在这个环境中源代码被转换为可执行的机器指令。
- 执行环境,它用于实际执行代码。
2. 详解翻译环境
总的来说,翻译环境是将源文件(.c文件)转化为可执行程序(.exe程序)
-
组成一个程序的每个源文件通过编译过程分别转换成目标代码(object code)。
-
每个目标文件由链接器(linker)捆绑在一起,形成一个单一而完整的可执行程序。
-
链接器同时也会引入标准C函数库中任何被该程序所用到的函数,而且它可以搜索程序员个人的程序库,将其需要的函数也链接到程序中。

2.1 详解编译过程
PS:编译过程基于Lunix操作环境进行讲解
上图中的.c文件转换为.obj文件的过程就被称为编译过程,编译过程又被分为下面三个步骤
- 预编译
- 编译
- 汇编

在这些过程中编译器都做了什么呢?做这些的目的是什么呢?
这里先给大家一个笼统的概念,具体内容会在后面分析: >

每一个.c的源文件,都会在编译器编译后,生成.o的目标文件,而这些目标文件又要被链接器连接起来生成.exe的文件
2.1.1 预编译(预处理)
总体来说预编译阶段处理的是:文本操作👇
- 头文件的包含
#include - 删除注释
#define定义符号的替换- 处理条件预编译指令如:
"#if、#ifdef、#elif、#else、#endif"
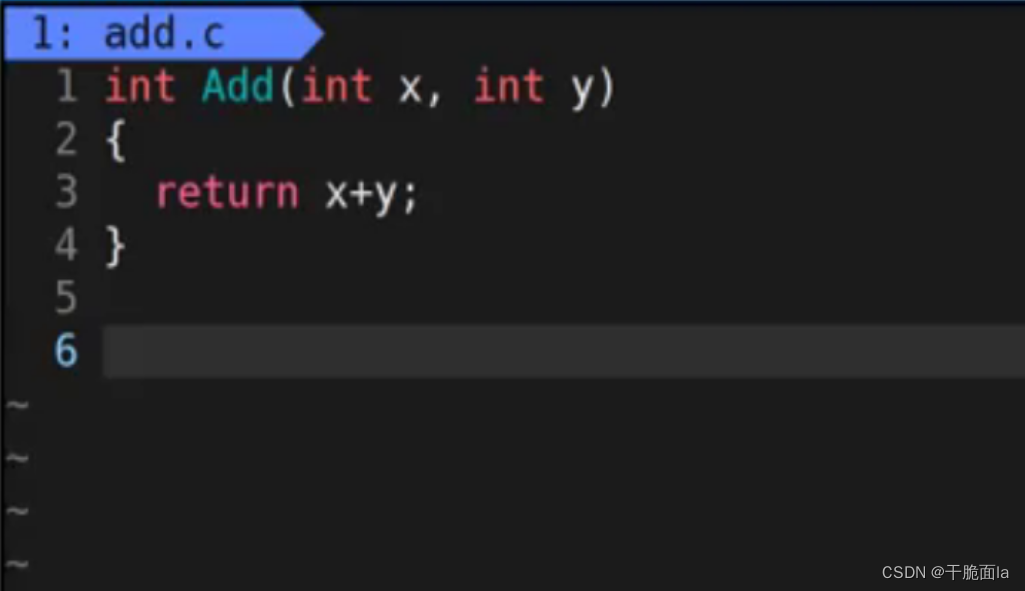
以实现两数相加为例:写下test.c和add.c文件

输入指令
gcc -E test.c -o test.i可以使预处理完成之后就停下来,预处理之后产生的结果都放在test.i文件中。
打开test.i文件,我们发现原本十几行的代码,在预处理后变成了八百多行。
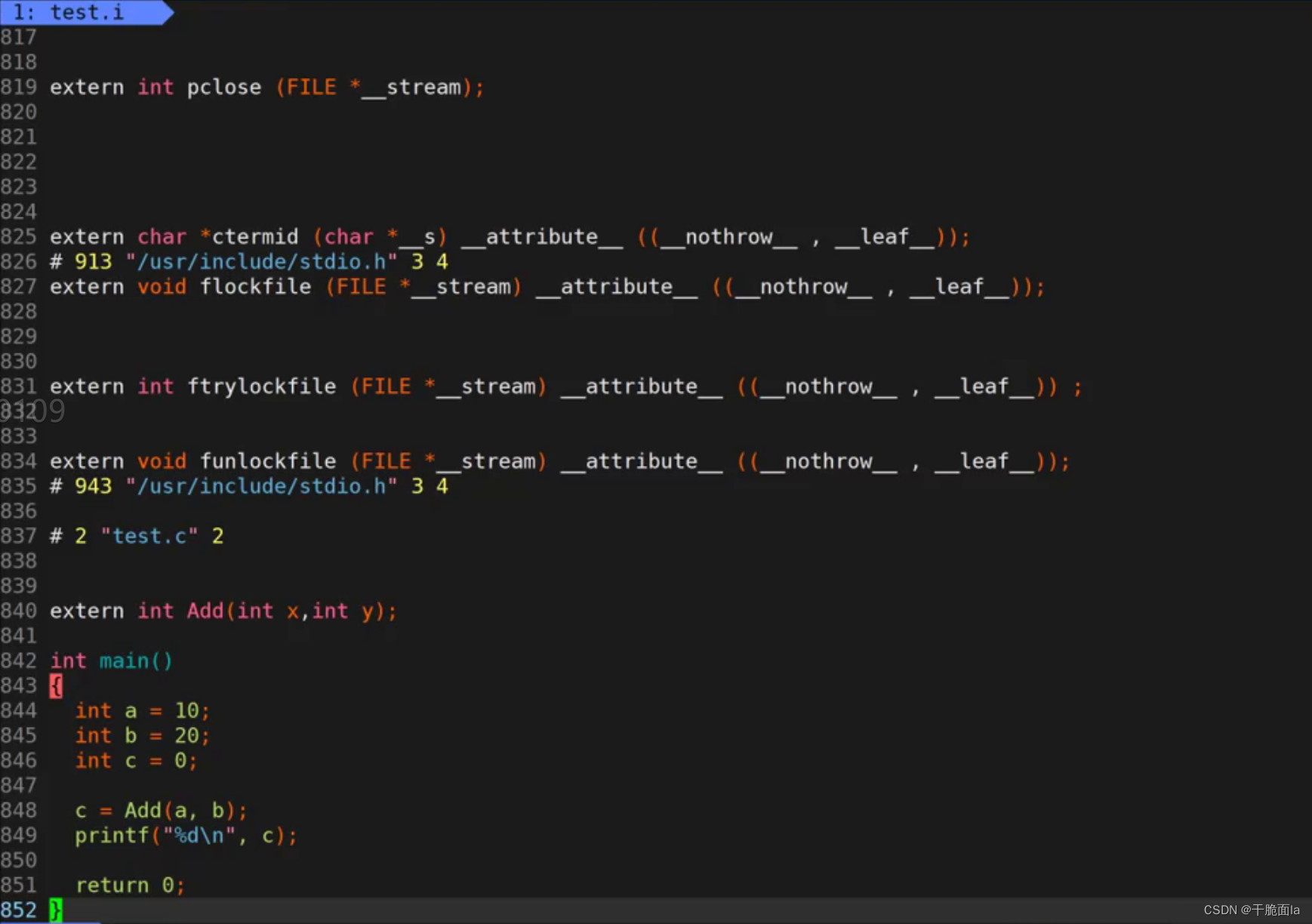
不难发现,对比于test.c文件,在test.i文件中少了声明函数的代码#include <stdio.h>,实际上就是把stdio.h这个头文件展开并包含进来了。
第一个结论:预编译会进行头文件的包含
#include
对比于test.c文件,我们还发现我们写下的注释://声明函数,对于编译器来说,注释是没用的,因此会将其删除。
第二个结论:预编译会删除注释
我们再次打开test.c文件,对其新增#define MAX 100 和int m = MAX两句话👇
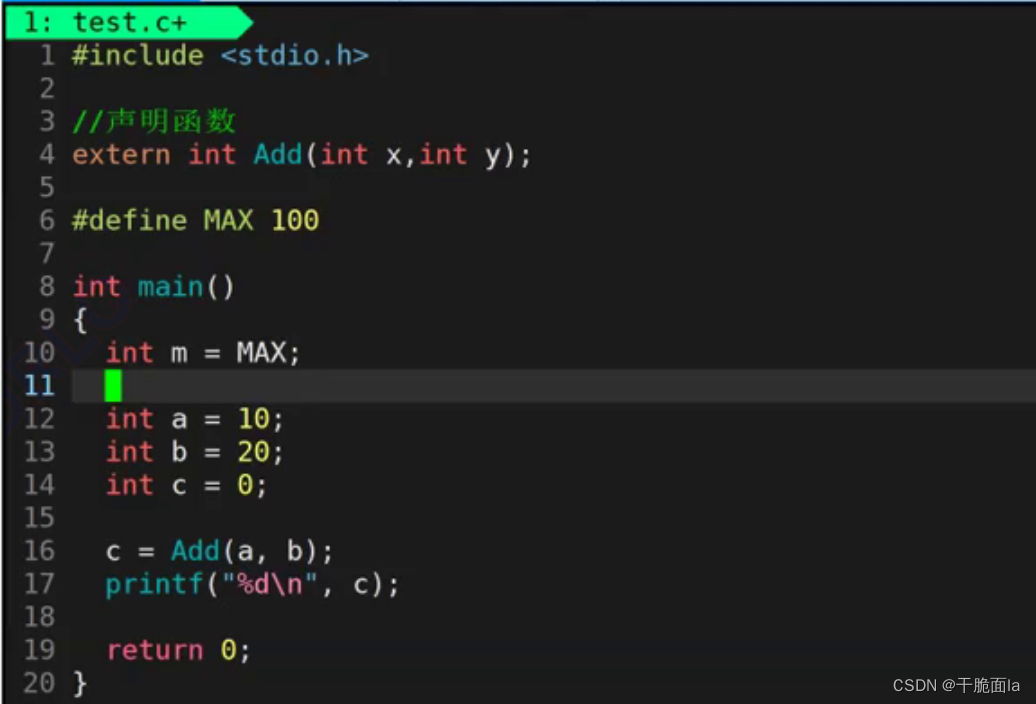
再次打开test.i文件,我们可以发现语句#define MAX 100不见了,并且将int m = MAX替换成了int m = 100
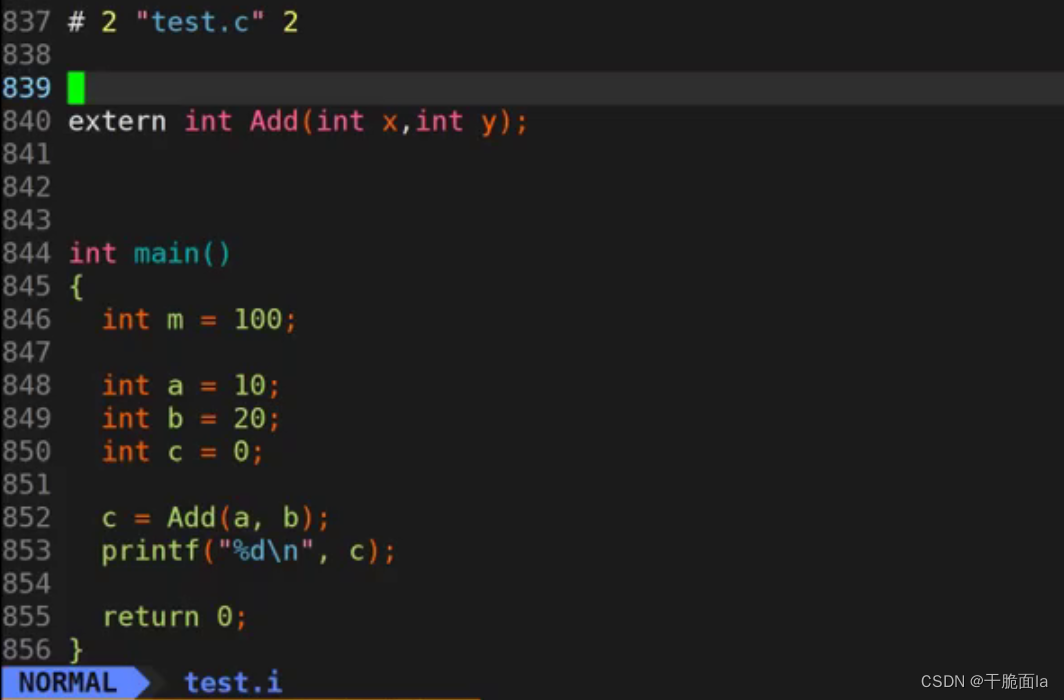
第三个结论:预编译会将
#define定义符号进行替换
条件编译
PS:对于条件预编译指令的处理会在后面的章节提到,这里先不提
2.1.2 编译
总体来说预编译阶段处理的是:将C语言代码翻译成汇编代码👇
- 词法分析
- 语法分析(编译器在此过程中报语法错误)
- 语义分析
- 符号汇总
输入指令
gcc -S test.i,使编译完成之后就停下来,结果保存在test.s中。
打开test.s文件,下面这些即为汇编代码:
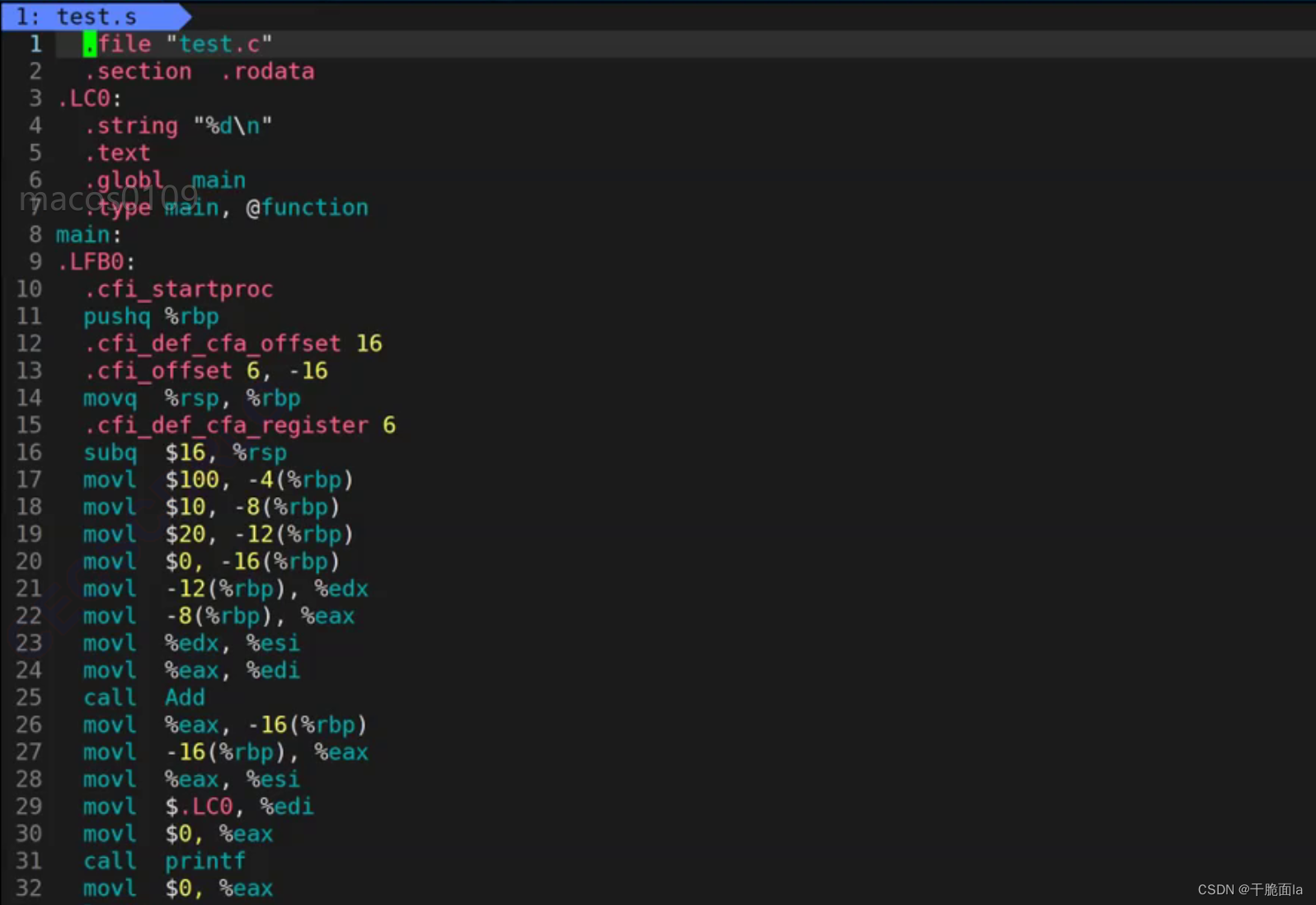
要想将C语言转化转化为汇编代码,需要经过1.词法分析、2.语法分析、3.语义分析的过程,这个过程很复杂,我们简单介绍。
①词法分析
首先将源代码程序输入到扫描器中,将其分割成一系列的记号,如这样一句代码:arr[1] = n * 2;,会被分割成下面这样👇
| 记号 | 类型 |
|---|---|
| arr | 标识符 |
| [ | 左方括号 |
| 1 | 数字 |
| ] | 右方括号 |
| = | 赋值 |
| n | 标识符 |
| * | 乘号 |
| 2 | 数字 |
记号一般被分为几大类:关键字、标识符、字面量(数字、字符串等)和特殊符号(加号,等号)。在识别记号的同时,扫描器也完成了其他操作,比如将标识符放到符号表;把数字、字符串等放到文字表等。
②语法分析
接下来语法分析器将对扫描器分割下来的记号进行语法分析,从而形成语法树,如下图。
此过程中语法分析器可以对错误的语法进行报错(如括号不匹配、表达式缺少操作符等)。

③语义分析
接下来是由语义分析器进行语义分析,语法分析仅完成了表达式的语法层面的分析,无法判断该句是否有意义。比如两个指针在进行乘法运算的时候是没有意义的,但在语法分析里不会报错。
经过语义分析后,语法树的表达式都被标识了类型。如果有些类型需要做隐式转换还会插入相应的转换节点,由于例子中都是整型,所以无需转换。如下图👇

可以看到每个表达式,包括(符号和数字)都被标识了类型。
PS:符号汇总会在汇编中讲到
2.1.3 汇编
总体来说汇编处理的是:将汇编代码转变成机器可以执行的二进制指令👇
- 将汇编代码转变成二进制指令
- 形成符号表
输入指令
gcc -c test.s,使汇编完成之后就停下来,结果保存在test.o中。
PS:windows环境下汇编生成.obj文件,Linux环境下生成.o文件
①将汇编代码转变成二进制指令
打开test.o文件,我们里面已经是二进制的信息了👇

但在汇编过程中其实还进行了符号表的形成,这里我们重点讲述一下符号表的形成。
②符号表的形成
前面的讲解中我们只对test.c文件进行操作并生成了它的目标文件,我们再次输入下面的指令,生成add.o的文件👇
gcc -E add.c -o add.i
gcc -S add.i
gcc -c add.s
此时目录下就有这些文件,而add.o和test.o文件就是要被链接转换成.exe文件的目标文件👇

在先前的编译中提到过符号汇总,所谓的符号会将全局的符号进行汇总(暂时忽略库函数printf)👇

而在汇编的时候,会对这些符号进行相关的补充,形成符号表。
在对test.c文件单独进行编译处理(这里的编译处理指的是大过程,包含预编译、编译、汇编) 的时候,只见过Add函数的声明,也就是说Add函数没有它的函数地址。
而对于main函数是在test.c里面进行定义的,也就是有它的函数地址。
而形成符号表的时候,会对add和main填充函数地址
对于在test.c中定义的main函数会填充其函数地址,比如0x400;而对Add函数只会往符号表中放一个默认的填充值,比如0x000。
同样的道理,对于Add.c文件进行编译处理的时候,会填充Add函数的函数地址,比如0x200👇

在Linux环境下,.o文件和可执行程序的文件格式是elf
这时候需要用一个工具readelf来解析elf格式的文件
输入指令来解析该文件的符号表👇
readelf -s test.o

这时我们可以在符号表中看到main Add printf函数,证明符号表是确确实实实在的。
2.2 链接
- 合并段表
- 符号表的合并和符号表的重定位

输入指令:
gcc test.o add.o,对它们进行链接
此时就生成了a.out的可执行程序👇
PS:windows下可执行程序后缀名为.obj, Linux下可执行程序后缀名为.out

2.2.1合并段表
其实test.o和add.o这样的elf文件,是分为几个段的,每个段都有其特殊的意义,并且两个elf格式的文件段的数量是相同并且功能是一一对应的。
而链接的过程中想要把两个.o文件连接在一起,形成可执行程序。其实就是要把这样的一个个对应的段给连接起来👇

2.2.2符号表的合并和重定位
符号表的合并和重定位其实就是将先前test.c文件的符号表中名为add的符号,与add.c文件的符号表中符号名为add进行合并,称为符号表的合并。
合并的过程中将先前add默认填充的0x000地址,修改为add的真实函数地址0x200的过程叫做重定位,如下图👇

而可执行程序a.out中便有这个合并后的符号表
2.2.3符号表的形成以及合并的意义
前面描述了这么多编译器是如何形成符号表以及如何合并符号表过程,那么符号表的形成以及合并的意义究竟是什么呢?
多个目标文件进行链接的时候,会通过符号表查看来自外部的符号是否存在。
若符号表中的函数地址是默认填充的(0x000)那么即便声明了函数,编译器依然会报错
将add.c文件中的Add函数定义给删除,再次运行👇
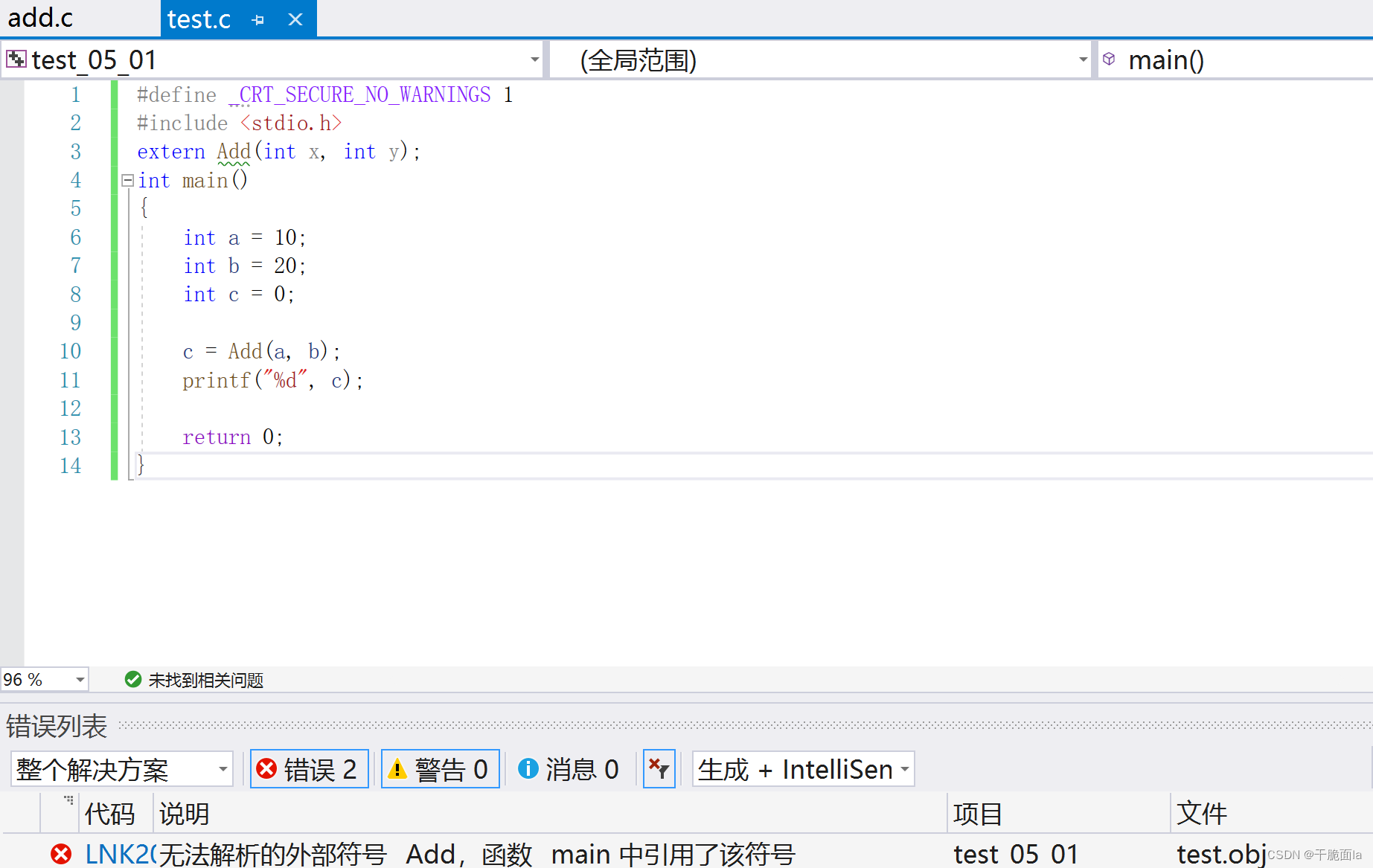
程序此时正是在链接的过程中报的错。
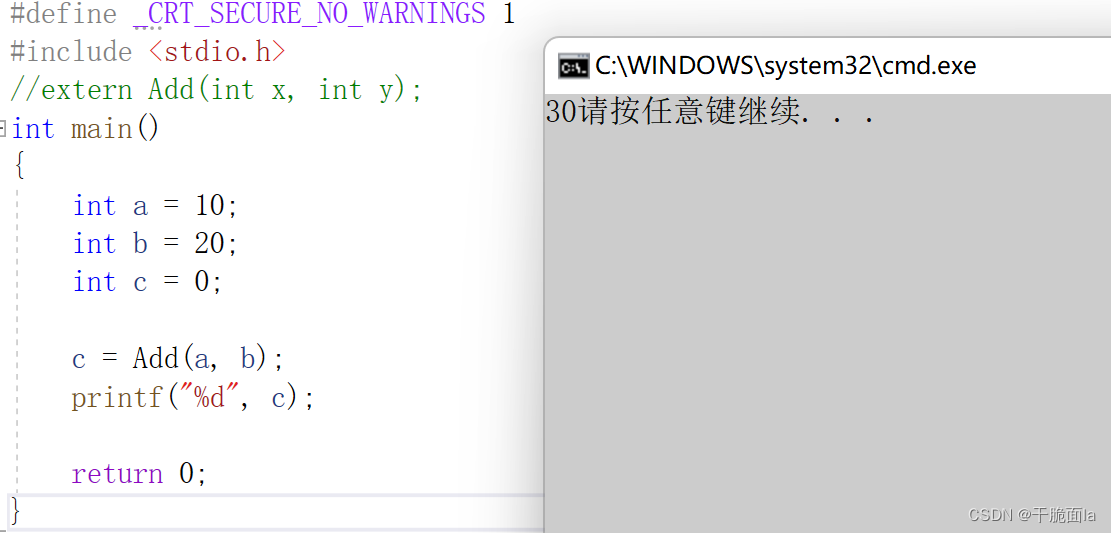
如果我们再把extern Add(int x, int y)给注释掉。并且将Add函数的定义写上,此时便没有函数声明。再次运行程序,由于符号表的形成以及合并我们发现程序依旧能运行起来👇
3. 简介运行环境
程序执行的过程:
- 程序必须载入内存中。在有操作系统的环境中:一般这个由操作系统完成。在独立的环境中,程序的载入必须由手工安排,也可能是通过可执行代码置入只读内存来完成。
- 程序的执行便开始。接着便调用main函数。
- 开始执行程序代码。这个时候程序将使用一个运行时堆栈(stack),(也就是函数栈帧,对于函数栈帧的的创建和销毁👉戳这里),存储函数的局部变量和返回地址。程序同时也可以使用静态(static)内存,存储于静态内存中的变量在程序的整个执行过程一直保留他们的值。
- 终止程序。正常终止main函数;也有可能是意外终止。
















 4899
4899











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











