







一、实现免密登录
免密登录这里我们展示的是基于密钥的认证((publickey认证)本质为非对称加密):
- 客户端产生一对公共密钥,将公钥保存到将要登录的服务器上的那个账号的家目录的.ssh/authorizedkeys文件中。认证阶段:客户端首先将公钥传给服务器端。服务器端收到公钥后会与本地该账号家目录下的authorizedkeys中的公钥进行对比,如果不相同,则认证失败;否则服务端生成一段随机字符串,并先后用客户端公钥和会话密钥对其加密,发送给客户端。客户端收到后将解密后的随机字符串用会话密钥发送给服务器。如果发回的字符串与服务器端之前生成的一样,则认证通过,否则,认证失败。
- 注意:服务器端对客户端进行认证,如果认证失败,则向客户端发送认证失败消息,其中包含可以再次认证的方法列表。客户端从认证方法列表中选取一种认证方法再次进行认证,该过程反复进行。直到认证成功或者认证次数达到上限,服务器关闭连接为止。
1.Linux主机间的免密登录
1)先设置服务端Linux的公钥和私钥
配置如下:
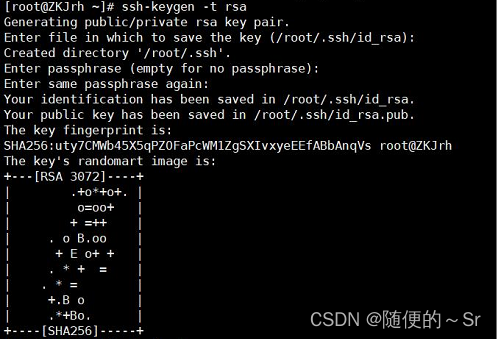
指令:ssh-keygen -t rsa : 生成、管理和转换认证密钥 -t制定类型 RSA 型
这里可以看到虽然我们没有输入公钥及私钥但根据提示可知Linux服务端主机已自动帮我们生成了公钥及私钥分别保存在 /root/.ssh/id_rsa.pub(公钥),/ root/.ssh/id_rsa私钥。
2)查看是否生成密钥文件

3)将公钥发送给客户端的Linux主机
集体配置:
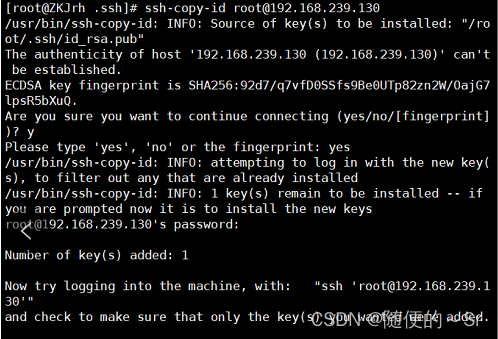
指令:ssh-copy-id:将公钥发给指定IP的Linux主机
4)在客户端的Linux主机上查看是否有公钥文件

5)进行Linux间的免密登录
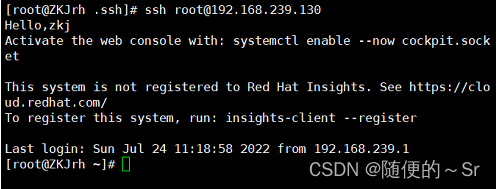
可以看到Linux服务端成功免密登录到Linux客户端
2.windows主机与linux主机间的免密登录
这里我们用xshell进行演示
1)先通过Xshell菜单栏里的工具选项进入新建密码生成导向
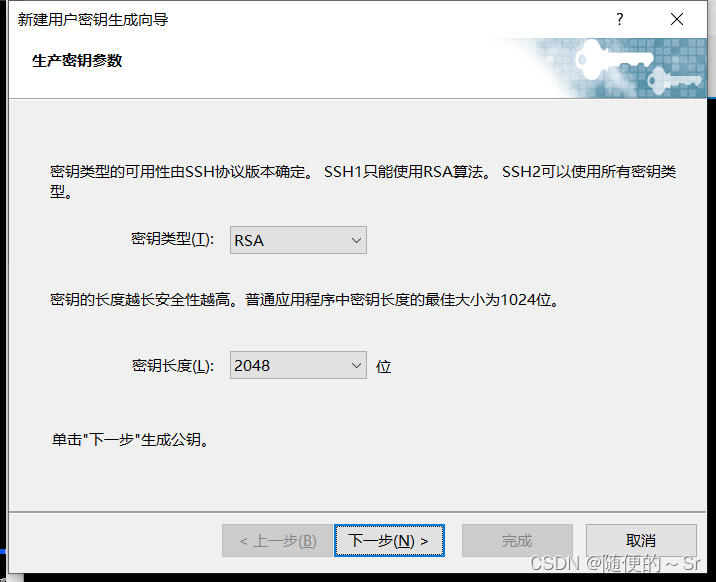
选择密钥类型单击下一步
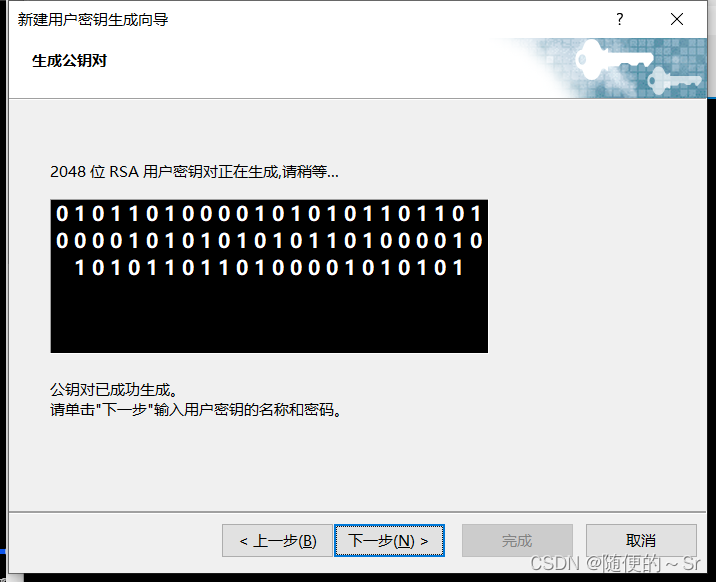
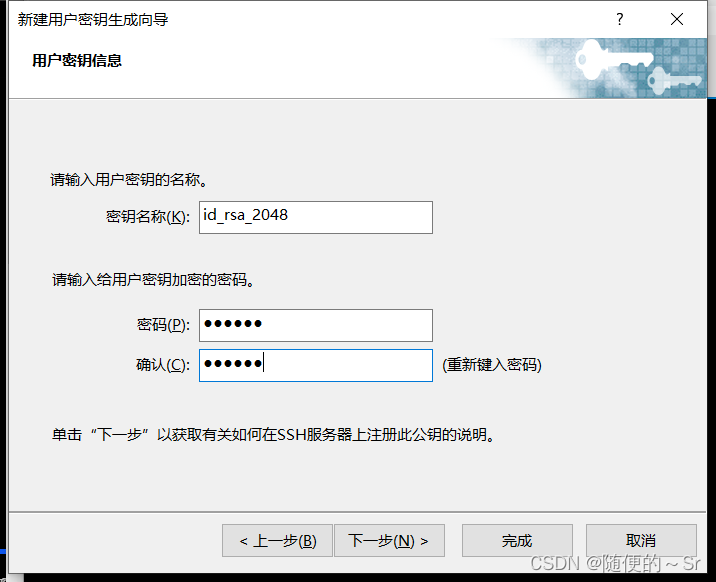
Windows通过Xshell免密登录必须要输入密码
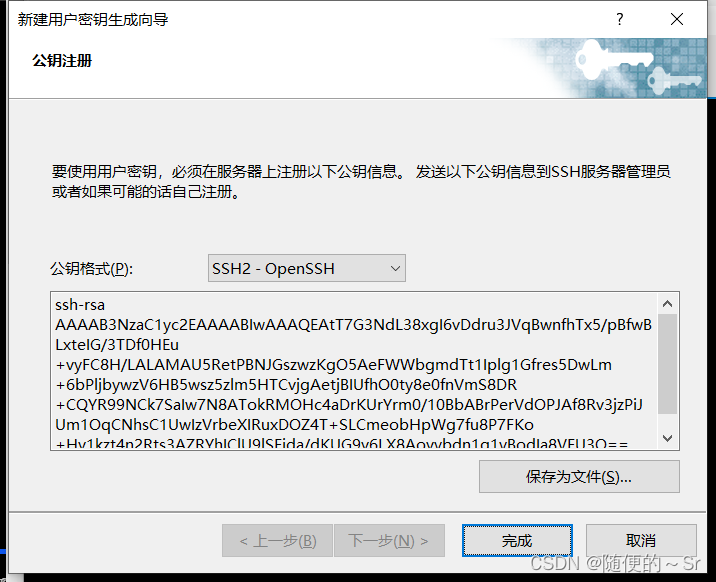
此处显示的为公钥的格式将他保存
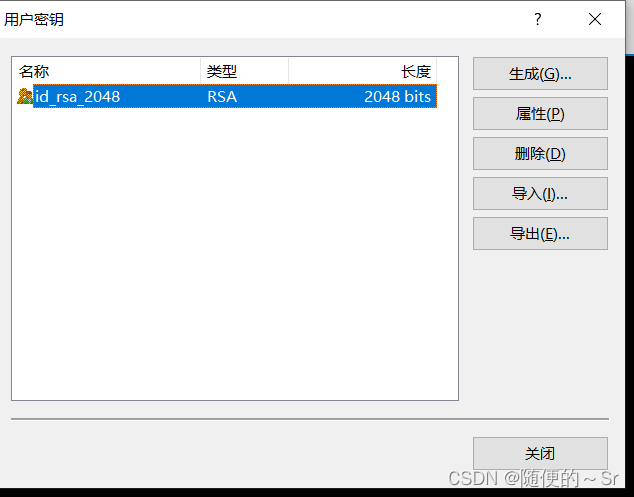
单击完成上一步后已生成私钥密钥
2)向Linux客户端导入公钥文件
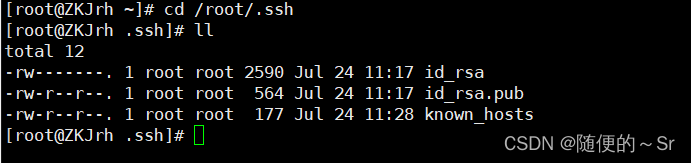
查看到Linux下的/root/.ssh目录下现在没有id_rsa_2048.pub文件(免密登录的公钥存放文件)及Linux客户端还没有公钥。
通过xftp应用将刚才保存的公钥文件传输到Linux下的/root/.ssh目录
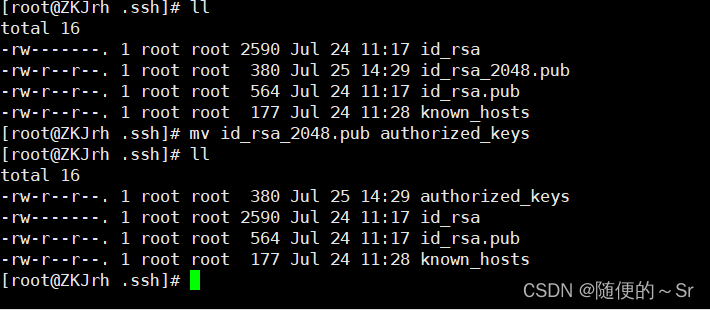
重新查看发现此目录下已有刚刚保存的公钥文件“id_rsa_2048.pub”并将它重命名为免密登录可识别的存放公钥文件“authorized_keys”。
3)配置Xshll免密登录
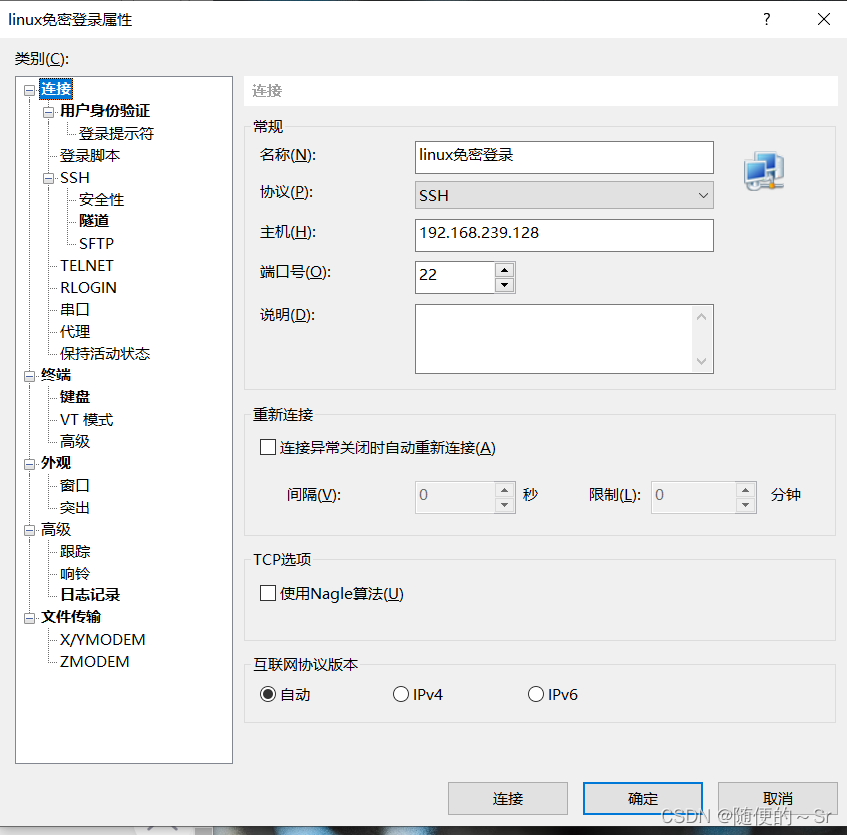
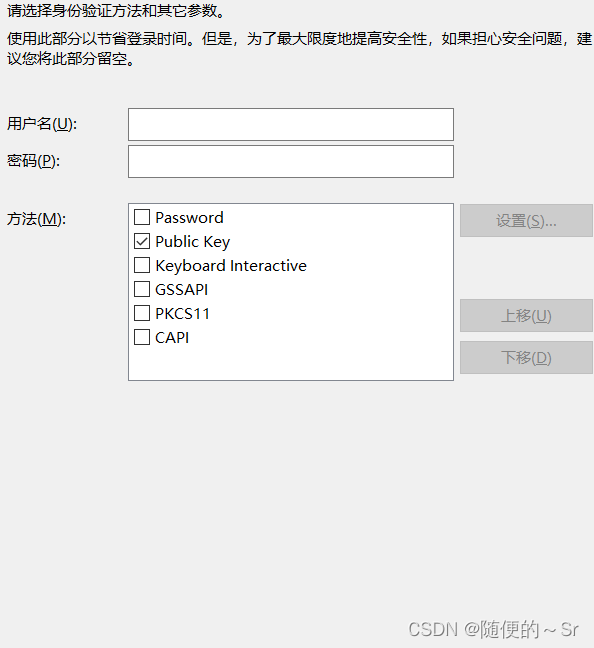
进入用户身份验证界面将验证方式改为public Key模式
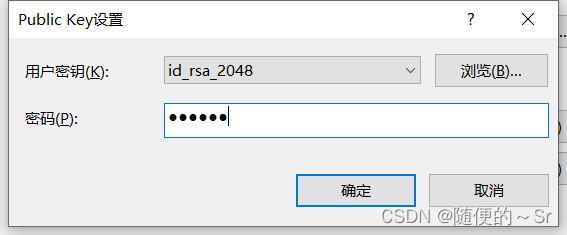
设置密钥,选择用户密钥,输入密码。
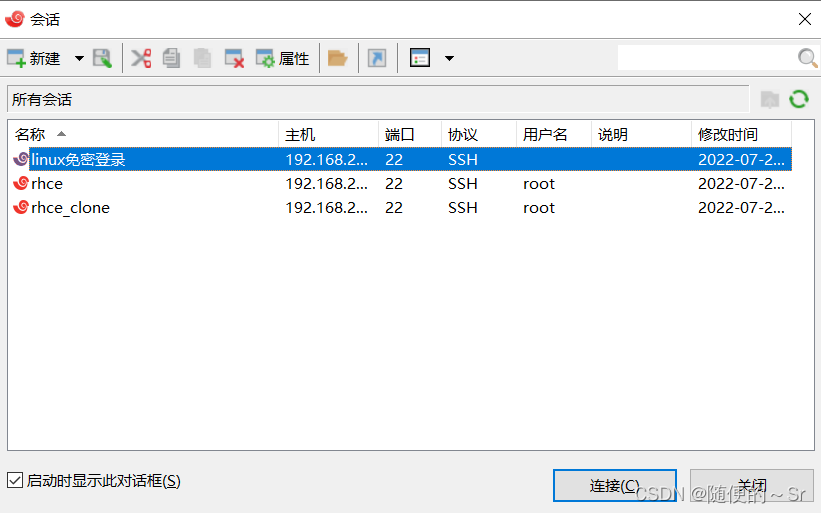
选择Linux免密登录的方式进行登录
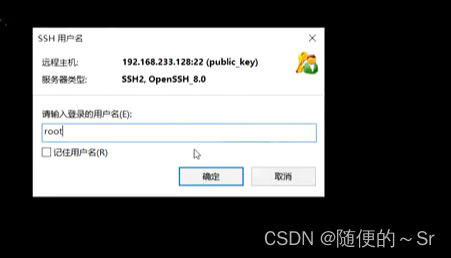
输入登录用户
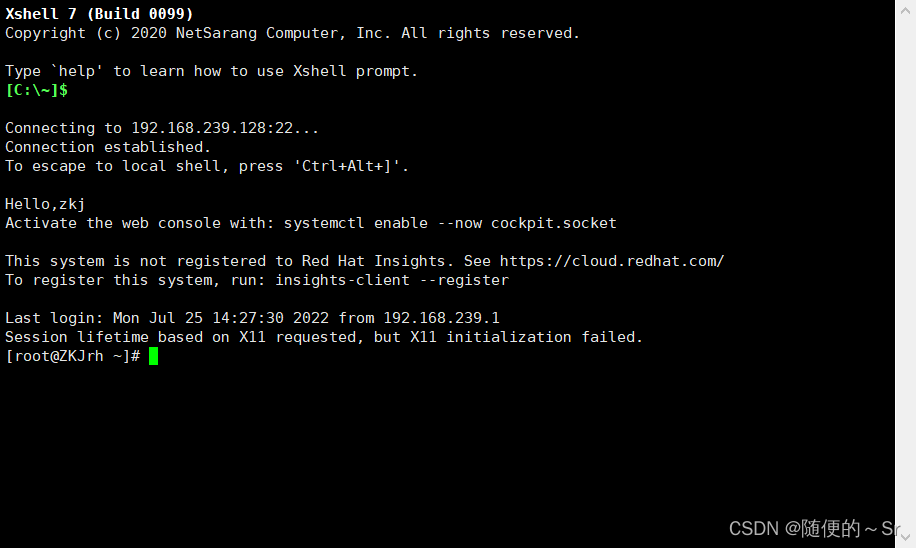
Windows主机成功免密登录到Linux主机的root用户下。
二、限制Linux用户登录
要求:设置只允许student1, student2用户登录
1.创建用户登录白名单
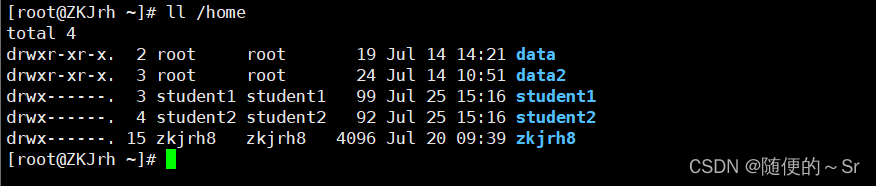
可以看到我的Linux主机下有4个用户分别是root,student1,student2,zkjrh8。
配置如下:
首先通过vim指令编辑/etc/ssh/sshd_config下的配置文件
 在配置文件末尾编写如图所示指令,用于创建Linux用户student1,student2的白名单。
在配置文件末尾编写如图所示指令,用于创建Linux用户student1,student2的白名单。
![]()
用上图所示指令重启sshd服务。
2.测试Linux用户登陆情况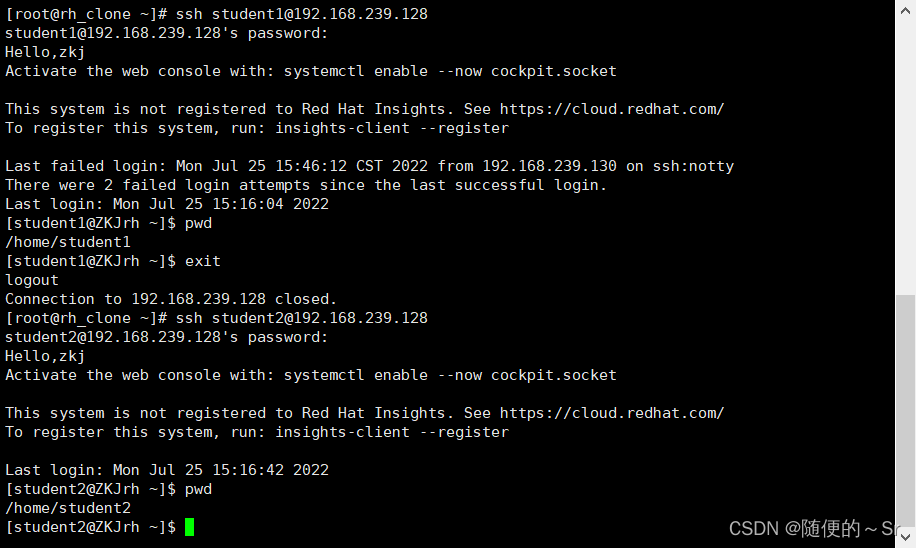
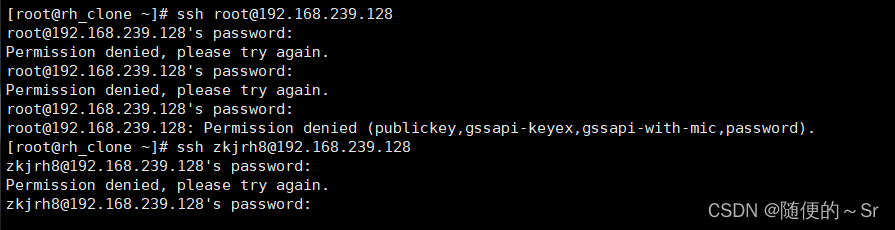
如上图所示:我们用一台新的Linux主机在测试机进行用户登录测试,加入登录白名单的用户student1,student2可正常登录,未添加进登录白名单的用户 root,zkjrh8在登陆时全部卡在了输入密码过程中而无法成功进行用户登录。
证明:限制Linux用户登录配置成功
三、分析HTTP中get和post的区别
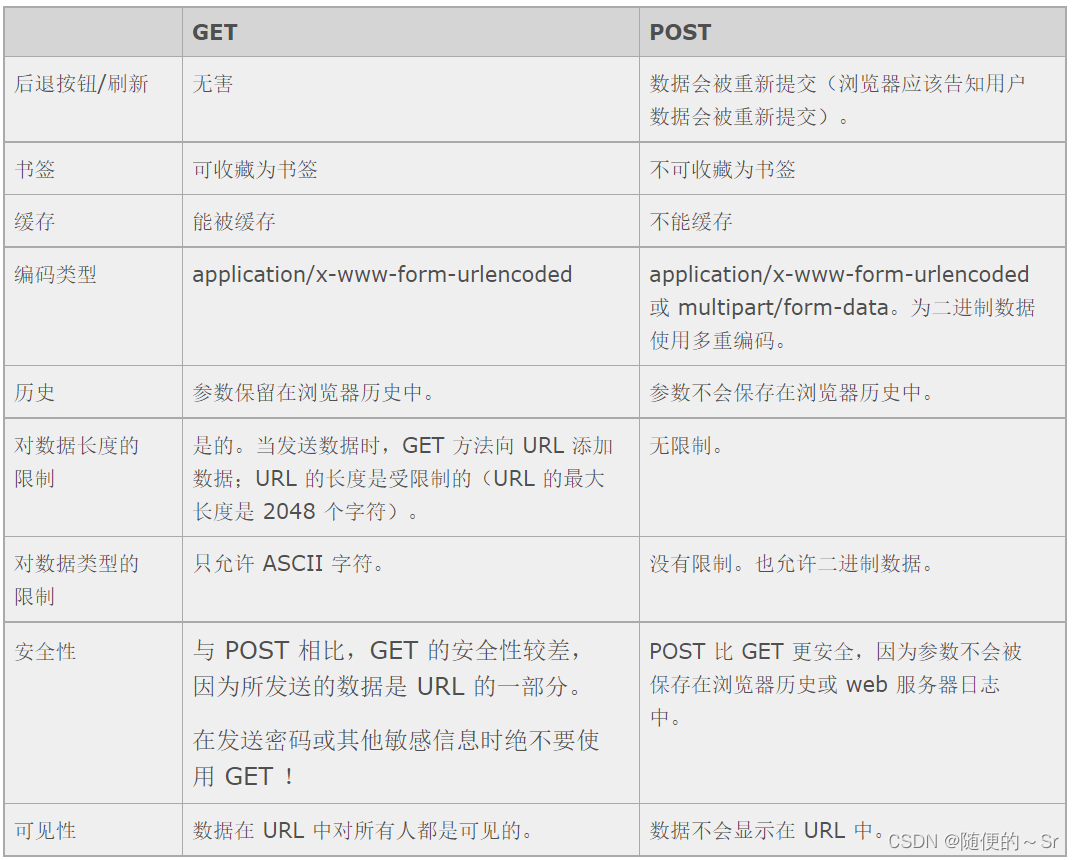
其他方面的区别:
1、功能不同:
1)post是向服务器发送数据; get是向服务器获取数据;
2、过程不同:
1)get在浏览器回退时是无害的,但是post会再次提交请求,
2)get请求会被浏览器主动缓存,但是post不会,除非手动设置 get请求只能进行URL编码,但是 post支持多种编码方式; get请求的参数会保存在浏览器的历史记录中。
3)get请求在URL中传送的参数是有长度限制的,但是post没有;
4)get比post更加不安全,因为传送的参数直接暴露在URL上,所以不能来传送敏感信息。 get参 数通过URL传送,但是post是放在request body里面的。
3、获取值的方式不同
1)get方法,服务端使用的是request.queryString()
2)post方法,服务端使用的是request.form()获取提交的数据。
4、底层记忆方法:
htfp协议中两种发送请求的方法:HTTP是其于TCP/P协议关于数据在万维网中如何通信的协议。
在万维网中,TCP是一辆运输数据的车子,但是重要分清每辆车是做什么用的,这样才能够让运输数据有目的性,并目有秩序,所以呢 Http就发挥作用,给每个车子明确标好是坐什么服务:get、post、delete、put等,要使用GET服务时候,就给车一个标签贴着GET,然后将信息放在车顶的URL中,但是车顶的东西不能无限制的放,而post方法是将要传动的数据放在车厢内,这样敏感信息就更加安全,并且车厢很大,没有限制噻多少数据。所以说get方法和post方法就是TCP连接。
并且get会产生一个TCP数据包,而post会产生两个TCP数据包。对干aet方法:HTTP会把header和data一起发送出去;服务器响应回来200;对干post方法,HTTP会先发送header,服务器响应100;再发送data,服务器响应200,并目研究表明:在网络较好的环境下,我们发送一次数据包和发送两次数据包的时间大致相同,但是网络不好的情况下,两次TCP包对干校验数据的完整性有很大的作用;并目并不是所有的浏览器在处理这个post请求的时候都会进行两次的发包,火狐浏览器就不是。
四、HTTP状态码,常用的状态码有哪些?
1.状态码特点
- 1xx:指示信息 —— 表示请求已接收,继续处理
- 2xx:成功 —— 表示请求已被成功接收、理解、接受
- 3xx:重定向 —— 要完成请求必须进行更进一步的操作
- 4xx:客户端错误 —— 请求有语法错误或请求无法实现
- 5xx:服务器端错误 —— 服务器未能实现合法的请求
2.具体的状态码
100 (客户端继续发送请求,这是临时响应):这个临时响应是用来通知客户端它部分请求已经被服务器接收,且仍未被拒绝。客户端应当继续发送请求的剩余部分,或者如果请求已经完成,忽略这个响应。服务器必须完成后向客户端发送一个最终响应
101:服务器根据客户端的请求切换协议,主要用于websocket或http2升级
200(成功):请求已成功,请求所希望的响应或数据体将随此响应返回
201(已创建):请求成功并且服务器创建了新的资源
202(已创建):服务器已经请求,但尚未处理
203(非授权信息):服务器已成功处理请求,但返回的信息可能来自另一来源
204(无内容):服务器成功处理请求,但没有返回任何内容
300:针对请求,服务器可执行多种操作。
301:请求的网页已经永久移动到新位置
302:服务器目前从不同的位置网页响应请求 但请求者应继续使用原有位置来进行以后的请求
303:请求者当对目前从不同的位置使用单独的GET请求来检索响应时 服务器返回此代码
305:请求者只能使用代理访问请求的网页
400:服务器不理解请求的语法
401:请求要求身份验证
403:服务器拒绝了请求
404:服务器找不到请求的网页
405:禁用请求中指定的方法
406:无法使用请求的内容特性响应请求的网页
500:服务器遇到错误 无法完成请求
501:服务器不具备完成请求的功能
502:服务器作为网关或代理 从上游服务器收到无效响应
503:服务器目前无法使用
504:服务器作为网关或代理,但是没有及时从上游服务器收到请求
505:服务器不支持请求中所用的HTTP协议版本
五、HTTP请求报文和响应报文
HTTP报文:http报文中有很多行内容,这些行的字段内容都是由一些ASCII码串组成,但各个字段的长度是不同的。http报文可分为两种,一种是从web客户端发往web服务器的http报文,称为请求报文。另外一种是从web服务器发往web客户端的报文,称为响应报文
1.http请求报文

- MIME(Multipurpose Internet Mail Extension,多用途因特网邮件扩展)最初是为了解决在不同的电子邮件系统之间搬移报文时存在的问题。后来http也支持了这个功能,用它来描述数据并标记不同的数据内容类型。
- 当web服务器响应http请求时,会为每一个http对象数据加一个MIME类型。当web浏览器获取到服务器返回的对象时,会去查看相关的MIME类型,并进行相应的处理。
- MIME类型存在于HTTP响应报文的响应头部信息里,它是一种文本标记,表示一种主要的对象类型和一个特定的子类型。常见的MIME类型:
| MIME类型 | 文件类型 |
| text/html | html、htm、shtml文本类型 |
| text/css | css文本类型 |
| text/xml | xml文本类型 |
| image/gif | gif图像类型 |
| video/x-ms-wmv | wmv视频类型 |
| application/json | json文本类型 |
2. http响应报文
所谓响应其实就是服务器对请求处理的结果,或者如果浏览器请求的直接就是一个静态资源的话,响应的就是这个资源本身。
HTTP响应报文主要由状态行、响应头部、响应正文3部分组成。

状态行格式为:HTTP-Version Status-Code Reason-Phrase CRLF,分别为:协议版本,状态码,状态码描述,之间由空格分隔。其中,HTTP-Version表示服务器HTTP协议的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。状态码如上问所示。
六、HTTP是如何保持连接状态的
1.cookie+session实现
首先我们来学习一下cookie和session的概念
cookie:
Cookie是由服务器端生成,发送给浏览器,浏览器会将Cookie的key/value保存到某个目录下的文本文件内,下次请求同一网站时自动发送该Cookie给服务器
Cookie可以用来在某个WEB站点会话间持久的保持状态
session:
Session是另一种记录客户状态的机制,基于Cookie实现,不同的是Cookie保存在客户端浏览器中,而Session保存在服务器上
客户端浏览器访问服务器的时候,服务器把客户端信息以某种形式记录在服务器上,这就是Session,客户端浏览器再次访问时只需要从该Session中查找该客户的状态就可以了。
通过cookie和session的了解,我们可以看出Cookie的本质就是文件,一般放在请求头里,保存在浏览器上。
由于cookie并不是很安全,别人可以分析存放在本地的cookie并进行cookie欺骗,考虑到安全应当使用session。并且session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,考虑到减轻服务器性能方面,应当使用cookie
2.HttpSession对象
在所有的Session追踪技术中,HttpSession对象是最强大的,也是功能最多的。用户可以没有或者有一个HttpSession,并且只能访问自己的HttpSession
HttpSession是当一个用户第一次访问某个网站时自动创建的。通过在HttpServletRequest中调用getSession方法,可以获取用户的HttpSession
与网址重写、隐藏域和cookie不同的地方在于,放在HttpSession中的值是保存在服务器的内存中的。注意,HttpSession中保存的值不发送到客户端,这与其他的Session管理方法不同。Servlet容器为它所创建的每一个HttpSession生成一个唯一标识符,并将这个标识符作为一个token发送给浏览器,一般是作为一个名为JSESSIONID的cookie,或者作为一个jsessionid参数添加到URL后面。在后续的请求中,浏览器会将这个token发送回服务器,使服务器能够知道是哪个用户在发出请求。
HttpSession中还定义了一个invalidate方法。这个方法强制Session过期,并将绑定到它的所有对象都解除绑定。在默认情况下,HttpSession是在用户静默一定时间之后过期。可以在部署描述符的session-timeout元素中将session的期限设置为整个应用程序
添加到HttpSession中的值不一定是String,可以为任意Java 对象,只要它的类实现了java.io.Serializable接口即可,以便当Servlet容器认为有必要的时候,保存的对象可以序列化成一个文件或者保存到数据库中















 126
126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









