开始我们机器学习的第一个算法。
还是借用吴老师的例子:
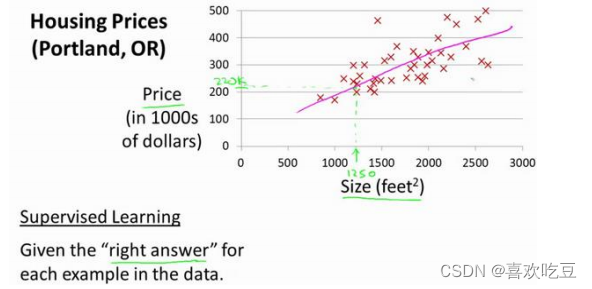
这个例子是预测住房价格的,我们要使用一个数据集,数据集包含俄勒冈州波特兰市的住房价格。在这里,我要根据不同房屋尺寸所售出的价格,画出我的数据集。比方说,如果你朋友的房子是 1250
平方尺大小,你要告诉他们这房子能卖多少钱。那么,你可以做的一件事就是构建一个模型,也许是条直线,从这个数据模型上来看,也许你可以告诉你的朋友,他能以大约 220000(
美元
)
左右的价格卖掉这个房子。
一,建立模型:
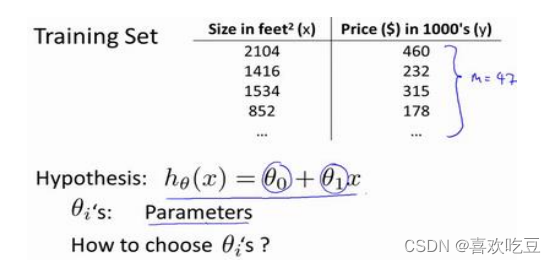
以之前的房屋交易问题为例,假使我们回归问题的训练集(Training Set)如下表所示:
这就是一个监督学习算法的工作方式,我们可以看到这里有我们的训练集里房屋价格。我们把它喂给我们的学习算法,学习算法的工作了,然后输出一个函数,通常表示为小写 ℎ表示。ℎ
代表
hypothesis
(
假设
)
,
ℎ
表示一个函数,输入是房屋尺寸大小,就像你朋友想出售的房屋,因此 ℎ
根据输入的
𝑥
值来得出
𝑦
值,
𝑦
值对应房子的价格 因此,
ℎ
是一个从
𝑥到 𝑦
的函数映射。
接下来我们会引入一些术语我们现在要做的便是为我们的模型选择合适的
参数(parameters
)
𝜃
0
和
𝜃
1
,在房价问题这个例子中便是直线的斜率和在
𝑦
轴上的截距。
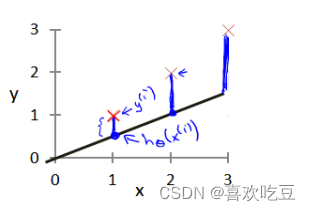
我们选择的参数决定了我们得到的直线相对于我们的训练集的准确程度,模型所预测的值与训练集中实际值之间的差距(下图中蓝线所指)就是建模误差
(
modeling error
)。
我们的目标便是选择出可以使得建模误差的平方和能够最小的模型参数。 即使得代价
函数
𝐽(𝜃
0
, 𝜃
1
) = 1/2m
∑ (ℎ𝜃
(𝑥
(𝑖)
) − 𝑦
(𝑖)
)^
2
最小。
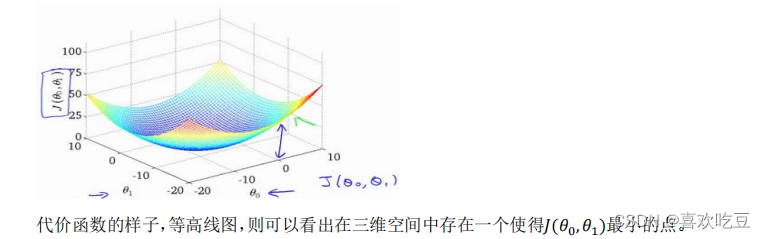
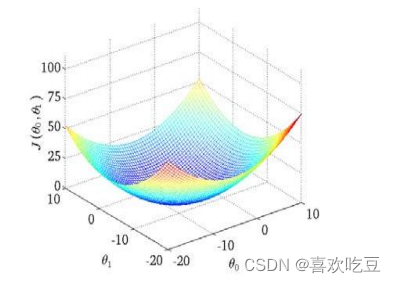
我们绘制一个等高线图,三个坐标分别为
𝜃
0
和
𝜃
1
和
𝐽(𝜃
0
, 𝜃
1
)
:
则可以看出在三维空间中存在一个使得
𝐽(𝜃
0
, 𝜃
1
)
最小的点。
代价函数也被称作平方误差函数,有时也被称为平方误差代价函数。我们之所以要求出误差的平方和,是因为误差平方代价函数,对于大多数问题,特别是回归问题,都是一个合理的选择。还有其他的代价函数也能很好地发挥作用,但是平方误差代价函数可能是解决回归问题最常用的手段了。
在后续文章中,我们还会谈论其他的代价函数,但我们刚刚讲的选择是对于大多数线性回归问题非常合理的


函数分类
回归问题

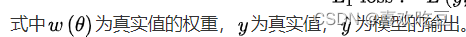
各类回归模型,例如线性回归、广义线性模型(Generalized Linear Model, GLM)和人工神经网络(Artificial Neural Network, ANN)通过最小化L2或L1损失对其参数进行估计。L2损失和L1损失的不同在于,L2损失通过平方计算放大了估计值和真实值的距离,因此对偏离观测值的输出给予很大的惩罚。此外,L2损失是平滑函数,在求解其优化问题时有利于误差梯度的计算;L1损失对估计值和真实值之差取绝对值,对偏离真实值的输出不敏感,因此在观测中存在异常值时有利于保持模型稳定。
分类问题
分类问题所对应的损失函数为0-1损失,其是分类准确度的度量,对分类正确的估计值取0,反之取1:
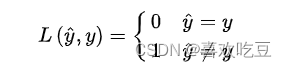
0-1损失函数是一个不连续的分段函数,不利于求解其最小化问题,因此在应用可构造其代理损失(surrogate loss)。代理损失是与原损失函数具有相合性(consistency)的损失函数,最小化代理损失所得的模型参数也是最小化原损失函数的解。当一个函数是连续凸函数,并在任意取值下是0-1损失函数的上界时,该函数可作为0-1损失函数的代理函数 [5-6] 。
这里给出二元分类(binary classification)中0-1损失函数的代理损失:
铰链损失(实线)、交叉熵损失(点)、指数损失(虚线)

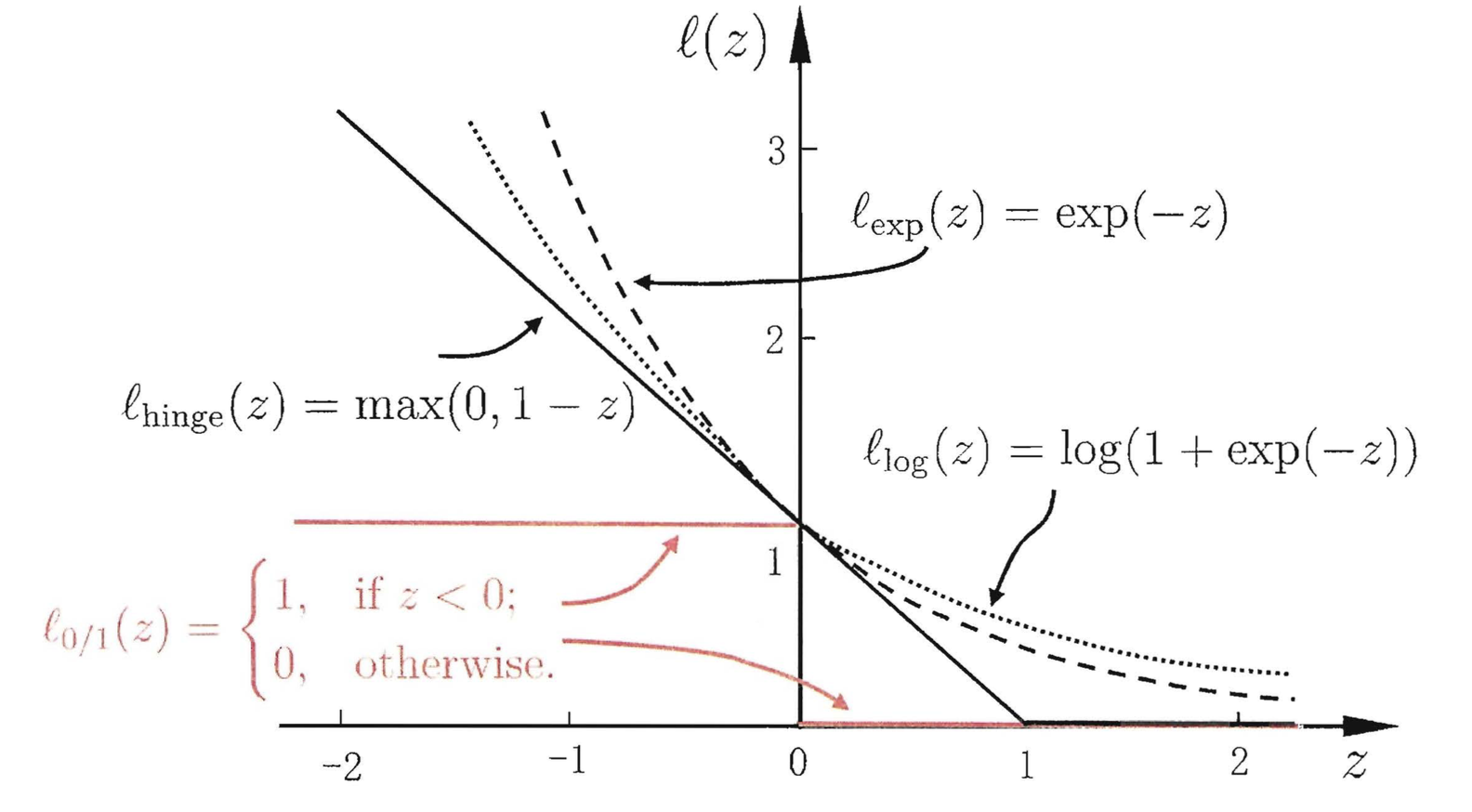
铰链损失函数是一个分段连续函数,其在分类器分类完全正确时取0。使用铰链损失对应的分类器是支持向量机(Support Vector Machine, SVM),铰链损失的性质决定了SVM具有稀疏性,即分类正确但概率不足1和分类错误的样本被识别为支持向量(support vector)被用于划分决策边界,其余分类完全正确的样本没有参与模型求解 [6] 。
交叉熵损失函数是一个平滑函数,其本质是信息理论(information theory)中的交叉熵(cross entropy)在分类问题中的应用。由交叉熵的定义可知,最小化交叉熵等价于最小化观测值和估计值的相对熵(relative entropy),即两者概率分布的Kullback-Leibler散度:
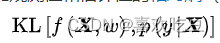
因此其是一个提供无偏估计的代理损失。交叉熵损失函数是表中使用最广泛的代理损失,对应的分类器例子包括logistic回归、人工神经网络和概率输出的支持向量机。
指数损失函数是表中对错误分类施加最大惩罚的损失函数,因此其优势是误差梯度大,对应的极小值问题在使用梯度算法时求解速度快。使用指数损失的分类器通常为自适应提升算法(Adaptive Boosting, AdaBoost),AdaBoot利用指数损失易于计算的特点,构建多个可快速求解的“弱”分类器成员并按成员表现进行赋权和迭代,组合得到一个“强”分类器并输出结果。
三,代价函数的直观理解:
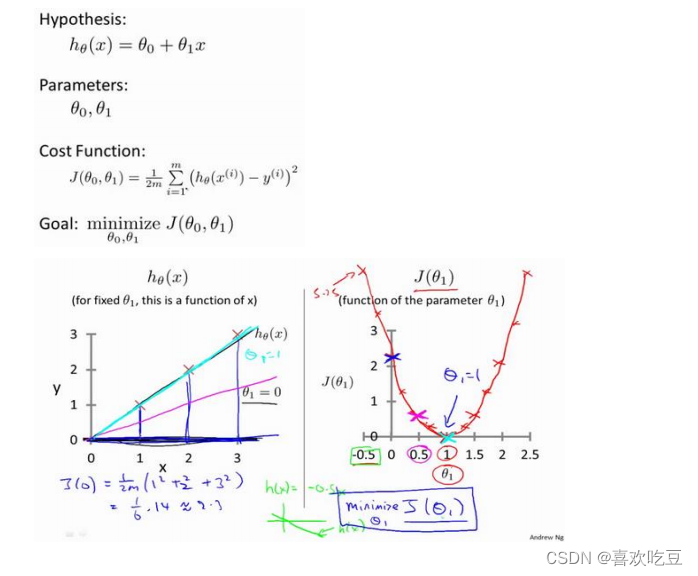
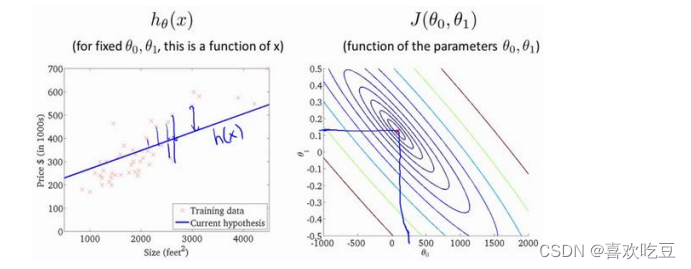
我们真正需要的是一种有效的算法,能够自动地找出这些使代价函数
𝐽
取最小值的参数𝜃
0
和
𝜃
1
来。
我们也不希望编个程序把这些点画出来,然后人工的方法来读出这些点的数值,这很明显不是一个好办法。我们会遇到更复杂、更高维度、更多参数的情况,而这些情况是很难画出图的,因此更无法将其可视化,因此我们真正需要的是编写程序来找出这些最小化代价函数的𝜃
0
和
𝜃
1
的值。
四,梯度下降:
梯度下降是一个用来求函数最小值的算法,我们将使用梯度下降算法来求出代价函数𝐽(𝜃0
, 𝜃
1) 的最小值。
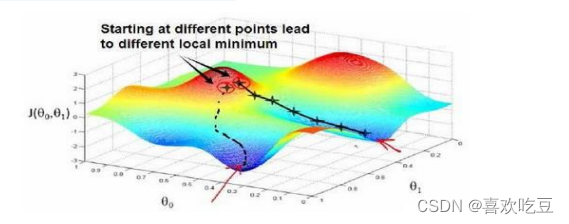
梯度下降背后的思想是:开始时我们随机选择一个参数的组合
(𝜃
0
, 𝜃
1
, . . . . . . , 𝜃
𝑛
)
,计算代价函数,然后我们寻找下一个能让代价函数值下降最多的参数组合。我们持续这么做直到一个局部最小值(local minimum
),因为我们并没有尝试完所有的参数组合,所以不能确定我们得到的局部最小值是否便是全局最小值(global minimum
),选择不同的初始参数组合,可能会找到不同的局部最小值。
批量梯度下降(
batch gradient descent
)算法的公式为:
其中
𝑎
是学习率(
learning rate
),它决定了我们沿着能让代价函数下降程度最大的方向
向下迈出的步子有多大,在批量梯度下降中,我们每一次都同时让所有的参数减去学习速率
乘以代价函数的导数
五,梯度下降的直观理解:
描述:对
𝜃
赋值,使得
𝐽(𝜃)
按梯度下降最快方向进行,一直迭代下去,最终得到局部最
小值。其中
𝑎
是学习率(
learning rate
),它决定了我们沿着能让代价函数下降程度最大的方
向向下迈出的步子有多大。
缺点
-
靠近极小值时收敛速度减慢。
-
直线搜索时可能会产生一些问题。
-
可能会“之字形”地下降。
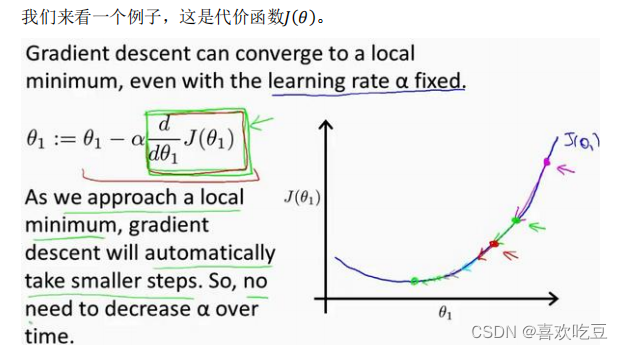
如果
𝑎
太小了,即我的学习速率太小,结果就是只能这样像小宝宝一样一点点地挪动,去努力接近最低点,这样就需要很多步才能到达最低点,所以如果𝑎
太小的话,可能会很慢,因为它会一点点挪动,它会需要很多步才能到达全局最低点。如果𝑎
太大,那么梯度下降法可能会越过最低点,甚至可能无法收敛,下一次迭代又移动了一大步,越过一次,又越过一次,一次次越过最低点,直到你发现实际上离最低点越来越远,所以,如果𝑎太大,它会导致无法收敛,甚至发散。
如果我们预先把
𝜃
1
放在一个局部的最低点,你认为下一步梯度下降法会怎样工作?
假设你将
𝜃
1
初始化在局部最低点,在这儿,它已经在一个局部的最优处或局部最低点。
结果是局部最优点的导数将等于零,因为它是那条切线的斜率。这意味着你已经在局部最优点,它使得𝜃
1
不再改变,也就是新的
𝜃
1
等于原来的
𝜃
1
,因此,如果你的参数已经处于局部最低点,那么梯度下降法更新其实什么都没做,它不会改变参数的值。这也解释了为什么即使学习速率𝑎
保持不变时,梯度下降也可以收敛到局部最低点
六,梯度下降的线性回归:
我们刚刚使用的算法,有时也称为批量梯度下降。实际上,在机器学习中,通常不太会给算法起名字,但这个名字”
批量梯度下降
”
,指的是在梯度下降的每一步中,我们都用到了所有的训练样本,在梯度下降中,在计算微分求导项时,我们需要进行求和运算,所以,在每一个单独的梯度下降中,我们最终都要计算这样一个东西,这个项需要对所有𝑚
个训练样本求和。因此,批量梯度下降法这个名字说明了我们需要考虑所有这一"
批
"
训练样本,而事实上,有时也有其他类型的梯度下降法,不是这种"
批量
"
型的,不考虑整个的训练集,而
每次只关注训练集中的一些小的子集。









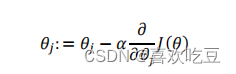


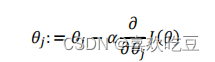


















 1150
1150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











