







52 | 算法实战(一):剖析Redis常用数据类型对应的数据结构
经典数据库 Redis 中的常用数据类型,底层都是用哪种数据结构实现的?
Redis 数据库介绍
Redis 是一种键值(Key-Value)数据库。相对于关系型数据库(比如 MySQL),Redis 也被叫作非关系型数据库。
像 MySQL 这样的关系型数据库,表的结构比较复杂,会包含很多字段,可以通过 SQL 语句,来实现非常复杂的查询需求。而 Redis 中只包含“键”和“值”两部分,只能通过“键”来查询“值”。正是因为这样简单的存储结构,也让 Redis 的读写效率非常高。
除此之外,Redis 主要是作为内存数据库来使用,也就是说,数据是存储在内存中的。尽管它经常被用作内存数据库,但是,它也支持将数据存储在硬盘中。
Redis 中,键的数据类型是字符串,但是为了丰富数据存储的方式,方便开发者使用,值的数据类型有很多,常用的数据类型有这样几种,它们分别是字符串、列表、字典、集合、有序集合。
“字符串”这种数据类型非常简单,对应到数据结构里,就是字符串。
列表(list)
列表这种数据类型支持存储一组数据。这种数据类型对应两种实现方法,一种是压缩列表(ziplist),另一种是双向循环链表。
当列表中存储的数据量比较小的时候,就可以采用压缩列表的方式。具体需要同时满足下面两个条件:
-
列表中保存的单个数据(有可能是字符串类型的)小于 64 字节;
-
列表中数据个数少于 512 个。
压缩列表并不是基础数据结构,而是 Redis 自己设计的一种数据存储结构。它有点儿类似数组,通过一片连续的内存空间,来存储数据。不过,它跟数组不同的一点是,它允许存储的数据大小不同。
听到“压缩”两个字,直观的反应就是节省内存。之所以说这种存储结构节省内存,是相较于数组的存储思路而言的。数组要求每个元素的大小相同,如果要存储不同长度的字符串,那就需要用最大长度的字符串大小作为元素的大小(假设是 20 个字节)。
压缩列表,一方面比较节省内存,另一方面可以支持不同类型数据的存储。而且,因为数据存储在一片连续的内存空间,通过键来获取值为列表类型的数据,读取的效率也非常高。
当列表中存储的数据量比较大的时候,列表就要通过双向循环链表来实现了。
Redis 的这种双向链表的实现方式,非常值得借鉴。它额外定义一个 list 结构体,来组织链表的首、尾指针,还有长度等信息。这样,在使用的时候就会非常方便。
// 以下是 C 语言代码,因为 Redis 是用 C 语言实现的。
typedef struct listnode {
struct listNode *prev;
struct listNode *next;
void *value;
} listNode;
typedef struct list {
listNode *head;
listNode *tail;
unsigned long len;
// .... 省略其他定义
} list;字典(hash)
字典类型用来存储一组数据对。每个数据对又包含键值两部分。字典类型也有两种实现方式。一种是压缩列表,另一种是散列表。
同样,只有当存储的数据量比较小的情况下,Redis 才使用压缩列表来实现字典类型。具体需要满足两个条件:
-
字典中保存的键和值的大小都要小于 64 字节;
-
字典中键值对的个数要小于 512 个。
当不能同时满足上面两个条件的时候,Redis 就使用散列表来实现字典类型。Redis 使用MurmurHash2这种运行速度快、随机性好的哈希算法作为哈希函数。对于哈希冲突问题,Redis 使用链表法来解决。除此之外,Redis 还支持散列表的动态扩容、缩容。
当数据动态增加之后,散列表的装载因子会不停地变大。为了避免散列表性能的下降,当装载因子大于 1 的时候,Redis 会触发扩容,将散列表扩大为原来大小的 2 倍左右。
当数据动态减少之后,为了节省内存,当装载因子小于 0.1 的时候,Redis 就会触发缩容,缩小为字典中数据个数的大约 2 倍大小。
扩容缩容要做大量的数据搬移和哈希值的重新计算,所以比较耗时。针对这个问题,Redis 使用渐进式扩容缩容策略,将数据的搬移分批进行,避免了大量数据一次性搬移导致的服务停顿。
集合(set)
集合这种数据类型用来存储一组不重复的数据。这种数据类型也有两种实现方法,一种是基于有序数组,另一种是基于散列表。
当要存储的数据,同时满足下面两个条件时,Redis 就采用有序数组,来实现集合这种数据类型。
-
存储的数据都是整数;
-
存储的数据元素个数不超过 512 个。
当不能同时满足这两个条件的时候,Redis 就使用散列表来存储集合中的数据。
有序集合(sortedset)
有序集合用来存储一组数据,并且每个数据会附带一个得分。通过得分的大小,将数据组织成跳表这样的数据结构,以支持快速地按照得分值、得分区间获取数据。
实际上,跟 Redis 的其他数据类型一样,有序集合也并不仅仅只有跳表这一种实现方式。当数据量比较小的时候,Redis 会用压缩列表来实现有序集合。
数据结构持久化
尽管 Redis 经常会被用作内存数据库,但是,它也支持数据落盘,也就是将内存中的数据存储到硬盘中。这样,当机器断电的时候,存储在 Redis 中的数据也不会丢失。在机器重新启动之后,Redis 只需要再将存储在硬盘中的数据,重新读取到内存,就可以继续工作了。
Redis 的数据格式由“键”和“值”两部分组成。而“值”又支持很多数据类型,比如字符串、列表、字典、集合、有序集合。像字典、集合等类型,底层用到了散列表,散列表中有指针的概念,而指针指向的是内存中的存储地址。 那 Redis 是如何将这样一个跟具体内存地址有关的数据结构存储到磁盘中的呢?
实际上,Redis 遇到的这个问题并不特殊,很多场景中都会遇到。我们把它叫作数据结构的持久化问题,或者对象的持久化问题。这里的“持久化”,可以笼统地可以理解为“存储到磁盘”。
如何将数据结构持久化到硬盘?主要有两种解决思路。
第一种是清除原有的存储结构,只将数据存储到磁盘中。当需要从磁盘还原数据到内存的时候,再重新将数据组织成原来的数据结构。实际上,Redis 采用的就是这种持久化思路。
不过,这种方式也有一定的弊端。那就是数据从硬盘还原到内存的过程,会耗用比较多的时间。比如,现在要将散列表中的数据存储到磁盘。当从磁盘中,取出数据重新构建散列表的时候,需要重新计算每个数据的哈希值。如果磁盘中存储的是几 GB 的数据,那重构数据结构的耗时就不可忽视了。
第二种方式是保留原来的存储格式,将数据按照原有的格式存储在磁盘中。拿散列表这样的数据结构来举例。可以将散列表的大小、每个数据被散列到的槽的编号等信息,都保存在磁盘中。有了这些信息,从磁盘中将数据还原到内存中的时候,就可以避免重新计算哈希值。
总结引申
Redis 中常用数据类型底层依赖的数据结构,大概有这五种:压缩列表(可以看作一种特殊的数组)、有序数组、链表、散列表、跳表。实际上,Redis 就是这些常用数据结构的封装。
课后思考
-
你有没有发现,在数据量比较小的情况下,Redis 中的很多数据类型,比如字典、有序集合等,都是通过多种数据结构来实现的,为什么这样设计呢?用一种固定的数据结构,不是更加简单吗?
-
redis的数据结构由多种数据结构来实现,主要是出于时间和空间的考虑,当数据量小的时候通过数组下标访问最快、占用内存最小,而压缩列表只是数组的升级版; 因为数组需要占用连续的内存空间,所以当数据量大的时候,就需要使用链表了,同时为了保证速度又需要和数组结合,也就有了散列表。 对于数据的大小和多少采用哪种数据结构,相信redis团队一定是根据大多数的开发场景而定的。
-
数据量小时采用连续内存的数据结构是为了CPU缓存读取连续内存来提高命中率,而限制数据数量和数据大小应该是考虑到CPU缓存的大小
-
压缩列表优点:访问存取快速,节省内存。但是受到操作系统空闲内存限制。越大的连续内存空间越不容易申请到。所以用了其他数据结构比如链表替代。
-
这个是因为每种数据结构都有适合自己的场景,比如压缩列表(特殊的有序数组)比较适合查询操作,删除新增的时间复杂度较高为O(n),数据量小的时候可以使用,因为结构简单,数据量大的时候删除新增的效率非常低;所以量大的时候要考虑增删改查都比较快的数据结构,比如散列表、跳表、二叉树、红黑树等等数据结构了
-
-
数据结构持久化有两种方法。对于二叉查找树这种数据结构,如何将它持久化到磁盘中呢?
-
二叉查找树的存储,我倾向于存储方式一,通过填充叶子节点形成完全二叉树,然后以数组的形式存储到硬盘,数据还原过程也是非常高效的。如果用存储方式二就比较复杂了。
-
二叉树可以通过前序+中序写入磁盘,之后通过前序+中序还原;或者类似于将堆的时候,将数据按层遍历存入数组中,从下标1开始存储,下标i的左右子树存储在(2i,2i+1)下标中,然后顺序写入磁盘,这个的缺点是会产生空洞,因为不一定是满二叉树
-
2.对于二叉树的持久化可以参考leetcode接口,采用数组即可。
-
-
压缩列表不支持随机访问。有点类似链表。但是比较省存储空间啊。Redis一般都是通过key获取整个value的值,也就是整个压缩列表的数据,并不需要随机访问。
53 | 算法实战(二):剖析搜索引擎背后的经典数据结构和算法
借助搜索引擎展示一下,数据结构和算法是如何应用在其中的。
整体系统介绍
如何在一台机器上(假设这台机器的内存是 8GB, 硬盘是 100 多 GB),通过少量的代码,实现一个小型搜索引擎。
搜索引擎大致可以分为四个部分:搜集、分析、索引、查询。其中,搜集,就是常说的利用爬虫爬取网页。分析,主要负责网页内容抽取、分词,构建临时索引,计算 PageRank 值这几部分工作。索引,主要负责通过分析阶段得到的临时索引,构建倒排索引。查询,主要负责响应用户的请求,根据倒排索引获取相关网页,计算网页排名,返回查询结果给用户。
搜集
搜索引擎是如何爬取网页的呢?
搜索引擎把整个互联网看作数据结构中的有向图,把每个页面看作一个顶点。如果某个页面中包含另外一个页面的链接,那就在两个顶点之间连一条有向边。可以利用图的遍历搜索算法,来遍历整个互联网中的网页。
图的遍历方法,深度优先和广度优先。搜索引擎采用的是广度优先搜索策略。具体点讲的话,那就是,先找一些比较知名的网页(专业的叫法是权重比较高)的链接(比如新浪主页网址、腾讯主页网址等),作为种子网页链接,放入到队列中。爬虫按照广度优先的策略,不停地从队列中取出链接,然后取爬取对应的网页,解析出网页里包含的其他网页链接,再将解析出来的链接添加到队列中。
搜集工程都有哪些关键技术细节。
1. 待爬取网页链接文件:links.bin
在广度优先搜索爬取页面的过程中,爬虫会不停地解析页面链接,将其放到队列中。于是,队列中的链接就会越来越多,可能会多到内存放不下。所以,用一个存储在磁盘中的文件(links.bin)来作为广度优先搜索中的队列。爬虫从 links.bin 文件中,取出链接去爬取对应的页面。等爬取到网页之后,将解析出来的链接,直接存储到 links.bin 文件中。
这样用文件来存储网页链接的方式,还有其他好处。比如,支持断点续爬。也就是说,当机器断电之后,网页链接不会丢失;当机器重启之后,还可以从之前爬取到的位置继续爬取。
关于如何解析页面获取链接,可以把整个页面看作一个大的字符串,利用字符串匹配算法,在这个大字符串中,搜索这样一个网页标签,然后顺序读取之间的字符串。这其实就是网页链接。
2. 网页判重文件:bloom_filter.bin
如何避免重复爬取相同的网页呢?这个问题在位图那一节已经讲过了。使用布隆过滤器,就可以快速并且非常节省内存地实现网页的判重。
如果把布隆过滤器存储在内存中,那机器宕机重启之后,布隆过滤器就被清空了。这样就可能导致大量已经爬取的网页会被重复爬取。
可以定期地(比如每隔半小时)将布隆过滤器持久化到磁盘中,存储在 bloom_filter.bin 文件中。这样,即便出现机器宕机,也只会丢失布隆过滤器中的部分数据。当机器重启之后,就可以重新读取磁盘中的 bloom_filter.bin 文件,将其恢复到内存中。
3. 原始网页存储文件:doc_raw.bin
爬取到网页之后,需要将其存储下来,以备后面离线分析、索引之用。那如何存储海量的原始网页数据呢?
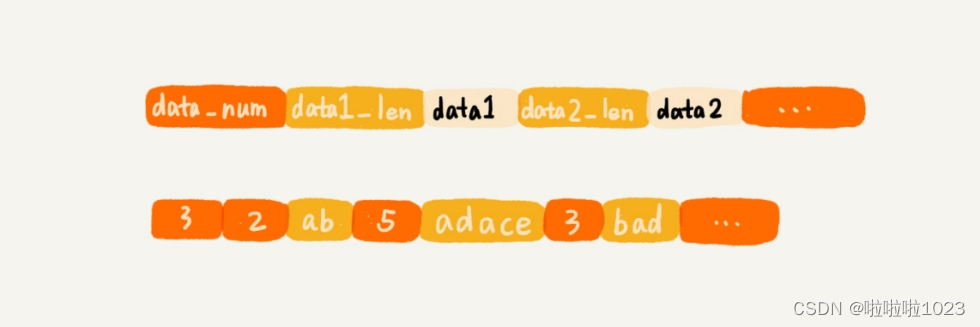
如果把每个网页都存储为一个独立的文件,那磁盘中的文件就会非常多,数量可能会有几千万,甚至上亿。常用的文件系统显然不适合存储如此多的文件。所以,可以把多个网页存储在一个文件中。每个网页之间,通过一定的标识进行分隔,方便后续读取。具体的存储格式,如下图所示。其中,doc_id 这个字段是网页的编号。

当然,这样的一个文件也不能太大,因为文件系统对文件的大小也有一定的限制。所以,可以设置每个文件的大小不能超过一定的值(比如 1GB)。随着越来越多的网页被添加到文件中,文件的大小就会越来越大,当超过 1GB 的时候,就创建一个新的文件,用来存储新爬取的网页。
4. 网页链接及其编号的对应文件:doc_id.bin
网页编号实际上就是给每个网页分配一个唯一的 ID,方便我们后续对网页进行分析、索引。那如何给网页编号呢?
可以按照网页被爬取的先后顺序,从小到大依次编号。具体是这样做的:维护一个中心的计数器,每爬取到一个网页之后,就从计数器中拿一个号码,分配给这个网页,然后计数器加一。在存储网页的同时,将网页链接跟编号之间的对应关系,存储在另一个 doc_id.bin 文件中。
爬虫在爬取网页的过程中,涉及的四个重要的文件,其中,links.bin 和 bloom_filter.bin 这两个文件是爬虫自身所用的。另外的两个(doc_raw.bin、doc_id.bin)是作为搜集阶段的成果,供后面的分析、索引、查询用的。
分析
网页爬取下来之后,需要对网页进行离线分析。分析阶段主要包括两个步骤,第一个是抽取网页文本信息,第二个是分词并创建临时索引。
1. 抽取网页文本信息
网页是半结构化数据,里面夹杂着各种标签、JavaScript 代码、CSS 样式。对于搜索引擎来说,它只关心网页中的文本信息,也就是,网页显示在浏览器中时,能被用户肉眼看到的那部分信息。如何从半结构化的网页中,抽取出搜索引擎关系的文本信息呢?
之所以把网页叫作半结构化数据,是因为它本身是按照一定的规则来书写的。这个规则就是HTML 语法规范。依靠 HTML 标签来抽取网页中的文本信息。这个抽取的过程,大体可以分为两步。
第一步是去掉 JavaScript 代码、CSS 格式以及下拉框中的内容(因为下拉框在用户不操作的情况下,也是看不到的)。也就是<style></style>,<script></script>,<option></option>这三组标签之间的内容。可以利用 AC 自动机这种多模式串匹配算法,在网页这个大字符串中,一次性查找<style>, <script>, <option>这三个关键词。当找到某个关键词出现的位置之后,只需要依次往后遍历,直到对应结束标签(</style>, </script>, </option)为止。而这期间遍历到的字符串连带着标签就应该从网页中删除。
第二步是去掉所有 HTML 标签。这一步也是通过字符串匹配算法来实现的。过程跟第一步类似。
2. 分词并创建临时索引
经过上面的处理之后,就从网页中抽取出了文本信息。接下来,要对文本信息进行分词,并且创建临时索引。
对于英文网页来说,分词非常简单。只需要通过空格、标点符号等分隔符,将每个单词分割开来就可以了。但是,对于中文来说,分词就复杂太多了。这里介绍一种比较简单的思路,基于字典和规则的分词方法。
其中,字典也叫词库,里面包含大量常用的词语(可以直接从网上下载别人整理好的)。借助词库并采用最长匹配规则,来对文本进行分词。所谓最长匹配,也就是匹配尽可能长的词语。
每个网页的文本信息在分词完成之后,都得到一组单词列表。把单词与网页之间的对应关系,写入到一个临时索引文件中(tmp_Index.bin),这个临时索引文件用来构建倒排索引文件。临时索引文件的格式如下:

在临时索引文件中,存储的是单词编号,也就是图中的 term_id,而非单词本身。这样做的目的主要是为了节省存储的空间。那这些单词的编号是怎么来的呢?
给单词编号的方式,跟给网页编号类似。维护一个计数器,每当从网页文本信息中分割出一个新的单词的时候,就从计数器中取一个编号,分配给它,然后计数器加一。
在这个过程中,还需要使用散列表,记录已经编过号的单词。在对网页文本信息分词的过程中,拿分割出来的单词,先到散列表中查找,如果找到,那就直接使用已有的编号;如果没有找到,再去计数器中拿号码,并且将这个新单词以及编号添加到散列表中。
当所有的网页处理(分词及写入临时索引)完成之后,再将这个单词跟编号之间的对应关系,写入到磁盘文件中,并命名为 term_id.bin。
经过分析阶段,得到了临时索引文件(tmp_index.bin)和单词编号文件(term_id.bin)。
索引
索引阶段主要负责将分析阶段产生的临时索引,构建成倒排索引。倒排索引( Inverted index)中记录了每个单词以及包含它的网页列表。

在临时索引文件中,记录的是单词跟每个包含它的文档之间的对应关系。那如何通过临时索引文件,构建出倒排索引文件呢?
解决这个问题的方法有很多。考虑到临时索引文件很大,无法一次性加载到内存中,搜索引擎一般会选择使用多路归并排序的方法来实现。
先对临时索引文件,按照单词编号的大小进行排序。因为临时索引很大,所以一般基于内存的排序算法就没法处理这个问题了。可以归并排序的处理思想,将其分割成多个小文件,先对每个小文件独立排序,最后再合并在一起。当然,实际的软件开发中,其实可以直接利用 MapReduce 来处理。
临时索引文件排序完成之后,相同的单词就被排列到了一起。只需要顺序地遍历排好序的临时索引文件,就能将每个单词对应的网页编号列表找出来,然后把它们存储在倒排索引文件中。
除了倒排文件之外,还需要一个文件,来记录每个单词编号在倒排索引文件中的偏移位置。把这个文件命名为 term_offset.bin。这个文件的作用是,帮助快速地查找某个单词编号在倒排索引中存储的位置,进而快速地从倒排索引中读取单词编号对应的网页编号列表。

经过索引阶段的处理,我们得到了两个有价值的文件,它们分别是倒排索引文件(index.bin)和记录单词编号在索引文件中的偏移位置的文件(term_offset.bin)。
查询
前面三个阶段的处理,只是为了最后的查询做铺垫。因此,现在就要利用之前产生的几个文件,来实现最终的用户搜索功能。
-
doc_id.bin:记录网页链接和编号之间的对应关系。
-
term_id.bin:记录单词和编号之间的对应关系。
-
index.bin:倒排索引文件,记录每个单词编号以及对应包含它的网页编号列表。
-
term_offsert.bin:记录每个单词编号在倒排索引文件中的偏移位置。
这四个文件中,除了倒排索引文件(index.bin)比较大之外,其他的都比较小。为了方便快速查找数据,将其他三个文件都加载到内存中,并且组织成散列表这种数据结构。
当用户在搜索框中,输入某个查询文本的时候,先对用户输入的文本进行分词处理。假设分词之后,得到 k 个单词。
拿这 k 个单词,去 term_id.bin 对应的散列表中,查找对应的单词编号。经过这个查询之后,得到了这 k 个单词对应的单词编号。
拿这 k 个单词编号,去 term_offset.bin 对应的散列表中,查找每个单词编号在倒排索引文件中的偏移位置。经过这个查询之后,得到了 k 个偏移位置。
拿这 k 个偏移位置,去倒排索引(index.bin)中,查找 k 个单词对应的包含它的网页编号列表。经过这一步查询之后,得到了 k 个网页编号列表。
针对这 k 个网页编号列表,统计每个网页编号出现的次数。具体到实现层面,可以借助散列表来进行统计。统计得到的结果,按照出现次数的多少,从小到大排序。出现次数越多,说明包含越多的用户查询单词(用户输入的搜索文本,经过分词之后的单词)。
经过这一系列查询,就得到了一组排好序的网页编号。拿着网页编号,去 doc_id.bin 文件中查找对应的网页链接,分页显示给用户就可以了。
总结引申
这只是一个搜索引擎设计的基本原理,有很多优化、细节并未涉及,比如计算网页权重的PageRank算法、计算查询结果排名的tf-idf模型等等。
在讲解的过程中,涉及的数据结构和算法有:图、散列表、Trie 树、布隆过滤器、单模式字符串匹配算法、AC 自动机、广度优先遍历、归并排序等。
课后思考
-
图的遍历方法有两种,深度优先和广度优先。搜索引擎中的爬虫是通过广度优先策略来爬取网页的。搜索引擎为什么选择广度优先策略,而不是深度优先策略呢?
-
网络是动态变化的,所以爬虫的任务是在有限的时间里,爬到尽可能多的最重要的网页,而重要的网页一般是首页及其直接链接的网页。这样从首页开始一层层遍历更满足要求,尤其是在资源紧张的时候。所以BFS更适合。起码在大的调度次序上是这样。但在工程上要考虑网络通讯中“握手”次数过于频繁的问题,调度算法的具体实现细节会吸取DFS的优点。
-
因为搜索引擎要优先爬取权重较高的页面,离种子网页越近,较大可能权重更高,广度优先更合适。
-
深度优化借助栈这种数据结构,网页的深度是不可预测的,如果很深,栈大小会很大,内存可能会爆掉。
-
-
大部分搜索引擎在结果显示的时候,都支持摘要信息和网页快照。实际上,你只需要对我今天讲的设计思路,稍加改造,就可以支持这两项功能。你知道如何改造吗?
-
摘要信息: 增加 summary.bin 和 summary_offset.bin。在抽取网页文本信息后,取出前 80-160 个字作为摘要,写入到 summary.bin,并将偏移位置写入到 summary_offset.bin。 summary.bin 格式: doc_id \t summary_size \t summary \r\n\r\n summary_offset.bin 格式: doc_id \t offset \r\n Google 搜索结果中显示的摘要是搜索词附近的文本。如果要实现这种效果,可以保存全部网页文本,构建搜索结果时,在网页文本中查找搜索词位置,截取搜索词附近文本。
-
网页快照: 可以把 doc_raw.bin 当作快照,增加 doc_raw_offset.bin 记录 doc_id 在 doc_raw.bin 中的偏移位置。 doc_raw_offset.bin 格式: doc_id \t offset \r\n
-
正排-》文档包含哪些单词 倒排-》单词被哪些文档包含
搜集:将广度优先搜索的优先队列存储在磁盘文件links.bin(如何解析网页内的链接?),有布隆过滤器判重并定期写入磁盘文件bloom_filter.bin,将访问到的原始网页数据存入磁盘文件doc_raw.bin,计数分配网页编号并与其链接对应关系存入磁盘文件doc_id.bin。
分析:首先抽取网页文本信息,依据HTML语法规范,通过AC自动机多模式串匹配算法,去除网页中格式化部分,提取文本内容。然后分词并创建临时索引,分词的目的是找到能够标识网页文本“身份”的特征,可借助词库(通过Trie树实现)搜索文本中与词库匹配的最长词语,因为一般情况下越长信息越多,越具有表征能力(为什么英文简单?)。分词完成后得到一组用于表征网页的单词列表,与其对应的网页编号存入磁盘文件tmp_index.bin作为临时索引,为节省空间单词是以单词编号的形式写入,单词文本与编号的对应关系写入磁盘文本term_id.bin。
索引:通过临时索引构建倒排索引文件index.bin。倒排索引其实是以单词为主键,将临时索引中的多个相同单词行合并为一行。通过以单词为主键的排序算法,可以将相同单词的行连续排列在一起,之后只要将单词相同的连续行合并为一行即可。由于数据量大,应采用分治策略。最后建立所有单词在倒排索引文件中位置的索引文件term_offset.bin,以方便快速查找。
查询:先对搜索条件文本做分词处理,然后去term_id.bin查单词们的编号,再查term_offset.bin找到单词们在倒排索引中的位置,到index.bin找到每个单词对应的网页编号,通过网页出现次数、预评权重和统计算法(如pagerank、tf-idf)计算网页的优先次序并输出。最后在doc_in.bin中找到网页链接按序输出显示给用户。
54 | 算法实战(三):剖析高性能队列Disruptor背后的数据结构和算法
Disruptor 是一种内存消息队列。从功能上讲,它其实有点儿类似 Kafka。不过,和 Kafka 不同的是,Disruptor 是线程之间用于消息传递的队列。它在 Apache Storm、Camel、Log4j 2 等很多知名项目中都有广泛应用。
之所以如此受青睐,主要还是因为它的性能表现非常优秀。它比 Java 中另外一个非常常用的内存消息队列 ArrayBlockingQueue(ABS)的性能,要高一个数量级,可以算得上是最快的内存消息队列了。它还因此获得过 Oracle 官方的 Duke 大奖。
Disruptor 是如何做到如此高性能的?其底层依赖了哪些数据结构和算法?
基于循环队列的“生产者 - 消费者模型”
什么是内存消息队列?“生产者 - 消费者模型”,在这个模型中,“生产者”生产数据,并且将数据放到一个中心存储容器中。之后,“消费者”从中心存储容器中,取出数据消费。
这里面存储数据的中心存储容器,是用什么样的数据结构来实现的呢?
实际上,实现中心存储容器最常用的一种数据结构,就是队列。队列支持数据的先进先出。正是这个特性,使得数据被消费的顺序性可以得到保证,也就是说,早被生产的数据就会早被消费。
队列有两种实现思路。一种是基于链表实现的链式队列,另一种是基于数组实现的顺序队列。不同的需求背景下,会选择不同的实现方式。
如果要实现一个无界队列,队列的大小事先不确定,理论上可以支持无限大。这种情况下,选用链表来实现队列。因为链表支持快速地动态扩容。如果要实现一个有界队列,队列的大小事先确定,当队列中数据满了之后,生产者就需要等待。直到消费者消费了数据,队列有空闲位置的时候,生产者才能将数据放入。
相较于无界队列,有界队列的应用场景更加广泛。毕竟,机器内存是有限的。而无界队列占用的内存数量是不可控的。对于实际的软件开发来说,这种不可控的因素,就会有潜在的风险。在某些极端情况下,无界队列就有可能因为内存持续增长,而导致 OOM(Out of Memory)错误。
非循环的顺序队列在添加、删除数据的工程中,会涉及数据的搬移操作,导致性能变差。而循环队列正好可以解决这个数据搬移的问题,所以,性能更加好。所以,大部分用到顺序队列的场景中都选择用顺序队列中的循环队列。
实际上,循环队列这种数据结构,就是内存消息队列的雏形。
对于生产者和消费者之间操作的同步,并没有用到线程相关的操作。而是采用了“当队列满了之后,生产者就轮训等待;当队列空了之后,消费者就轮训等待”这样的措施。
public class Queue {
private Long[] data;
private int size = 0, head = 0, tail = 0;
public Queue(int size) {
this.data = new Long[size];
this.size = size;
}
public boolean add(Long element) {
if ((tail + 1) % size == head) return false;
data[tail] = element;
tail = (tail + 1) % size;
return true;
}
public Long poll() {
if (head == tail) return null;
long ret = data[head];
head = (head + 1) % size;
return ret;
}
}
public class Producer {
private Queue queue;
public Producer(Queue queue) {
this.queue = queue;
}
public void produce(Long data) throws InterruptedException {
while (!queue.add(data)) {
Thread.sleep(100);
}
}
}
public class Consumer {
private Queue queue;
public Consumer(Queue queue) {
this.queue = queue;
}
public void comsume() throws InterruptedException {
while (true) {
Long data = queue.poll();
if (data == null) {
Thread.sleep(100);
} else {
// TODO:... 消费数据的业务逻辑...
}
}
}
}基于加锁的并发“生产者 - 消费者模型”
实际上,刚刚的“生产者 - 消费者模型”实现代码,是不完善的。为什么这么说呢?
如果只有一个生产者往队列中写数据,一个消费者从队列中读取数据,那上面的代码是没有问题的。但是,如果有多个生产者在并发地往队列中写入数据,或者多个消费者并发地从队列中消费数据,那上面的代码就不能正确工作了。
在多个生产者或者多个消费者并发操作队列的情况下,刚刚的代码主要会有下面两个问题:
-
多个生产者写入的数据可能会互相覆盖;
-
多个消费者可能会读取重复的数据。
第一个问题和第二个问题产生的原理是类似的。
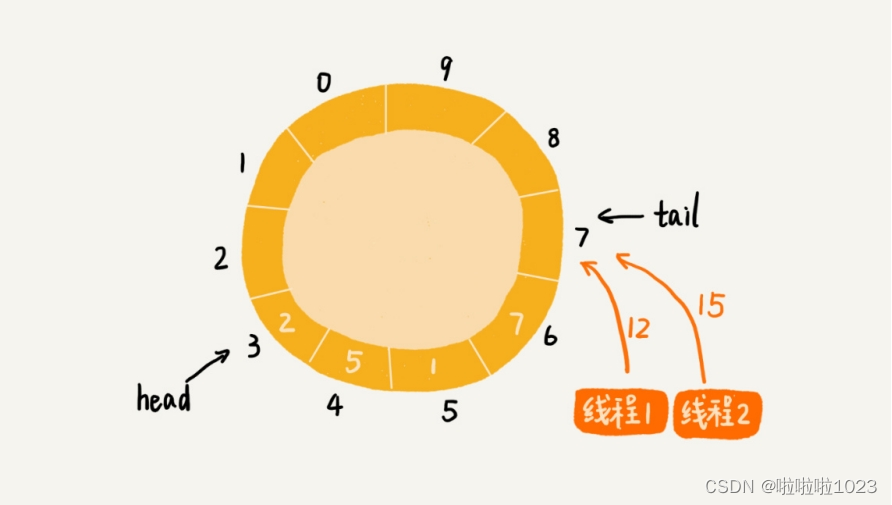
两个线程同时往队列中添加数据,也就相当于两个线程同时执行类 Queue 中的 add() 函数。假设队列的大小 size 是 10,当前的 tail 指向下标 7,head 指向下标 3,也就是说,队列中还有空闲空间。这个时候,线程 1 调用 add() 函数,往队列中添加一个值为 12 的数据;线程 2 调用 add() 函数,往队列中添加一个值为 15 的数据。在极端情况下,本来是往队列中添加了两个数据(12 和 15),最终可能只有一个数据添加成功,另一个数据会被覆盖。这是为什么呢?
public boolean add(Long element) {
if ((tail + 1) % size == head) return false;
data[tail] = element;
tail = (tail + 1) % size;
return true;
}从代码中,可以看到,第 3 行给 data[tail] 赋值,然后第 4 行才给 tail 的值加一。赋值和 tail 加一两个操作,并非原子操作。这就会导致这样的情况发生:当线程 1 和线程 2 同时执行 add() 函数的时候,线程 1 先执行完了第 3 行语句,将 data[7](tail 等于 7)的值设置为 12。在线程 1 还未执行到第 4 行语句之前,也就是还未将 tail 加一之前,线程 2 执行了第 3 行语句,又将 data[7] 的值设置为 15,也就是说,那线程 2 插入的数据覆盖了线程 1 插入的数据。原本应该插入两个数据(12 和 15)的,现在只插入了一个数据(15)。
那如何解决这种线程并发往队列中添加数据时,导致的数据覆盖、运行不正确问题呢?
最简单的处理方法就是给这段代码加锁,同一时间只允许一个线程执行 add() 函数。这就相当于将这段代码的执行,由并行改成了串行,也就不存在刚刚说的问题了。
不过,加锁将并行改成串行,必然导致多个生产者同时生产数据的时候,执行效率的下降。当然,可以继续优化代码,用CAS(compare and swap,比较并交换)操作等减少加锁的粒度,但是,这不是这节的重点。直接看 Disruptor 的处理方法。
基于无锁的并发“生产者 - 消费者模型”
尽管 Disruptor 的源码读起来很复杂,但是基本思想其实非常简单。实际上,它是换了一种队列和“生产者 - 消费者模型”的实现思路。
之前的实现思路中,队列只支持两个操作,添加数据和读取并移除数据,分别对应代码中的 add() 函数和 poll() 函数,而 Disruptor 采用了另一种实现思路。
对于生产者来说,它往队列中添加数据之前,先申请可用空闲存储单元,并且是批量地申请连续的 n 个(n≥1)存储单元。当申请到这组连续的存储单元之后,后续往队列中添加元素,就可以不用加锁了,因为这组存储单元是这个线程独享的。不过,申请存储单元的过程是需要加锁的。
对于消费者来说,处理的过程跟生产者是类似的。它先去申请一批连续可读的存储单元(这个申请的过程也是需要加锁的),当申请到这批存储单元之后,后续的读取操作就可以不用加锁了。
如果生产者 A 申请到了一组连续的存储单元,假设是下标为 3 到 6 的存储单元,生产者 B 紧跟着申请到了下标是 7 到 9 的存储单元,那在 3 到 6 没有完全写入数据之前,7 到 9 的数据是无法读取的。这个也是 Disruptor 实现思路的一个弊端。
实际上,Disruptor 采用的是 RingBuffer 和 AvailableBuffer 这两个结构,来实现功能。
总结引申
如何实现一个高性能的并发队列。这里的“并发”两个字,实际上就是多线程安全的意思。
常见的内存队列往往采用循环队列来实现。这种实现方法,对于只有一个生产者和一个消费者的场景,已经足够了。但是,当存在多个生产者或者多个消费者的时候,单纯的循环队列的实现方式,就无法正确工作了。
这主要是因为,多个生产者在同时往队列中写入数据的时候,在某些情况下,会存在数据覆盖的问题。而多个消费者同时消费数据,在某些情况下,会存在消费重复数据的问题。
针对这个问题,最简单、暴力的解决方法就是,对写入和读取过程加锁。这种处理方法,相当于将原来可以并行执行的操作,强制串行执行,相应地就会导致操作性能的下降。
为了在保证逻辑正确的前提下,尽可能地提高队列在并发情况下的性能,Disruptor 采用了“两阶段写入”的方法。在写入数据之前,先加锁申请批量的空闲存储单元,之后往队列中写入数据的操作就不需要加锁了,写入的性能因此就提高了。Disruptor 对消费过程的改造,跟对生产过程的改造是类似的。它先加锁申请批量的可读取的存储单元,之后从队列中读取数据的操作也就不需要加锁了,读取的性能因此也就提高了。
课后思考
为了提高存储性能,往往通过分库分表的方式设计数据库表。假设有 8 张表用来存储用户信息。这个时候,每张用户表中的 ID 字段就不能通过自增的方式来产生了。因为这样的话,就会导致不同表之间的用户 ID 值重复。
为了解决这个问题,需要实现一个 ID 生成器,可以为所有的用户表生成唯一的 ID 号。那现在问题是,如何设计一个高性能、支持并发的、能够生成全局唯一 ID 的 ID 生成器呢?
-
1)分库分表也可以使用自增主键,可以设置增加的步长。8台机器分别从1、2、3。。开始,步长8. 从1开始的下一个id是9,与其他的不重复就可以了。 2)redis或者zk应该也能生成自增主键,不过他们的写性能可能不能支持真正的高并发。 3)开放独立的id生成服务。最有名的算法应该是snowflake吧。snowflake的好处是基本有序,每秒钟可以生成很大的量,容易水平扩展。 也可以把今天的disrupt用上,用自己生成id算法,提前生成id存入disrupt,预估一下峰值时业务需要的id量,比如提前生成50万;
-
加锁批量生成ID,使用时就不用加锁了
-
disruptor使用环的数据结构,内存连续,初始化时就申请并设置对象,将原本队列的头尾节点锁的争用转化为cas操作,并利用Java对象填充,解决cache line伪共享问题
-
__sync_fetch_and_add操作即可实现原子自增的操作。
-
项目中有使用过分布式id生成器,但是不知道具体是怎么实现的,参考今天的Disruptor的思路: \1. id生成器相当于一个全局的生产者,可以提前生成一批id \2. 对于每一张表,可以类似于Disruptor的消费者思路,从id生成器中申请一批id,用作当前表的id使用,当然申请一批id对于id生成器来说是需要加锁操作的
-
雪花算法可以根据不同机子生成不同的id
-
1.最简单的办法就是加锁,但这样就不支持并发。 2.将所有生成唯一Id的请求放入队列中,队列每次取出数据来产生Id,优点是不需要加锁。缺点是不支持并发。
3.不同步长的自增主键还是会重复的,应该是使用唯一ID生成器将生成好的ID放到Disruptor中,之后8个以加锁申请之后读取的方式获取相应的ID。
55 | 算法实战(四):剖析微服务接口鉴权限流背后的数据结构和算法
微服务就是把复杂的大应用,解耦拆分成几个小的应用。这样做的好处有很多。比如,这样有利于团队组织架构的拆分;再比如,每个应用都可以独立运维,独立扩容,独立上线,各个应用之间互不影响。不用像原来那样,一个小功能上线,整个大应用都要重新发布。
不过,大应用拆分成微服务之后,服务之间的调用关系变得更复杂,平台的整体复杂熵升高,出错的概率、debug 问题的难度都高了好几个数量级。所以,为了解决这些问题,服务治理便成了微服务的一个技术重点。
所谓服务治理,就是管理微服务,保证平台整体正常、平稳地运行。服务治理涉及的内容比较多,比如鉴权、限流、降级、熔断、监控告警等等。这些服务治理功能的实现,底层依赖大量的数据结构和算法。拿其中的鉴权和限流这两个功能,来看看它们的实现过程中都要用到哪些数据结构和算法。
鉴权背景介绍
假设有一个微服务叫用户服务(User Service)。它提供很多用户相关的接口,比如获取用户信息、注册、登录等,给公司内部的其他应用使用。但是,并不是公司内部所有应用,都可以访问这个用户服务,也并不是每个有访问权限的应用,都可以访问用户服务的所有接口。
这里面,只有 A、B、C、D 四个应用可以访问用户服务,并且每个应用只能访问用户服务的部分接口。
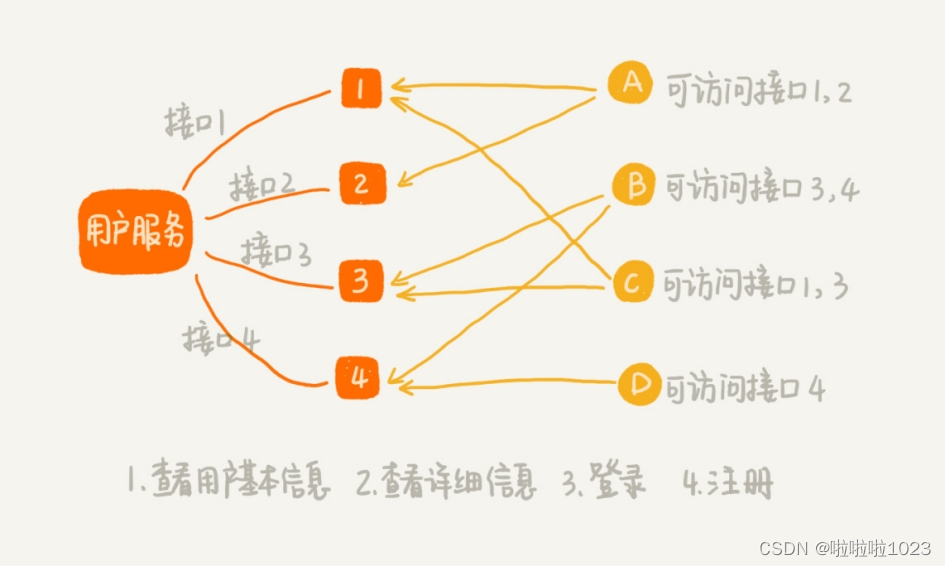
要实现接口鉴权功能,需要事先将应用对接口的访问权限规则设置好。当某个应用访问其中一个接口的时候,就可以拿应用的请求 URL,在规则中进行匹配。如果匹配成功,就说明允许访问;如果没有可以匹配的规则,那就说明这个应用没有这个接口的访问权限,就拒绝服务。
如何实现快速鉴权?
接口的格式有很多,有类似 Dubbo 这样的 RPC 接口,也有类似 Spring Cloud 这样的 HTTP 接口。不同接口的鉴权实现方式是类似的,这里主要拿 HTTP 接口讲解。
鉴权的原理比较简单、好理解。那具体到实现层面,该用什么数据结构来存储规则呢?用户请求 URL 在规则中快速匹配,又该用什么样的算法呢?
实际上,不同的规则和匹配模式,对应的数据结构和匹配算法也是不一样的。
1. 如何实现精确匹配规则?
最简单的一种匹配模式。只有当请求 URL 跟规则中配置的某个接口精确匹配时,这个请求才会被接受、处理。
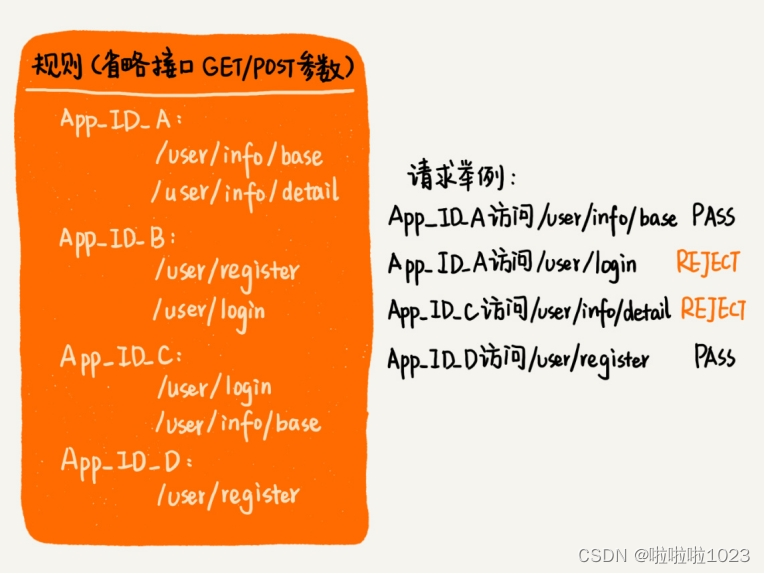
不同的应用对应不同的规则集合。可以采用散列表来存储这种对应关系。每个应用对应的规则集合,该如何存储和匹配。
针对这种匹配模式,可以将每个应用对应的权限规则,存储在一个字符串数组中。当用户请求到来时,拿用户的请求 URL,在这个字符串数组中逐一匹配,匹配的算法就是字符串匹配算法(比如 KMP、BM、BF 等)。
规则不会经常变动,所以,为了加快匹配速度,可以按照字符串的大小给规则排序,把它组织成有序数组这种数据结构。当要查找某个 URL 能否匹配其中某条规则的时候,可以采用二分查找算法,在有序数组中进行匹配。
而二分查找算法的时间复杂度是 O(logn)(n 表示规则的个数),这比起时间复杂度是 O(n) 的顺序遍历快了很多。对于规则中接口长度比较长,并且鉴权功能调用量非常大的情况,这种优化方法带来的性能提升还是非常可观的 。
2. 如何实现前缀匹配规则?
只要某条规则可以匹配请求 URL 的前缀,就说这条规则能够跟这个请求 URL 匹配。

不同的应用对应不同的规则集合。采用散列表来存储这种对应关系。每个应用的规则集合,最适合用什么样的数据结构来存储。
Trie 树非常适合用来做前缀匹配。所以,针对这个需求,可以将每个用户的规则集合,组织成 Trie 树这种数据结构。
不过,Trie 树中的每个节点不是存储单个字符,而是存储接口被“/”分割之后的子目录(比如“/user/name”被分割为“user”“name”两个子目录)。因为规则并不会经常变动,所以,在 Trie 树中,可以把每个节点的子节点们,组织成有序数组这种数据结构。当在匹配的过程中,可以利用二分查找算法,决定从一个节点应该跳到哪一个子节点。
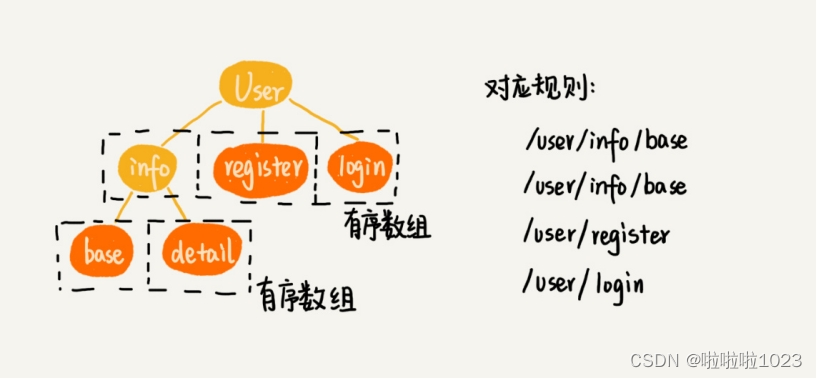
3. 如何实现模糊匹配规则?
如果规则更加复杂,规则中包含通配符,比如“ * * ”表示匹配任意多个子目录,“*”表示匹配任意一个子目录。只要用户请求 URL 可以跟某条规则模糊匹配,就说这条规则适用于这个请求。

不同的应用对应不同的规则集合。还是采用散列表来存储这种对应关系。每个用户对应的规则集合,该用什么数据结构来存储?针对这种包含通配符的模糊匹配,又该使用什么算法来实现呢?
可以借助正则表达式那个例子的解决思路,来解决这个问题。采用回溯算法,拿请求 URL 跟每条规则逐一进行模糊匹配。
不过,这个解决思路的时间复杂度是非常高的。需要拿每一个规则,跟请求 URL 匹配一遍。
实际上,可以结合实际情况,挖掘出这样一个隐形的条件,那就是,并不是每条规则都包含通配符,包含通配符的只是少数。于是,可以把不包含通配符的规则和包含通配符的规则分开处理。
把不包含通配符的规则,组织成有序数组或者 Trie 树(具体组织成什么结构,视具体的需求而定,是精确匹配,就组织成有序数组,是前缀匹配,就组织成 Trie 树),而这一部分匹配就会非常高效。剩下的是少数包含通配符的规则,只要把它们简单存储在一个数组中就可以了。尽管匹配起来会比较慢,但是毕竟这种规则比较少,所以这种方法也是可以接受的。
当接收到一个请求 URL 之后,可以先在不包含通配符的有序数组或者 Trie 树中查找。如果能够匹配,就不需要继续在通配符规则中匹配了;如果不能匹配,就继续在通配符规则中查找匹配。
限流背景介绍
所谓限流,顾名思义,就是对接口调用的频率进行限制。比如每秒钟不能超过 100 次调用,超过之后,就拒绝服务。限流的原理听起来非常简单,但它在很多场景中,发挥着重要的作用。比如在秒杀、大促、双 11、618 等场景中,限流已经成为了保证系统平稳运行的一种标配的技术解决方案。
按照不同的限流粒度,限流可以分为很多种类型。比如给每个接口限制不同的访问频率,或者给所有接口限制总的访问频率,又或者更细粒度地限制某个应用对某个接口的访问频率等等。
主要针对限制所有接口总的访问频率这样一个限流需求来讲解。
如何实现精准限流?
最简单的限流算法叫固定时间窗口限流算法。首先需要选定一个时间起点,之后每当有接口请求到来,就将计数器加一。如果在当前时间窗口内,根据限流规则(比如每秒钟最大允许 100 次访问请求),出现累加访问次数超过限流值的情况时,就拒绝后续的访问请求。当进入下一个时间窗口之后,计数器就清零重新计数。
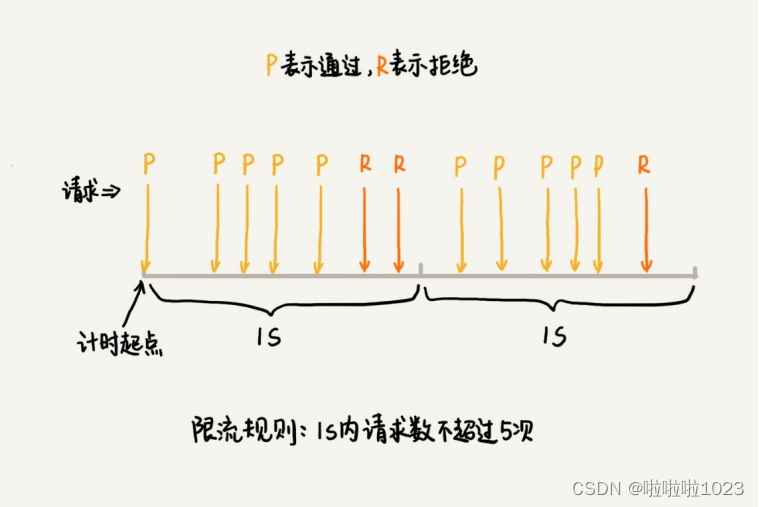
这种基于固定时间窗口的限流算法的缺点是,限流策略过于粗略,无法应对两个时间窗口临界时间内的突发流量。这是怎么回事呢?
假设限流规则是,每秒钟不能超过 100 次接口请求。第一个 1s 时间窗口内,100 次接口请求都集中在最后 10ms 内。在第二个 1s 的时间窗口内,100 次接口请求都集中在最开始的 10ms 内。虽然两个时间窗口内流量都符合限流要求(≤100 个请求),但在两个时间窗口临界的 20ms 内,会集中有 200 次接口请求。固定时间窗口限流算法并不能对这种情况做限制,所以,集中在这 20ms 内的 200 次请求就有可能压垮系统。
为了解决这个问题,可以对固定时间窗口限流算法稍加改造。可以限制任意时间窗口内,接口请求数都不能超过某个阈值。因此,相对于固定时间窗口限流算法,这个算法叫滑动时间窗口限流算法。
流量经过滑动时间窗口限流算法整形之后,可以保证任意一个 1s 的时间窗口内,都不会超过最大允许的限流值,从流量曲线上来看会更加平滑。那具体到实现层面,该如何来做呢?
假设限流的规则是,在任意 1s 内,接口的请求次数都不能大于 K 次。就维护一个大小为 K+1 的循环队列,用来记录 1s 内到来的请求。注意,这里循环队列的大小等于限流次数加一,因为循环队列存储数据时会浪费一个存储单元。
当有新的请求到来时,将与这个新请求的时间间隔超过 1s 的请求,从队列中删除。然后,再来看循环队列中是否有空闲位置。如果有,则把新请求存储在队列尾部(tail 指针所指的位置);如果没有,则说明这 1 秒内的请求次数已经超过了限流值 K,所以这个请求被拒绝服务。
为了方便你理解,我举一个例子,给你解释一下。在这个例子中,我们假设限流的规则是,任意 1s 内,接口的请求次数都不能大于 6 次。
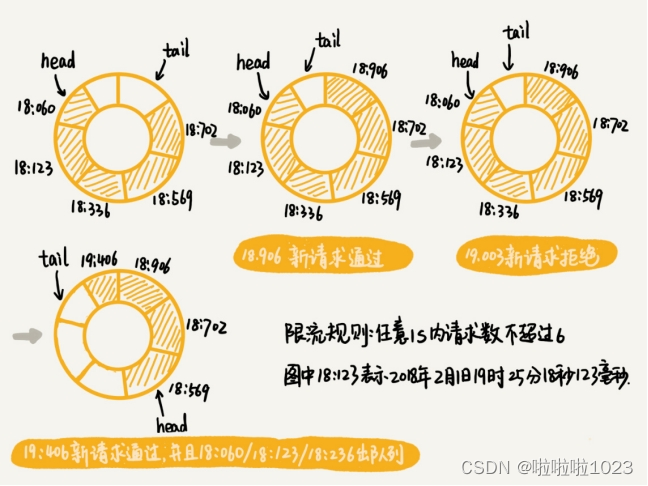
即便滑动时间窗口限流算法可以保证任意时间窗口内,接口请求次数都不会超过最大限流值,但是仍然不能防止,在细时间粒度上访问过于集中的问题。
基于时间窗口的限流算法,不管是固定时间窗口还是滑动时间窗口,只能在选定的时间粒度上限流,对选定时间粒度内的更加细粒度的访问频率不做限制。
实际上,针对这个问题,还有很多更加平滑的限流算法,比如令牌桶算法、漏桶算法等。
总结引申
关于鉴权,有三种不同的规则匹配模式。不管是哪种匹配模式,都可以用散列表来存储不同应用对应的不同规则集合。对于每个应用的规则集合的存储,三种匹配模式使用不同的数据结构。
对于第一种精确匹配模式,有序数组来存储每个应用的规则集合,并且通过二分查找和字符串匹配算法,来匹配请求 URL 与规则。对于第二种前缀匹配模式,利用 Trie 树来存储每个应用的规则集合。对于第三种模糊匹配模式,采用普通的数组来存储包含通配符的规则,通过回溯算法,来进行请求 URL 与规则的匹配。
关于限流,有两种限流算法,第一种是固定时间窗口限流算法,第二种是滑动时间窗口限流算法。对于滑动时间窗口限流算法,用了循环队列来实现。比起固定时间窗口限流算法,它对流量的整形效果更好,流量更加平滑。
课后思考
-
除了用循环队列来实现滑动时间窗口限流算法之外,是否还可以用其他数据结构来实现呢?请对比一下这些数据结构跟循环队列在解决这个问题时的优劣之处。
-
还可以采用双向链表,每次请求往链表尾插入一个时间,插入之前先从链表头删除一秒之前的节点,之后看下链表的size是否大于等于N,大于等于N则拒绝本次访问,否则允许本次访问并插入链表尾;占用的空间比循环链表要大
-
-
分析一下鉴权那部分内容中,前缀匹配算法的时间复杂度和空间复杂度。
-
假设有n个规则,每个规则的单词个数平均为m,则时间复杂度为O(m* logn), 空间复杂度O(n* m) 时间复杂度分析下:平均搜索m层,每一层最多有n个单词,由于是采用有序数组存储,查找时间复杂度为O(logn),所以总的时间复杂度为O(m*logn)
-
56 | 算法实战(五):如何用学过的数据结构和算法实现一个短网址系统?
短网址服务,如果在微博里发布一条带网址的信息,微博会把里面的网址转化成一个更短的网址。只要访问这个短网址,就相当于访问原始的网址。比如下面这两个网址,尽管长度不同,但是都可以跳转到一个 GitHub 开源项目里。其中,第二个网址就是通过新浪提供的短网址服务生成的。
原始网址:https://github.com/wangzheng0822/ratelimiter4j
短网址:http://t.cn/EtR9QEG从功能上讲,短网址服务其实非常简单,就是把一个长的网址转化成一个短的网址。这样一个简单的功能,是如何实现的呢?底层都依赖了哪些数据结构和算法呢?
短网址服务整体介绍
短网址服务的一个核心功能,就是把原始的长网址转化成短网址。除了这个功能之外,短网址服务还有另外一个必不可少的功能。那就是,当用户点击短网址的时候,短网址服务会将浏览器重定向为原始网址。这个过程是如何实现的呢?
浏览器会先访问短网址服务,通过短网址获取到原始网址,再通过原始网址访问到页面。如何将长网址转化成短网址?
如何通过哈希算法生成短网址?
哈希算法可以将一个不管多长的字符串,转化成一个长度固定的哈希值。可以利用哈希算法,来生成短网址。
在生成短网址这个问题上,毕竟不需要考虑反向解密的难度,所以只需要关心哈希算法的计算速度和冲突概率。
能够满足这样要求的哈希算法有很多,其中比较著名并且应用广泛的一个哈希算法,那就是MurmurHash 算法。
MurmurHash 算法提供了两种长度的哈希值,一种是 32bits,一种是 128bits。为了让最终生成的短网址尽可能短,可以选择 32bits 的哈希值。对于开头那个 GitHub 网址,经过 MurmurHash 计算后,得到的哈希值就是 181338494。再拼上短网址服务的域名,就变成了最终的短网址 Sina Visitor System(其中,微博国际 是短网址服务的域名)。
1. 如何让短网址更短?
不过,通过 MurmurHash 算法得到的短网址还是很长,而且跟开头那个网址的格式好像也不一样。只需要稍微改变一个哈希值的表示方法,就可以轻松把短网址变得更短些。
可以将 10 进制的哈希值,转化成更高进制的哈希值,这样哈希值就变短了。16 进制中,用 A~E,来表示 10~15。在网址 URL 中,常用的合法字符有 0~9、a~z、A~Z 这样 62 个字符。为了让哈希值表示起来尽可能短,可以将 10 进制的哈希值转化成 62 进制。最终用 62 进制表示的短网址就是http://t.cn/cgSqq。

2. 如何解决哈希冲突问题?
哈希算法无法避免的一个问题,就是哈希冲突。尽管 MurmurHash 算法,冲突的概率非常低。但是,一旦冲突,就会导致两个原始网址被转化成同一个短网址。当用户访问短网址的时候,就无从判断,用户想要访问的是哪一个原始网址了。这个问题该如何解决呢?
一般情况下,会保存短网址跟原始网址之间的对应关系,以便后续用户在访问短网址的时候,可以根据对应关系,查找到原始网址。存储这种对应关系的方式有很多,比如自己设计存储系统或者利用现成的数据库。数据库有 MySQL、Redis。就拿 MySQL 来举例。假设短网址与原始网址之间的对应关系,就存储在 MySQL 数据库中。
当有一个新的原始网址需要生成短网址的时候,先利用 MurmurHash 算法,生成短网址。然后,拿这个新生成的短网址,在 MySQL 数据库中查找。
如果没有找到相同的短网址,这也就表明,这个新生成的短网址没有冲突。于是就将这个短网址返回给用户,然后将这个短网址与原始网址之间的对应关系,存储到 MySQL 数据库中。
如果在数据库中,找到了相同的短网址,那也并不一定说明就冲突了。从数据库中,将这个短网址对应的原始网址也取出来。如果数据库中的原始网址,跟现在正在处理的原始网址是一样的,这就说明已经有人请求过这个原始网址的短网址了。就可以拿这个短网址直接用。如果数据库中记录的原始网址,跟正在处理的原始网址不一样,那就说明哈希算法发生了冲突。不同的原始网址,经过计算,得到的短网址重复了。这个时候,该怎么办呢?
可以给原始网址拼接一串特殊字符,比如“[DUPLICATED]”,然后再重新计算哈希值,两次哈希计算都冲突的概率,显然是非常低的。假设出现非常极端的情况,又发生冲突了,可以再换一个拼接字符串,比如“[OHMYGOD]”,再计算哈希值。然后把计算得到的哈希值,跟原始网址拼接了特殊字符串之后的文本,一并存储在 MySQL 数据库中。
当用户访问短网址的时候,短网址服务先通过短网址,在数据库中查找到对应的原始网址。如果原始网址有拼接特殊字符(这个很容易通过字符串匹配算法找到),就先将特殊字符去掉,然后再将不包含特殊字符的原始网址返回给浏览器。
3. 如何优化哈希算法生成短网址的性能?
为了判断生成的短网址是否冲突,需要拿生成的短网址,在数据库中查找。如果数据库中存储的数据非常多,那查找起来就会非常慢,势必影响短网址服务的性能。那有没有什么优化的手段呢?
MySQL 数据库索引,可以给短网址字段添加 B+ 树索引。这样通过短网址查询原始网址的速度就提高了很多。实际上,在真实的软件开发中,还可以通过一个小技巧,来进一步提高速度。
在短网址生成的过程中,会跟数据库打两次交道,也就是会执行两条 SQL 语句。第一个 SQL 语句是通过短网址查询短网址与原始网址的对应关系,第二个 SQL 语句是将新生成的短网址和原始网址之间的对应关系存储到数据库。
一般情况下,数据库和应用服务(只做计算不存储数据的业务逻辑部分)会部署在两个独立的服务器或者虚拟服务器上。那两条 SQL 语句的执行就需要两次网络通信。这种 IO 通信耗时以及 SQL 语句的执行,才是整个短网址服务的性能瓶颈所在。所以,为了提高性能,需要尽量减少 SQL 语句。那又该如何减少 SQL 语句呢?
可以给数据库中的短网址字段,添加一个唯一索引(不止是索引,还要求表中不能有重复的数据)。当有新的原始网址需要生成短网址的时候,并不会先拿生成的短网址,在数据库中查找判重,而是直接将生成的短网址与对应的原始网址,尝试存储到数据库中。如果数据库能够将数据正常写入,那说明并没有违反唯一索引,也就是说,这个新生成的短网址并没有冲突。
当然,如果数据库反馈违反唯一性索引异常,那还得重新执行刚刚讲过的“查询、写入”过程,SQL 语句执行的次数不减反增。但是,在大部分情况下,把新生成的短网址和对应的原始网址,插入到数据库的时候,并不会出现冲突。所以,大部分情况下,只需要执行一条写入的 SQL 语句就可以了。所以,从整体上看,总的 SQL 语句执行次数会大大减少。
实际上,还有另外一个优化 SQL 语句次数的方法,那就是借助布隆过滤器。
把已经生成的短网址,构建成布隆过滤器。布隆过滤器是比较节省内存的一种存储结构,长度是 10 亿的布隆过滤器,也只需要 125MB 左右的内存空间。
当有新的短网址生成的时候,先拿这个新生成的短网址,在布隆过滤器中查找。如果查找的结果是不存在,那就说明这个新生成的短网址并没有冲突。这个时候,只需要再执行写入短网址和对应原始网页的 SQL 语句就可以了。通过先查询布隆过滤器,总的 SQL 语句的执行次数减少了。
还有另外一种短网址的生成算法,那就是利用自增的 ID 生成器来生成短网址。
如何通过 ID 生成器生成短网址?
可以维护一个 ID 自增生成器。它可以生成 1、2、3…这样自增的整数 ID。当短网址服务接收到一个原始网址转化成短网址的请求之后,它先从 ID 生成器中取一个号码,然后将其转化成 62 进制表示法,拼接到短网址服务的域名(比如微博国际)后面,就形成了最终的短网址。最后,还是会把生成的短网址和对应的原始网址存储到数据库中。
理论非常简单好理解。不过,这里有几个细节问题需要处理。
1. 相同的原始网址可能会对应不同的短网址
每次新来一个原始网址,就生成一个新的短网址,这种做法就会导致两个相同的原始网址生成了不同的短网址。这个该如何处理呢?实际上,有两种处理思路。
第一种处理思路是不做处理。实际上,相同的原始网址对应不同的短网址,这个用户是可以接受的。在大部分短网址的应用场景里,用户只关心短网址能否正确地跳转到原始网址。所以,即便是同一个原始网址,两次生成的短网址不一样,也并不会影响到用户的使用。
第二种处理思路是借助哈希算法生成短网址的处理思想,当要给一个原始网址生成短网址的时候,要先拿原始网址在数据库中查找,看数据库中是否已经存在相同的原始网址了。如果数据库中存在,那就取出对应的短网址,直接返回给用户。
不过,这种处理思路有个问题,需要给数据库中的短网址和原始网址这两个字段,都添加索引。短网址上加索引是为了提高用户查询短网址对应的原始网页的速度,原始网址上加索引是为了加快刚刚讲的通过原始网址查询短网址的速度。这种解决思路虽然能满足“相同原始网址对应相同短网址”这样一个需求,但是是有代价的:一方面两个索引会占用更多的存储空间,另一方面索引还会导致插入、删除等操作性能的下降。
2. 如何实现高性能的 ID 生成器?
实现 ID 生成器的方法有很多,比如利用数据库自增字段。当然也可以自己维护一个计数器,不停地加一加一。但是,一个计数器来应对频繁的短网址生成请求,显然是有点吃力的(因为计数器必须保证生成的 ID 不重复,笼统概念上讲,就是需要加锁)。如何提高 ID 生成器的性能呢?关于这个问题,实际上,有很多解决思路。这里给出两种思路。
第一种思路是给 ID 生成器装多个前置发号器。批量地给每个前置发号器发送 ID 号码。当接受到短网址生成请求的时候,就选择一个前置发号器来取号码。这样通过多个前置发号器,明显提高了并发发号的能力。
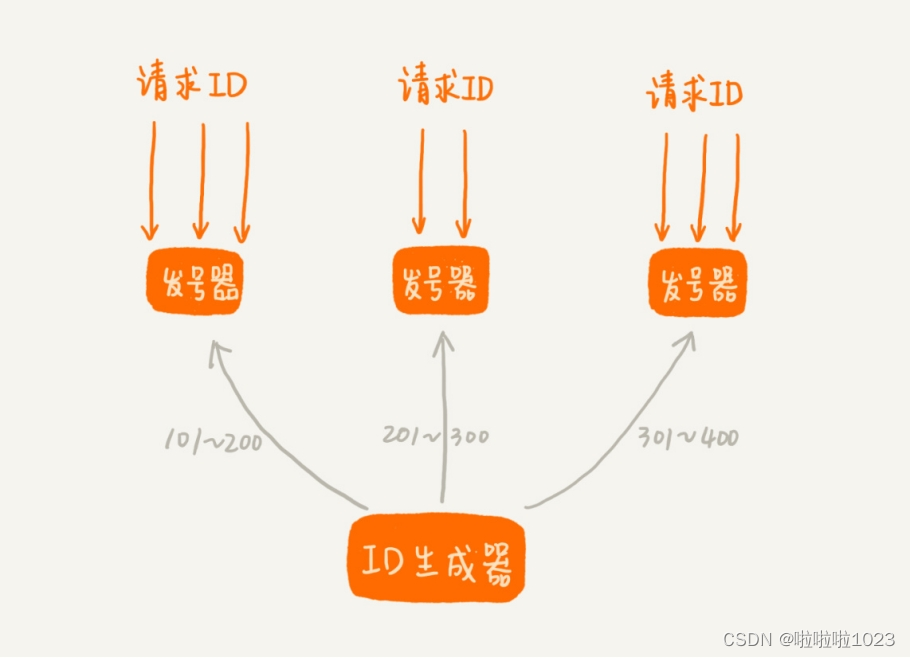
第二种思路跟第一种差不多。不过,不再使用一个 ID 生成器和多个前置发号器这样的架构,而是,直接实现多个 ID 生成器同时服务。为了保证每个 ID 生成器生成的 ID 不重复。要求每个 ID 生成器按照一定的规则,来生成 ID 号码。比如,第一个 ID 生成器只能生成尾号为 0 的,第二个只能生成尾号为 1 的,以此类推。这样通过多个 ID 生成器同时工作,也提高了 ID 生成的效率。
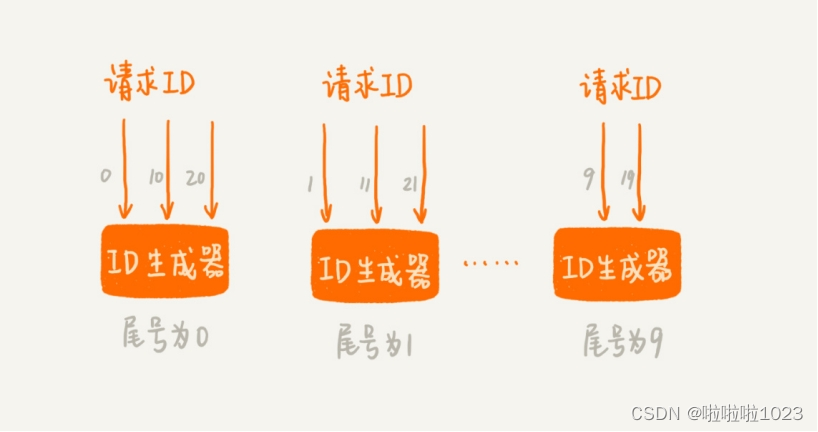
总结引申
短网址服务的两种实现方法。
第一种实现思路是通过哈希算法生成短网址。采用计算速度快、冲突概率小的 MurmurHash 算法,并将计算得到的 10 进制数,转化成 62 进制表示法,进一步缩短短网址的长度。对于哈希算法的哈希冲突问题,通过给原始网址添加特殊前缀字符,重新计算哈希值的方法来解决。
第二种实现思路是通过 ID 生成器来生成短网址。维护一个 ID 自增的 ID 生成器,给每个原始网址分配一个 ID 号码,并且同样转成 62 进制表示法,拼接到短网址服务的域名之后,形成最终的短网址。
课后思考
-
如果还要额外支持用户自定义短网址功能(http//t.cn/{用户自定部分}),又该如何改造刚刚的算法呢?
-
- 尝试将用户自定义后的短网址和原网址的映射关系存入数据库 - 插入成功, 则提示用户短网址生成成功 - 若插入失败, 说明存在冲突, 则进行判重处理 - 若数据库中短网址对应的原网址与当前正在处理的相同, 提示该短网址有效 - 若数据库中短网址对应的原网址与当前正在处理的不相同, 提示该短网址已被占用
-
首先查询“用户自定义部分”是否与已经生成的短网址冲突,如果冲突,只能提示用户进行修改。如果不冲突,将“用户自定义部分”和对应的原始网址写入数据库即可。
-
相当于用户自己指定算法生成短链,现在要考虑的就是短链冲突的问题,按照之前的思路可以先利用布隆过滤器判断是否冲突,不冲突,再将短链和对应的原始网址插入数据库(前提是数据库短链加了唯一索引);如果冲突了就要提示用户重新输入短链了
-
-
我们在讲通过 ID 生成器生成短网址这种实现思路的时候,讲到相同的原始网址可能会对应不同的短网址。针对这个问题,其中一个解决思路就是,不做处理。但是,如果每个请求都生成一个短网址,并且存储在数据库中,那这样会不会撑爆数据库呢?我们又该如何解决呢?
-
可以使用布隆过滤器进行判重验证, 通过之后再插入
-
id生成器,不处理,会导致相同的长域名重复。有个解决方案,长域名设置唯一的限制,在重复的情况下,插入表失败后,查询已经存在的长域名,对应的短域名。返回该短域名
-
给原始网址加唯一索引。如果写入异常,说明原始网址已经存在,再根据原始网址查询一次,取出短网址返回给用户。
-
-
通过哈希函数,在长网址字符串基础上,生成短网址哈希值。将哈希值从10进制提升至62进制,进一步缩短短网址长度。为了通过短网址回溯到原网址,需要建立长短网址的对应关系,存入数据库。
为了避免散列冲突,需要在在建立新的对应关系时,查询数据库中是否已有短网址,若有再检查长网址是否一致,若不一致则发生冲突,需要给新的长网址字符串加前缀,再用哈希函数生成短网址,直到没有冲突,最终将前缀、对应关系均存入数据库。
为方便查询,需要在数据库中建立短网址的索引(B+树)。减少SQL语句数量也可以提高性能,把查询+写入两条语句,简化为写入一条。代价是设置短网址唯一索引,不允许出现重复,这样当重复写入时数据库才会报错,此时再通过查询、前缀、写入的方式解决散列冲突。也可以针对短网址建立布隆过滤器,当新的短网址不在过滤器中则正常写入,否则通过查询判重并解决冲突。
另一种方式是通过全局计数器,给每个请求的原网址分配一个序号,作为短网址的主要部分。但它可能造成同一个原网址对应多个短网址的现象(虽然不影响应用体验)。为提高给号的并发性能,可以针对不同号段设置多个发号器并行发号。















 514
514











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









