






一、简单排序方法
1.直接插入排序(Insert Sort)
(1)算法思想:
每次将一个待排序的数与依次前面已经排好序的子序列中的数相比较并插入,直到全部待排序的数插入成功。该算法是一个稳定的算法。
这个算法思想和它的名字一样,真的就一个数向前依次的一个一个比较。举个例子,例如现在有一组数字为:52,92,28,15,25,对其进行直接插入排序的升序排序,第一个数字永远都是有序的,所以排序的时候直接从第二个数开始,即92和52进行比较,92大于52有序,得到52,92,28,15,25对下一个数28排序,将28与前面已经排好序的子序列52,92进行比较,先与92比较,92大于28应该在28之后,于是交换28和92的顺序数组变为52,28,92,15,25继续将28和52比较,28小于52交换二者顺序,得到28,52,92,15,25这样经过对前三个数字的排序可以得到前三个数字有序的子序列,继续将15和92比较得到28,52,15,92,25,继续将15分别和52,28比较后得到15,28,52,92,25,最后25和前面排好序的数字比较得到最终比较序列15,25,28,52,92,至此比较结束。
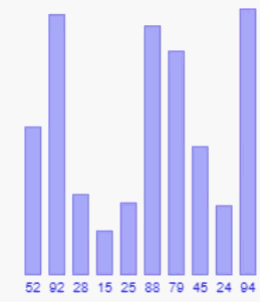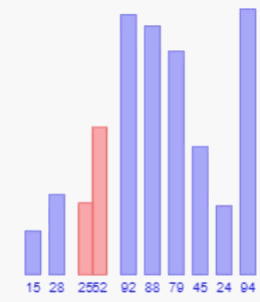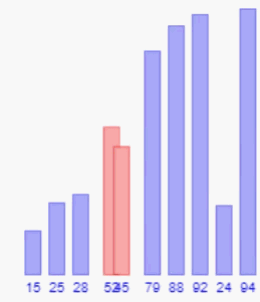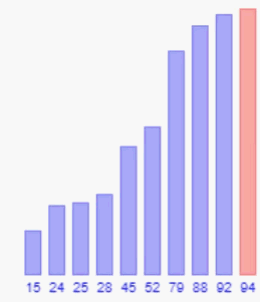
以上过程将每一个比较的数字和他前面已经排好序的数字依次比较,每比较一次不符合升序顺序的都会进行交换,这是基于顺序存储结构的,例如线性表这种插入操作需要移动大量元素的数据结构,就只能一个一个比较并交换了,但是如果是便于插入的链表,那在插入操作的时候就方便很多了,排序的时候,只需要将当前数字和前面排好序的数字依次比较,在比较结束后直接将当前数据插入其中就行,过程中省去一个一个交换的麻烦。
(2)代码实现:
以下是两段c语言代码实现仅供参考,读者可根据算法思想自行实现
//插入排序(升序)
void insertsort(int a[],int len)
{
int i=1, j=0,temp = 0,k;
for (i;i < len;i++)
{
if (a[i - 1] > a[i])//若当前数字小于前一数字,二者交换并再向前比较
{
temp = a[i];//保留当前比较值以防交换后被覆盖
//交换并继续向当前关键字之前比较,直到遇到比当前关键字小的数或者前面所有元素均比较完
for (j = i - 1;j >= 0 && a[j] > temp;j--)
{
a[j + 1] = a[j];
}
a[j + 1] = temp;//将比较的值插入
}
}
printsort(a, len);//打印排好序的结果
}#include"stdio.h"
#include"stdlib.h"
void printsort(int a[], int len)
{
for (int i = 0;i < len;i++)
printf("%d ", a[i]);
}
//插入排序(升序)
void insertsort(int a[],int len)
{
int i=1, j=0,temp = 0,k;
for (i;i < len;i++)//遍历数组中所有元素
{
k = i;//将当前遍历的位置记录下来
j = k - 1;
//从当前的数向前比较,若比前面的数小则交换
while (a[k] < a[j]&&j>=0)
{
temp = a[k];
a[k] = a[j];
a[j] = temp;
k = j;//交换后向前移动
j--;
}
}
printsort(a, len);
}
void main()
{
int a[] = { 11,4,6,7,2,5,3,1 };
int len = 8;
insertsort(a,len);
}(3)时间复杂度:
在清楚了直接插入排序算法思想和代码实现之后,不难看出,其算法时间复杂度应该是比较的时间加上移动元素的时间,假设有n个待排元素,n个元素逆序的时候是最坏的情况,在最坏的情况下除了第一个元素,剩下n-1个元素都要跟其之前的元素进行比较后再插入,时间复杂度即为内外两层循环所花费的时间O(n^2),最好的情况为顺序时,不需要移动元素,每个待排元素只需要比较一次即可,时间复杂度为O(n),因此平均时间复杂度为O(n^2) 。
2.希尔排序(Shell Sort)
(1)算法思想
先将待排序表以步长di其中i=(1,2,...),将排序表分割成若干段,对各个子表分别进行直接插入排序即可,每次分割缩小增量d,直到d=1。该算法不稳定。
例如
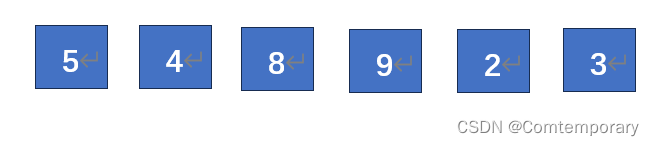
第一趟排序以d1 = n/2 =3划分,得到三个子表分别为(5,9)、(4,2)、(8,3)

对其三个子表各自进行直接插入进行升序排序,得到

第二趟排序缩小增量,d2 = 2,得到子表(5,3,4)、(2,9,8)

继续对各个子表进行插入排序

第三趟排序继续缩小增量,d3 = 1,这时每个数据都是一个子表
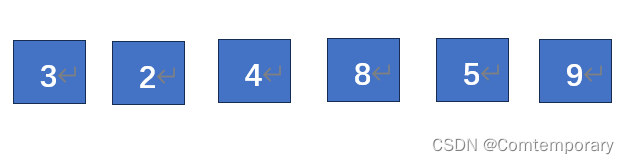
由于前几次的排序,此时的表中元素已基本有序,插入排序即可得到升序后序列
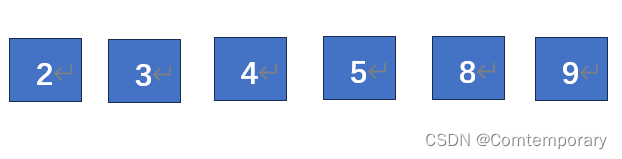
其实,希尔排序的核心就是先局部有序再逐渐逼近整体有序,而对于各个子表之间的排序除了可以使用直接插入,还可以使用折半插入查找来进行优化。由于希尔排序要求对数据的随机存取,因此无法用链表实现,只适用于线性表。
(2)代码实现
//输入len=8,a[8]={8,7,6,5,4,3,2,1}
void shellsort(int a[],int len)
{
int d,j,temp,i=0;
for (d = len / 2;d >= 1;d--)//增量d每次减1
{
for(i=d;i<len;i++)//反复切换子表,对各子表直接插入
{
if (a[i - d] > a[i])
{
temp = a[i];
for (j = i - d;j >= 0 && a[j] > temp;j=j-d)
{
a[j+d] = a[j];
}
a[j+d] = temp;
}
}
}
printsort(a, 8);//输出1 2 3 4 5 6 7 8
}(3)时间复杂度
该算法的时间复杂度取决于增量d的选取,算法时间复杂度未知,但当d=1时退化为插入排序,得到其最坏的时间复杂度为O(n^2)。
二、交换排序
1.冒泡排序
(1)算法思想
从后往前(或者从前往后)两两比较相邻元素的大小,若为逆序,则交换他们,直到序列比较完,这样为一趟冒泡排序。冒泡排序是一种稳定的排序算法。
例如对下列元素升序排序,即从前往后每趟冒泡排序将大的元素“往后冒”

第一趟










第一趟比较结束,最大的数8被排到最后,第二趟排序继续从头开始两两比较,由于最大的元素已经排好,第二趟不再对8排序,比较进行到倒数第二个元素即可,以此类推,即可实现升序排序。
这个例子中,在第二趟排序后就可得到升序序列,那么在第三趟冒泡时将不再有任何元素进行交换,此时便可以结束排序得到结果。
(2)代码实现
void bubblesort(int a[],int len)
{
int i, j,temp;
for (i = 0;i < len;i++)//外层循环遍历所有元素
{
for (j = 0;j < len - i-1;j++)//内层循环每趟冒泡,都从头开始遍历
{
if (a[j + 1] < a[j])
{
temp = a[j];
a[j] = a[j + 1];
a[j + 1] = temp;
}
}
printsort(a, 8);
printf("\n");
}
printsort(a, 8);
}(3)时间复杂度
最好的情况为顺序时,如1,2,3,4,5,6,此时只需要一趟冒泡进行n-1次比较,0次交换即可,时间复杂度为O(n),最坏的情况为逆序时,第一趟需要n-1次比较,第二趟需要n-2次比较,总的比较次数为(n-1)+(n-2)...2+1=n(n-1)/2次,即时间复杂度为O(n^2)。平均时间复杂度为O(n^2)。
2.快速排序
(1)算法思想
将待排序表L中任取一个元素作为基准(通常取首元素),通过一趟排序将待排序表划分为独立的两部分L1[1...k-1]和L2[k+1...n],使得L1中的所有元素小于基准值,L2中所有元素大于等于基准值,将基准值最终放在L[k]上,然后分别递归的对两个子表重复上述过程,直至每部分内只有一个元素或空为止,即所有元素放在其最终的位置。是一种不稳定的算法。
如图:
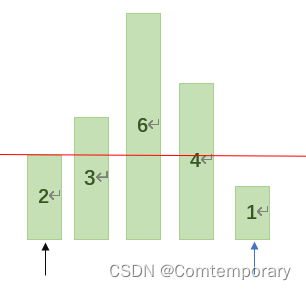
选择第一个元素2为基准,此时low(图中黑色箭头)指向第一个元素,high(图中蓝色箭头)指向最后一个元素1,从high开始向前依次将所指元素与基准2进行比较,如果high>=2,那么继续将high向前移动,此时high=1<2,此时将high的值赋给low。
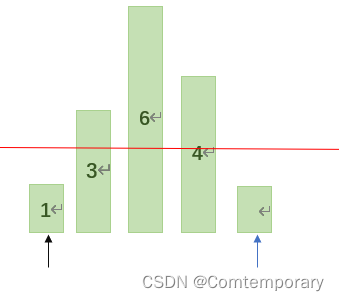
继续从low开始向后依次与基准值比较,如果low<=2,则low继续向后移动。
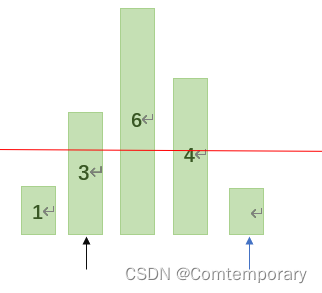
此时low=3>2,则将low值赋给high
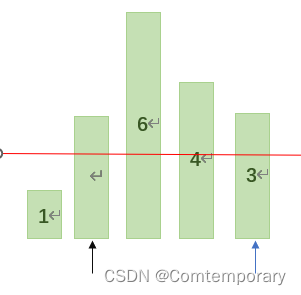
再从high开始向前比较,由于3,4,6均大于等于基准值2,因此high将移动到1。
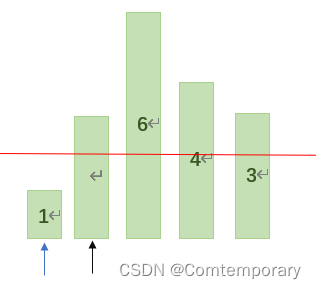
此时low>high,此轮交换结束,最后将基准值2赋值给low,经过这一轮交换后,可以将元素以基值为准,分成两部分,基准值以左的元素小于他,而他右边的元素均大于他,这样就完成了一次划分。
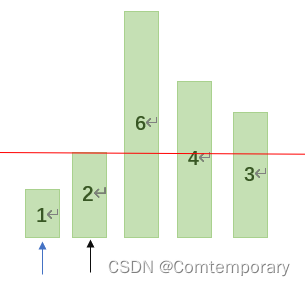
不难看出,如果接下来继续对以2为基准值分别划分好的左右两部分分别继续进行划分,即左半部分以1为基准划分,但由于只剩一个元素,可不用划分,右半部分以6为基准再次划分
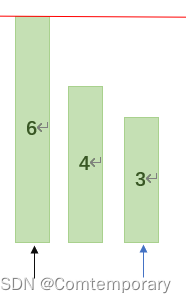
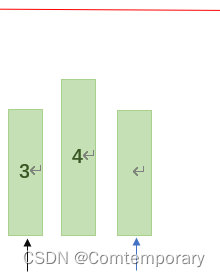
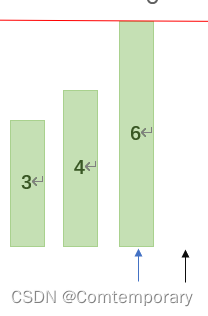
以此类推,再对划分后的左右部分再次划分直到划分后左右两部分只有一个元素即停止,这个过程可以通过递归来实现。
快速排序的核心就是选择基准并分成两部分,一部分值大于基准,另一部分小于基准,通过递归再实现排序的目的。
(2)代码实现
#include"stdio.h"
#include"stdlib.h"
void printsort(int a[], int len)
{
for (int i = 0;i < len;i++)
printf("%d ", a[i]);
}
int partition(int a[], int low, int high)
{
int base = 0;
base = a[low];
while (low < high)
{
while (low < high&&a[high] >= base) --high;
a[low] = a[high];
while (low < high&&a[low] <= base) ++low;
a[high] = a[low];
}
a[low] = base;
return low;
}
//快排(升序)
void quicksort(int a[], int low, int high)
{
int mid = 0;
if (low<high)
{
mid = partition(a, low, high);
quicksort(a,low,mid-1);
quicksort(a, mid+1, high);
}
}
void main()
{
int a[] = { 9,5,4,7,6,2,1,3};
int len = 8;
//partition(a, 0, 7);
quicksort(a, 0, 7);
printsort(a, 8);
}(3)时间复杂度
对于一个有n个元素的待排序列,第一次quicksort需要对n元素进行比较排序,之后的quicksort都是对上一次已经划分好的序列的部分进行排序,每次递归处理的元素都将小于n,于是时间复杂度O(n*递归深度),快排的递归深度,可以将其形象的看做是一颗二叉树,可以知道二叉树的树高即为递归的深度,若每次划分的均匀,则树越矮,递归深度低,若每次划分不均匀,递归越深,那么最好的情况下树高h=log2^(n)-1,那么时间复杂度为O(nlogn),最坏的情况则为O(n^2),平均时间复杂度为O(nlogn)。
三、选择排序
1.简单选择排序
(1)算法思想
每一趟排序都在待排序元素中选择关键字最小的元素加入有序子序列中
例如
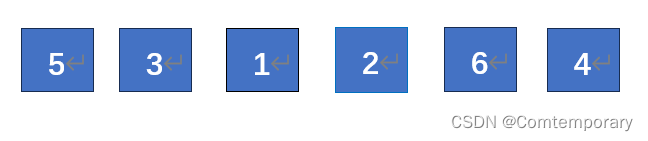
第一趟排序,从第一个元素开始遍历整个序列寻找最小的元素,找到后将其与第一个元素位置交换。
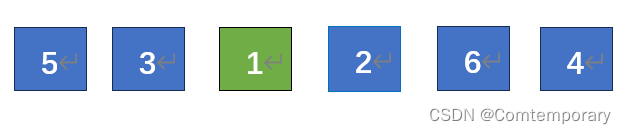

第二趟排序从第二个元素开始,遍历序列寻找最小的元素,再将其与第二个元素交换


以此类推,每趟排序都将找到一个待排序列中最小的元素,并将其加入到已经排好的序列中即可






(2)代码实现
void selectsort(int a[],int len)
{
int i, j = 0,min,temp;
for (i = 0;i < len - 1;i++)
{
min = i;//记录最小元素的位置
for (j = i+1;j < len;j++)//遍历序列,寻找最小元素
{
if (a[j] < a[min])
min = j;
}
if (min != i)//交换
{
temp = a[i];
a[i] = a[min];
a[min] = temp;
}
}
}(3)时间复杂度
对于n个元素序列的简单选择排序需要进行n-1趟排序,每趟排序都需要遍历所有待排元素比较找到每趟最小的元素,总的比较次数为(n-1)+(n-2)...+1 = [n*(n-1)]/2, 因此时间复杂度应该为
O(n^2),该算法不稳定。
2.堆排序
(1)算法思想
基于大根堆或者小根堆排序,每一趟将对顶元素与待排序列的最后一个元素交换。补充一点,大根堆的特点为:根>=左、右,即根值大于左子树和右子树的值,如下图即为一个大根堆。
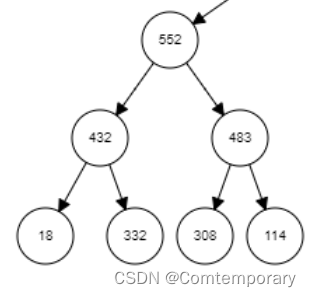
小根堆的特点为:根<=左、右。
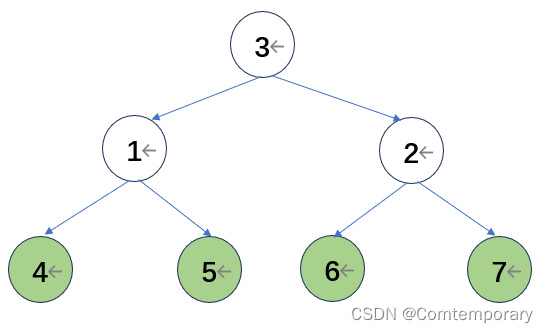
以基于大根堆的排序为例,待排序列为{5,2,3,1,6,4,7},首先根据待排序列画出生成树。

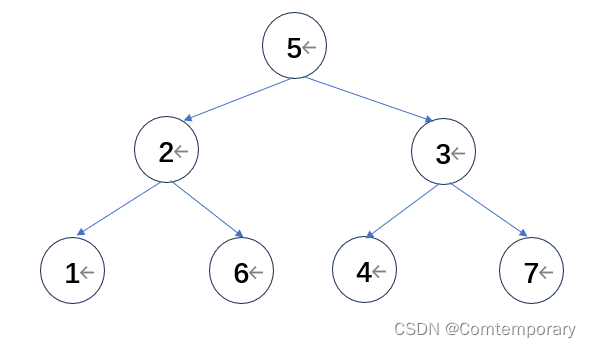
从最后一个元素开始,调整元素位置,形成大根堆。对于结点7所在子树是根节点为3,左结点为4的子树,根据大根堆的特点即根值大于左右结点值,两两比较发现7为最大元素应该将其与3交换。

继续向前处理根值为2,其左孩子为1,右孩子为6的子树,比较发现6为最大值,应放在根结点位置,将其与2交换。
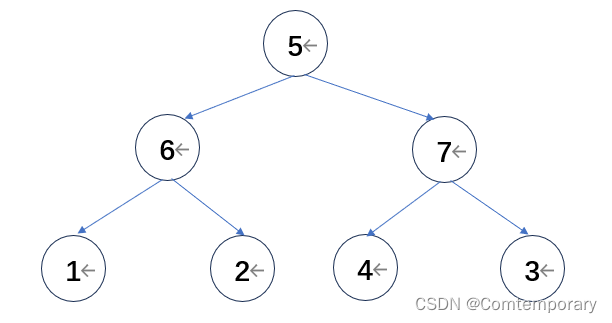
继续比较根节点5,其左孩子为6,右孩子为7,最大值7应该在根节点位置,二者交换
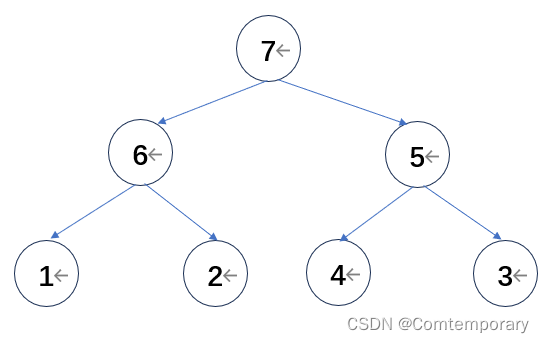
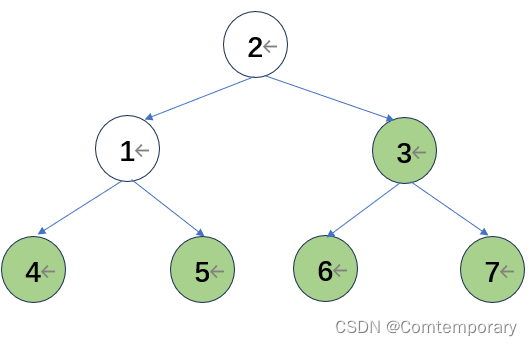
此时,经过一轮比较,树根的位置为待排序列中值最大的元素,将其与最后一个元素交换,下一轮比较的待排元素变为{3,6,5,1,2,4,7},下一轮不再对7进行比较,此时大根堆变为
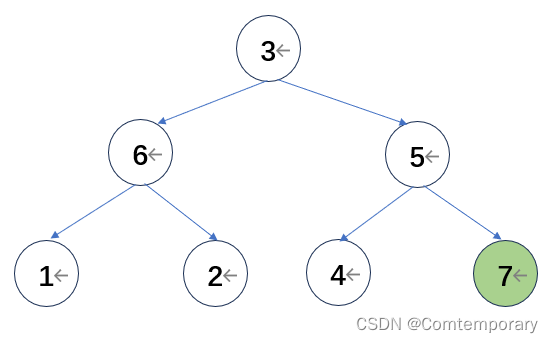
第二轮比较从4开始,继续形成大根堆得到
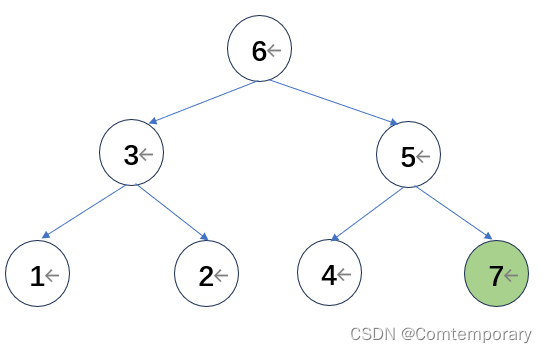
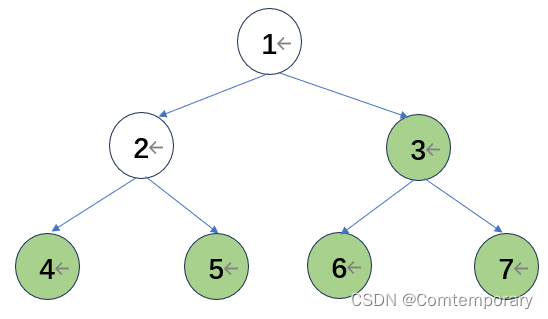
将根元素6和最后一个元素4交换
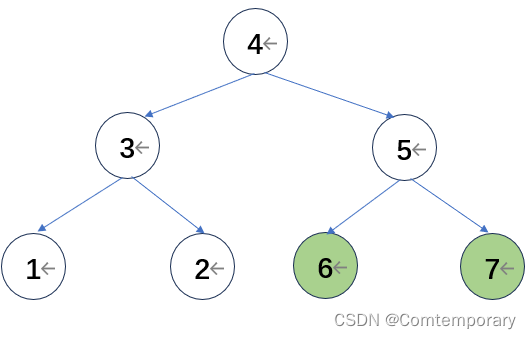
第三轮从2开始比较,形成大根堆
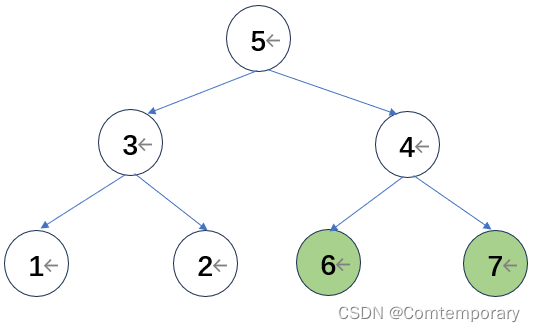
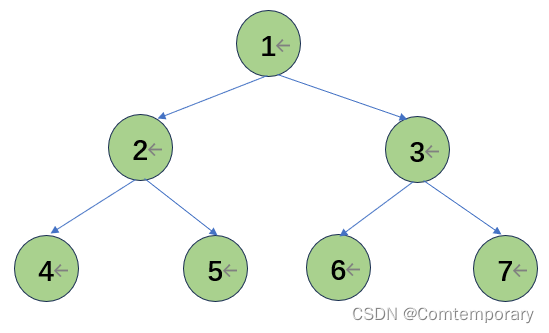
将根元素5与最后一个元素2交换

继续进行比较形成大根堆,并将根元素与末元素交换
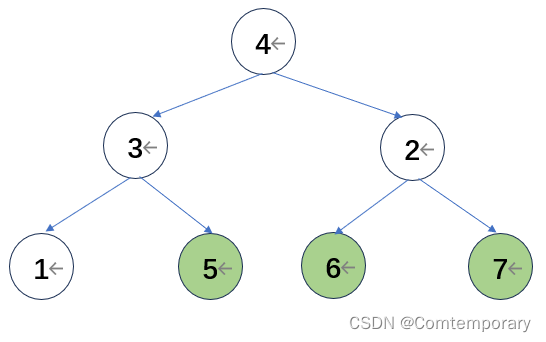
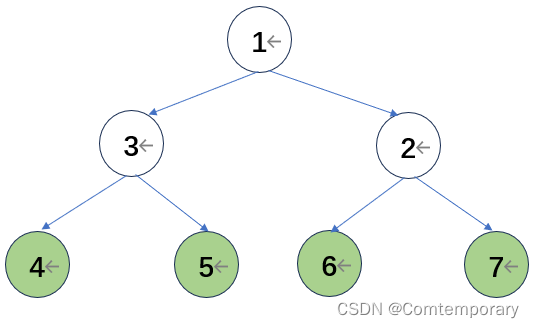
(2)时间复杂度
对于n个元素的堆排序,其时间复杂度包括建立堆和比较排序花费的时间,其中建立堆的时间 O(n),之后进行交换和建立大根堆(或小根堆)的过程要经过n-1趟,每一趟交换都需要将根节点“下坠”调整成大根堆,每次最多比较2次值,最多会“下坠”h-1层,因此每一趟排序复杂度不超过O(h) = O(logn),总的时间复杂度为O(nlogn)。
总结:
在学习排序的时候,学的排序越多发现自己越晕乎,感觉每个排序的思想都大差不差的,于是我决定总结一下,花了不少时间,在这个过程中我发现,即使只是对算法的思想很清楚,但自己要是没有真真切切的把他用代码实现了,还是不算理解的,在总结的过程中我发现算法的思想比起代码实现能更容易理解,我试图通过自己对算法思想的理解尝试自己实现代码,但往往写出来即使能够实现也感觉很生硬,查阅资料后发现,原来一种算法的实现不仅仅在于其思路的优越,还有实现起来逻辑上的精巧,算法的逻辑十分巧妙,是可以用很简洁的代码实现起来的高楼大厦。















 319
319

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









