






在线算法与离线算法
- 在线算法在面对未知的未来请求时做决策,而离线算法可以在知道所有请求后做决策。虚拟存储计算机中使用的最小淘汰(MIN)算法是一种离线算法。最近最少使用(LRU)算法不是实际可行的,但它是在线算法的一种策略。
- 离线算法在已知所有信息的情况下具有明显优势。
衡量在线算法优劣
- 在线算法的成本通常与最优离线算法的成本进行比较,竞争比用于衡量在线算法的性能。
- 竞争比定义为在线算法的成本与最优离线算法的成本(OPT)比值。竞争比越低算法越优。
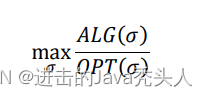 LRU,FIFO,RANDOM的竞争比都是k(为什么LRU和FIFO是k竞争比:因为当最优算法出现1次错误的时候,其最多出现k个错误(接下来的k个页面都需要被替换,k是缓存的最大数));LFU没有一个有界的竞争比,最糟糕的。他们之间的性能需要通过面对什么对手才能比较优劣性。对于paging问题,LRU算法在最坏情况下的性能与最优离线方案相似(每一次页面都发生页面错误,即每一次请求的页面都不一样都不在缓存里)。
LRU,FIFO,RANDOM的竞争比都是k(为什么LRU和FIFO是k竞争比:因为当最优算法出现1次错误的时候,其最多出现k个错误(接下来的k个页面都需要被替换,k是缓存的最大数));LFU没有一个有界的竞争比,最糟糕的。他们之间的性能需要通过面对什么对手才能比较优劣性。对于paging问题,LRU算法在最坏情况下的性能与最优离线方案相似(每一次页面都发生页面错误,即每一次请求的页面都不一样都不在缓存里)。
在线算法的实际应用:
- 资源分配:在云计算环境中,资源(如服务器、存储和带宽)需要根据实时需求动态地分配给用户,这可以通过在线算法来实现。
- 页交换算法:在计算机内存管理中,页面访问模式通常是未知的,页面交换算法决定何时将内存中的页面交换到磁盘上,以及何时将需要的页面加载回内存。
- 股票交易:在线算法可以用于自动化的股票交易系统,它们根据市场条件和策略在实时变动中决定买卖股票。
- 推荐系统:在线推荐算法可以根据用户的实时行为和反馈来调整推荐内容,比如视频平台的视频推荐。
对手:
- 适应性离线对手:拥有整个请求序列的知识,并且可以在序列结束之后选择最优策略来最大化成本。这意味着对手可以看到整个游戏的进程,并据此做出最优的决策。
- 适应性在线对手:可以根据算法的每一步决策来做出响应,但它必须即时做出决策,不能等待整个序列结束。
- 无感知对手:在选择请求序列时不知道算法的随机选择,但是它可以提前计划整个序列。
- 总结:适应性离线选手基于过去的所有历史数据做出最优决策,并在决策执行过程中不管根据实时变化改变决策;适应性在线选手是在执行计划的过程中会根据实际情况进行调整;无感知选手是基于过去的所有历史数据做出最优决策,但是在决策执行过程中不会实时改变决策。所以,适应性离线选手=适应性在线选手+无感知对手
在线广告词问题:
每个广告商都有一定数量的预算,他们愿意为某些关键词支付一定的费用。当一个搜索者搜索某个关键词时,需要决定展示哪个广告商的广告。广告商的预算有限,因此必须合理分配他们的预算以获得最大的收益。
- 解决方法:假设广告商的预算足够大,Balance算法能够通过有效地平衡收益和预算限制来解决问题,并且在理论上保证了它能够以接近1-1/e的比率与最优解竞争。
- 贪心算法:利用局部最优解来达到近似全局最优解的效果,例如Prim算法,零钱找回算法,Djikstra算法
- 最大前缀的定义:要求子序列是连续的。并且这个子序列在后面不再出现。
确定性算法:是指在给定相同输入的情况下,无论运行多少次,都会产生相同输出结果的算法。这种算法的输出完全由输入决定,并且它的执行过程不会因为随机因素而改变。(LRU,LFU,FIFO)
自组织列表:是一种可以移动元素并使其自动排序的数据结构,通常用于优化搜索和访问时间。是一种在线算法的应用实例,它们可以根据请求动态地调整其内部状态,从而实现高效的数据查找或排序。
标记算法的来源:
- 在线算法的需求: 在许多实际情况中,如操作系统的内存管理,算法必须即时做出决策而不知道未来的请求。因此,需要在线算法来处理这类问题。
- 对抗最坏情况: 虽然在线算法通常无法与拥有完整请求序列知识的离线算法相媲美,但它们旨在尽可能地减少最坏情况下的性能损失。
- 随机化的优势: MARKING算法使用随机化来对抗恶意的请求序列。通过随机化决策过程,算法可以避免被敌手轻易设计出最坏情况的请求序列来耗尽系统资源。
- 对抗敌手: 在某些情况下,敌手(可能是一个黑客)可能会故意发送难以处理的请求序列来攻击系统。随机化算法由于其不可预测性,使得敌手难以预测算法的行为,从而增加了系统的鲁棒性。
- 性能与理论证明: MARKING算法不仅在实践中表现良好,而且论文中还提供了理论证明,显示它在随机化算法中接近最优(competitive)。定理4证明:0
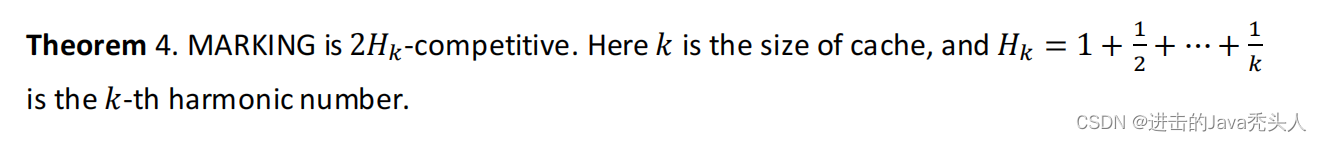
标记算法:该算法要求缓存中的每个页面需要一个标记位。最初,高速缓存中的所有页面都未被标记。当一个到页面的请求到达时,如果它在缓存中,然后标记它。如果没有,则随机删除一个未标记的页面,从磁盘中获取,并标记它。如果在页面出现故障时,缓存中的所有页面都被标记,在应用上述策略之前先取消标记所有页面。
Question1:为什么MIN只有在每k次请求时才会发生一次页面错误
Answer1:每当k个新页面请求之后,由于缓存大小限制,必须替换一个页面。
Question2:MIN算法的竞争比是1吗,LRU算法是k竞争比
Answer2:如果将MIN算法与自身比较,那么它的竞争比是1,因为它本身就是最优的。在最坏的情况下,LRU算法的成本(页面错误的次数)最多是最优离线算法OPT的成本的k倍
Question3:自组织列表问题有哪些可能的在线策略?他们的优劣各体现在哪里?
Answer3:自组织列表问题有三种可能的在线策略:Move-To-Front(MTF),Transpose和Frequency-Count(FC)。MTF是最有效的策略,因为它总是把最近使用的元素移动到最前面,这使得查找时间始终保持最低。然而,其他两种策略都有一定的局限性,Transponse虽然能够减少内存消耗,但在某些情况下可能会导致搜索效率降低;Frequency-Count虽然可以根据频率调整位置,但是由于排序操作的存在,可能导致额外的时间开销。
Question4:证明BIT算法(自组织列表问题的随机算法)的竞争率是多少?它是如何工作的?
Answer4:BIT算法的竞争率为1.75。该算法的工作原理是存储每个列表项的状态位,初始设置为0或1,然后当收到某个项的请求时,改变状态位。如果状态变为1,那么这个项目就被移到队列的前端,否则就留在原处不动。
Question5:证明设A是一个针对自适应在线对手的c竞争性随机化在线算法。如果还存在一个针对无感知对手的d竞争性算法,那么A是针对自适应离线对手的(c·d)竞争性的。
Answer5:如果你有一个随机化在线算法A,它在面对适应性在线对手时具有c倍的竞争力,这意味着算法A的成本最多是最优离线算法成本的c倍。同时,如果你有一个确定性算法,它在面对无感知对手时具有d倍的竞争力,这意味着这个确定性算法的成本最多是最优离线算法成本的d倍。
这里的关键点是,适应性离线对手可以模拟适应性在线对手的行为(因为它知道整个序列),并且可以做出与无感知对手一样最优的选择(因为它在序列结束之后选择最优策略)。因此,适应性离线对手结合了这两种对手的挑战。
Question6:在已有RANDOM算法下,为什么还要引出MAKING算法,优势在哪里
Answer6:RANDOM算法的性能被证明对于某些输入序列并不理想,特别是当输入序列是由一个oblivious adversary(一种特定类型的对手模型,它按照一定的模式产生请求)产生时。在这种最坏情况下,它的性能是与最优离线算法(OPT)相比的k倍。
Question7:在已有确定性算法,为什么还要引出随机算法呢,优势在哪里呢
Answer7:引入随机算法的优势在于它们能够更好地应对不确定性和复杂性。在面对强大的对手时,随机算法往往能展现出更好的性能和鲁棒性。
Question8: 为什么任何确定性算法至少是 k-竞争的
Answer8:证明:最优解至少和一种策略一样好,即驱逐将来最远才会被请求的页面。最优解至少在 k 步后才会有未命中。如果 p 是任意步骤中被驱逐的页面,那么在下一次请求 p 之前,缓存中其他 k−1 个页面至少会被请求一次。因此,最优解有 kn 次未命中,其中 n 是请求序列中的页面数量。对于任意确定性算法,在最坏情况下会有 n−K 次未命中。通过比较,算法至少是 k-竞争的。















 2643
2643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









