







09-自动补全-自定义分词器
1.自定义分词器
刚才学习了拼音分词器的基本用法,但是这个时候的拼音分词器还没有办法直接应用在生产环境,他还存在一些问题,为什么?
我们刚刚测试的“如家酒店还不错”,他在分词的时候rjjdhbc的全拼首字母在这里,也就是说明这句话首先没有被分词,而是作为一个整体出现,这是拼音分词器的第一个问题:他不会分词。
第二个问题:他还把这句话中的每一个字都形成了一个拼音,这没什么用,将来还不如形成全拼。比如如家你来个rujia。
第三个问题:没有汉字只剩下了拼音,我们其实用拼音搜索的情况是占少数的,大多数情况下我们其实是想用中文去搜,所以有拼音只是锦上添花,但是不能把汉字给扔了,汉字也得保留。
所以我们必须对拼音分词器做一些配置和自定义了。要想自定义,得先了解拼音分词器的构成:
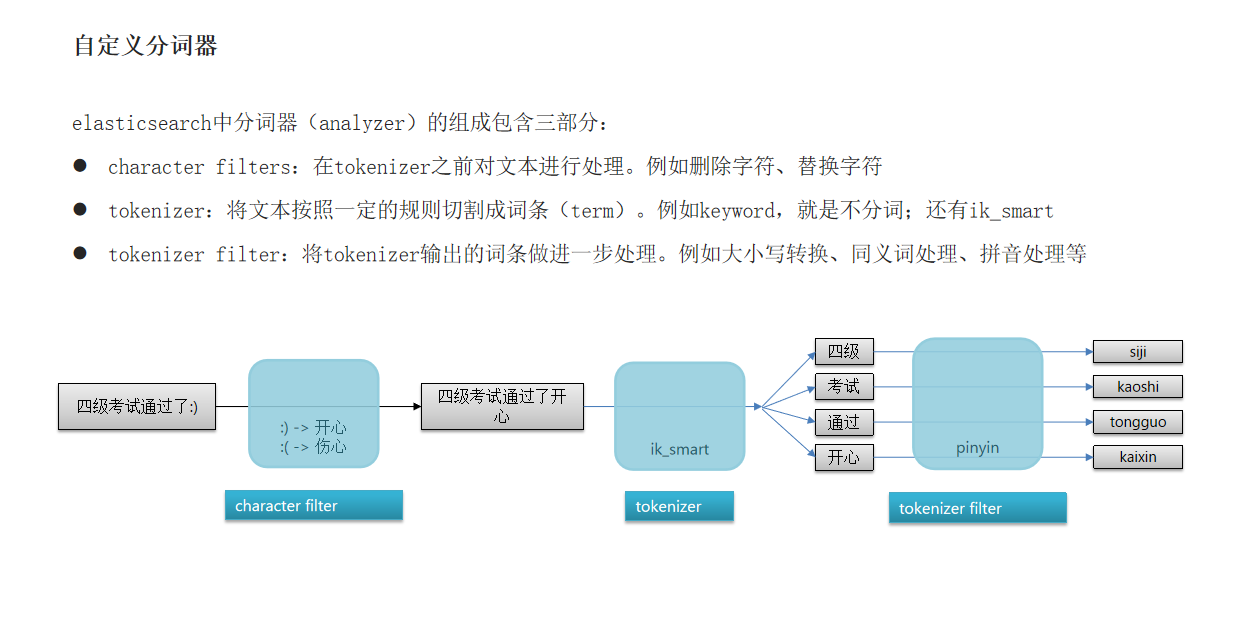
elasticsearch中分词器(analyzer)的组成包含三部分:
character filters:在tokenizer之前对文本进行处理。例如删除字符、替换字符
tokenizer:将文本按照一定的规则切割成词条(term)。例如keyword,就是不分词;还有ik_smart
tokenizer filter:将tokenizer输出的词条做进一步处理。例如大小写转换、同义词处理、拼音处理等
2.自定义分词器
我们可以在创建索引库时,通过settings来配置自定义的analyzer(分词器):
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "pinyin"
}
}
}
}
}
PUT /test
{
"settings": {
"analysis": {
"analyzer": { // 自定义分词器
"my_analyzer": { // 分词器名称
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": { // 自定义tokenizer filter
"py": { // 过滤器名称
"type": "pinyin", // 过滤器类型,这里是pinyin
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
}
}
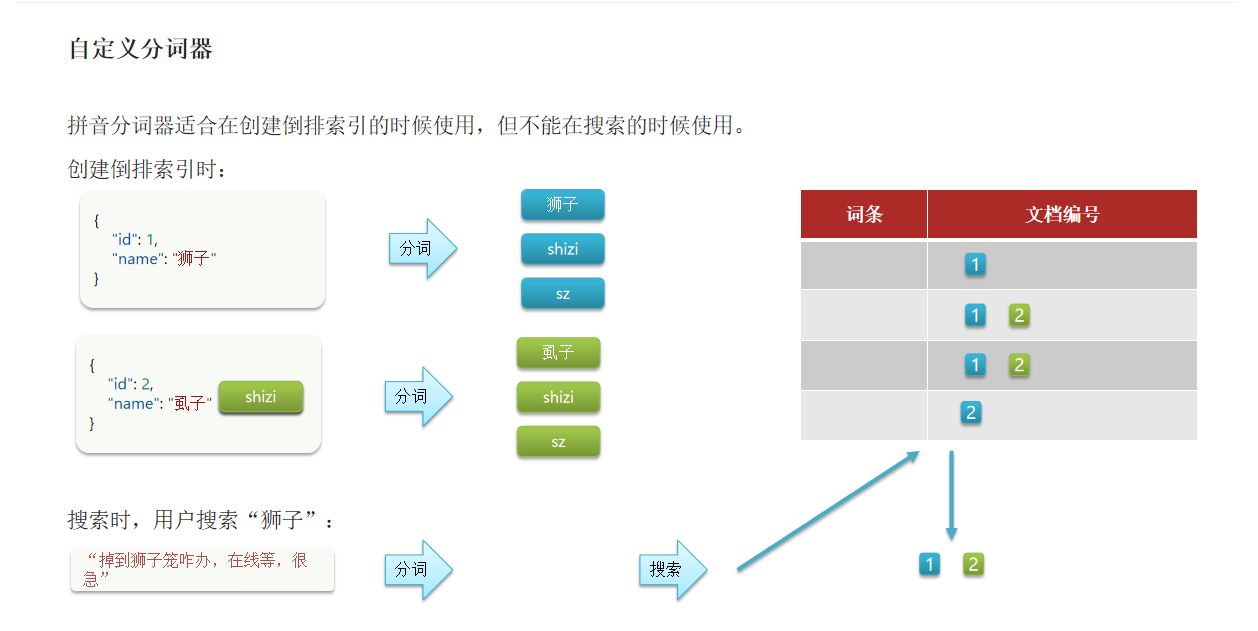
拼音分词器适合在创建倒排索引的时候使用,但不能在搜索的时候使用。
创建倒排索引时:
为什么??
你创建倒排索引的时候,你现在插入了一条狮子文档,这个狮子按照我们的分词方式会分成中文狮子、全拼(shizi)、缩写(sz),,然后创建倒排索引后形成词条以及文档编号。但是如果又插入一条这个“虱子”,因为他俩的拼音是一样的,所以除了中文以外,剩下的都一致,将来在往词条里面插入的时候,这个虱子作为一个全新词条插入,而(shizi和sz)因为之前插入狮子的时候已经存在了,索引只是记录文档id。
因此这就会导致我们这两个文档他们的拼音是一样的,这个时候如果别人来搜“调入狮子笼怎么办?在线等,很急!”,结果一搜分出来一个拼音shizi,一搜就能搜到两条文档,然后你说拍他,你还以为是这个“虱子”,这就完蛋了。
所以这就是出现问题的原因,因为你在搜索的时候你也用了拼音分词器,这个中文狮子也被分成了拼音,拿拼音去搜可不就两个都搜到了。这不是我们希望看到的,因此创建倒排索引的时候,你用拼音分词器没问题,但你在搜素的时候不应该用拼音分词器。
搜索的时候用户输入的如果是中文,你就应该拿这个中文去搜,用户输的是拼音,你才拿拼音去搜。所以我们创建和搜索的时候用不同的分词器。
怎么让他们分开呢??
看3.自定义分词器
3.自定义分词器
因此字段在创建倒排索引时应该用my_analyzer分词器;字段在搜索时应该使用ik_smart分词器;
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word", "filter": "py"
}
},
"filter": {
"py": { ... }
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
实现:这个时候搜索狮子就只会出现一条文档了。搜sz还是可以出现两条文档。
# 自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer",
"search_analyzer": "ik_smart"
}
}
}
}
POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
GET /test/_search
{
"query": {
"match": {
"name": "掉入狮子笼咋办"
}
}
}
4.总结:
如何使用拼音分词器?
下载pinyin分词器
解压并放到elasticsearch的plugin目录
重启即可
如何自定义分词器?
创建索引库时,在settings中配置,可以包含三部分
character filter
tokenizer
filter
拼音分词器注意事项?
如何使用拼音分词器?
下载pinyin分词器
解压并放到elasticsearch的plugin目录
重启即可
如何自定义分词器?
创建索引库时,在settings中配置,可以包含三部分
character filter
tokenizer
filter
拼音分词器注意事项?
为了避免搜索到同音字,搜索时不要使用拼音分词器















 446
446











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









