







ElasticSearch之自动补全查询-拼音分词器
使用场景
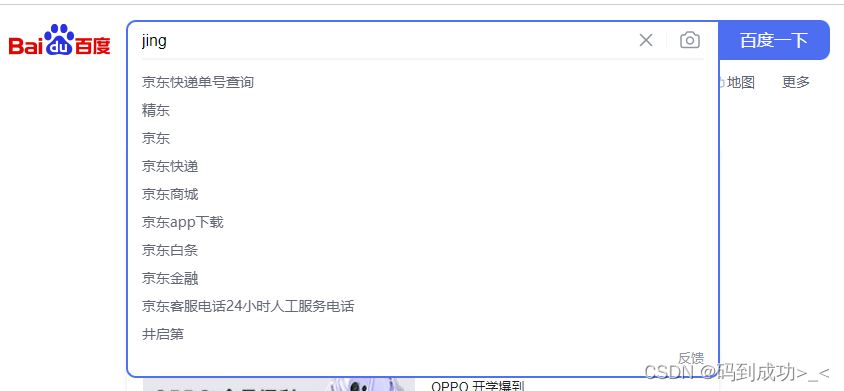
当用户在搜索框输入字符时,提示出与该字符有关的搜索项,如下:输入 jing 时提示出用户可能输出的词汇进行补全
1、环境
centos 7
ElasticSearch 7.6.1
elasticsearch-head
kibana 7.6.1
ik分词器 elasticsearch-analysis-ik-7.6.1
2、拼音分词器的安装
拼音分词插件地址:https://github.com/medcl/elasticsearch-analysis-pinyin/releases
安装的拼音分词器的版本最好和es的版本对应
# 解压到es的plugins目录下
unzip elasticsearch-analysis-pinyin-7.6.1.zip -d /opt/module/es-7.6.1/plugins/analysis-pinyin

重启es即可
在kibana上测试下拼音分词器
# 使用拼音分词器,对字符串 【如家酒店还不错】 进行分词 analyzer 指定分词器
POST /_analyze
{
"text": ["如家酒店还不错"],
"analyzer": "pinyin"
}
分析后的结果中是将每一个字的拼音作为一个词,把整个文本的拼音小写首字母连在一起作为一个词,如下截图
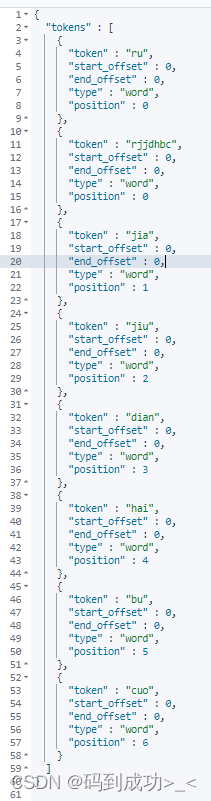
到这里拼音分词器已经按照好了,但是这个还不能够用于生产,存在以下问题:
1)使用拼音分词器后,仅剩下拼音分词,没有汉字了
2)分词的效果是把每个字的拼音作为一个词,这对我们检索用处不大
3)拼音分词只有文本内容中所有字的首字母拼成的词,仅输入文本内容开头几个字的首字母无法进行检索
3、自定义分词器
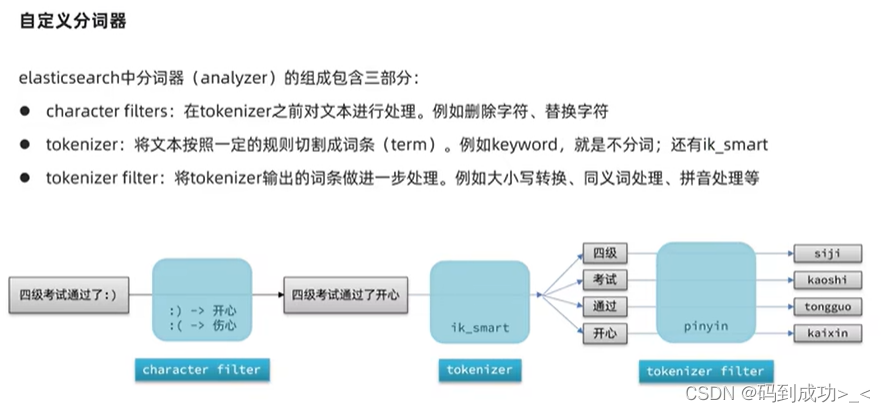
分词的顺序是 character filters -> tokenizer -> tokenizer filter

通过settings 设置的分词器仅对当前索引库有效
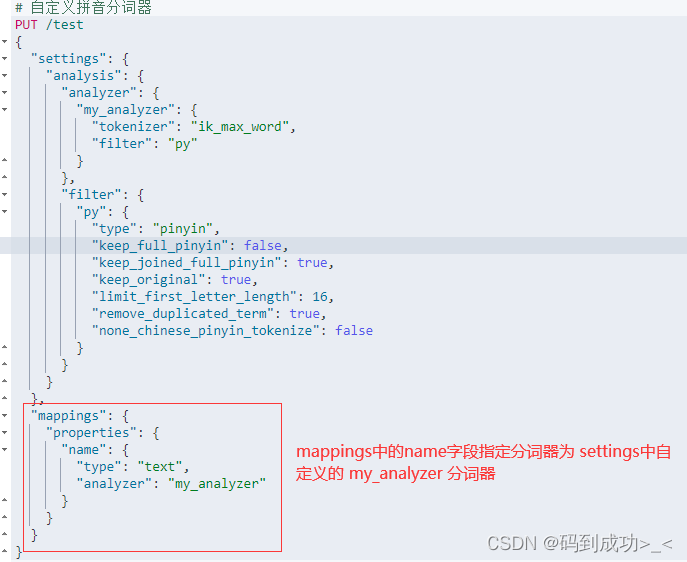
# 自定义拼音分词器
PUT /test
{
"settings": {
"analysis": {
"analyzer": {
"my_analyzer": {
"tokenizer": "ik_max_word",
"filter": "py"
}
},
"filter": {
"py": {
"type": "pinyin",
"keep_full_pinyin": false,
"keep_joined_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"remove_duplicated_term": true,
"none_chinese_pinyin_tokenize": false
}
}
}
},
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "my_analyzer"
}
}
}
}
向 test 索引库中添加两条测试数据
POST /test/_doc/1
{
"id": 1,
"name": "狮子"
}
POST /test/_doc/2
{
"id": 2,
"name": "虱子"
}
使用拼音 shizi 进行检索,因为 狮子、虱子 两个词的拼音是一样的,两个词都会被检索到
GET /test/_search
{
"query": {
"match": {
"name": "shizi"
}
}
}
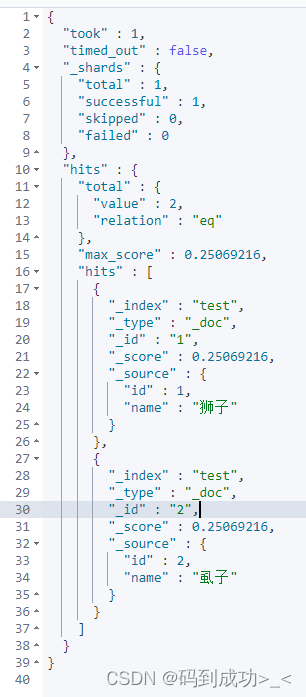
此时,再次使用仅包含 狮子 的文本测试下,我们的预期是要仅搜素处 狮子 词, 但是结果 狮子、虱子 两个词都搜索出来了
GET /test/_search
{
"query": {
"match": {
"name": "掉入狮子笼咋办"
}
}
}
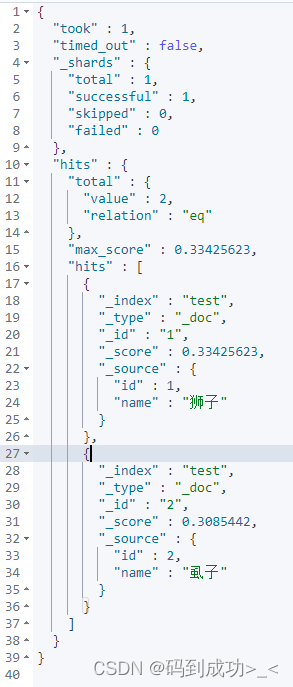
那如何才能达到我们预期的结果呢?
需要在创建索引库时指定下检索时使用的分词器 search_analyzer

删除掉 test 索引库,重新创建索引 ,在 mappings 中指定 检索时使用的分词器search_analyzer 为 ik_smart (ik分词器)
重新添加测试数据
再次检索
GET /test/_search
{
"query": {
"match": {
"name": "掉入狮子笼咋办"
}
}
}
此时检索的结果就只有 狮子 这一条数据
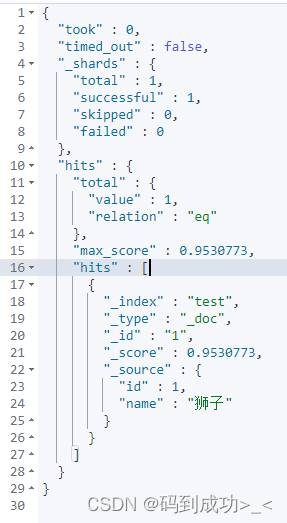
4、DSL实现自动补全查询
当用户在搜索框输入字符时,提示出与该字符有关的搜索项
elasticsearch提供了Completion Suggester查询来实现自动补全功能。这个查询会匹配以用户输入内容开头的词条并返回。为了提高补全查询的效率,对于文档中字段的类型有一些约束:
-
参与补全查询的字段必须是completion类型。
-
字段的内容一般是用来补全的多个词条形成的数组。

创建 test02 索引库
# 创建索引库
PUT test02
{
"mappings": {
"properties": {
"title":{
"type": "completion"
}
}
}
}
添加测试数据
POST test02/_doc
{
"title": ["Sony", "WH-1000XM3"]
}
POST test02/_doc
{
"title": ["SK-II", "PITERA"]
}
POST test02/_doc
{
"title": ["Nintendo", "switch"]
}
# 搜索文本为 s
POST /test02/_search
{
"suggest": {
"title_suggest": {
"text": "s",
"completion": {
"field": "title",
"skip_duplicates": true,
"size": 10
}
}
}
}
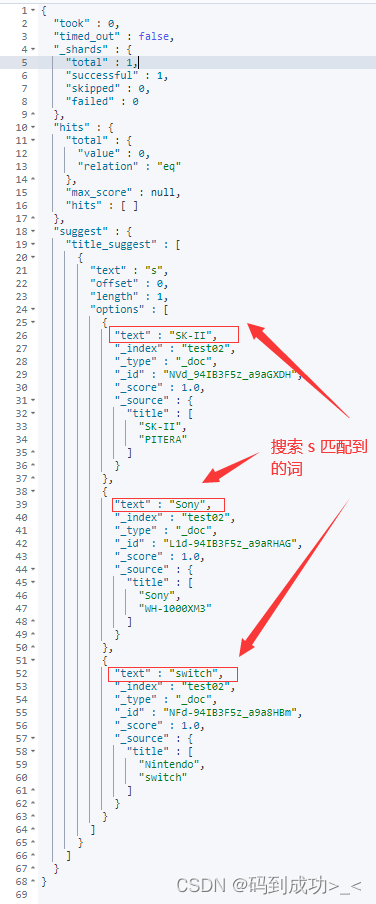
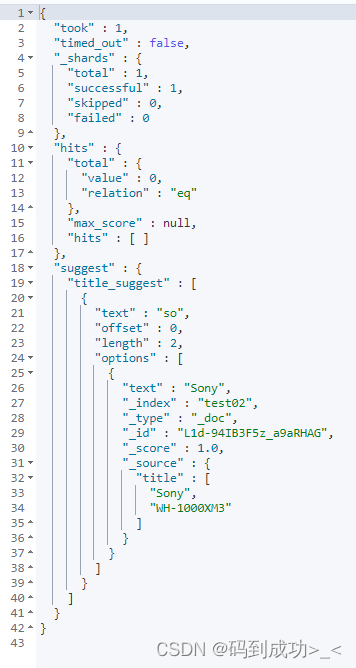
当搜索文本为 so 时,此时的搜索结果中仅包含一条
# 搜索文本为 so
POST /test02/_search
{
"suggest": {
"title_suggest": {
"text": "so",
"completion": {
"field": "title",
"skip_duplicates": true,
"size": 10
}
}
}
}

参考
SpringCloud+RabbitMQ+Docker+Redis+搜索+分布式,史上最全面的springcloud微服务技术栈课程|黑马程序员Java微服务
















 9160
9160











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











