






 本文详细介绍了如何在Linux系统上部署Spark,包括本地模式、Standalone模式和SparkonYARN模式,涉及HDFS和YARN的配置,以及环境变量、配置文件和测试步骤。
本文详细介绍了如何在Linux系统上部署Spark,包括本地模式、Standalone模式和SparkonYARN模式,涉及HDFS和YARN的配置,以及环境变量、配置文件和测试步骤。
首先完成HDFS和yarn的部署:
https://blog.csdn.net/m0_63500252/article/details/138465542?spm=1001.2014.3001.5502
下载spark
wget https://mirrors.tuna.tsinghua.edu.cn/apache/spark/spark-3.5.1/spark-3.5.1-bin-hadoop3.tgzlocal模式部署:
解压下载好的spark安装包
tar -zxvf spark-3.5.1-bin-hadoop3.tgz -C /export/server/配置环境变量:
在/etc/profile添加以下内容:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export SPARK_HOME=/export/server/spark
# 这里填你自己python解释器的位置
export PYSPARK_PYTHON=/export/server/miniconda3/envs/develop/bin/python3.8
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
然后source /etc/profile
接着在~/.bashrc添加以下内容
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PYSPARK_PYTHON=/export/server/miniconda3/envs/develop/bin/python3.8
测试:
在spark/bin运行pyspark,出现以下内容

(这里警告是因为没设置SPARK_LOCAL_IP,在spark-env.sh中设置)
浏览器可以打开4040端口:

至此local模式部署完成。
standalone模式部署
由于是单机配置,spark的master和worker进程都配置在localhost上。前提是先部署好local模式并且安装好python。
在spark/conf目录下
mv workers.template workers
vim workers添加workers机器的位置,这里不做修改了。
接着输入
mv spark-env.sh.template spark-env.sh
vim spark-env.sh添加以下内容
JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
HADOOP_CONF_DIR=/export/server/hadoop/etc/hadoop
YARN_CONF_DIR=/export/server/hadoop/etc/hadoop
export SPARK_MASTER_HOST=localhost
export SPARK_MASTER_PORT=7077
SPARK_MASTER_WEBUI_PORT=8080
SPARK_WORKER_CORES=1
SPARK_WORKER_MEMORY=1g
SPARK_WORKER_PORT=7078
SPARK_WORKER_WEBUI_PORT=8081
# 将spark程序运行的历史日志存到sparklog
SPARK_HISTORY_OPTS="-Dspark.history.fs.logDirectory=hdfs://localhost:8020/sparklog/ -Dspark.history.fs.cleaner.enabled=true"接下来在hdfs中创建sparklog目录,并授权,记得先启动hdfs
输入
hdfs dfs -mkdir /sparklog
hdfs dfs -chmod 777 /sparklog配置spark-defaults.conf
mv spark-defaults.conf.template spark-defaults.conf打开后添加
spark.eventLog.enabled true
spark.eventLog.dir hdfs://localhost:8020/sparklog/
spark.eventLog.compress true配置log4j2.properties
mv log4j2.properties.template log4j2.properties打开
修改这里为warn,以免日志全部输出到控制台,可改可不改。

可以启动spark集群了
sbin/start-all.sh
webui也能正常打开
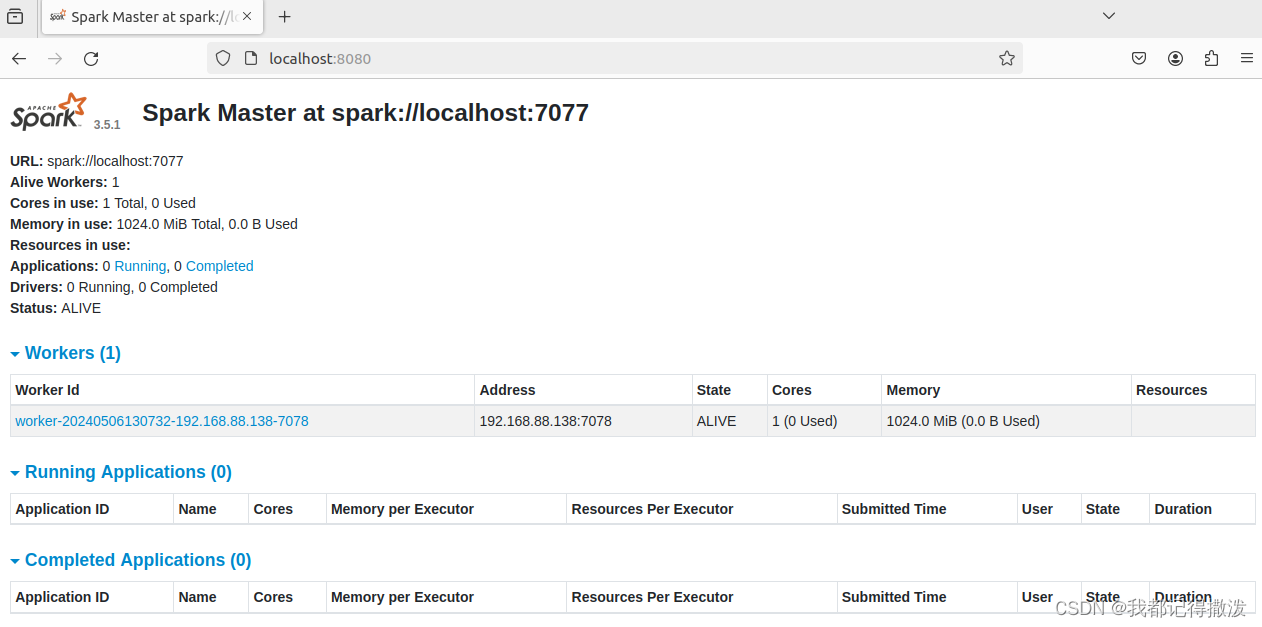
sparkshell可以连接到spark://localhost:7077

到此配置完毕。
spark on yarn模式部署
这种部署模式的好处是只需在yarn集群中的一台机器中部署spark,就可以将任务提交到yarn集群中运行,可以节约资源,spark的master由yarn的resourcemanager代替了,worker则由nodemanager代替。
要在yarn中提交spark任务,只需要
./pyspark --master yarn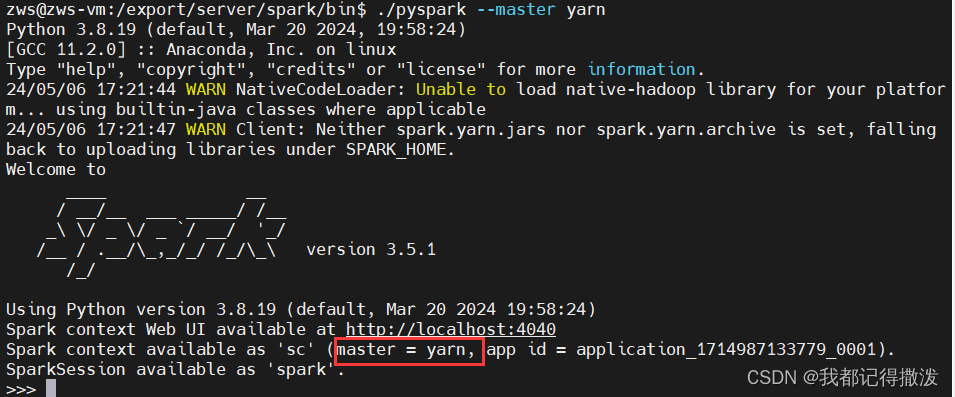
至此部署完成。















 1655
1655











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









