







目录
前言:
本篇文章讲述Python 中最常用的组合数据类型。
我们先来了解一下什么是“组合数据类型”:
~假如说我们需要实现:有新同学入学,让新同学输入其姓名、年 龄、籍贯、手机号码,并且将所有的信息存储到一个盒子中。
~将复杂的问题简单化 ->> 将所有的不相同类型的信息放在一个盒子中。
1.列表
2.元组
3.字典4.集合
一、列表
1.列表介绍
1)列表的介绍
列表是 Python 中最常用的组合数据类型之一。从数据结构角度看,列表是一个 可变 长度的 顺序序列 存储结构。在 Python 中,使用 list 表示列表类型。
2)列表创建方式
语法1:[元素1,元素2,元素3]
注意:
1. 元素可以是任何数据类型
2. 元素可重复
元素可以是任何类型:也包括列表
stu = ['小明','男','178',[60,90]]
print(type(stu))
print(stu)元素可重复
student =['小明',178.5,19,19]
print(type(student))
print(student)语法2:list(序列) ->> 将序列逐个拆解为列表中的元素
注意:
1. 一定是序列 =>>可以通过下标获取每个元素 ,如字符串等。
eg:
a = list("123456")
print(a)
print(type(a))
b = list(123456)
print(b) #报错,只能存序列,而此处为数值
2.列表的增删改查
1)获取列表中某个元素(查)
语法:li[索引]
注意:
1. 索引默认从0开始
eg:
stu =['小明', 178.5, 19, 19]
print(stu[0],type(stu[1]))
# 小明 <class 'float'>注意:若只取一个元素,数据类型保持不变,仍是原数据类型
语法2:li[起始位置:结束位置:步长]
注意:
1. 起始位置默认从0开始
2. 结束位置取不到,往后加1位 (左闭又开)
3. 步长默认为1
4. 起始位置与结束位置不写时,则默认从头取到尾
stu = ['小明', '江苏', 178.5, 19, '男']
print(stu[:5:])
print(stu[1:5:2])
print(sth[::])
2)修改元素的值(改)
语法:li[下标] = 新值
列表是可以修改的 =>>因为它可变
stu = ['小明', '江苏', 178.5, 19, '男']
stu[0] = '小红'
stu[2] = 178
print(stu)
# ['小红', '江苏', 178, 19, '男']3)删除元素(删)
语法:
| 方法 | 功能描述 |
|---|---|
| 列表.remove(元素) | 删除该指定元素,若有重复只删除第一个 |
| 列表.pop(索引) | 删除索引对应元素 |
| 列表.clear() | 清空列表 |
| del 列表[索引] | 删除索引对应元素 |
| del 列表 | 删除列表 |
列表.remove(元素)
删除指定元素,如果有重复的只删除第一个:
li = ['a','b','a']
li.remove('a')
print(li)
#输出:['b', 'a']列表.pop(索引)
删除指定索引对应的元素:
li = ['a','b','a']
li.pop(1)
print(li)
#输出:['a', 'a']若不指定索引,则默认删除最后一个元素:
li = ['a','b','a']
li.pop()
print(li)
# 输出:['a', 'b']列表.clear()
清空列表:
li = ['a','b','a']
li.clear()
print(li)
#输出:[]del 列表[索引]
删除指定索引对应的元素:
li = ['a','b','a']
del li[1]
print(li)
#输出:['a', 'a']del 列表
删除指定列表:
li = ['a','b','a']
del li
print(li)
运行结果:
报错:不存在此列表
4)添加元素(增)
语法:
| 方法 | 功能描述 |
|---|---|
| 列表.append(元素) | 往列表中追加(后面)元素 |
| 列表.insert(索引,元素) | 在索引前面添加元素 |
| 列表.extend(序列) | 将列表与序列合并为一个列表 |
列表.append(元素)
li = ['a','b','a']
li.append('c')
print(li)
#输出:['a', 'b', 'a', 'c']列表.insert(索引,元素)
li = ['a','b','a']
li.insert(1,'c')
print(li)
#输出:['a', 'c', 'b', 'a']列表.extend(序列)
li = ['a',1]
str = 'cd'
li.extend(str)
print(li)
#输出:['a', 1, 'c', 'd']3.其它常用方法
1)列表常用方法
列表还自带了一些其它的常用方法,如下:
| 方法 | 功能描述 |
|---|---|
| 列表.count(元素) | 返回指定元素在列表中出现的次数 |
| 列表.index(元素) | 查找指定元素所在的最小索引 |
| 列表.reverse() | 将列表进行反转 |
| 列表.sort() | 将列表进行排序,默认为升序 |
列表.count(元素)
li = ['a','b','a']
print(li.count('a'))
#输出:2列表.index(元素)
li = ['a','b','a']
print(li.index('a'))
#输出:0列表.reverse()
stu = ['小明','男','178',[60,90]]
stu.reverse()
print(stu)回忆一下我们之前所学过的内容:有没有具有同样功能的实现??
那就是:“分片”
stu = ['小明','男','178',[60,90]]
print(stu[::-1])
列表.sort()
限制:列表中的元素必须是同一种数据类型
li = [2,5,7,1,3]
li.sort()
print(li)
# 输出:[1, 2, 3, 5, 7]
li = ['b','a','d','c']
li.sort()
print(li)
# 输出:['a', 'b', 'c', 'd']
li = [2,5,7,1,'a']
li.sort()
print(li)
#报错,因为不是同一种数据类型,无法比较大小降序:
默认的是升序,那如果我们想进行降序排序该怎么写呢?
当然我们可以利用已学的内容进行解决:
在已进行升序的基础上:1,利用:列表.reverse()方法,把列表进行反转。2,利用分片进行反转
列表.sort() 中有一个reverse参数,让其为True。
即,列表.sort(reverse=True)
li = [2,5,7,1]
li.sort(reverse=True)
print(li)
# 输出:[7, 5, 2, 1]2)常用Python内置方法
Python 中还有一些内置的方法应用于列表中,如下:
| 方法 | 功能描述 |
|---|---|
| max(列表) | 返回列表种最大的元素 |
| min(列表) | 返回列表中最小的元素 |
| len(列表) | 返回列表的长度 |
| sorted(列表) | 默认升序,指定reverse=True为降序 |
max(列表)
li = ['a','b','a']
print(max(li))
#输出:bmin(列表)
li = ['a','b','a']
print(min(li))
#输出:alen(列表)
li = ['a','b','a']
print(len(li))
#输出:3拼接:可以联系字符串的拼接
li1 = [1,2,3]
li2 = [4,5]
print(li1 + li2)
print('123','45',sep='')
输出:[1, 2, 3, 4, 5]
12345
相乘:也可以联系字符串
li1 = [1,2,3]
li2 = [4,5]
print(li1 * 3)
print('123'*3)
输出:[1, 2, 3, 1, 2, 3, 1, 2, 3]
123123123二、元组
1.元组介绍
1)元组的介绍
在前言中已经说到:组合数据类型是将所有的不相同类型的信息放在一个盒子中。对于元组来说只有查看权限,而不能被改变
元组也是序列结构,但是是一种 不可变 序列。在 Python 中,使用 tuple 表示元组类型。
2)元组创建方式
语法1:(元素1,元素2,元素3)
注意:
1. 只有一个元素时必须带小蝌蚪表类型
2. 元素可以是任何数据类型
3. 元素可重复
只有一个元素时必须带小蝌蚪表类型
a = (1)
print(a)
print(type(a))
输出:1
<class 'int'>
a = (1,)
print(a)
print(type(a))
输出:(1,)
<class 'tuple'>
语法2:tuple(序列)
注意:
1. 序列为字符串 ->> 将序列逐个拆解为元组中的元素
2. 序列为列表 ->> 将列表转为元组
tuple()->>将列表转为元组
c = [1, 3, 5]
c1 = tuple(c)
print(c1)
输出:(1, 3, 5)2.元组的查
1)获取元组中的元素(查)
语法:tu[索引]
切片语法:tu[起始位置:结束位置:步长]
注意:
1. 索引默认从0开始
2. 结束位置取不到,往后加1位
3. 步长默认为1
3.常用内置方法
1)常用的内置方法
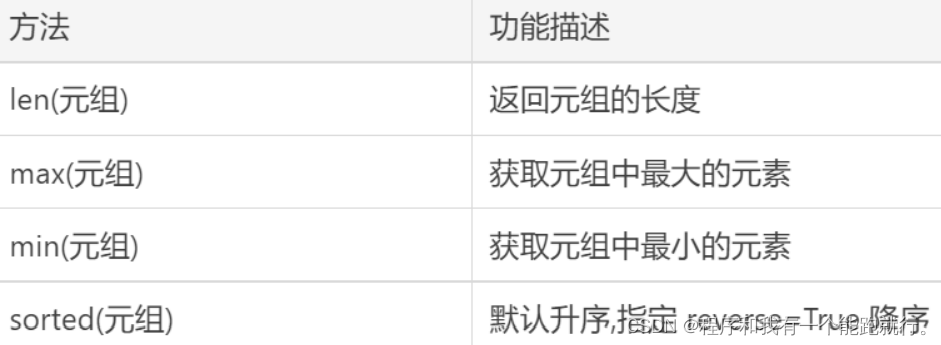
| 方法 | 功能描述 |
|---|---|
| len(元组) | 返回元组的长度 |
| max(元组) | 获取元组中最大的元素 |
| min(元组) | 获取元组中最小的元素 |
| sorted(元组) | 默认升序,指定reverse=True降序 |
sorted
# 默认升序
c1 = sorted(c)
print(c1)
# 降序
c2 = sorted(c, reverse=True)
print(c2)4.元组的长处
1)元组的优势
1. 因为元组为不可变数据类型,所以安全性更高
2. 元组性能更佳
tu = (1, 2, 3)
print(tu.__sizeof__())
输出:48
li = [1, 2, 3]
print(li.__sizeof__())
输出:64此方法可以输出占用计算机多个字节的内存。
三、字典
1.字典的介绍与创建
1)字典的介绍
字典是 可变无序 数据结构,主要由键 (key) 和对应值 (value) 成对组成,根据键 (key) 计算对应值 (value) 的地址,以至于字典具有非常快的查询与插入速度。在 Python 中,使用 dict 表 示字典类型。
2)字典的创建
语法1:{键1:值1, 键2:值2, 键3:值3}
eg:
dic1 = {"name":"小明","age":19,"sex":'男'}
print(dic1)
print(type(dic1))
输出:{'name': '小明', 'age': 19, 'sex': '男'}
<class 'dict'>语法2:dict(键=值,键=值)
eg:
dic2 =dict(name = '小明',age = 19 ,sex = '男')
print(dic2)语法3:dict([(键1,值1),(键2,值2)])
eg:
dic3 =dict([('name','小明'),('age',19),('sex','男')])
print(dic3)
集合=>>列表=>>元组
每一个键值对都是以元组的形式放在列表里的
注意1:
1. 键必须是不可变的数据类型
2. 键要唯一,如重复则覆盖
3. 值可以为任意类型
键必须是不可变的数据类型 (字符串、元组、数值、布尔)
dic4 = {(1, 2, 3): 1, "1": 1, [1, 2, 3]: 2}
print(dic4) # 报错,列表是可变的数据类型键要唯一,如重复则覆盖
dic = {'age':19,'age':20}
print(dic)
输出:{'age': 20}2.字典的增删改查
1)访问字典中的值(查)
语法:dic[键]
注意1:
1. 当键不存在时则报错
2)修改字典中的值(改)
语法:dic[键] = 新值
思路:
1. 先获取
2. 赋值
3)字典中添加键值对(增)
语法:dic[新键] = 新值
思路:
1. 添加新键
2. 赋值
4)删除字典中的值(删)
语法:
| 方法 | 功能描述 |
|---|---|
| dic.pop(键) | 删除键对应的值 |
| dic.clear() | 清空字典 |
| del dic[键] | 删除键对应的值 |
| del dic | 删除字典 |
3.常用方法
Python 字典常用的 3 个方法,详情如下:
| 方法 | 功能描述 |
|---|---|
| dict.keys() | 获取字典中所有的键 |
| dict.values() | 获取字典中所有的值 |
| dict.items() | 获取字典中所有的键值对 |
| dict.get(key) | 获取字典中指定键对应的值 |
dict.keys() 返回的是列表
dic = {'name':'小明','age':20}
print(dic.keys())
输出:dict_keys(['name', 'age'])
dict.values() 返回的也是列表
dic = {'name':'小明','age':20}
print(dic.values())
#输出:dict_values(['小明', 20])dict.items()
dic = {'name':'小明','age':20}
print(dic.items())
#输出:dict_items([('name', '小明'), ('age', 20)])
拓展:
怎么分别将两个 序列 里的元素分别作为键和值,组成一个字典??
# 将li1 与 li2 ->> [("name","小明"),("age",19)]->>{"name":"小明","age":19} ->> 两个列表中的值一一对应
# zip(序列1,序列2)->>序列1与序列2中对应位置的元素打包为元组,并组成列表
li1 = ["name","age"]
li2 = ["小明",19]
print(zip(li1, li2)) # 将两个序列打包为一个元组,输出的是一个内存地址
print(list(zip(li1, li2)))
print(dict(zip(li1, li2)))
输出:<zip object at 0x000001DC12EE1408>
[('name', '小明'), ('age', 19)]
{'name': '小明', 'age': 19}dict.get(键)
字典get() 函数返回指定键的值,如果值不在字典中返回默认值。
dict.get(key, default=None)即:
- key -- 字典中要查找的键。
- default -- 如果指定键的值不存在时,返回该默认值值。
四、集合
1.集合介绍与创建
1)集合介绍
集合是一个 无序、不重复 的 可变 序列,在 Python 中,使用 set 来表示集合类型。
2)集合创建
语法1:{元素1,元素2,元素3}
eg:
s = {}
print(type(s))
输出:<class 'dict'>注意:在python中,直接写{}创建的是空的字典。
语法2:set(序列)
1. 参数为字符串时 ->> 将序列逐个拆解为集合中的元素,并去重
2. 参数为列表时 ->> 将列表转为集合,并去重
3. 参数为元组时 ->> 将元组转为集合,并去重
eg:
s1 = {1, 2, 3, 3, 2, 2, 2, 1, "1"}
print(s1)
print(type(s1))
输出:{1, 2, 3, '1'}
<class 'set'>2.集合的增删
1)给集合添加元素(增)
| 方法 | 功能描述 |
|---|---|
| 集合.add(元素) | 向集合中新增一个元素 |
| 集合.update(序列) | 将序列中每个元素更新到集合中 |
注意:
1. 集合是一个无序的序列。无法通过下标获取元素,也无法修改元素
2. 集合具备自动去重功能
3. 集合中元素为不可变对象
eg:
s1 = {1, 2, 3}
s1.add(4)
s1.add(2)
print(s1)
#输出:{1, 2, 3, 4}
l1 = [3, 4, 6]
s1.update(l1)
print(s1)
#输出:{1, 2, 3, 4, 6}注意: 1 == 1.0
2)删除集合中的元素(删)
语法:集合.remove(元素) ->> 从集合中删除指定元素
集合.clear() ->> 移除集合中的所有元素
总结:
可变不可变 --> id地址
有序序列 --> 下标
有序序列:字符串、列表、元组
无序序列:集合
数值和字典不是序列
可变数据类型:列表、字典、集合
不可变数据类型:数值、字符串、元组、布尔值
1.数值:不可变、非序列。用来计算。
2.布尔值:不可变、非序列。用来判断。
3.字符串:不可变、有序序列。文本。不能增删改,可以查。
4.列表:可变、有序序列。可以增删改查。
5.元组:不可变、有序序列。不能增删改,可以查。
6.字典:可变、不是序列。可以增删改查。通过键来查。
7.集合:可变、无序序列。,可以增删,没有修改以及查询的操作。

















 213
213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











