






 本文介绍了如何使用PaddlePaddle库在AIStudio上复现HashNet算法,包括模型架构、精度评估、数据集使用、环境配置及训练步骤。作者提供了详细的教程和代码示例,覆盖了模型训练与验证,以及TIPC验证流程。
本文介绍了如何使用PaddlePaddle库在AIStudio上复现HashNet算法,包括模型架构、精度评估、数据集使用、环境配置及训练步骤。作者提供了详细的教程和代码示例,覆盖了模型训练与验证,以及TIPC验证流程。
转自AI Studio,原文链接:
【论文复现】基于 PaddlePaddle 实现 HashNet - 飞桨AI Studio
【论文复现-图像检索】基于 PaddlePaddle 实现 HashNet(ICCV2017)
-
官方原版代码(基于caffe/PyTorch)HashNet.
-
第三方参考代码(基于PyTorch)DeepHash-pytorch.
-
本项目GitHub repo paddle_hashnet,欢迎star~
一、简介
对于大规模的最近邻搜索问题,比如图像检索 Deep Hashing等,哈希学习被广泛应用。然而现有基于深度学习的哈希学习方法需要先学习一个连续表征,再通过单独的二值化来生成二进制的哈希编码,这导致检索质量严重下降。HashNet则提出了两点改进方式:1. 针对不平衡分布的数据做了一个均衡化;2. 针对符号激活进行了改进,即让激活函数 h=tanh(βz)h=tanh(\beta z)h=tanh(βz) 中的 β\betaβ 在训练过程中不断变化最终逼近1。下图展示了 HashNet 的主要架构。
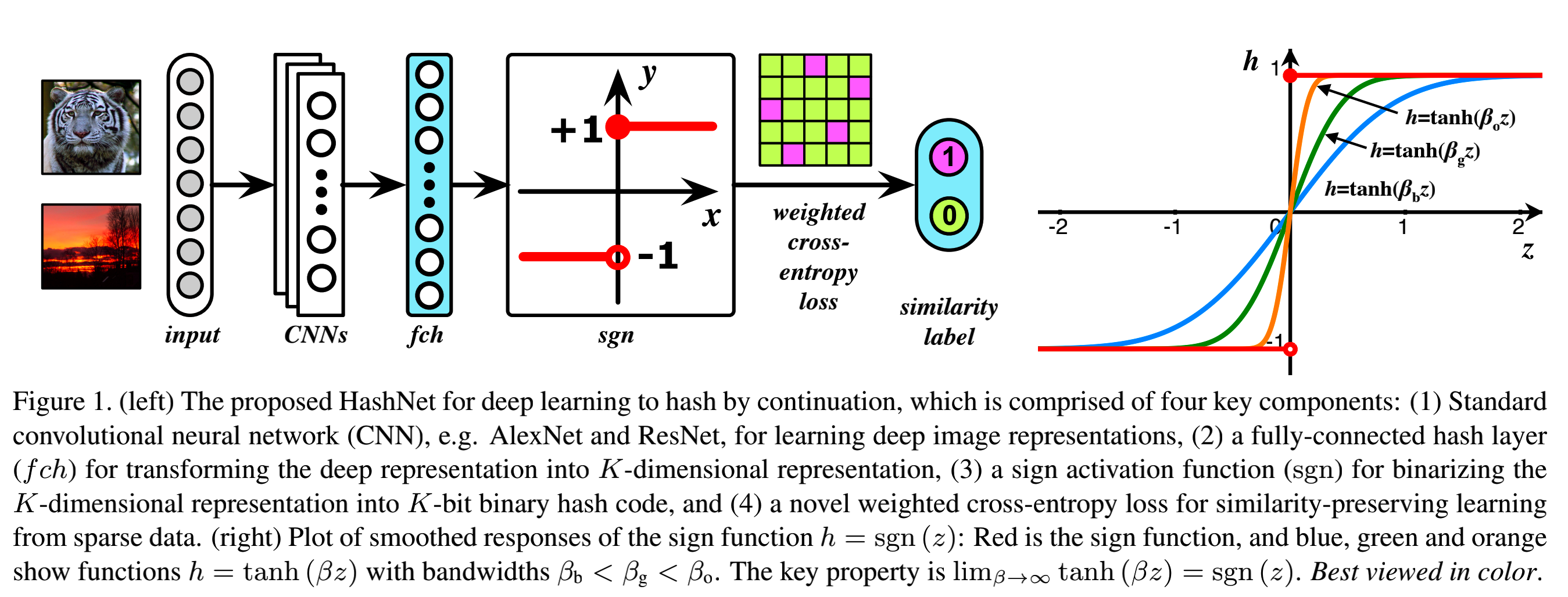
HashNet 架构
二、复现精度
| 16bits | 32bits | 48bits | 64bits | |
|---|---|---|---|---|
| 验收指标 | 0.622 | 0.682 | 0.715 | 0.727 |
| 复现结果 | 0.619 | 0.682 | 0.715 | 0.734 |
本项目(基于 PaddlePaddle )依次跑 16/32/48/64 bits 的结果罗列在上表中,且已将训练得到的模型参数与训练日志 log 存放于paddle_hashnet/output文件夹下。由于训练时设置了随机数种子,理论上是可复现的。
三、数据集
MS COCO(即 COCO2014 )
-
COCO2014 是一个图像识别、分割和字幕数据集。它包含 82,783 张训练图像和 40,504 张验证图像,共 80 个类别。
-
对其中没有类别信息的图像进行剪枝后,将训练图像和验证图像相结合,得到 122218 张图像。然后随机抽取 5000 张图像作为查询集,其余用作数据库;此外,从数据库中随机抽取 10,000 张图像作为训练集。数据集处理代码详见 paddle_hashnet/utils/datasets.py。另外数据集分割好的list放在 paddle_hashnet/data/coco/ 路径下。
-
需要注意的是:通过对比发现,原作者的list与第三方参考代码 DeepHash-pytorch 中的list略有不同,不过经过测试,两种list最终跑出来精度差不多。本项目复现的时候采用与原作者一样的list。
-
数据集准备过程如下:
In [1]
%cd /home/aistudio/data/data107046
!unzip -q val2014.zip
!unzip -q train2014.zip/home/aistudio/data/data107046 val2014/COCO_val2014_000000264819.jpg bad CRC 26cc9046 (should be 31672bf3) train2014/COCO_train2014_000000470472.jpg bad CRC fe4e7fc0 (should be 30b79e46)
- 另外,为了方便快速体验本项目的训练过程,已将少量的 coco 数据(coco_lite)位于 paddle_hashnet/datasets/coco_lite 下,同时对应的 list 在 paddle_hashnet/data/coco_lite 下。
四、环境依赖
本人环境配置:
- Python: 3.7.11
- PaddlePaddle: 2.2.2
- 硬件:NVIDIA 2080Ti * 2
五、快速开始
step1: 下载本项目及训练权重
本项目在AI Studio上,您可以选择fork下来直接运行。
或者,您也可以从GitHub上git本repo在本地运行:
git clone https://github.com/hatimwen/paddle_hashnet.git
cd paddle_hashnet
权重部分:
-
由于权重比较多,加起来有 1 个 GB ,因此我放到百度网盘里了,烦请下载后按照 六、代码结构与详细说明 排列各个权重文件。或者您也可以按照下载某个bit位数的权重以测试相应性能。
-
下载链接:BaiduNetdisk, 提取码: pa1c 。
-
注意:在AI Studio上,已上传了 weights_64.pdparams 权重文件在 paddle_hashnet/output 路径下,方便体验。
step2: 修改参数
请根据实际情况,修改 paddle_hashnet/scripts 中想运行脚本的配置内容(如:data_path, batch_size等)。
step3: 验证模型
- 以
hashnet_64的模型验证为例,在 AI Studio 上,由于已预先上传 weights_64.pdparams 权重文件,因此可以直接运行:
In [2]
%cd /home/aistudio/paddle_hashnet
!python main_single_gpu.py \
--bit 64 \
--eval \
--pretrained output/weights_64 \
--data-path /home/aistudio/data/data107046 \
--batch-size 64/home/aistudio/paddle_hashnet
train_set 10000
test 5000
database 112218
0508 10:32:29 PM
Namespace(alpha=0.1, batch_size=64, bit=64, crop_size=224, data={'train_set': {'list_path': 'data/coco/train.txt', 'batch_size': 64}, 'database': {'list_path': 'data/coco/database.txt', 'batch_size': 64}, 'test': {'list_path': 'data/coco/test.txt', 'batch_size': 64}}, data_path='/home/aistudio/data/data107046', dataset='coco', de_step=50, debug_steps=50, epoch=150, eval=True, eval_epoch=10, last_epoch=0, learning_rate=0.001, log_path='logs/', model='HashNet', momentum=0.9, num_class=80, num_train=10000, optimizer='SGD', output_dir='checkpoints/', pretrained='output/weights_64', resize_size=256, resume=None, seed=2000, step_continuation=20, topK=5000, weight_decay=0.0005)
W0508 22:32:29.411818 3079 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0508 22:32:29.415261 3079 device_context.cc:465] device: 0, cuDNN Version: 7.6.
Loading AlexNet state from path: /home/aistudio/paddle_hashnet/models/AlexNet_pretrained.pdparams
0508 10:32:39 PM ----- Total # of train batch: 157
0508 10:32:39 PM ----- Total # of test batch: 79
0508 10:32:39 PM ----- Total # of base batch: 1754
0508 10:32:41 PM ----- Pretrained: Load model state from output/weights_64.pdparams
0508 10:32:41 PM ----- Start Validating
100%|███████████████████████████████████████████| 79/79 [00:35<00:00, 2.25it/s]
100%|███████████████████████████████████████| 1754/1754 [11:45<00:00, 2.48it/s]
100%|███████████████████████████████████████| 5000/5000 [16:22<00:00, 5.09it/s]
0508 11:01:25 PM EVAL-HashNet, bit:64, dataset:coco, MAP:0.734
注意:在您自己的环境中,需要提前下载并排列好 BaiduNetdisk 中的各个预训练模型。另外,在您自己的环境里,可以用下面的脚本进行模型的验证:
- 多卡,直接运行该脚本:
sh scripts/test_multi_gpu.sh
- 单卡,直接运行该脚本:
sh scripts/test_single_gpu.sh
step4: 训练模型
- 以
hashnet_64在 少量数据coco_lite 上的模型训练为例,在 AI Studio 上可以直接运行:
In [5]
# hashnet_64 coco_lite train:
%cd /home/aistudio/paddle_hashnet
!python main_single_gpu.py \
--bit 64 \
--dataset coco_lite \
--data-path datasets/coco_lite \
--seed 2000 \
--batch-size 10 \
--learning_rate 0.001 \
--epoch 2/home/aistudio/paddle_hashnet
train_set 9
test 4
database 13
0508 11:21:40 PM
Namespace(alpha=0.1, batch_size=10, bit=64, crop_size=224, data={'train_set': {'list_path': 'data/coco_lite/train.txt', 'batch_size': 10}, 'database': {'list_path': 'data/coco_lite/database.txt', 'batch_size': 10}, 'test': {'list_path': 'data/coco_lite/test.txt', 'batch_size': 10}}, data_path='datasets/coco_lite', dataset='coco_lite', de_step=50, debug_steps=50, epoch=2, eval=False, eval_epoch=10, last_epoch=0, learning_rate=0.001, log_path='logs/', model='HashNet', momentum=0.9, num_class=80, num_train=9, optimizer='SGD', output_dir='checkpoints/', pretrained=None, resize_size=256, resume=None, seed=2000, step_continuation=20, topK=5000, weight_decay=0.0005)
W0508 23:21:40.076992 6493 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1
W0508 23:21:40.080780 6493 device_context.cc:465] device: 0, cuDNN Version: 7.6.
Loading AlexNet state from path: /home/aistudio/paddle_hashnet/models/AlexNet_pretrained.pdparams
0508 11:21:44 PM ----- Total # of train batch: 1
0508 11:21:44 PM ----- Total # of test batch: 1
0508 11:21:44 PM ----- Total # of base batch: 2
0508 11:21:44 PM Start training from epoch 1.
0508 11:21:44 PM Epoch[001/002], Step[0000/0001], Loss: 1.2787
0508 11:21:44 PM HashNet[ 1/ 2] bit:64, lr:0.000156250, scale:1.000, train loss:1.279
0508 11:21:45 PM Epoch[002/002], Step[0000/0001], Loss: 1.2734
0508 11:21:45 PM HashNet[ 2/ 2] bit:64, lr:0.000156250, scale:1.000, train loss:1.273
0508 11:21:45 PM ----- Validation after Epoch: 2
100%|█████████████████████████████████████████████| 1/1 [00:00<00:00, 3.49it/s]
100%|█████████████████████████████████████████████| 2/2 [00:00<00:00, 4.75it/s]
100%|███████████████████████████████████████████| 4/4 [00:00<00:00, 3843.58it/s]
0508 11:21:45 PM save in checkpoints/model_best_64
0508 11:21:47 PM Max mAP so far: 0.6074 at epoch_2
0508 11:21:47 PM ----- Save BEST model: checkpoints/model_best_64.pdparams
0508 11:21:47 PM ----- Save BEST optim: checkpoints/model_best_64.pdopt
0508 11:21:47 PM HashNet epoch:2, bit:64, dataset:coco_lite, MAP:0.607, Best MAP(e2): 0.607
0508 11:21:47 PM Training completed for HashNet(64).
0508 11:21:47 PM Best MAP(e2): 0.607
- 而对于
hashnet_64在 完整COCO2014数据集 上的完整模型训练过程,在 AI Studio 上运行下列命令(具体输出不再展示,有兴趣可自行运行训练):
# hashnet_64 COCO2014 train:
cd /home/aistudio/paddle_hashnet
python main_single_gpu.py \
--bit 64 \
--data-path /home/aistudio/data/data107046 \
--seed 2000 \
--batch-size 64 \
--learning_rate 0.001 \
--epoch 150
另外,在您自己的环境里,可以用下面的脚本进行模型的完整训练过程:
- 多卡,直接运行该脚本(本项目运行场景为双卡,因此建议用双卡跑此脚本复现):
sh scripts/train_multi_gpu.sh
- 单卡,直接运行该脚本:
sh scripts/train_single_gpu.sh
step5: 验证预测
- 由于为数据库编码用时较长,因此已将通过 各个bits 的 HashNet 编码得到的数据库编码存在
paddle_hashnet/output/database_code_*.npy。亦可将其删去后运行 paddle_hashnet/predict.py ,会在第一次预测的时候自动保存数据库编码。

验证图片
- 以 64 bits 为例,对于上面的验证图片,验证预测的命令如下:
In [6]
%cd /home/aistudio/paddle_hashnet
!python predict.py \
--bit 64 \
--data_path /home/aistudio/data/data107046/ \
--img resources/COCO_val2014_000000403864.jpg \
--save_path ./output/home/aistudio/paddle_hashnet train_set 10000 test 5000 database 112218 W0508 23:22:46.023320 6662 device_context.cc:447] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 10.1 W0508 23:22:46.026542 6662 device_context.cc:465] device: 0, cuDNN Version: 7.6. Loading AlexNet state from path: /home/aistudio/paddle_hashnet/models/AlexNet_pretrained.pdparams ----- Pretrained: Load model state from output/weights_64 ----- Load code of database from ./output/database_code_64.npy ----- Predicted Hamm_min: 0.0 ----- Found Mateched Pic: /home/aistudio/data/data107046/val2014/COCO_val2014_000000403864.jpg ----- Save Mateched Pic in: ./output/COCO_val2014_000000403864.jpg
显然,匹配结果正确。
六、TIPC
-
本项目为 16/32/48/64 bits 分别写了对应的 TIPC 配置文件, 均位于 paddle_hashnet/test_tipc/configs 文件夹下;另外方便起见, paddle_hashnet/scripts/tipc.sh 是一个直接跑所有 bits 的脚本;
-
详细日志放置在 paddle_hashnet/test_tipc/output 目录下;
-
具体 TIPC 介绍及使用流程请参阅:paddle_hashnet/test_tipc/README.md。
七、代码结构与详细说明
|-- paddle_hashnet
|-- data # 数据集list
|-- coco # 暂时仅验证coco数据集
|-- database.txt # 数据库list
|-- test.txt # 测试集list
|-- train.txt # 训练集list
|-- coco_lite # 用于 TIPC 验证的少量数据list
|-- database.txt # 数据库list
|-- test.txt # 测试集list
|-- train.txt # 训练集list
|-- datasets # 数据集存放位置
|-- coco_lite # 用于 TIPC 验证的少量数据集
|-- train2014 # 训练集图片
|-- val2014 # 测试集图片
|-- deploy
|-- inference_python
|-- infer.py # TIPC 推理代码
|-- README.md # TIPC 推理流程介绍
|-- models # 模型定义
|-- __init__.py
|-- alexnet.py # AlexNet 定义,注意这里有略微有别于 paddle 集成的 AlexNet
|-- hashnet.py # HashNet 算法定义
|-- output # 日志及模型文件
|-- test # 测试日志
|-- log_16.txt # 16bits的测试日志
|-- log_32.txt # 32bits的测试日志
|-- log_48.txt # 48bits的测试日志
|-- log_64.txt # 64bits的测试日志
|-- train # 训练日志
|-- log_16.txt # 16bits的训练日志
|-- log_32.txt # 32bits的训练日志
|-- log_48.txt # 48bits的训练日志
|-- log_64.txt # 64bits的训练日志
|-- weights_16.pdparams # 16bits的模型权重
|-- weights_32.pdparams # 32bits的模型权重
|-- weights_48.pdparams # 48bits的模型权重
|-- weights_64.pdparams # 64bits的模型权重
|-- database_code_16.npy # 数据库通过HashNet得到的16bits编码
|-- database_code_32.npy # 数据库通过HashNet得到的32bits编码
|-- database_code_48.npy # 数据库通过HashNet得到的48bits编码
|-- database_code_64.npy # 数据库通过HashNet得到的64bits编码
|-- scripts
|-- test_multi_gpu.sh # 多卡测试脚本
|-- test_single_gpu.sh # 单卡测试脚本
|-- tipc.sh # TIPC 脚本
|-- train_multi_gpu.sh # 多卡训练脚本
|-- train_single_gpu.sh # 单卡训练脚本
|-- test_tipc # 飞桨训推一体认证(TIPC)
|-- utils
|-- datasets.py # dataset, dataloader, transforms
|-- loss.py # HashNetLoss 定义
|-- lr_scheduler.py # 学习率策略定义
|-- tools.py # mAP计算;随机数种子固定函数;database_code计算
|-- export_model.py # 模型动态转静态代码
|-- main_multi_gpu.py # 多卡训练测试代码
|-- main_single_gpu.py # 单卡训练测试代码
|-- predict.py # 预测演示代码
|-- README.md
八、模型信息
关于模型的其他信息,可以参考下表:
| 信息 | 说明 |
|---|---|
| 发布者 | 文洪涛 |
| hatimwen@163.com | |
| 时间 | 2022.04 |
| 框架版本 | Paddle 2.2.2 |
| 应用场景 | 图像检索 |
| 支持硬件 | GPU、CPU |
| 下载链接 | 预训练模型 提取码: pa1c |
| Github repo | paddle_hashnet |
| License | Apache 2.0 license |
九、参考及引用
@inproceedings{cao2017hashnet,
title={Hashnet: Deep learning to hash by continuation},
author={Cao, Zhangjie and Long, Mingsheng and Wang, Jianmin and Yu, Philip S},
booktitle={Proceedings of the IEEE international conference on computer vision},
pages={5608--5617},
year={2017}
}
十、参赛心得及经验分享
概括来说,本次参赛心得及经验有3点,希望对大家有所启发和帮助:
-
复现代码的第一步就是要跑通别人的代码,这一步非常重要!这样你首先能知道官方代码训练和测试的流程,同时也保证了你要复现的目标是可实现的。在我复现过程中发现原论文开放出来的代码实际跑出来和原论文是有一些出入的。这在实际中也是十分常见的现象,毕竟最终开源出来的代码是在实际做实验的代码基础上”润色“得到的;
-
阅读原论文。建议有时间把Method和Experiment重点阅读,其一是对算法的实现有个印象,实际复现的过程中也是在复现Method,其二就是Experiment中有一些参数和代码config中可能会不一样,这种情况尤其出现在较多backbone和小实验的情况下。
最后,非常感谢百度举办的飞桨论文复现挑战赛(第六期)让本人对 PaddlePaddle 理解更加深刻。

















 628
628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









