






★★★ 本文源自AI Studio社区精品项目,【点击此处】查看更多精品内容 >>>
第一届全国中医药知识图谱构建与应用大赛初赛命名实体识别第一:基于SPANNER实现命名实体识别模型
初赛命名实体识别
初赛最终成绩: 加权F1值69.21%,排名第一
虽然只是个小比赛,而且网上关于知识图谱相关的模型有很多教学代码,但这对于第一次参加算法比赛的肉鸡来说还是非常有价值的。这个比赛是在2022年6,7月左右,由于个人原因没有参加后续决赛,后续的关系抽取部分没有进行实现,同时这个项目是去年只完成一半,有很多地方今年才开始完善,所以可能会存在不足不对的地方,请大佬们多多赐教
1 项目介绍
1.1 赛题背景
知识图谱是近年来知识管理和知识服务领域中出现的一项新兴技术,它为中医临床知识的关联、整合与分析提供了理想的技术手段。我们基于中医医案等临床知识源,初步建立了由疾病、证候、症状、方剂、中药等核心概念所构成的中医临床知识图谱,以促进中医临床知识的互融互通,揭示中医方证的相关关系,辅助中医临床研究和临床决策。
中医药学是一门古老的医学,历代医家在数千年的实践中积累了丰富的临床经验,形成了完整的知识体系,产生了海量的临床文献。近年来,国家对中医药事业大力扶持,中医药领域的临床实践和临床研究都取得了长足的发展。中医临床方法在国际社会得到广泛认可,传播到183个国家和地区。
利用信息技术手段开展中医临床知识的管理和服务是一项开创性的探索,在临床上具有极大的应用价值。近年来,知识图谱(Knowledge Graph)成为知识管理领域中的一项新兴技术,因其简单易学、可扩展性强、支持智能应用等优点而得到广泛应用。它有助于实现临床指南、中医医案以及方剂知识等各类知识的关联与整合,挖掘整理中医临证经验与学术思想,实现智能化、个性化的中医药知识服务,因此在中医临床领域具有广阔的应用前景。
1.2 赛题任务介绍
以主办方提供的标注语料及相关文段作为生产数据,以网络发表的公开的语料集(如人民日报语料集)作为参照数据,使用基于规则、基于字典、机器学习、深度学习等方法进行命名实体识别。
任务目的是从中医药期刊文献的题目和摘要中识别中医药相关实体,实体类型具体包括:中医诊断、西医诊断、中医证候、临床表现、中医治则、方剂、中药、其他治疗等
提供的训练数据为BIO格式,如:
- 现 O
- 头 O
- 昏 O
- 口 B-临床表现
- 苦 I-临床表现
1.3 所需环境
!pip install --upgrade paddlenlp==2.2.6
import paddle
from paddle.io import Dataset
import paddle.nn as nn
import paddle.nn.functional as F
import paddlenlp
from paddlenlp.transformers import LinearDecayWithWarmup
from paddlenlp.data import Stack, Pad, Tuple
from paddlenlp.metrics import ChunkEvaluator
from paddlenlp.layers.crf import LinearChainCrf, LinearChainCrfLoss, ViterbiDecoder
from functools import partial
import numpy as np
import pandas as pd
import time
import os
# # 可视化工具
import seaborn as sns
import matplotlib.pyplot as plt
from visualdl import LogWriter
2 任务一初赛命名实体提取方案介绍
2.1 数据集部分
数据集部分:数据集清洗,包括对部分错标处理、利用词典对漏标进行补充。医案数据对训练集进行补充(这个好像影响不大)
2.2 模型架构部分
三层架构,底层句子表示层,采用ernie-health-chinese百度开源医疗预训练语言模型进行句子向量表示;第二层LSTM层,将第一层输出作为Bi-LSTM层输入让模型学习前后依赖信息;第三层SPAN预测,将第二层LSTM输出(只取序列输出)放到全连接层1预测实体头,输出shape为[batch_size , seq_len , num_labels],然后实体头预测结果和第二层LSTM输出(只取序列输出,输入shape[batch_size , seq_len , hidden_size * 2+1])放到全连接层2预测实体尾。
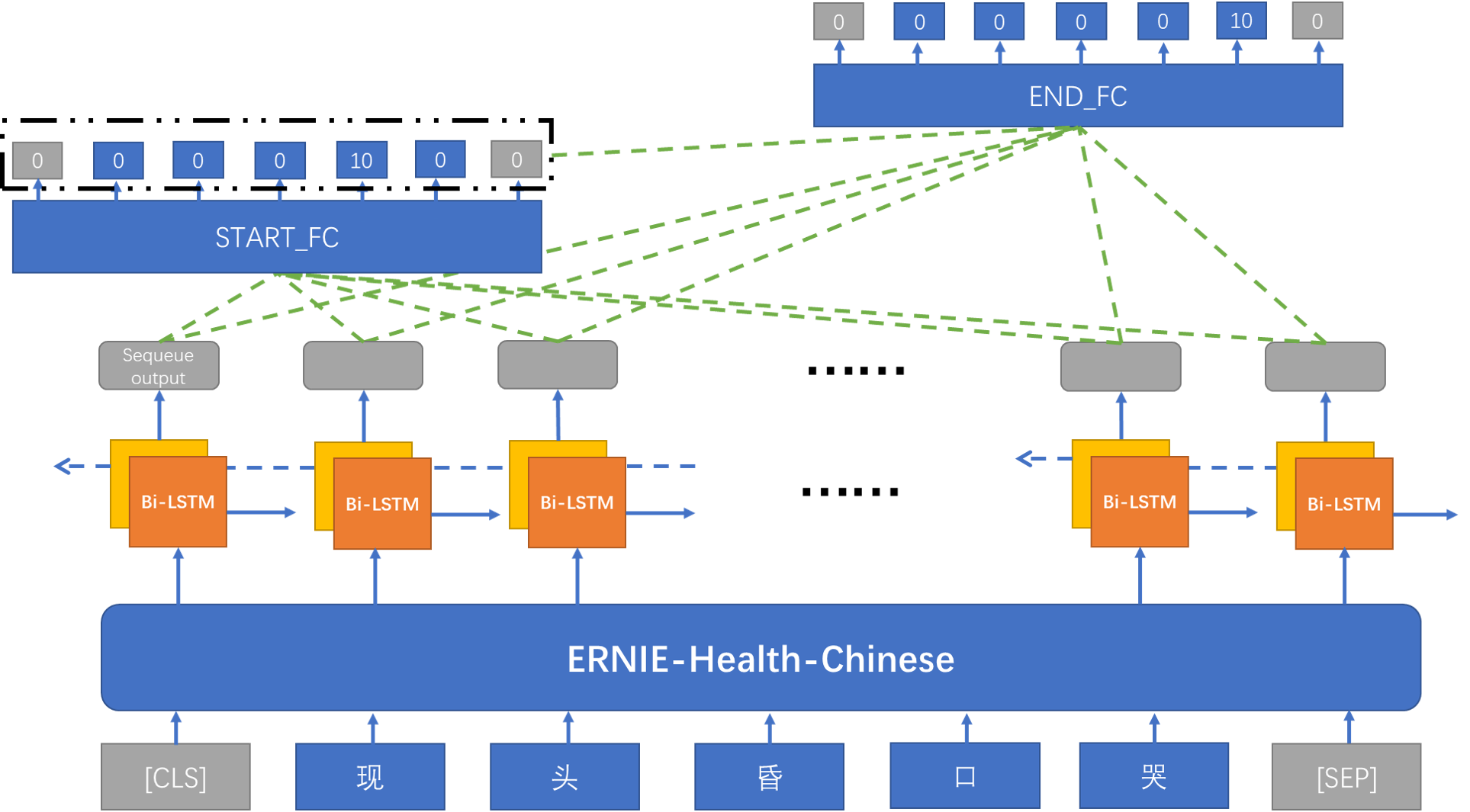
2.3 模型训练优化部分
根据数据探索性分析,损失函数采用多分类的focal loss(label smooth好像也行但没有实现),降低模型对预测实体标签类别有不同倾向,减少标签分类数量不平衡的影响,提高模型泛化性;fgm/pgd强化训练,训练更平稳,减少模型过拟合情况。优化器采用adamW。
Focal loss是最初由何恺明提出的,最初用于图像领域解决数据不平衡造成的模型性能问题。

这里推荐个博客有关于focal loss二分类和多分类的介绍和实现https://blog.csdn.net/u014311125/article/details/109470137
3 赛事数据处理与分析
3.1 数据集加载
数据集有4个包括:训练集、验证集、测试集和相关医案数据,该部分加载的数据集是经过部分处理(去掉标签中字符’B’、‘I’、‘-’,并把一条所有字符拼接),方便数据初始分析及后续转为span格式
span格式的数据集,如:
- 现 O O
- 头 O O
- 昏 O O
- 口 临床表现 O
- 苦 O 临床表现
# 符合span格式的训练集
train_df = pd.read_csv('format_data/train.csv',sep='\t')
# 符合span格式的验证集
dev_df = pd.read_csv('format_data/dev.csv',sep='\t')
# 医案语料
yian_df=pd.read_csv('format_data/yian.csv',sep='\t')
# 符合span格式的测试集
test_df = pd.read_csv('format_data/test.csv',sep='\t')
yian_df['text'].str.len()[:4]
# 医案语料长度
0 1097
1 1257
2 975
3 3095
Name: text, dtype: int64
预处理的标签表读入
命名实体识别对应标签信息读入,标签包括:
O、中医治则、方剂、中医治疗、中医证候、中医诊断、中药、其他治疗、西医治疗、西医诊断、临床表现
labeldict = open('dict/label.txt',mode='r').readlines()
labeldict = [i.strip() for i in labeldict]
label2ids = {x:i for i,x in enumerate(labeldict)}
ids2label = {i:x for i,x in enumerate(labeldict)}
# ids2label、label2ids 用于标签转id、id转标签
3.2 数据集探索性分析
print('数据文本平均长度:',
'\n train:',sum(train_df['text'].str.len()/2)/len(train_df),
'\n dev:',sum(dev_df['text'].str.len()/2)/len(dev_df),
'\n test:',sum(test_df['text'].str.len()/2)/len(test_df))
数据文本平均长度:
train: 37.96937999239255
dev: 38.00762195121951
test: 36.4855403348554
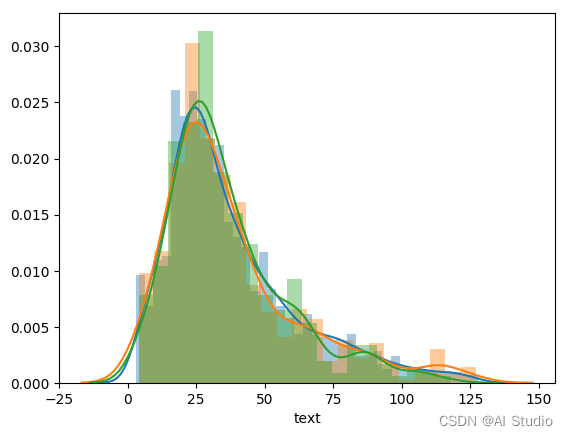
# 数据集中每条数据长度分布,拼接时加了空格符,所以每条数据长度要除2
sns.distplot(train_df['text'].str.len()/2)
sns.distplot(dev_df['text'].str.len()/2)
sns.distplot(test_df['text'].str.len()/2)
# 1.训练集、验证集和测试集每条数据长度同分布
# 2.长度范围为[0,150]
<matplotlib.axes._subplots.AxesSubplot at 0x7f40c97fe310>
from matplotlib import font_manager
plt.rcParams["font.sans-serif"]=["DejaVu"] #设置字体
plt.rcParams["axes.unicode_minus"]=False #该语句解决图像中的“-”负号的乱码问题
font_manager.FontProperties(fname='work/font/SIMHEI.TTF');
def label_count_plot(df):
label_text = ''
for i in df['labels'].str.split():
label_text += ' '.join(i)+' '
# 统计标签数量
plt.figure(figsize=(16,9),dpi=200)
label_count = pd.Series(label_text.split()).value_counts()
ax = sns.barplot(x=label_count.keys()[1:],y=label_count.values[1:])
ax.set_xticklabels(
labels=label_count.keys()[1:],
fontdict={
'fontproperties':font_manager.FontProperties(fname='work/font/SIMHEI.TTF')
},
)
ax.set_xticklabels(ax.get_xticklabels(),rotation = 30);
return label_count
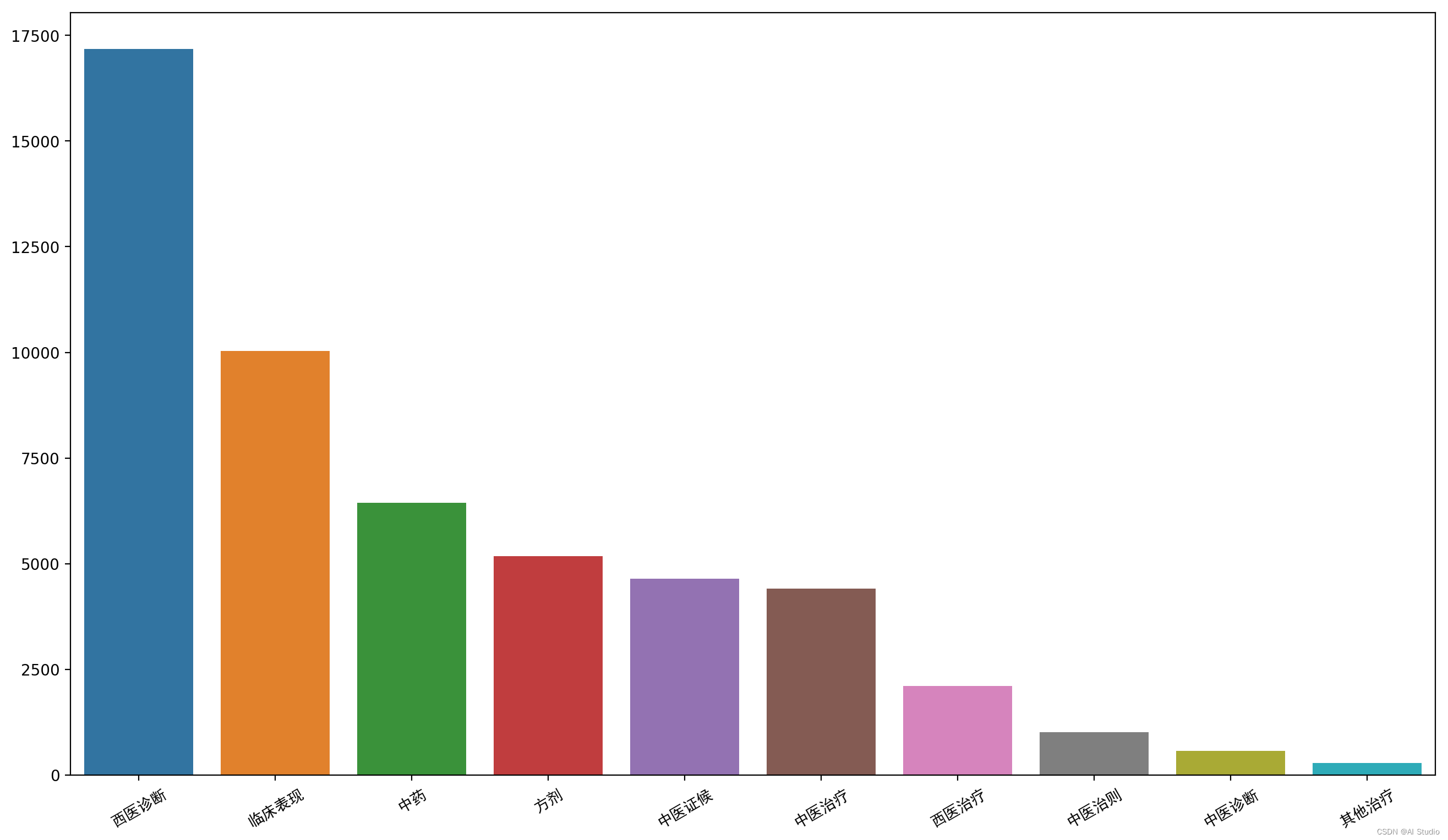
# 统计训练集中实体标签数量,不区分实体头或尾等
train_label_count = label_count_plot(train_df)
# 同理验证集和测试集
# train_label_count = label_count_plot(dev_df)
# train_label_count = label_count_plot(test_df)
def label_count_plot(df):
label_text = ''
for i in df['labels'].str.split():
label_text += ' '.join(i)+' '
# 统计标签数量
plt.figure(figsize=(16,9),dpi=200)
label_count = pd.Series(label_text.split()).value_counts()
ax = sns.barplot(x=label_count.keys()[1:],y=label_count.values[1:])
ax.set_xticklabels(
labels=label_count.keys()[1:],
fontdict={
'fontproperties':font_manager.FontProperties(fname='work/font/SIMHEI.TTF')
},
)
ax.set_xticklabels(ax.get_xticklabels(),rotation = 30);
return label_count
def entity_countplot(label_counter):
entity_counter=dict()
for i in label_counter.keys():
if 'B-' in i:
entity_counter.setdefault(i,label_counter[i])
plt.figure(figsize=(16,5),dpi=200)
ax = sns.barplot(y=list(entity_counter.values()),x=list(entity_counter.keys()))
ax.set_xticklabels(
labels=entity_counter.keys(),
fontdict={'fontproperties':font_manager.FontProperties(fname='work/font/SIMHEI.TTF')},
)
ax.set_xticklabels(ax.get_xticklabels(),rotation = 30);
bio_train_df = pd.read_csv('format_data/bio_train.csv',sep='\t')
bio_dev_df = pd.read_csv('format_data/bio_dev.csv',sep='\t')
bio_test_df = pd.read_csv('format_data/bio_test.csv',sep='\t')
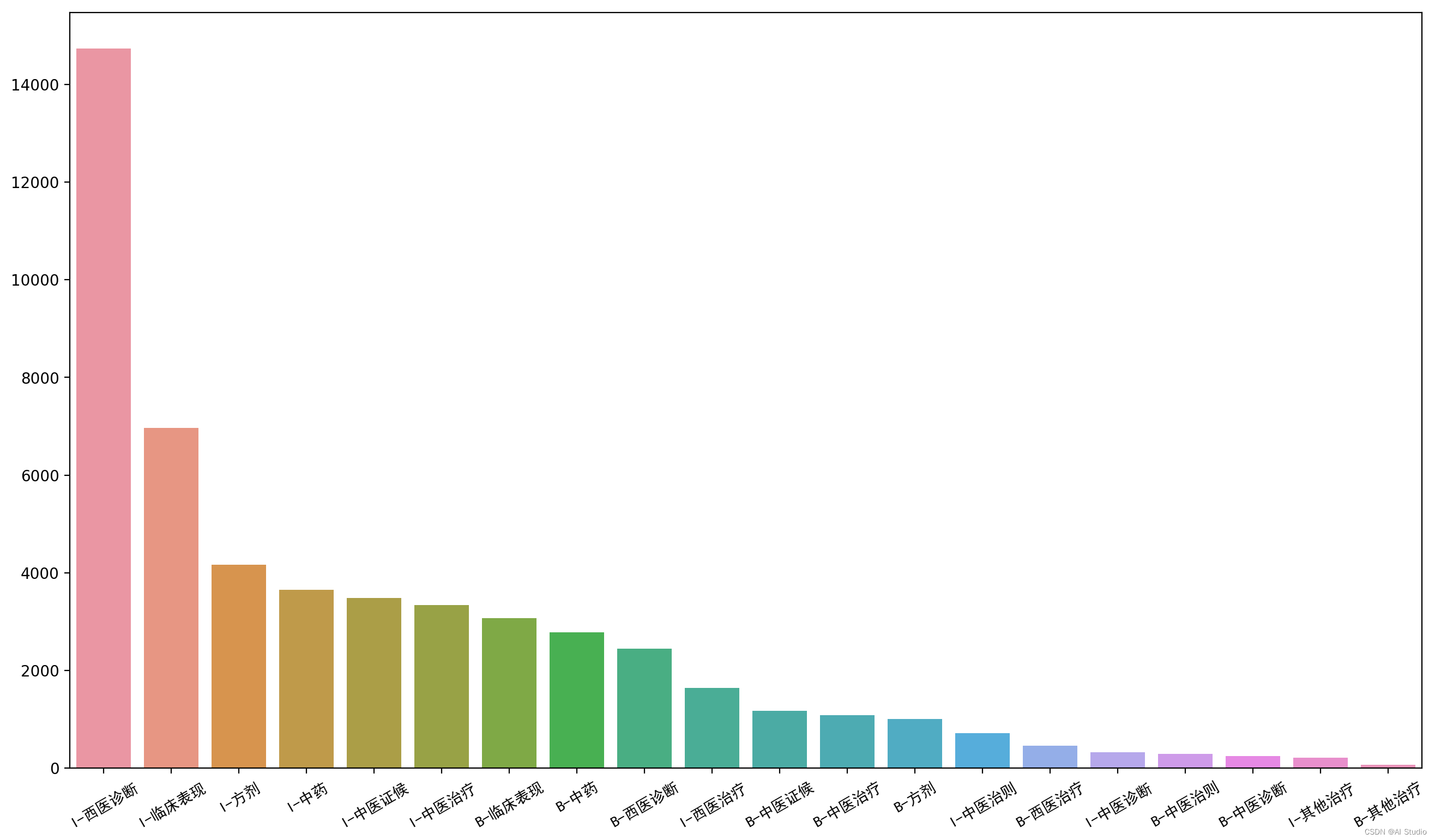
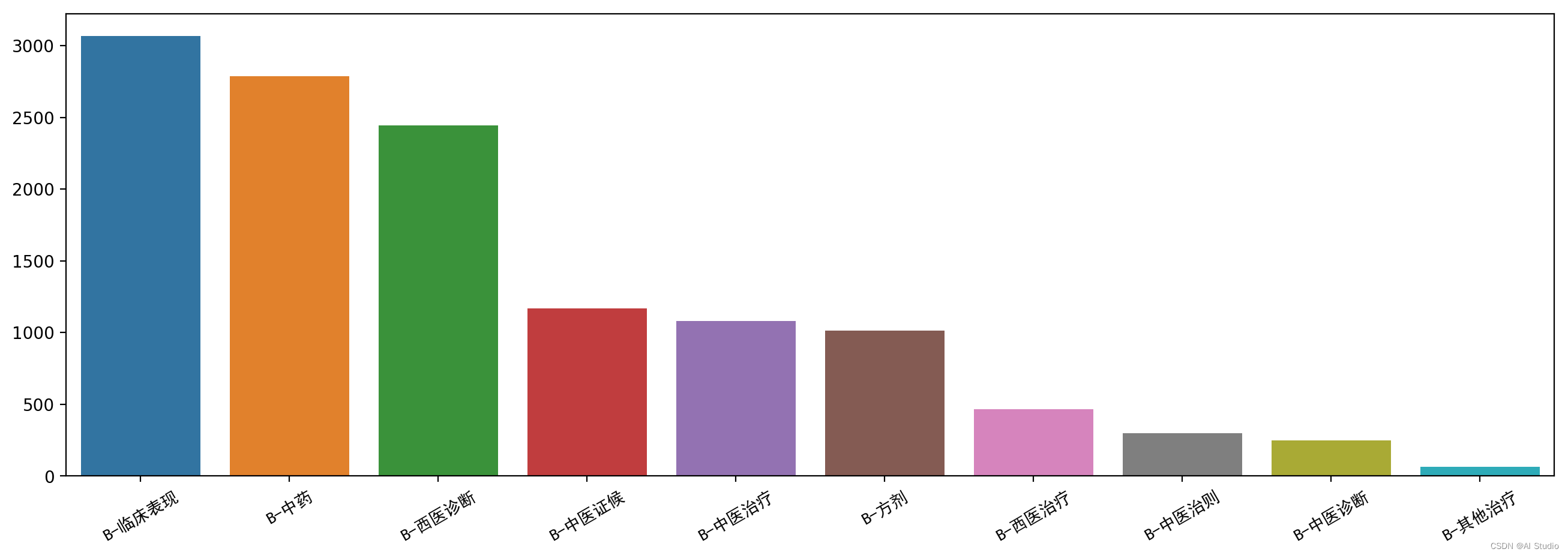
entity_countplot(label_count_plot(bio_train_df))
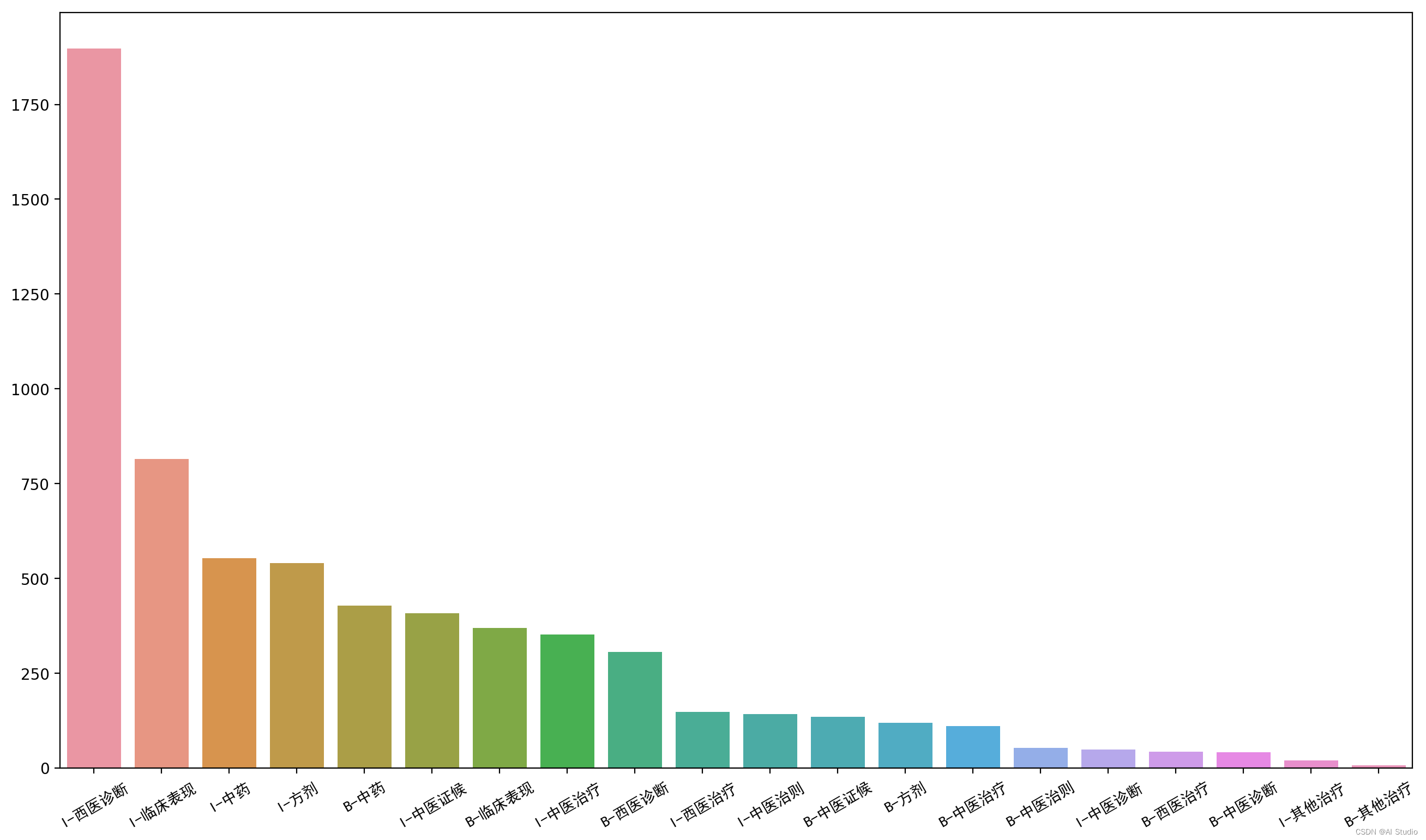
entity_countplot(label_count_plot(bio_dev_df))
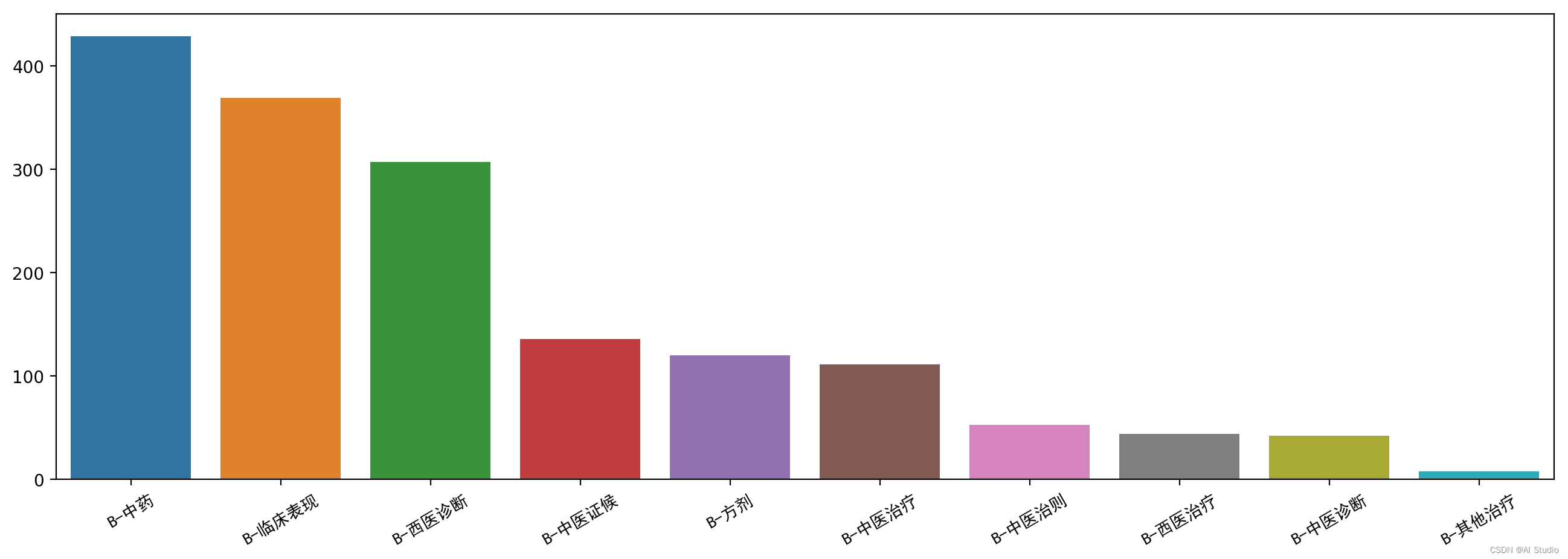
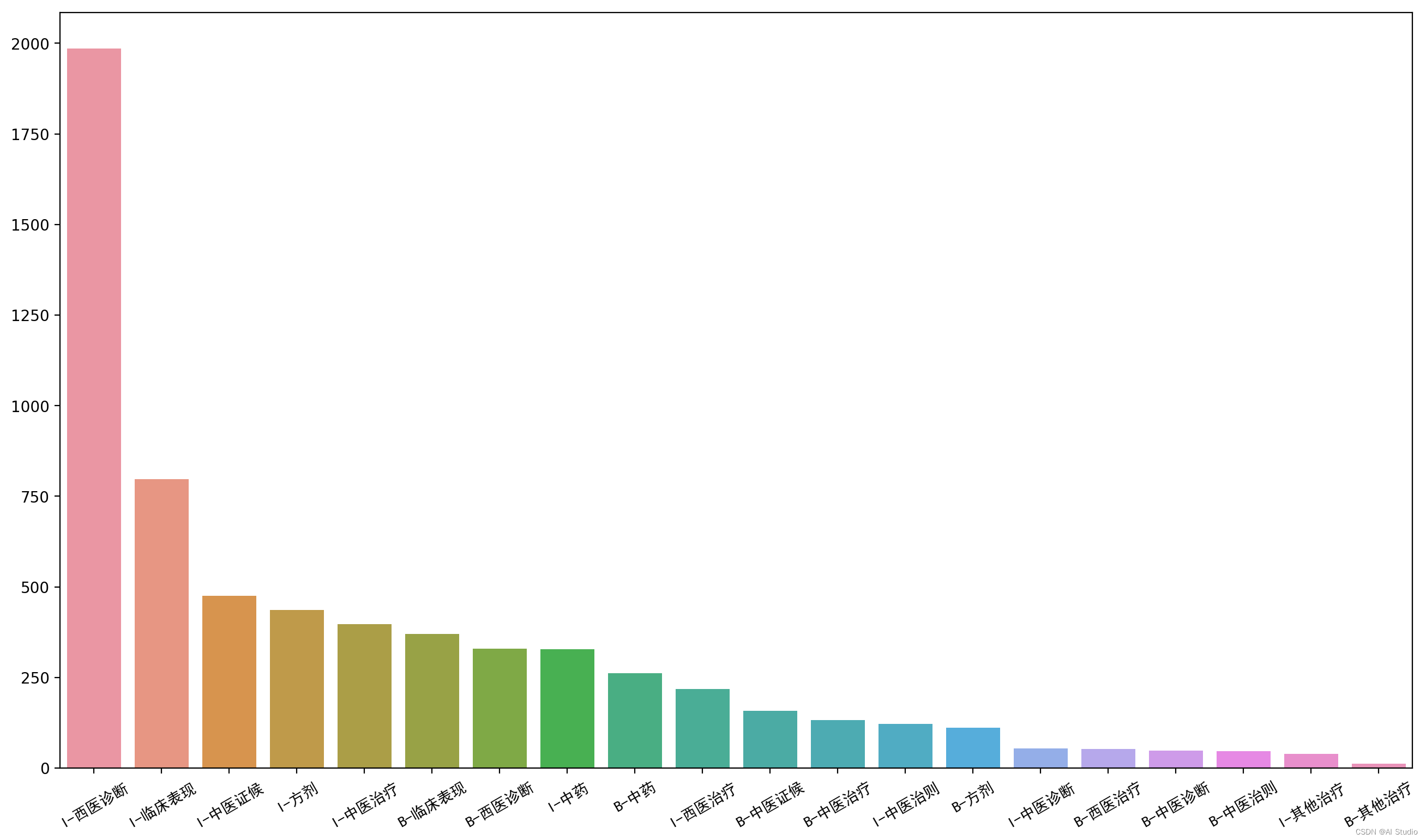
entity_countplot(label_count_plot(bio_test_df))
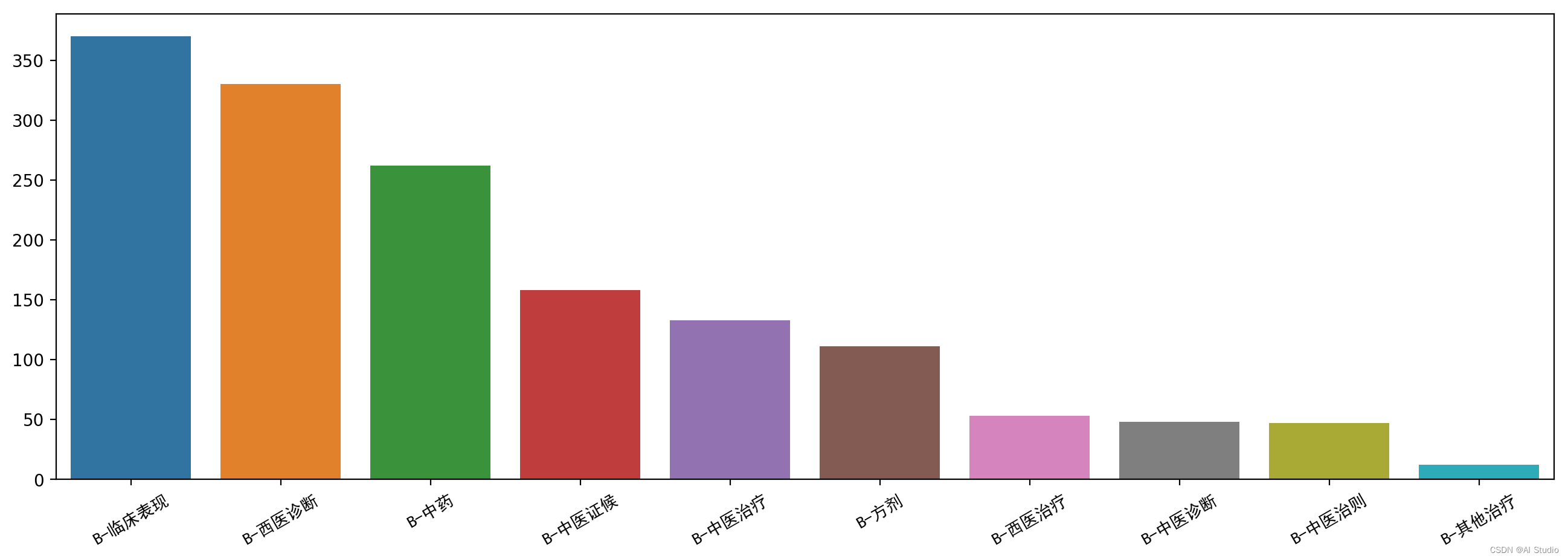
3.3小结
-
训练集、验证集和测试集同分布,长度范围为[0,150],数据平均长度约37
-
同时通过人工检查还发现数据集存在大量漏标、少量错标的情况,后面在数据预处理阶段可以通过实体标签词典来修正补充训练集
-
各标签数量分布非常不均匀,出现最多的的实体是临床表现、西医诊断、中药, 中医诊断、中医治则、其他治疗实体较少,可以考虑补充有相关实体的数据集
4 方案实现
4.1 数据预处理
encoding层句子表示预训练模型使用ernie-health-chinese百度开源医疗预训练语言模型
# 加载预训练模型和模型对应分词工具
pretrained_model = paddlenlp.transformers.AutoModel.from_pretrained('ernie-health-chinese')
tokenizer = paddlenlp.transformers.AutoTokenizer.from_pretrained('ernie-health-chinese')
[2023-02-09 16:32:28,768] [ INFO] - We are using <class 'paddlenlp.transformers.electra.modeling.ElectraModel'> to load 'ernie-health-chinese'.
[2023-02-09 16:32:28,772] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie-health-chinese/ernie-health-chinese.pdparams and saved to /home/aistudio/.paddlenlp/models/ernie-health-chinese
[2023-02-09 16:32:28,775] [ INFO] - Downloading ernie-health-chinese.pdparams from https://paddlenlp.bj.bcebos.com/models/transformers/ernie-health-chinese/ernie-health-chinese.pdparams
100%|██████████| 392M/392M [00:19<00:00, 20.7MB/s]
W0209 16:32:48.748164 184 gpu_resources.cc:61] Please NOTE: device: 0, GPU Compute Capability: 7.0, Driver API Version: 11.2, Runtime API Version: 11.2
W0209 16:32:48.752935 184 gpu_resources.cc:91] device: 0, cuDNN Version: 8.2.
[2023-02-09 16:32:51,206] [ INFO] - We are using <class 'paddlenlp.transformers.electra.tokenizer.ElectraTokenizer'> to load 'ernie-health-chinese'.
[2023-02-09 16:32:51,209] [ INFO] - Downloading https://paddlenlp.bj.bcebos.com/models/transformers/ernie-health-chinese/vocab.txt and saved to /home/aistudio/.paddlenlp/models/ernie-health-chinese
[2023-02-09 16:32:51,212] [ INFO] - Downloading vocab.txt from https://paddlenlp.bj.bcebos.com/models/transformers/ernie-health-chinese/vocab.txt
100%|██████████| 109k/109k [00:00<00:00, 2.26MB/s]
4.1.1 文本数据分词tokenize
# 通过预处理获得每个标签对应实体名称,用于修正训练集
def load_dictionary(dictionary_path):
dictionary = {}
for i in labeldict[1:]:
with open(dictionary_path+i+'.txt','r') as f:
data = (' '.join(f.readlines())).split()
dictionary[i] = set(data)
return dictionary
dictionary = load_dictionary('dict/dictionary/')
from utils.BIO2SPAN import BIO2SPAN
from utils.addDict2Span import addDict2Span
# 将字符数据转换为对应向量,span格式只在实体开头第一个字和最后一个字表示
def convert_example(
text,
label2ids,
labels=None,
tokenizer=None,
max_seq_length=180,
is_test=False,
dictionary=dictionary,
is_SPAN=True,
is_BIO=False
):
encoded_inputs = tokenizer(
text=text,
max_seq_len=max_seq_length,
)
input_ids = encoded_inputs["input_ids"]
token_type_ids = encoded_inputs["token_type_ids"]
if is_test:
return input_ids, token_type_ids
else:
if is_SPAN:
label_start, label_end = BIO2SPAN(labels, label2ids, len(input_ids))
# assert len(input_ids) == len(token_type_ids) == len(label_start) == len(label_end)
if not dictionary==None: # 在不修改原本标注下,补充基于span的词典信息
# 根据词典信息补充漏标实体,考虑到addDict2Span是在项目运行时才运行的,可能会影响程序性能
# 后续可以优化
label_start, label_end = addDict2Span(text, dictionary,label_start, label_end, label2ids)
return input_ids, token_type_ids, label_start, label_end
elif is_BIO:
label = ['O'] + labels.split() + ['O']
label = [label2ids[i] for i in label]
return input_ids, token_type_ids, label
idx = 13
input_ids, token_type_ids, label_start, label_end = convert_example(
text=train_df['text'][idx],
label2ids=label2ids,
labels=train_df['labels'][idx],
tokenizer=tokenizer
)
print('text:',' '.join(train_df['text'][idx].split()),' input_ids:',input_ids)
print('label:',train_df['labels'][idx])
print('token_type_ids:',token_type_ids)
print('label_start:',label_start)
print('label_end:',label_end)
text: 1 9 9 9 年 4 月 1 2 日 起 恶 寒 发 热 , 头 痛 身 楚 , 腹 胀 纳 呆 , 溲 黄 便 软 , 谷 丙 转 氨 酶 & g t input_ids: [2, 20, 746, 746, 746, 151, 405, 53, 20, 249, 362, 108, 649, 890, 61, 273, 1, 147, 95, 194, 794, 1, 276, 523, 1607, 1763, 1, 5102, 348, 202, 525, 1, 1360, 1298, 474, 869, 974, 1, 1287, 1525, 3]
label: O O O O O O O O O O O O O O O O O O O O O O O 临床表现 临床表现 O O O O O O O O O O O O O O
token_type_ids: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
label_start: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 10, 0, 0, 0, 0, 0, 0, 0, 10, 0, 10, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
label_end: [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 10, 0, 0, 0, 0, 0, 0, 0, 10, 0, 10, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]
# 为了后续方便使用,我们给 convert_example 赋予一些默认参数
# 训练集的样本转换函数
trans_func = partial(
convert_example,
label2ids=label2ids,
tokenizer=tokenizer,
max_seq_length=None
)
4.2 自定义dataset、dataLoader
class my_Dataset(Dataset):
def __init__(self, data, trans_func, is_test=False):
super(my_Dataset, self).__init__()
self.data = data
self.trans_func = trans_func
self.is_test = is_test
def __getitem__(self, index):
if self.is_test == False:
input_ids, token_type_ids, label_start, label_end = self.trans_func(
text = self.data['text'][index],
labels = self.data['labels'][index],
is_test = self.is_test
)
return input_ids, token_type_ids, label_start, label_end
if self.is_test:
input_ids, token_type_ids = self.trans_func(
text = self.data['text'][index],
is_test = self.is_test
)
return input_ids, token_type_ids
def __len__(self):
return len(self.data)
train_df = train_df.append(dev_df, ignore_index = True)
train_ds = my_Dataset(train_df, trans_func,is_test=False)
test_ds = my_Dataset(test_df, trans_func,is_test=False)
# 我们的训练数据会返回 input_ids, token_type_ids, seq_len, labels 4 个字段
# 因此针对这 4 个字段需要分别定义 4 个组 batch 操作
# 训练集和验证集batchify_fn
ignore_label = -1 # 将填充的标签设为-1
batchify_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
Pad(axis=0, pad_val=ignore_label), # label_start
Pad(axis=0, pad_val=ignore_label) # label_end
): fn(samples)
# 测试集的batchify_fn
batchify_test_fn = lambda samples, fn=Tuple(
Pad(axis=0, pad_val=tokenizer.pad_token_id), # input_ids
Pad(axis=0, pad_val=tokenizer.pad_token_type_id), # token_type_ids
): fn(samples)
batch_sampler = paddle.io.DistributedBatchSampler(train_ds, batch_size=128, shuffle=True)
train_dataloader = paddle.io.DataLoader(
dataset=train_ds,
batch_sampler=batch_sampler,
collate_fn=batchify_fn
)
# 定义 test_data_loader
batch_sampler = paddle.io.BatchSampler(test_ds, batch_size=1, shuffle=False)
test_dataloader = paddle.io.DataLoader(
dataset=test_ds,
batch_sampler=batch_sampler,
collate_fn=batchify_fn,
# collate_fn=batchify_test_fn,
)
4.3 命名实体识别模型搭建
from model.loss.focalloss import FocalLoss
# from model.biaffine import Biaffine1, Biaffine2 # 双仿射变化模块
from model.net import BertLSTMSpanNER, BertSpanNER, BertLstmCrf
from model.ErnieSeqLabelModel import ErnieSeqLabel
from model.AdversarialTrain_block import FGM, PGD
class BertLSTMSpanNER(nn.Layer):
def __init__(
self,
pretrained_model,
num_labels,
ignore_label=-1,
loss_type='ce'):
super().__init__()
self.loss_type = loss_type
self.num_labels = num_labels
self.encoder = pretrained_model
self.dropout = nn.Dropout(0.1)
self.lstm = nn.LSTM(
input_size=self.encoder.config['hidden_size'],
hidden_size=int(self.encoder.config['hidden_size']/2),
dropout=0.1,
direction='bidirect'
)
self.start_fc = nn.Linear(
in_features=self.encoder.config['hidden_size'],
out_features=num_labels,
)
self.end_fc = nn.Sequential(
nn.Linear(self.encoder.config['hidden_size']+1,self.encoder.config['hidden_size']),
nn.Tanh(),
nn.LayerNorm(self.encoder.config['hidden_size']),
nn.Linear(self.encoder.config['hidden_size'],num_labels)
)
# 损失函数确定
assert self.loss_type in ['lsc', 'fcl', 'ce']
if self.loss_type =='lsc':
self.loss_fct = LabelSmoothingCrossEntropy()
elif self.loss_type == 'fcl':
self.loss_fct = FocalLoss(num_classes=self.num_labels)
else:
self.loss_fct = nn.loss.CrossEntropyLoss(ignore_index=ignore_label)
def forward(
self,
input_ids,
token_type_ids,
label_start=None,
label_end=None):
sequence_out = self.encoder(
input_ids,
token_type_ids=token_type_ids
)
sequence_out,_ = self.lstm(self.dropout(sequence_out)) # [batch_size , seq_len , hidden_size*2]
start_logits = self.start_fc(sequence_out) # 实体头预测 [batch_size , seq_len , num_labels]
start_preds = paddle.cast(start_logits.argmax(-1).unsqueeze(2), dtype='float32') # [batch_size , seq_len , 1]
end_logits = self.end_fc(paddle.concat([sequence_out,start_preds],axis=-1)) # 实体尾预测 输入shape[batch_size , seq_len , hidden_size*2+1]
outputs = start_logits, end_logits # 模型结果推断
# 计算loss
if label_start is not None and label_end is not None:
start_loss = self.loss_fct(start_logits, label_start)
end_loss = self.loss_fct(end_logits, label_end)
total_loss = (start_loss + end_loss) / 2
outputs = total_loss
# 训练时返回loss, 推断时返回logits
return outputs
对抗训练基本原理,训练过程中在embeding层增加扰动作为一种regularization,提高模型的泛化能力。https://zhuanlan.zhihu.com/p/91269728
# FGM对抗训练step函数
def fgm_step(input_ids,token_type_ids,label_start,label_end):
fgm.attack() # 在embedding上添加对抗扰动
loss_adv = model(
input_ids,
token_type_ids=token_type_ids,
label_start=label_start,
label_end=label_end
)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
fgm.restore() # 恢复embedding参数
# PGM对抗训练step函数
def pgm_step( input_ids,token_type_ids,label_start,label_end):
pgd.backup_grad()
# 对抗训练
K = 3
for t in range(K):
# 在embedding上添加对抗扰动, first attack时备份param.data
pgd.attack(is_first_attack=(t==0))
if t != K-1:
optimizer.clear_grad()
else:
pgd.restore_grad()
loss_adv = model(
input_ids,
token_type_ids=token_type_ids,
label_start=label_start,
label_end=label_end
)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数
#超参数设置
loss_type='fcl'
num_epochs = 100
lr = 9e-5
use_AT=2 # 0 不用对抗训练, 1使用FGM对抗训练, 2使用PGD对抗训练
save_param_path='ckp/best_model/' # 训练完成的模型存放路径
save_best_threshold=0.85 # 测试集准确率阈值,超过该阈值则保存模型参数
model = BertLSTMSpanNER(
pretrained_model=pretrained_model,
num_labels=len(label2ids),
loss_type=loss_type
)
if use_AT == 1:
fgm = FGM(model)
elif use_AT == 2:
pgd = PGD(model)
for step, batch in enumerate(train_dataloader, start=1):
input_ids, token_type_ids, label_start, label_end = batch
loss = model(
input_ids,
token_type_ids=token_type_ids,
label_start=label_start,
label_end=label_end
)
loss.backward()
# pgm_step(input_ids,token_type_ids,label_start,label_end)
print(loss)
if step==5:
break
Tensor(shape=[1], dtype=float32, place=Place(gpu:0), stop_gradient=False,
[1.90028715])
Tensor(shape=[1], dtype=float32, place=Place(gpu:0), stop_gradient=False,
[1.88355613])
Tensor(shape=[1], dtype=float32, place=Place(gpu:0), stop_gradient=False,
[1.88647342])
Tensor(shape=[1], dtype=float32, place=Place(gpu:0), stop_gradient=False,
[1.88523901])
Tensor(shape=[1], dtype=float32, place=Place(gpu:0), stop_gradient=False,
[1.87226939])
4.4 模型评估与训练
# 定义 learning_rate_scheduler,负责在训练过程中对 lr 进行调度
lr_scheduler = LinearDecayWithWarmup(
learning_rate=lr,
total_steps=50 * num_epochs,
warmup=0.1
)
decay_params = [
p.name for n, p in model.named_parameters()
if not any(nd in n for nd in ["bias", "norm"])
]
optimizer = paddle.optimizer.AdamW(
learning_rate=lr_scheduler,
parameters=model.parameters(),
apply_decay_param_fun=lambda x: x in decay_params)
from collections import Counter
class SpanEntityMetric(object):
def __init__(self, ids2label):
self.ids2label = ids2label
self.reset()
def reset(self):
self.origins = []
self.founds = []
self.rights = []
def compute(self, origin, found, right):
recall = 0 if origin == 0 else (right / origin)
precision = 0 if found == 0 else (right / found)
f1 = 0. if recall + precision == 0 else (2 * precision * recall) / (precision + recall)
return precision, recall, f1
def result(self):
class_info = {}
#
origin_counter = Counter([self.ids2label[x[0]] for x in self.origins])
found_counter = Counter([self.ids2label[x[0]] for x in self.founds])
right_counter = Counter([self.ids2label[x[0]] for x in self.rights])
for type_, count in origin_counter.items():
origin = count
found = found_counter.get(type_, 0)
right = right_counter.get(type_, 0)
precision,recall, f1 = self.compute(origin, found, right)
class_info[type_] = {"acc": round(precision, 4), 'recall': round(recall, 4), 'f1': round(f1, 4)}
origin = len(self.origins)
found = len(self.founds)
right = len(self.rights)
precision, recall, f1 = self.compute(origin, found, right)
return {'precision': precision, 'recall': recall, 'f1': f1}, class_info
def update(self, true_subject, pred_subject):
self.origins.extend(true_subject)
self.founds.extend(pred_subject)
self.rights.extend([pre_entity for pre_entity in pred_subject if pre_entity in true_subject])
metric = SpanEntityMetric(ids2label)
# 从预测的span实体中提取实体及其标签函数
def extract_item(line_start, line_end):
S = []
for i, s_l in enumerate(line_start):
if s_l == label2ids['O'] or s_l == -1:
continue
for j, e_l in enumerate(line_end[i:]):
if s_l == e_l:
S.append((s_l, i, i + j))
break
return S
# 合并邻近且标签相同的实体函数
def combine_item(pred_labels):
# pred_labels : [(predict_label_ids, predict_label_start, predict_label_end)*n]
# batch中每条数据按预测实体的start增序排序
combined_pred = []
flag_istaken = False
for index in range(len(pred_labels)):
if flag_istaken:
flag_istaken=False
continue
elif index==(len(pred_labels)-1):
combined_pred.append(pred_labels[index])
break
cur_labelid, cur_start, cur_end = pred_labels[index]
next_labelid, next_start, next_end = pred_labels[index+1]
if (cur_labelid == next_labelid) and (cur_end+1 == next_start):
combined_pred.append((cur_labelid, cur_start, next_end))
flag_istaken = True
else:
combined_pred.append((cur_labelid, cur_start, cur_end))
return combined_pred
# 模型评估函数
@paddle.no_grad()
def do_evaluate(data_loader):
metric.reset()#评估器复位
#依次处理每批数据
for input_ids, token_type_ids, label_start, label_end in data_loader:
# 训练时返回loss, 推断时返回logits
start_logits,end_logits = model(input_ids,token_type_ids=token_type_ids)
label_start = label_start.cpu().numpy()[:,1:-1]
label_end = label_end.cpu().numpy()[:,1:-1]
start_pred = paddle.argmax(start_logits,-1).cpu().numpy()[:,1:-1]
end_pred = paddle.argmax(end_logits,-1).cpu().numpy()[:,1:-1]
for i in range(len(label_start)):
label = extract_item(label_start[i], label_end[i])
pred = extract_item(start_pred[i], end_pred[i])
# pred = combine_item(pred) # 将预测相邻的且标签相同的合并为一个实体
metric.update(true_subject=label, pred_subject=pred)
return metric.result()
global_step = 0
for epoch in range(1, num_epochs + 1):
for step, batch in enumerate(train_dataloader, start=1):
model.train()
input_ids, token_type_ids, label_start, label_end = batch
loss = model(
input_ids,
token_type_ids=token_type_ids,
label_start=label_start,
label_end=label_end
)
loss.backward()
if use_AT == 1: # 对抗训练FGM
fgm_step(input_ids,token_type_ids,label_start,label_end)
elif use_AT == 2: # 对抗训练PGD
pgm_step(input_ids,token_type_ids,label_start,label_end)
optimizer.step()
lr_scheduler.step()
optimizer.clear_grad()
global_step += 1
# 每 step评估模型在验证集上的情况
if global_step % 40 == 0:
model.eval()
total_metric, _ = do_evaluate(test_dataloader)
print(
"gloabal_step:%d train-epoch:%d train_loss: %.6f" % (global_step, epoch, loss)
)
print('(eval):',total_metric)
# 保存最好模型,存储模型参数
if total_metric['f1'] > save_best_threshold:
save_best_threshold = total_metric['f1']
print('saving best model...')
save_path = os.path.join(
save_param_path,
str(save_best_threshold)+'ernie_lstm_span_model_state.pdparams'
)
paddle.save(model.state_dict(), save_path)
# 每10个epoch评估一下模型在训练集的情况
if epoch % 10 == 0:
model.eval()
total_metric,_ = do_evaluate(train_dataloader)
print('(train)',total_metric)
4.5 模型推断
# 推断函数, 返回[batch_size : n*(pred_item_labelid, pred_start, pred_end)]
@paddle.no_grad()
def do_infer(data_loader):
model.eval()
preds={i:list() for i in range(len(data_loader))} # {index : entities}
for index, batch in enumerate(data_loader):
if len(batch)==4:
input_ids, token_type_ids, label_start, label_end = batch
else:
input_ids, token_type_ids = batch
# 训练时返回loss, 推断时返回logits
start_logits,end_logits = model(input_ids,token_type_ids=token_type_ids)
start_pred = paddle.argmax(start_logits,-1).cpu().numpy()[:,1:-1]
end_pred = paddle.argmax(end_logits,-1).cpu().numpy()[:,1:-1]
for i in range(len(start_pred)):
pred = extract_item(start_pred[i], end_pred[i])
pred = combine_item(pred) # 将预测相邻的且标签相同的合并为一个实体
preds[index].append(pred)
return preds
pretrained_path = 'ckp/pretrained_ernie-health-zh' # ernie_health_zh
dictionary_path = 'dict/dictionary/'
infer_file_path = 'data/infer_bio/'
# trained_model_params_path = 'ckp/best_model/final/ernie_span_model_state.pdparams'
output_path = 'result/'
# # 最好模型参数读入
# best_model_param=paddle.load(trained_model_params_path)
# model.load_dict(trained_model_params)
def vec2result(result):
result_datalist = [] # entity_name, entity_label, text
for index in result:
text = ''.join(test_df['text'][index].split())
for entity in result[index][0]:
e_label, e_start, e_end = entity
entity_name = text[e_start:e_end+1]
entity_label = ids2label[e_label]
result_datalist.append((entity_name, entity_label, text))
return result_datalist
# 开始推断
result = do_infer(test_dataloader)
output = vec2result(result)
# 结果保存
output_df = pd.DataFrame(output,columns=['entity_name','entity_label', 'text'])
output_df.to_csv(os.path.join(output_path,'result.csv'),index=False,encoding='utf8')
metric_result = do_evaluate(test_dataloader)
print(metric_result)
({'precision': 0.8323500491642084, 'recall': 0.8593908629441624, 'f1': 0.8456543456543456}, {'中医诊断': {'acc': 0.7922, 'recall': 0.7176, 'f1': 0.7531}, '西医治疗': {'acc': 0.8478, 'recall': 0.9512, 'f1': 0.8966}, '西医诊断': {'acc': 0.8796, 'recall': 0.9385, 'f1': 0.9081}, '中医治则': {'acc': 0.7273, 'recall': 0.678, 'f1': 0.7018}, '中医治疗': {'acc': 0.9255, 'recall': 0.949, 'f1': 0.9371}, '临床表现': {'acc': 0.737, 'recall': 0.755, 'f1': 0.7459}, '中医证候': {'acc': 0.8909, 'recall': 0.9032, 'f1': 0.897}, '其他治疗': {'acc': 0.8235, 'recall': 0.8235, 'f1': 0.8235}, '方剂': {'acc': 0.8054, 'recall': 0.8869, 'f1': 0.8442}, '中药': {'acc': 0.8818, 'recall': 0.9122, 'f1': 0.8968}})
output_df
| entity_name | entity_label | text | |
|---|---|---|---|
| 0 | 黄疸 | 中医诊断 | 药进10帖,黄疸稍退,饮食稍增,精神稍振 |
| 1 | 法莫替丁 | 西医治疗 | 加味左金丸联合法莫替丁治疗胃食管反流病临床观察 |
| 2 | 胃食管反流病 | 西医诊断 | 加味左金丸联合法莫替丁治疗胃食管反流病临床观察 |
| 3 | 疏肝行气 | 中医治则 | “疏肝行气,调神解郁”推拿法结合西药治疗腹泻型ibs的临床疗效 |
| 4 | 调神解郁 | 中医治则 | “疏肝行气,调神解郁”推拿法结合西药治疗腹泻型ibs的临床疗效 |
| ... | ... | ... | ... |
| 2029 | 香砂养胃丸 | 方剂 | 方法:将96例寒热错杂型慢性萎缩性胃炎患者随机分为2组,各48例,对照组服用香砂养胃丸治疗,... |
| 2030 | 半夏泻心汤加味 | 方剂 | 方法:将96例寒热错杂型慢性萎缩性胃炎患者随机分为2组,各48例,对照组服用香砂养胃丸治疗,... |
| 2031 | 功能性消化不良 | 西医诊断 | 免煎中药柴平舒胃汤加减治疗功能性消化不良的临床研究 |
| 2032 | 柴胡疏肝散 | 方剂 | 柴胡疏肝散对功能性消化不良患者胃动力及胃肠激素的影响 |
| 2033 | 功能性消化不良 | 西医诊断 | 柴胡疏肝散对功能性消化不良患者胃动力及胃肠激素的影响 |
2034 rows × 3 columns
4.6 不同方案测试集F1值比较(部分)
| 方案(不包括对抗训练和数据集修正) | 测试集F1值 |
|---|---|
| BERT+LSTM+CRF(baseline) | 0.73919 |
| Ernie-health-ch+Bi-LSTM+CRF(BIO) | 0.78621 |
| Ernie-health-ch+MLP(SPAN) | 0.80161 |
| Nezha-wwm-large-chinese+Bi-LSTM+SPAN_predict(focal loss) | 0.80034 |
| Ernie-health-ch+Bi-LSTM+SPAN_predict(focal loss) | 0.81412 |
对抗训练FMG/PGD提升1个点左右,数据集修正(补充漏标为主)提升3-4个点
在主办方第一次发放中测试集F1值为0.85左右,第二次最终测试集加权F1值为0.6921,初赛第一
5 总结
22年7月左右的小比赛,肉鸡选手第一次参加,其实主要是报着学习的心得参加,积极收集各种资料,通过这次比赛也学会了很多模型搭建调优,更发现了更多自己的不足,如写代码时粗心大意,可以多使用assert检查自己代码,模型搭建也比较不熟手,可以多用shape观察每层输入输出情况。
模型很重要,数据集也很重要!
方案还有更多可以优化之处,如将输出字符偏旁部首拆字作为补充输入信息,将医案、期刊等语料给编码层做预预训练,模型融合、K折交叉训练、伪标签等等,但由于能力和时间有限没法完成。
最后,项目代码是去年6月份写的,其余是今年补充,所以难免存在错误,请大佬们多多指正0.0
参考资料
[1] 【Paddle打比赛】产品评论观点提取竞赛 baseline https://aistudio.baidu.com/aistudio/projectdetail/2417709
[2] CCKS2021阿里天池地址识别-BERT+BiGRU+CRF https://aistudio.baidu.com/aistudio/projectdetail/2272540
[3] 应用BERT模型做命名实体识别任务(Paddle2.0) https://aistudio.baidu.com/aistudio/projectdetail/1477098
[4] 你的CRF层的学习率可能不够大 https://kexue.fm/archives/7196
[5] 基于实体首尾指针SPAN的序列标注框架https://github.com/wzzzd/lm_ner_span
[6] 【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现
https://zhuanlan.zhihu.com/p/91269728
[7] 【炼丹技巧】功守道:NLP中的对抗训练 + PyTorch实现
https://zhuanlan.zhihu.com/p/91269728
[8] Focal Loss的理解以及在多分类任务上的使用(Pytorch)https://blog.csdn.net/u014311125/article/details/109470137
[9] 中医临床知识图谱的构建与应用https://x.cnki.net/xmlRead/xml.html?pageType=web&fileName=KJXS201704018&tableName=CJFDTOTAL&dbCode=CJFD&topic=&fileSourceType=1&taskId=&from=&groupId=&appId=CRSP_BASIC_PSMC&act=&customReading=














 4444
4444











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









