






#★★★本文源自AlStudio社区精品项目,
【点击此处】查看更多精品内容 >>>
(https://aistudio.baidu.com/aistudio/proiectoverview/public?ad-from=4100)
【PaddleSeg实践范例】PaddleSeg实现人脸部件分割与变妆
一、简介
想知道哪种发色最好看?想知道哪种唇色最适合?还不想真正化妆?那就快来试试我们的AI变妆!

AI变妆的思路是:
- 基于PaddleSeg图像分割套件,使用BiSeNet-v2和PP_LiteSeg模型在CelebAMask-HQ数据集上进行训练,得到人脸部件精细分割的模型;
- 使用模型对新的图片进行预测,精细分割人脸部件,比如嘴唇、头发、鼻子等;
- 根据颜色设置,对人脸部件更换颜色,实现AI变妆。
接下来,我们将从环境准备、数据准备、模型的训练、验证、预测、AI变妆和结果可视化五个方面进行详细介绍。
二、环境准备
PaddlePaddle环境准备
如果在AI Studio上运行此项目,请选择使用GPU版本的环境,默认已经安装了PaddlePaddle。
如果在本地运行此项目,需要自行安装PaddlePaddle。
由于图像分割模型计算开销大,建议在GPU版本的PaddlePaddle下使用PaddleSeg,安装教程请见PaddlePaddle官网。推荐:
- PaddlePaddle = 2.4
- Python = 3.7
PaddleSeg环境准备
安装过程请参考PaddleSeg官方安装文档,下面进行安装:
# 克隆github上的PaddleSeg2.7版本
%cd ~/work
!rm -rf PaddleSeg
!git clone --branch release/2.7 --depth 1 https://github.com/PaddlePaddle/PaddleSeg
# 执行如下命令,从源码编译安装PaddleSeg包。大家对于PaddleSeg/paddleseg目录下的修改,都会立即生效,无需重新安装
%cd PaddleSeg
!pip install -v -e .
# 验证PaddleSeg安装是否成功(可选), 执行如下命令, 会进行简单的单卡预测, 查看执行输出的log, 没有报错, 则验证安装成功
!sh tests/install/check_predict.sh
文件准备
将原本放在~/work下的变妆代码文件、配置文件和已训练好的模型权重移动到~/work/PaddleSeg下。 为了演示方便,上传了已训练好的模型权重。
%cd ~/work
!cp makeup.py ./PaddleSeg
!mkdir ./PaddleSeg/configs/face_parsing
!cp bisenetv2_CelebAMask-HQ_512x512_30k.yml ./PaddleSeg/configs/face_parsing
!cp pp_liteseg_CelebAMask-HQ_512x512_30k.yml ./PaddleSeg/configs/face_parsing
!cp -r bisenetv2_upload ./PaddleSeg/output
!cp -r pp_liteseg_upload ./PaddleSeg/output
三、数据准备
CelebAMask-HQ数据集共有30000张图片。
原始图片尺寸为1024x1024,经过预处理后的图片存放在images,尺寸为512x512。标签图片存放在mask,尺寸为512x512。
标签图片为单通道灰度图,像素值1-18代表人脸的18个部位,像素值0代表背景类,标签图片经过伪彩色处理后如下。

本案例使用预处理后的数据集,下面进行解压。
%cd /home/aistudio/data/data184438/
!unzip CelebAMask-HQ.zip
参考PaddleSeg自定义数据集文档,利用PaddleSeg提供的切分数据并生成文件列表的脚本划分数据集为训练集、验证集、测试集,比例为0.999,0.001,0:
!python /home/aistudio/work/PaddleSeg/tools/data/split_dataset_list.py \
/home/aistudio/data/data184438/CelebAMask-HQ images mask --split 0.999 0.001 0 --format jpg png
得到的数据集如下:
~/data/data184438/CelebAMask-HQ/
- images
- mask
- train.txt
- val.txt
- test.txt
其中images包含本案例使用的图片,mask包含所有的标签图片,train.txt等三个txt文件每行存放原始图片的相对路径与标签图片的相对路径。
四、模型的训练、验证、预测
选择模型
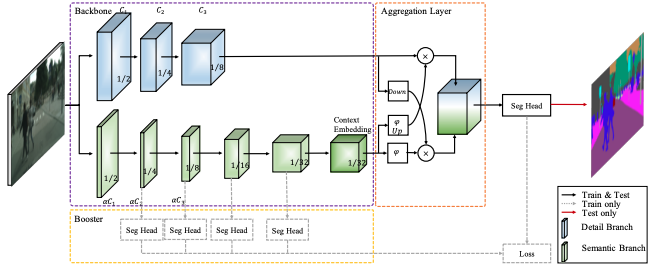
针对人脸部件分割任务,我们选择BiSeNet-v2和PP-LiteSeg。
BiSeNet-v2是一种轻量级的语义分割模型,模型结构如下图:
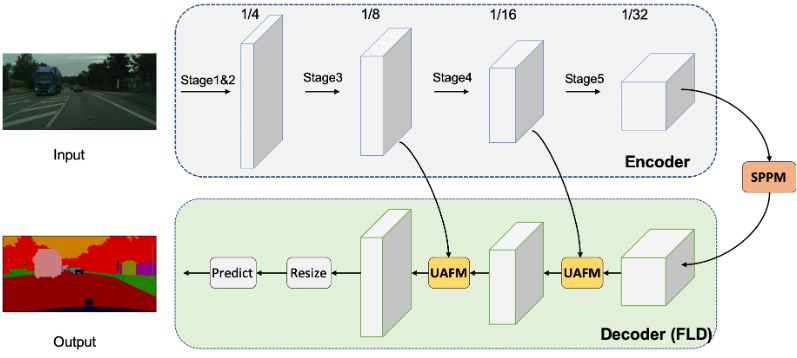
PP_LiteSeg是PaddleSeg团队自研的轻量级语义分割算法,模型结构如下图:
准备配置文件
我们参考PaddleSeg的配置文件文档准备配置文件(如下),并保存在~/work/PaddleSeg/configs/face_parsing/目录下。
batch_size: 32
iters: 80000
train_dataset:
type: Dataset
dataset_root: /home/aistudio/data/data184438/CelebAMask-HQ
train_path: /home/aistudio/data/data184438/CelebAMask-HQ/train.txt
num_classes: 19
mode: train
transforms:
- type: ResizeStepScaling
min_scale_factor: 0.5
max_scale_factor: 1.5
scale_step_size: 0.1
- type: RandomPaddingCrop
crop_size: [512, 512]
- type: RandomDistort
brightness_range: 0.5
contrast_range: 0.5
saturation_range: 0.5
- type: Normalize
mean: [ 0.485, 0.456, 0.406 ]
std: [ 0.229, 0.224, 0.225 ]
val_dataset:
type: Dataset
dataset_root: /home/aistudio/data/data184438/CelebAMask-HQ
val_path: /home/aistudio/data/data184438/CelebAMask-HQ/val.txt
num_classes: 19
mode: val
transforms:
- type: Normalize
mean: [ 0.485, 0.456, 0.406 ]
std: [ 0.229, 0.224, 0.225 ]
model:
type: PPLiteSeg
backbone:
type: STDC1
pretrained: https://bj.bcebos.com/paddleseg/dygraph/PP_STDCNet1.tar.gz
arm_out_chs: [32, 64, 128]
seg_head_inter_chs: [32, 64, 64]
optimizer:
type: sgd
momentum: 0.9
weight_decay: 0.0005
loss:
types:
- type: OhemCrossEntropyLoss
min_kept: 520000 # batch_size * 512 * 512 // 16
- type: OhemCrossEntropyLoss
min_kept: 520000
- type: OhemCrossEntropyLoss
min_kept: 520000
coef: [1, 1, 1]
lr_scheduler:
type: PolynomialDecay
learning_rate: 0.01
end_lr: 0.0
power: 0.9
warmup_iters: 1000
warmup_start_lr: 1.0e-5
模型训练
执行如下命令,在单卡GPU上训练PP-LiteSeg模型。如果想训练BiSeNet-V2模型,只需要替换配置文件即可。详细的训练文档,请参考PaddleSeg的训练文档。
%cd /home/aistudio/work/PaddleSeg
# 单卡GPU训练PP-LiteSeg模型
!python tools/train.py \
--config configs/face_parsing/pp_liteseg_CelebAMask-HQ_512x512_30k.yml \
--save_interval 5000 \
--save_dir output \
--num_workers 4 \
--log_iters 100 \
--do_eval \
--keep_checkpoint_max 15
若为多卡GPU训练,可执行如下多卡训练命令。
注意:多卡训练时需要修改配置文件中的超参,比如使用两张GPU,需要将batch_size调整为单卡的一半。
%cd /home/aistudio/work/PaddleSeg
# 多卡GPU训练PP-LiteSeg模型
!python -m paddle.distributed.launch tools/train.py \
--config configs/face_parsing/pp_liteseg_CelebAMask-HQ_512x512_30k.yml \
--save_interval 5000 \
--save_dir output \
--num_workers 8 \
--log_iters 100 \
--do_eval \
--keep_checkpoint_max 15
训练完成后,模型权重保存在~/work/PaddleSeg/output文件夹下。
模型验证
使用训练好的模型权重,我们可以验证模型的精度。
执行如下命令,使用事先训练好的模型权重进行验证,得到PP-LiteSeg的mIoU为0.7969,BiSeNet-V2的mIoU为0.7750。
%cd /home/aistudio/work/PaddleSeg
!python tools/val.py \
--config configs/face_parsing/pp_liteseg_CelebAMask-HQ_512x512_30k.yml \
--model_path output/pp_liteseg_upload/model.pdparams
!python tools/val.py \
--config configs/face_parsing/bisenetv2_CelebAMask-HQ_512x512_30k.yml \
--model_path output/bisenetv2_upload/model.pdparams
模型预测
参考PaddleSeg预测文档,执行如下命令进行单张图片的预测,这里使用单卡训练好的模型权重进行预测。
大家可以打开~/work/PaddleSeg/output/result/added_prediction/0.jpg查看预测结果。
%cd /home/aistudio/work/PaddleSeg
!python tools/predict.py \
--config configs/face_parsing/pp_liteseg_CelebAMask-HQ_512x512_30k.yml \
--model_path output/pp_liteseg_upload/model.pdparams \
--image_path /home/aistudio/data/data184438/CelebAMask-HQ/images/0.jpg \
--save_dir output/result
五、AI变妆
得到了模型预测的伪彩色图后,即可进行AI变妆。
变妆的代码文件存放在~/work/PaddleSeg/makeup.py,参考项目face-parsing,其原理是根据得到的分割模型预测的人脸部件分割结果,将变换颜色的BGR数值转换为HSV色彩空间进行颜色变换,为了使发色的改变更自然,还应用了滤波处理。
运行makeup.py的命令行参数有5个,下面进行介绍:
- –img_path:进行变妆图片的原图文件路径
- –pseudo_path:分割模型预测的伪彩色图片路径
- –save_dir:变妆结果图片保存的目录
- –parts:进行变妆的人脸部件
- –colors:对应–parts各部件变换的颜色,可选red、green、blue,用户也可在makeup.py中自行添加各种颜色的B,G,R的数值,变换更多的颜色
接着执行下面命令,即可进行发色和唇色的改变:
# 首先安装相关的包
!pip install scikit-image
# AI变妆
%cd /home/aistudio/work/PaddleSeg
!python makeup.py --img_path '/home/aistudio/data/data184438/CelebAMask-HQ/images/0.jpg' \
--pseudo_path '/home/aistudio/work/PaddleSeg/output/result/pseudo_color_prediction/0.png' \
--save_dir '/home/aistudio/work/PaddleSeg/output/result/makeup' \
--parts 'hair' 'upper_lip' 'lower_lip' \
--colors 'red' 'red' 'red'
六、结果可视化
模型预测与变妆的结果图保存在--save_dir指定的文件夹中,BiSeNet-v2与PP_LiteSeg的预测图对比如下所示,可以看出我们的pp_liteseg分割的结果更为精细和准确。

改变发色和嘴唇颜色的变妆结果图如下:

















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









