






学习率是控制 LoRA 在 SDXL 模型中“学习快慢”的关键超参,需分别为 U‑Net(画图部分)和 Text Encoder(语义理解部分)设定不同的值。根据素材集规模,U‑Net 学习率从 3e‑6(10 张)到 2e‑4(> 3000 张)逐步提高,Text Encoder 则从 5e‑7 上升到 3e‑5。训练总步数也应随数据量增长而增加(约 800–> 10000 步),并配合 3%–5% 的 warmup 预热,让学习曲线“先升后衰”更平滑。小数据集需适当降低学习率、增加正则与梯度裁剪,大规模训练则可适当加大学习率并辅以 early‑stopping、dropout 等策略,以兼顾收敛速度与生成质量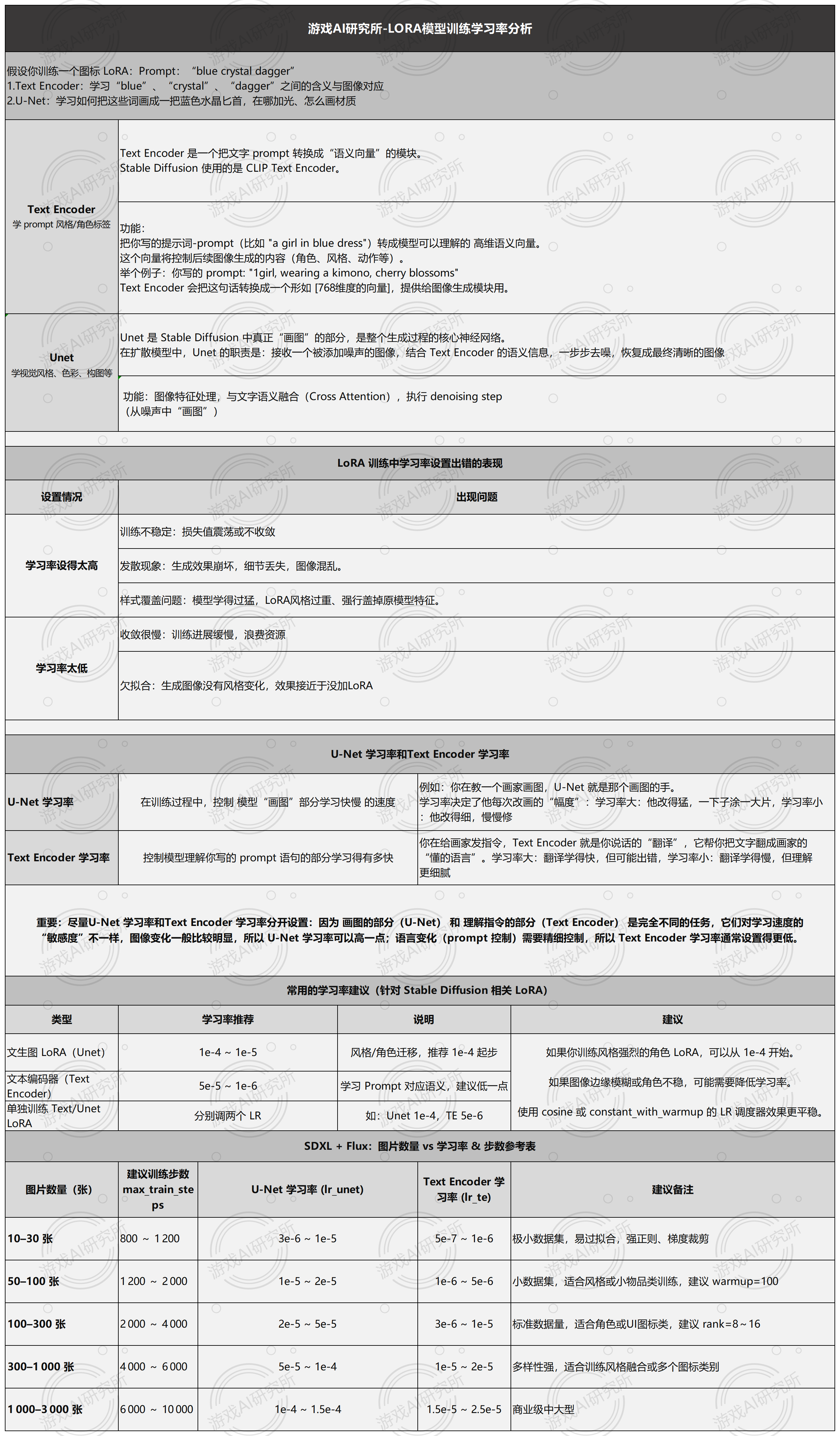

















11-19
 7万+
7万+
7万+
05-04
1443
1443
04-23

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









