






 本文介绍了百度网盘AI大赛中的表格检测项目,参赛者使用PP-YOLOE模型结合数据增强策略,如BatchRandomResize和额外数据集PubTables-1M,进行模型优化。各排名队伍的方案展示了模型微调、后处理阈值调整和数据类型分类的重要性,强调了数据在提升模型性能中的关键作用。
本文介绍了百度网盘AI大赛中的表格检测项目,参赛者使用PP-YOLOE模型结合数据增强策略,如BatchRandomResize和额外数据集PubTables-1M,进行模型优化。各排名队伍的方案展示了模型微调、后处理阈值调整和数据类型分类的重要性,强调了数据在提升模型性能中的关键作用。
★★★ 本文源自AlStudio社区精品项目,【点击此处】查看更多精品内容 >>>
一:项目介绍
本项目用于汇总比赛:百度网盘AI大赛——表格检测进阶:表格的结构化的开源方案,并进行简单解读。
由于笔者水平有限,因此在完成该项目中可能存在一些事实错误,欢迎大家指出
二:比赛介绍
随着票据、名单等带有表单、表格的文件被广泛应用,将纸质文件转化成电子数据并保存管理成为了很多企业的必然工作。
传统人工录入的方式效率低、差错多、流程长,如果能通过技术处理,实现表格图片的结构化展现,则可以很大程度降低成本,提高效率以及使用体验。
本次比赛希望各位选手能通过OCR等技术解决此痛点问题,识别表格图片的内容与坐标,精准还原纸质数据。
比赛主要是将输入的表格进行识别,对每个单元格的内容与位置进行识别,输出结构化表格数据。
数据集:
本次比赛最新发布的数据集共包含训练集、A榜测试集、B榜测试集三个部分。
其中训练集共7742张图片,A榜测试集共500张图片,B榜测试集500张图片;
比赛数据集包含有边界电子表、无边界电子表、拍照电子表和纸质表格四种类型
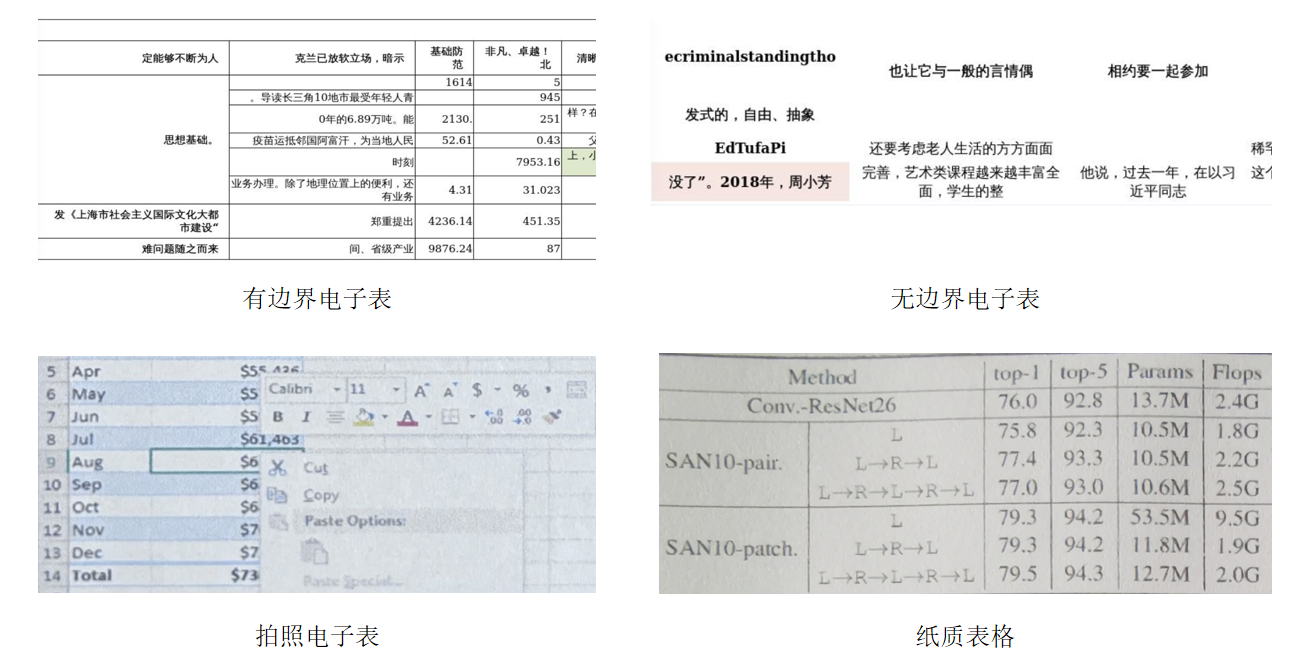
本次比赛共4个类别,分别为整体表格(table)、表格行(row)、表格列(column)、跨多行/列的合并单元格(spanning_cell)。
annos.txt 为标注文件,json格式。
三:方案介绍
Rank 1 :肉馅小饺子
Score :0.87502 Time_used:0.08034
1:模型方案:
最终方案
选择PaddleDetection框架,选用PP-YOLOE+L检测模型
先在PubTables-1M数据集中进行预训练,再在官方数据中进行微调
优化过程
- 作者在训练预训练模型时使用了预训练模型,加速模型收敛。
- 作者修改了动态
Resize的BatchRandomResize取值,使其更符合真实的数据分布。 - 作者训练时使用了
amp混合精度训练,可以加速训练过程,减少显存开销。
2:数据处理及增强:
* 训练验证数据比例:9:1图像增强
- 随机扭曲
- 随机扩展
- 随机裁剪
- 随机翻转
batch增强
- 不保持原图比例的随机
Resize增强 - 修改了动态
Resize的BatchRandomResize取值,使其更符合真实的数据分布。 - 将
NormalizeImage的标准化设为0和1(即删除了标准化),能少量提高模型表现。
3:补充数据集:
- PubTables-1M数据集
来自CVPR2022,PubTable - 1M是一个包含近一百万个来自科学文章的表,支持多种输入形式,并包含表结构的详细标题和位置信息.
论文证明了,仅数据改进就能显著提高表格结构识别(TSP)的表现.
4:优化方向:
暂无5:总结:
作者提供了一种直接的方案,由于参数的设置合理,并且训练数据足够获得了很好的效果。
后续的一系列改进可以从模型的优化着手,并根据现有模型识别结果的缺陷针对进行数据增强。
Rank 2 :一只孤鸭嘎嘎嘎
Score :0.0.87349 Time_used:0.12439
1:模型方案:
最终方案
选择PaddleDetection框架,选用PP-YOLOE+X检测模型
对后处理的对阈值进行手动调整:0.85
优化过程
主要是针对SPP层进行了如下的修改:
- 参考InceptionV3将第一层conv由 5 x 5 --> 5 x 1 + 1 x 5
- 参考SegNeXt使用self.sca
- 输出由 attn * x 更改为 attn
- 设置大卷积Size: 7 // 13 // 19 // 25
同时对比了预测尺寸:
| EvalSize | 800 | 960 | 768 | 832 | 736 | 704 | 672 | 864 | 896 |
|---|---|---|---|---|---|---|---|---|---|
| 精度 % | 93.02 | 93.02 | 93.04 | 93.04 | 93.06 | 93.04 | 93.03 | 93.05 | 93.01 |
作者认为在864尺寸的效果最好
| 方案 | 精度 |
|---|---|
| Baseline | 72.97% |
| 参考InceptionV3将第一层conv由 5 x 5 --> 5 x 1 + 1 x 5 | 72.52% |
| 参考SegNeXt使用self.sca | 72.52% |
| 输出由 attn * x 更改为 attn | 72.87% |
| 设置大卷积Size: 7 // 13 // 19 // 25 | 73.57% |
| conv1_annt | 73.71% |
注:训练5个epoch的策略笔者认为并不具有代表性。
- 作者在训练预训练模型时使用了预训练模型,加速模型收敛。
- 作者将
NormalizeImage的标准化设为0和1(即删除了标准化),能少量提高模型表现。 - 作者修改了动态
Resize的BatchRandomResize取值,使其更符合真实的数据分布。 - 作者训练时使用了
amp混合精度训练,可以加速训练过程,减少显存开销。
2:数据处理及增强:
- 训练验证数据比例:95:5
图像增强
- 随机扭曲
- 随机扩展
- 随机裁剪
- 随机翻转
- 栅格屏蔽(GridMask)
- 随机高斯模糊 (RandomGaussianBlur)
batch增强
- 不保持原图比例的随机
Resize增强
作者使用了巨量的随机比例在训练中进行数据增强
3:补充数据集:
暂无
4:优化方向:
暂无
5:总结:
作者引入了一些新的结构,和丰富的数据增强方法。但对结构的修改有效性不能通过5个epoch决定。
笔者认为,可能是数据增强,尤其是BatchRandomResize提高了模型的表现。
此外,修改结构会导致预训练模型读取失效,因此应该尽量修改模型靠后的结构或者重新训练以得到预训练模型。
后续可以加入额外的数据对模型进行训练,以及对新结构进行完整训练验证。
Rank 3 :青春之痕只为你
Score :0.87022 Time_used:0.08938
作者结论
整个数据集中,难样本集中在真实样本,预测过程中该类样本预测最难。
1:模型方案:
最终方案
选择PaddleDetection框架,选用PP-YOLOE+X检测模型
对后处理的对阈值进行手动调整:0.7
优化过程
-
实例分割模型
-
Mask RCNN
模型精度高但推理时间耗时长,不予选取
-
-
目标检测模型
-
PP-PicoDet
A 榜得分0.7左右,耗时0.04s
-
Cascade_RCNN
使用ViT作为Backbone网络(Cascade_RCNN_ViT-base)
A 榜得分0.86,耗时0.12s
-
PP-YOLOE+X
将CSPRepResNet更换为ConvNeXt(性能反而下降)
修改BatchRandomResize输入尺寸:增加[800,832,864,896,928]
修改eval输入尺寸:[640,640] --> [768,768]
-
-
模型及参数设置
optimizer_400e 的 base_lr 设置为 0.01,base_bacthsize 设置为 64。
| epoch | 80 | 300 | 400 |
|---|---|---|---|
| A榜得分 | 0.877 | 0.888 | 0.893 |
分析:说明模型训练精度未到瓶颈,继续增加训练轮数可获得一定分数提高,但同时按照规律,optimizer的base_Lr也要随之增大。
训练的batchsize为8,lr同比缩小应为0.00125。 但实验得出:batchsize为8,lr为0.01效果较好。
分析:因为使用迁移学习进行训练,学习率变化使用LinearWarmup,因此更大的学习率更易跳出鞍点。
- 模型推理参数
预测文件中thre为0.7,thre从[0.5,0.7],隔0.05取值,实验得出,thre为0.7最好。
分析:因训练过程中简单合成样本占绝大多数,因此网络置信度整体偏高,牺牲部分召回率可极大提高准确度,因此在分数表现上更好。
2:数据处理及增强:
图像增强
- 随机扭曲
- 随机扩展
- 随机裁剪
- 随机翻转
- 高斯模糊
batch增强
- 不保持原图比例的随机
Resize增强 - 作者增加了随机BatchResize的模板数量
- 作者将
NormalizeImage的标准化设为0和1(即删除了标准化),能少量提高模型表现。
3:补充数据集:
暂无
4:优化方向:
-
可以通过生成一些对抗样本来模型优化
-
通过形态学的处理增强表格结构,如锐化,对比度等
-
通过马赛克和遮挡进行数据增强
取得了推理时间较短,分数较高的成绩,同时也说明PP-YOLOE+性能优越,可以作为后续表格结构化检测持续优化的基础模型
5:总结:
作者同样是使用了PP-YOLOE+,增加了数据增强,删除数据标准化和调整后处理阈值,此外,没有使用amp混合精度训练。
作者的消融实验很有参考价值,其改进的思路适用性也很强。
笔者认为,在模型数据差异不大的情况下,优先考虑数据处理可以获得更大的收益。
Rank 4 :鸿飞往里
Score :0.86929 Time_used:0.16326
1:模型方案:
最终方案
-
选择
PaddleDetection框架,选用PP-YOLOE+X检测模型,训练周期为 80 epochs首先,我们采用 LinearWarmup 策略对ppyoloe-plus-x 进行预热,其中,预热周期为 5 epochs。 之后,采用 CosineDecay 策略对学习率进行调整,其中,训练的基础学习率为 0.001, 训练周期为 75 epochs。此外,我们采用动量为 0.9 的 Momentum 优化器对网络进行优化。同时,我们采用 Focal loss 作为分类损失,采用 GIOU 作为回归损失,采用 L1 Loss 计算预测值与真实值之间的误差,采用 DF loss 计算预测分布与真实分布之间的距离,并将上述四个损失的加权和作为模型的总损失。
-
不对数据集进行划分,采用全部数据进行训练
-
对后处理的对阈值使用分阶段的策略进行处理,具体如下:
由赛题分析部分可知,行和列的检测容易受到短边坐标波动的影响,在 iou>0.9 的匹配机制下,行的高度大一点、小一点,列的宽度大一点、小一点都可能匹配不上。
考虑到同一张表格图像中行列的宽高存在一定相关性,因此我们利用其他高置信度行或列的先验知识筛选掉由于短边波动导致匹配失败的行或列。
1)单元格过滤策略。单元格过滤策略基于"合并单元格的“高度大于所在行的高度”或"宽度大于所在列的宽度"的先验信息进行设计,可以很好地解决合并单元格与单个非合并单元格难以区分的问题,首先,我们从检测结果中选取置信度大于 0.7 的行或列,并将行的左上角纵坐标 ymin 和 高度 h 存储在 ymin_l 和 h_l 列表中,将列左上角横坐标 xmin 和 宽度 w 存储在 xmin_l 和 w_l 列表中。之后,假设每个单元格坐标为 (xmin, ymin, xmax, ymax),宽度为 w1 ,高度为 h1。遍历单元格列表,对于每个单元格,将 xmin_l 列表中与 xmin 距离最小的坐标记为 xmin_f, 与之对应行的高度记为 cell_h, 将 ymin_l 列表中与 ymin 距离最小的坐标记为 ymin_f, 与之对应列的宽度记为 cell_w。如果,h> cell_h+5 或 w> cell_w+5 时,我们将检测结果写入到 result.txt 中。对于多个非合并单元格被识别为合并单元格的问题,我们采用适当提高 spanning cell 的阈值解决。
2)表格过滤策略。表格过滤策略基于"一张图片只能有一个表格"的先验信息设计,可以提高表格的召回率。对于每张图片,该策略选取置信度最高的表格检测结果,写入到 result.txt 中。
3)行列过滤策略。行列过滤策略基于“行列之间的宽度和高度具有一定的相关性”的先验信息进行设计,可以有效解决短边波动造成的误检问题。首先,对于置信度大于 0.8 的高质量行列检测结果,我们直接将其写入到 result.txt 中,对于置信度在0.5 到 0.8 区间的行列检测结果,我们将其存储到 low_quality_table 中,同时,我们选取置信度最高的行的宽度,作为 high_quality_row_w, 置信度大于0.7 的行中,高度最小的行,作为 high_quality_row_h ;选取置信度最高的列的高度,作为 high_quality_col_h ,置信度大于 0.7的列中,宽度最小的列,作为 high_quality_col_w。之后,遍历 low_quality_table 列表,将宽度位于 [0.9* high_quality_row_w,1.1* high_quality_row_w],高度位于 [0.9* high_quality_row_h,1.1* high_quality_row_h] 的行写入到 result.txt 中, 将宽度位于 [0.9* high_quality_col_w ,1.1* high_quality_col_w ],高度位于 [0.9* high_quality_col_h,1.1* high_quality_col_h] 的列写入到 result.txt 中。
优化过程
- 模型及后处理策略
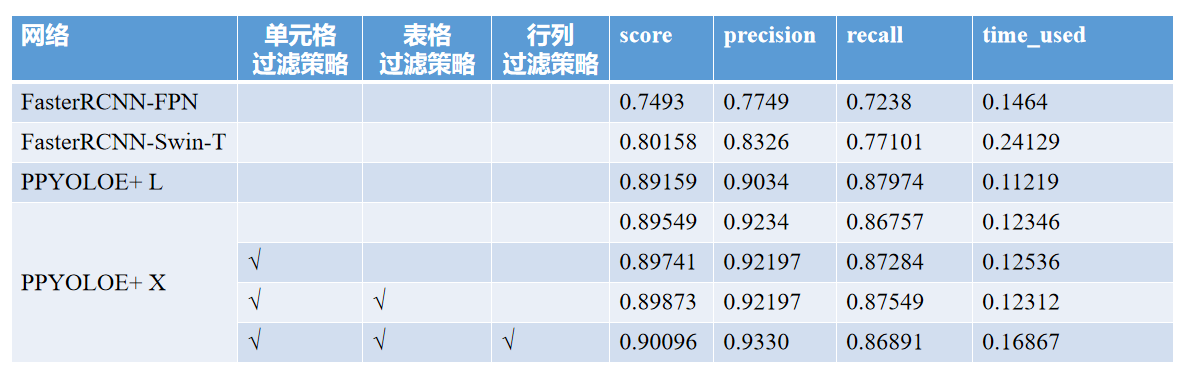
2:数据处理及增强:
图像增强
- 随机像素变换,包括对亮度、对比度、饱和度、色相角度、通道顺序的调整
- 随机扩展
- 随机裁剪
- 随机翻转
batch增强
- 不保持原图比例的随机
Resize增强 - 作者增加了随机BatchResize的模板数量
- 作者将
NormalizeImage的标准化设为0和1(即删除了标准化),能少量提高模型表现。
3:补充数据集:
暂无4:优化方向:
暂无5:总结:
作者的项目描述十分详细,消融实验也很完善,可以明显看到后处理的加入对模型精度是非常有效的。
主要还是学习作者如何将表格的先验信息转为可以上分的具体处理方法。
后续可以继续增加额外的训练数据,并且考虑训练更多的Epoch。
作者提到,拍照电子表会出现严重的遮挡问题,造成较多的漏检和误检。
笔者认为:可以考虑再训练一个简单的分类模型,对不同的数据类型进行分类后再训练单独的结构识别模型。
Rank 5 :树先生
Score :0.86499 Time_used:0.15057
1:模型方案:
最终方案
-
选择
PaddleDetection框架,选用PP-YOLOE+X检测模型 -
对后处理的对阈值进行手动调整:0.75
-
识别的图像尺寸设置为 1024 * 1024
优化过程
-
训练时不识别整体表格,只识别行、列以及合并单元格,最后由所有行、列的xmin、xmax、ymin、ymax确定整个表格的bbox
-
对原始图片进行了上下左右翻转的数据增强
-
加入后处理,对于相隔较远(超过最小行高或列框)的行或列,在它们中间插入一行或一列,但这个办法效果不好,不一定能够提分,因此没有采用。
2:数据处理及增强:
-
训练前对图像进行增强,图片翻转(水平、垂直、水平加垂直)。4倍原始数据量
笔者:这种数据增强的方式容易导致严重的模型过拟合
图像增强(默认)
- 随机扭曲
- 随机扩展
- 随机裁剪
- 随机翻转
batch增强
- 不保持原图比例的随机
BatchRandomResize增强
3:补充数据集:
暂无4:优化方向:
暂无5:总结:
作者使用了更大的图像大小,并且训练时只识别行、列以及合并单元格,也调整了阈值并意识到可以通过采取后处理进行进一步提升。
整体采用的思路和策略也很适用。但笔者对 原始图片进行了上下左右翻转的数据增强 存在怀疑,强行过拟合模型容易在换榜后产生波动。
还是应该从补充外部数据集入手,而且作者修改了原始配置的学习率和训练epoch,其中学习率不建议随意改动,要求与batchsize成正比。
作者不识别表格等策略没有进行消融实验。可能是否适用其他任务,还需要进一步实验。
Rank 6 :绿仔牛奶
Score :0.85987 Time_used:0.15808
1:模型方案:
最终方案
-
选择
PaddleDetection框架,选用PP-YOLOE+X检测模型 -
模型使用自定义的Neck模块:
CustomCSPPAN -
识别的图像尺寸设置为 960*960
-
修改了BatchRandomResize的取值模板
-
作者训练时使用了
amp混合精度训练,可以加速训练过程,减少显存开销。
优化过程
| 方法 | 精度 | 备注 |
|---|---|---|
| PP-YOLOE+X | 0.7672 | CustomCSPPAN |
| - | 0.7971 | + Epoch=100 |
| - | 0.8332 | + EvalSize=[960, 960] |
| - | 0.8712 | + 增加BatchRandomResize模板 |
| - | 0.8860 | + 将图片放大,减少长宽比,进一步提高BatchRandomResize尺寸至1152 |
| - | 0.8884 | + 设置预测阈值为 0.55 |
2:数据处理及增强:
图像增强
- 随机扩展
- Resize:[3000, 2000]
- 随机扭曲
- 随机裁剪
- 随机翻转
batch增强
- 不保持原图比例的随机
BatchRandomResize增强 - 将
NormalizeImage的标准化设为0和1(即删除了标准化),能少量提高模型表现。
3:补充数据集:
暂无4:优化方向:
暂无5:总结:
作者使用了自定义的CSPPAN模块,但是没有做消融实验,可能这种改变反而会影响精度。
同样作者进行了BatchRandomResize扩增等方案,并且也进行消融实验,
可以看到作者的阈值明显低于前几名的方案,模型的结构和训练的epoch可以继续调整。
Rank 7 :
Score :0.85833 Time_used:0.08016
1:模型方案:
最终方案
优化过程
2:数据处理及增强:
3:补充数据集:
4:优化方向:
5:总结:
Rank 8 :wgdgmidu
Score :0.85693 Time_used:0.0833
1:模型方案:
最终方案
-
选择
PaddleDetection框架,选用PP-YOLOE+X检测模型 -
对后处理的对阈值进行手动调整:0.8
优化过程
-
根据目标的统计修改
MultiClassNMS参数:nms_top_k: 200,keep_top_k: 80
2:数据处理及增强:
图像增强
- 随机扩展
- 随机扭曲
- 随机裁剪
- 随机翻转
- MixUp增强
batch增强
- 不保持原图比例的随机
BatchRandomResize增强 - 将
NormalizeImage的标准化设为0和1(即删除了标准化),能少量提高模型表现。
3:补充数据集:
暂无4:优化方向:
暂无5:总结:
作者增加了MixUp增强,nms的参数理论上会减少后处理的耗时,但对精度影响不大。
该方案比较常规,后续可以继续从数据增强上补充。
Rank 9 :BBH~
Score :0.8518 Time_used:0.11293
1:模型方案:
最终方案
- 选择
PaddleDetection框架,选用PP-YOLOE+X检测模型
优化过程
-
有效策略:
- 对有遮挡框和图表格的类型进行数据扩充。
- 增大随机缩放大小到832。
- 采用SIOU替换GIOU作为回归损失函数。
-
无效策略:
- Mosaic,Mixup,Cutmix等数据增强。
- 添加轻量级注意力机制,如CBAM,SE等。
2:数据处理及增强:
> 图像增强- 随机扩展
- 随机扭曲
- 随机裁剪
- 随机翻转
batch增强
- 不保持原图比例的随机
BatchRandomResize增强
3:补充数据集:
暂无4:优化方向:
- 预测后处理模块-自动纠正坐标。
- 引入坐标注意力机制。
5:总结:
作者增加了遮挡数据集的比例,考虑了新的损失函数,提高模型的表现。
笔者认为,对于数据扩充要谨慎,额外的数据可能会破坏原始数据的分布。
Rank 10:是阿恒呀
Score :0.85083 Time_used:0.07116
1:模型方案:
最终方案
-
选择
PaddleDetection框架,选用PP-YOLOE+L检测模型 -
首先采用了官方数据集进行第一次在学习率为0.01, 60epoch训练获得了有一定识别能力的二次预训练模型, 在此基础上将学习率调整为0.001, 对官方数据集+生成数据集进行120epoch进行训练
-
预训练模型: ppyoloe-plus-x 在 Object365 数据集上的预训练模型
优化过程
- 使用TableGeneration生成 2.5k的模糊, 倾斜的数据 用来提高模型的准确率和泛化性
2:数据处理及增强:
图像增强
- 随机扩展
- 随机像素内容变换,包括对亮度、对比度、饱和度、色相角度、通道顺序的调整
- 随机裁剪
- 随机翻转
batch增强
- 不保持原图比例的随机
BatchRandomResize增强 - 将
NormalizeImage的标准化设为0和1(即删除了标准化),能少量提高模型表现。
3:补充数据集:
作者新增加了2.5k的合成数据
4:优化方向:
暂无5:总结:
作者使用的是L规模的模型,但是调用的是X规模的预训练,这会导致预训练的模型加载无效。
作者的训练顺序也值得商榷,一般是在合成数据中进行训练,再在自己的数据中进行微调。
作者通过可视化不同场景数据的结果得出需要进行数据扩增的结论。
笔者认为增加一个场景分类模型用于对数据进行分类可能有较好的上分效果。
而且作者没有试图调整后处理的阈值,这可能是对结果影响较大的一个因素。
四:讨论与总结
对于表格类任务的几个关键点
-
几乎的模型都是
PP-YOLOE+X检测模型,对数据都增加了BatchRandomResize增强的模板。 -
针对数据不同类型调整后处理的置信度阈值非常有必要。
-
删除了标准化,能少量提高模型表现。
-
在推理过程中增加图像的尺寸也能直接提高模型表现。
-
大量的额外数据可以用于预训练数据,但应该谨慎参与最终模型的微调。
-
对于模型的结构修改应该保持谨慎,需要大量的训练资源进行验证。
数据!数据!数据!
对于此次比赛,笔者认为,始终如一的上分点,就是数据,无论是数据增强,还是使用额外数据进行预训练,甚至是后处理和数据增强。
对数据进行分析,并针对性设计策略是获得Top方案最直接的方式。
模型的改进相对来说门槛较高,获得的收益也不稳定。因此在面对新任务中,首先进行数据的分析是非常有效的策略。
可以看到在不限制额外数据集的情况下,使用额外开源数据集是提升模型性能的重要手段。
对于数据尺寸变化较大的数据,大量的丰富Resize增强的模板是很有效的方案。
在这次竞赛中,有几只队伍意识到训练集中存在不同的数据类型,并增加了合成数据。
笔者认为,对于该类问题,更好的方式是训练一个分类模型,针对不同的数据训练表格结构化模型,并进行调用,这也是 百度网盘赛:图像超分辨 Rank 1 使用的方案,其耗时没有增加多少,但是精度提升很大,该细分数据的思想在百度网盘赛的其他Top方案中也有用到。
因此学习大量的优秀方案,从中汲取到优秀的思想用到自己的任务中,这也是不断提高自己技术能力一个好方法。
后续计划
-
如果有关注,笔者会尝试收集更多的比赛方案合集,并将其中通用的有效上分策略进行总结。
-
对于热度高,有实际应用价值的项目,笔者也想将优秀的方案进行融合,训练并开源模型。
资料收集整理繁琐,如果能帮助到您,笔者不胜荣幸
此文章为搬运
原项目链接

















 6538
6538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









