







鲲鹏devkit性能分析工具介绍(二)
上一篇笔记录性能分析工具的全景分析模式的基本原理和重点参数的解读,在这片文章里将会讲解其他的分析功能特点和重点参数
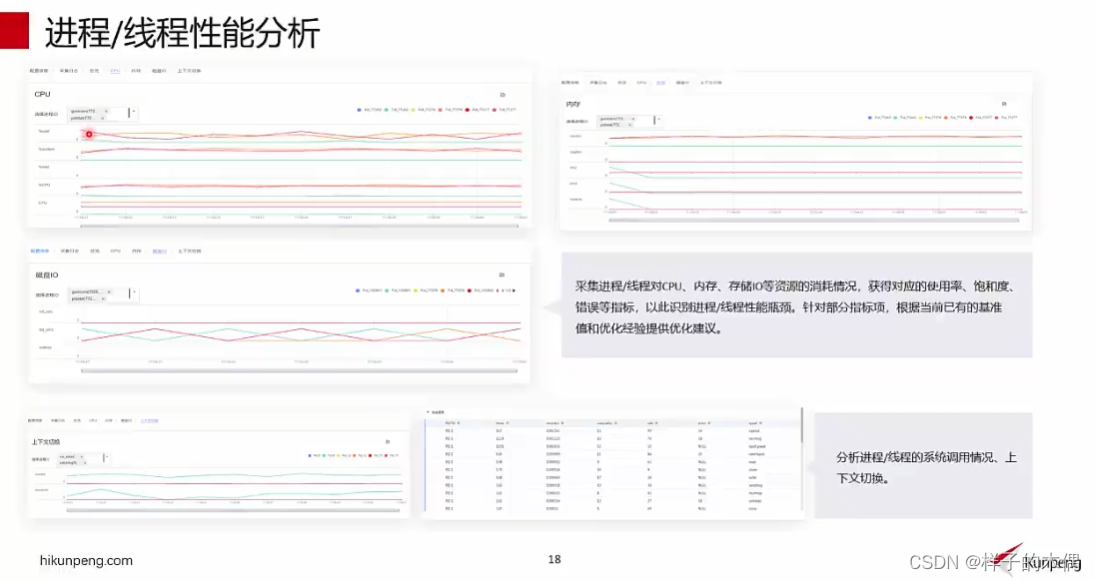
进程/线程性能分析
进程/线程性能分析借鉴业界的USE方法,采集进程/线程对CPU、GPU、内存、存储IO等资源的消耗情况,获得对应的使用率、饱和度、错误次数等指标,以此识别性能瓶颈。针对部分指标项,根据当前已有的基准值和优化经验提供优化建议。支持分析单个进程的系统调用情况。
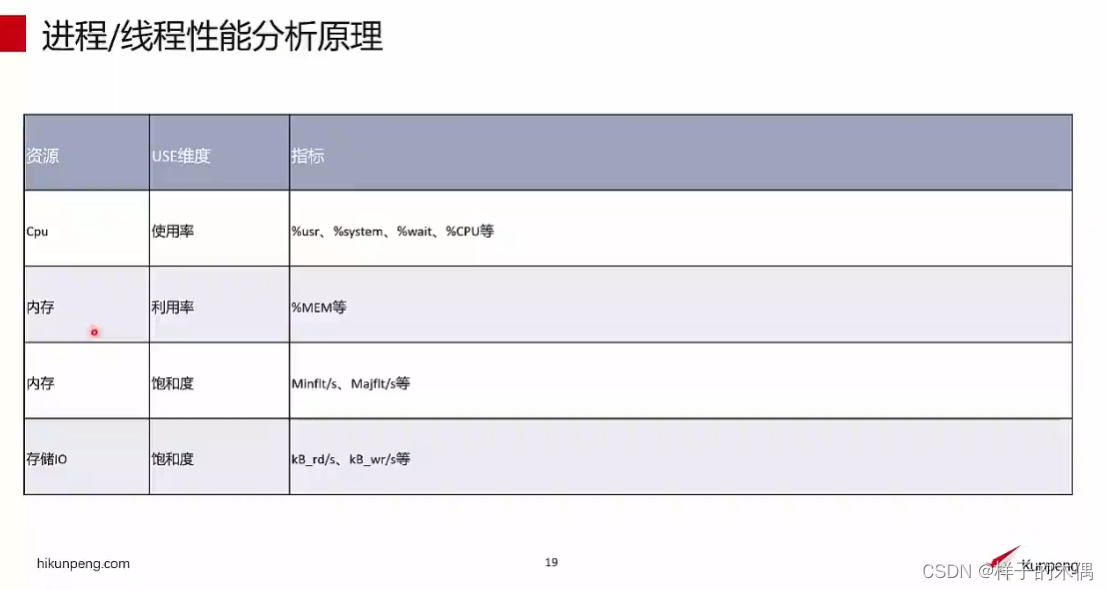
进程/线程性能分析原理
通过采集应用的资源信息从使用率、利用率、饱和度等多个维度进行分析
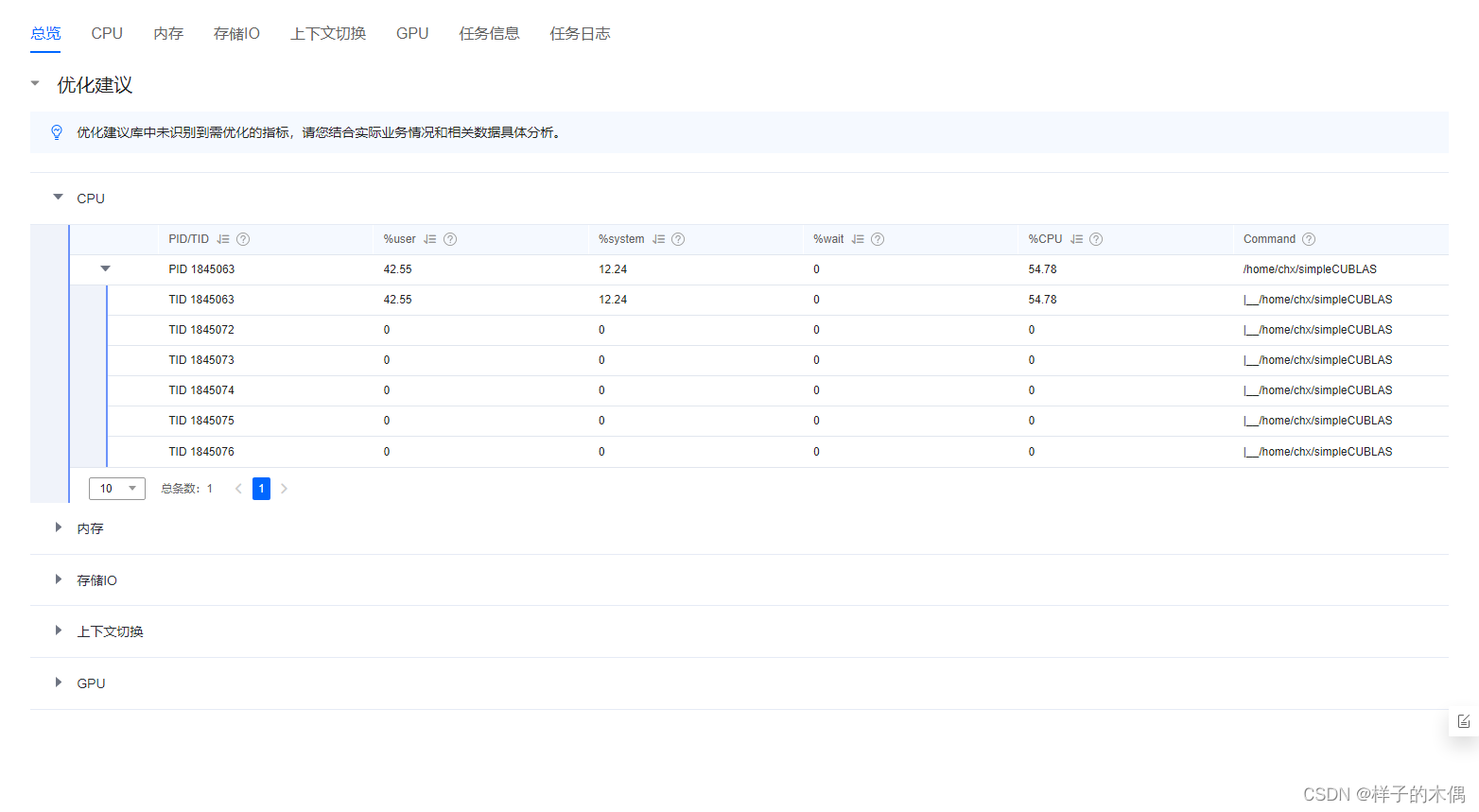
在分析报告中可以看到进程在用户空间的CPU占比,通常来说过同一个进程在两个核上进行CPU占比不平均这里就充分说明了应用还留有调优的空间,我们正是利用性能分析工具这些数据去进行分析判断最后来选择性能调优的手段
重点指标分析解读
上下文切换区域参数说明:
PID/TID
显示进程ID/线程ID。
cswch/s
每秒主动任务上下文切换次数,通常指任务无法获取所需资源,导致的上下文切换。例如I/O、内存等系统资源不足时,就会发生主动任务上下文切换。
nvcswch/s
每秒被动任务上下文切换次数,通常任务由于时间片已到、被高优先级进程抢占等原因,被系统强制调度,进而发生的上下文切换。例如大量进程都在争抢CPU时,就容易发生被动任务上下文切换。
Command
当前进程对应的命令名称。
系统调用区参数说明:
%time
系统CPU时间花在哪里的百分比。
seconds/s
总的系统CPU时间(以秒为单位)。
usecs/call(ms)
每次调用的平均系统CPU时间(以毫秒为单位)。
calls
整个采集过程中的系统调用次数。
errors
整个采集过程中的系统调用失败次数。
syscall
系统调用的名字。

性能影响:
1、在切换次数较多的情况下,很容易导致CPU将大量时间耗费在寄存器、内核栈以及虚拟内存等资源的保存和恢复上,进而大大缩短了正运行进程的时间。
2、切换后虚拟内存更新,TLB也需刷网新。内在的访问会随之变慢。多处理器系统上,缓存是被多个处理器共享的,所以还会影响共享缓存的其他处理器的进程。减少不必要的系统调用、中断,可以有效的降低进程上下文切换。提高进程性能。
热点函数分析
支持分析C/C++程序代码识别性能瓶颈,给出对应的热点函数以及源码和汇编指令的关联详情。通过冷/热火焰图展示函数的调用关系,发现优化路径。
麒麟V10(Tercel)暂不支持Launch Application模式的应用采集;UOS暂不支持分析模式选择“应用”。
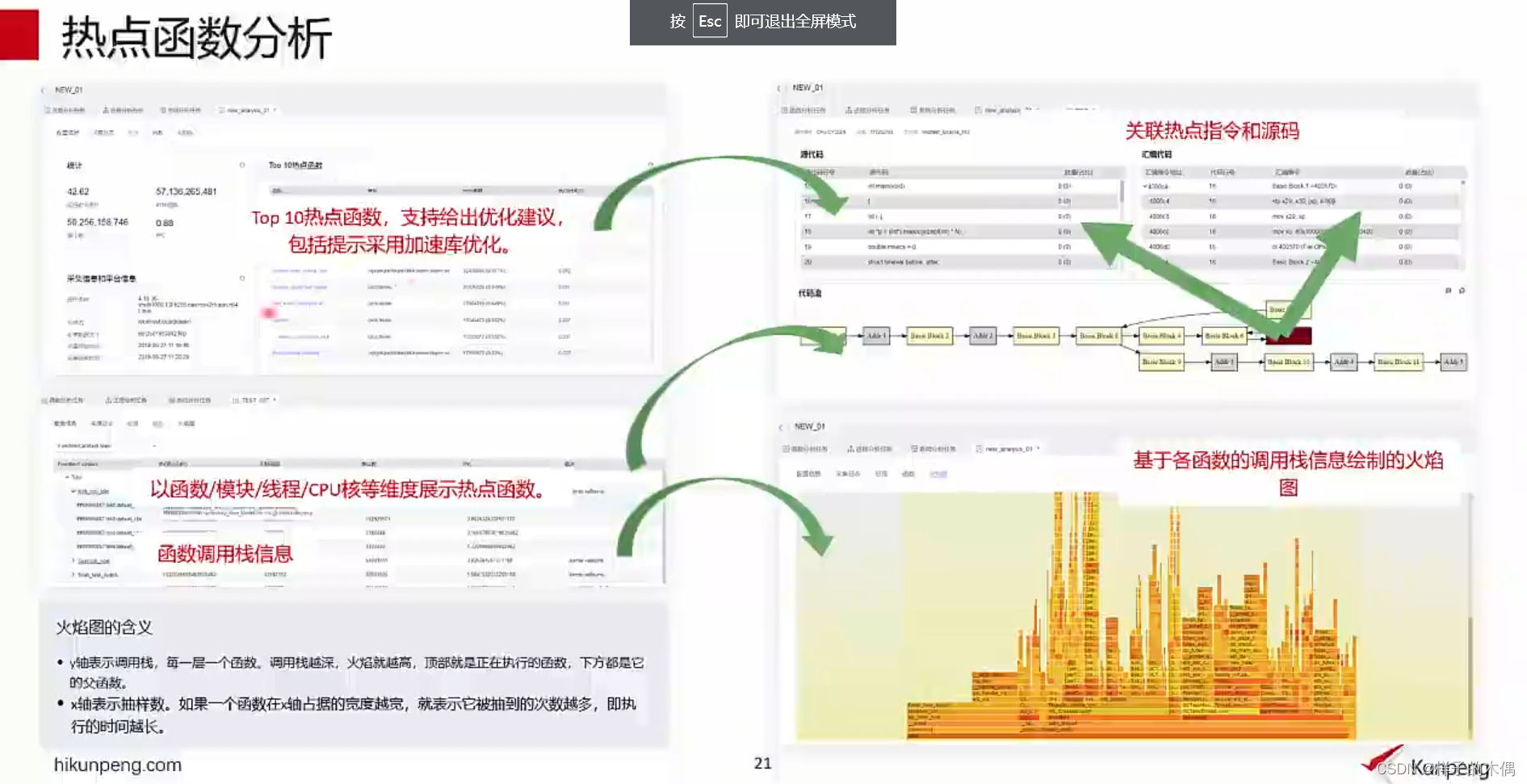
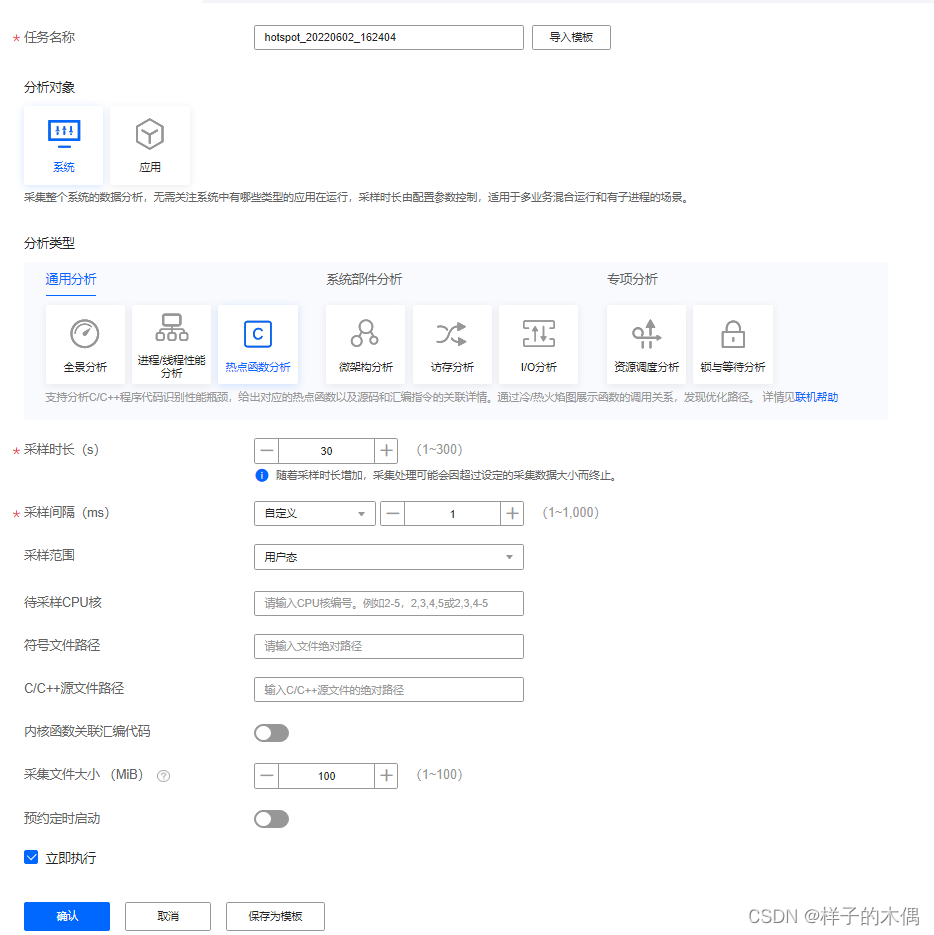
对于c/c++应用进行热点函数分析可以对其源码进行分析,通过应用执行过程分析出过程中那些函数为频繁调用的热点函数,这些热点函数往往就算我们进行性能调优的关键函数
热点函数分析举例
在视频教程中举例分析了一个矩阵计算函数为热带你函数,在点函数TOP10的排行榜中点击热点函数可以直接查看热点函数的代码块,方便进行修改
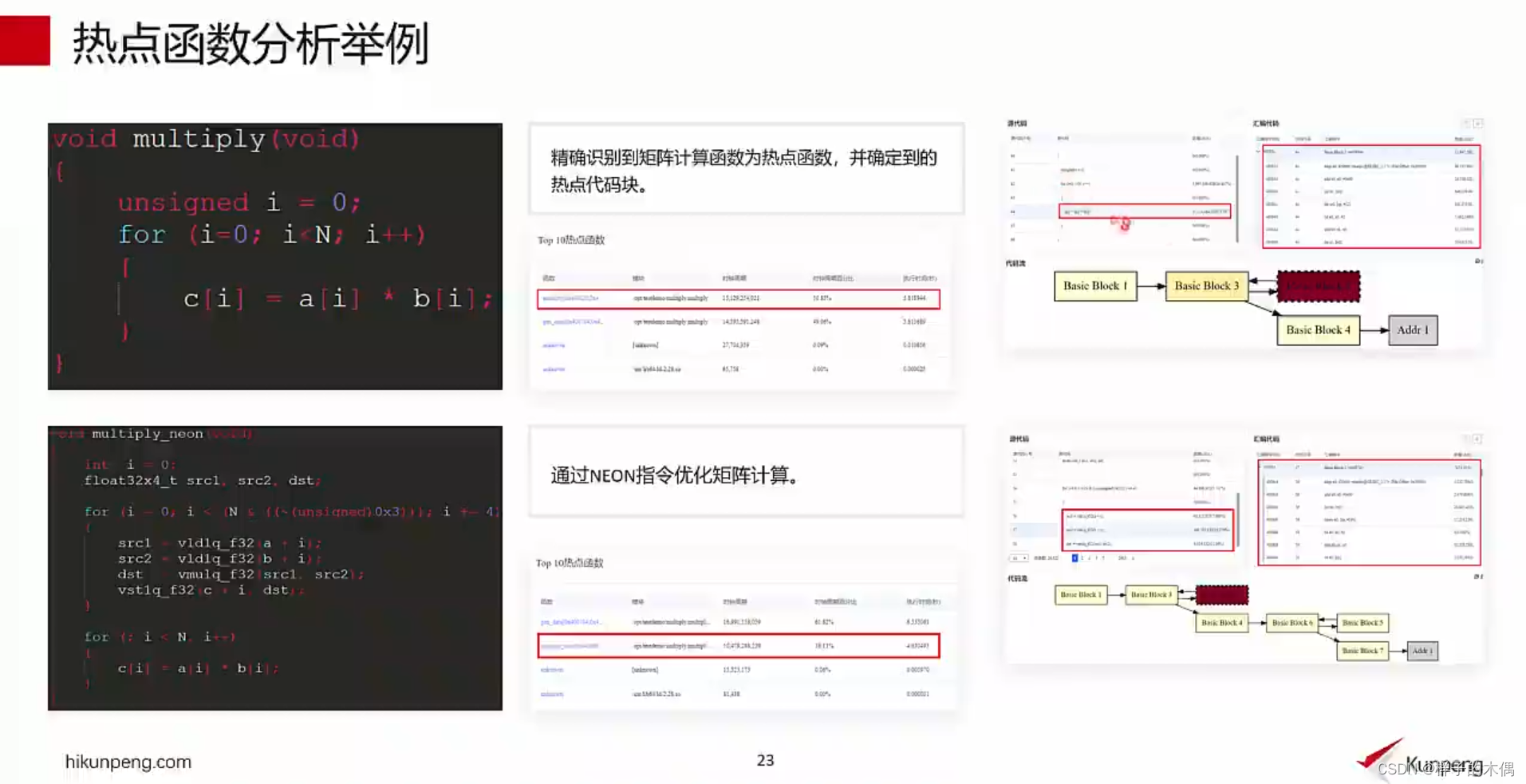
经过修改的热点函数目的是为了大大降低其频繁的调用次数,可以有效提高整体的性能
这里只能是c/c++应用才可以进行分析
微架构分析
什么是微架构?
微架构又称为微体系结构/微处理器体系结构。是在计算机工程中,将一种给定的 指令集架构在处理器中执行的方法。一种给定指令集可以在不同的微架构中执行。实施中可能因应不同的设计目的和技术提升而有所不同。计算机架构是微架构和指令集设计的结合。
微架构分析作用
微架构分析基于ARM PMU(Performance Monitor Unit)事件,获得指令在CPU流水线上的运行情况,帮助用户快速定位当前应用在CPU上的性能瓶颈。用户可以有针对性地修改自己的程序,以充分利用当前的硬件资源。当前微架构任务只支持物理机场景,创建工程时选择物理机节点。
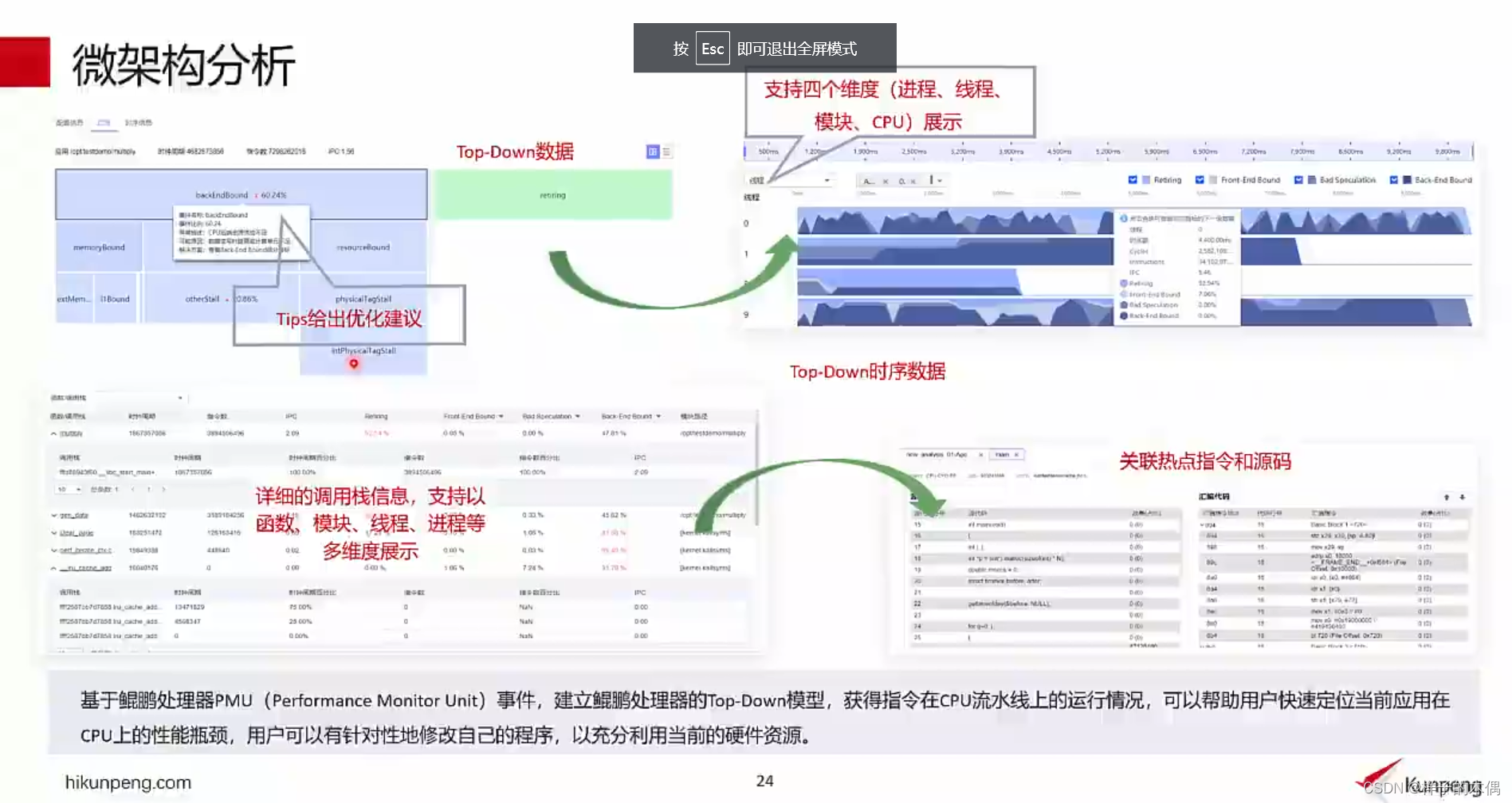
微架构分析支持四个维度(进程、线程、模块、CPU)展示,同时还会给出优化建议,通过对调用信息,等多维度的分析帮助开发者选择调优方向
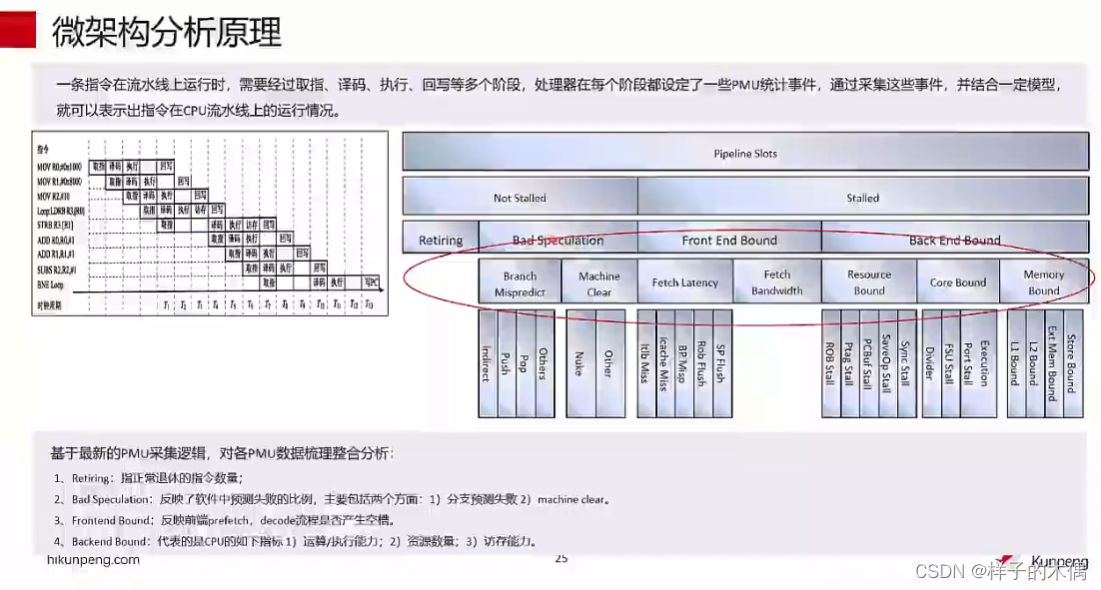
微架构分析原理
一条指令在流水线上运行时,需要经过取指、译码、执行、回写等多个阶段,处理器在每个阶段都设定了一些PMU统计事件,通过采集这些事件,并结合一定模型,就可以表示出指令在CPU流水线上的运行情况。
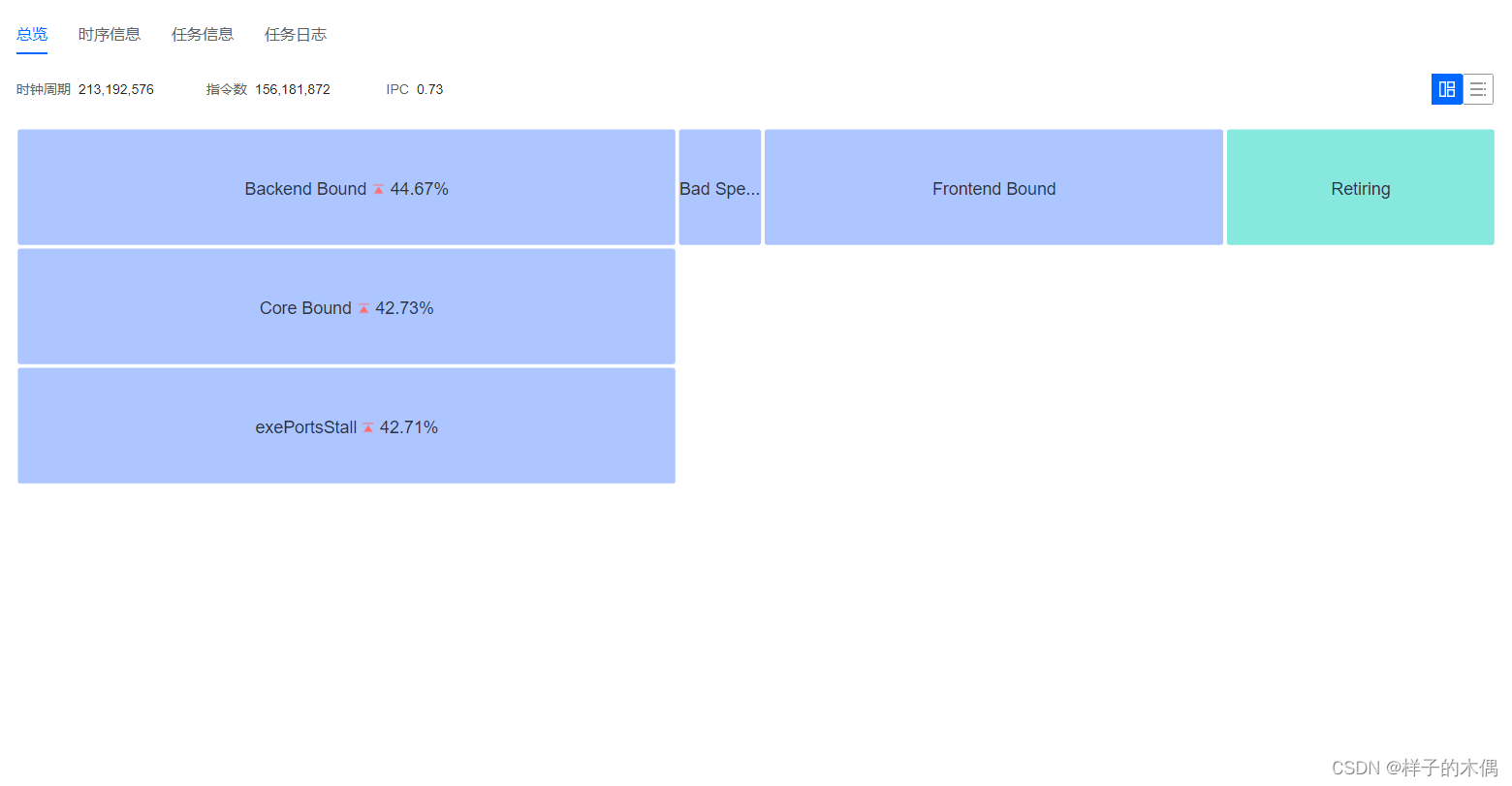
微架构分析举例
在视频教程中给出了一个数组排序的例子,我们可以通过这个例子进行分析一下
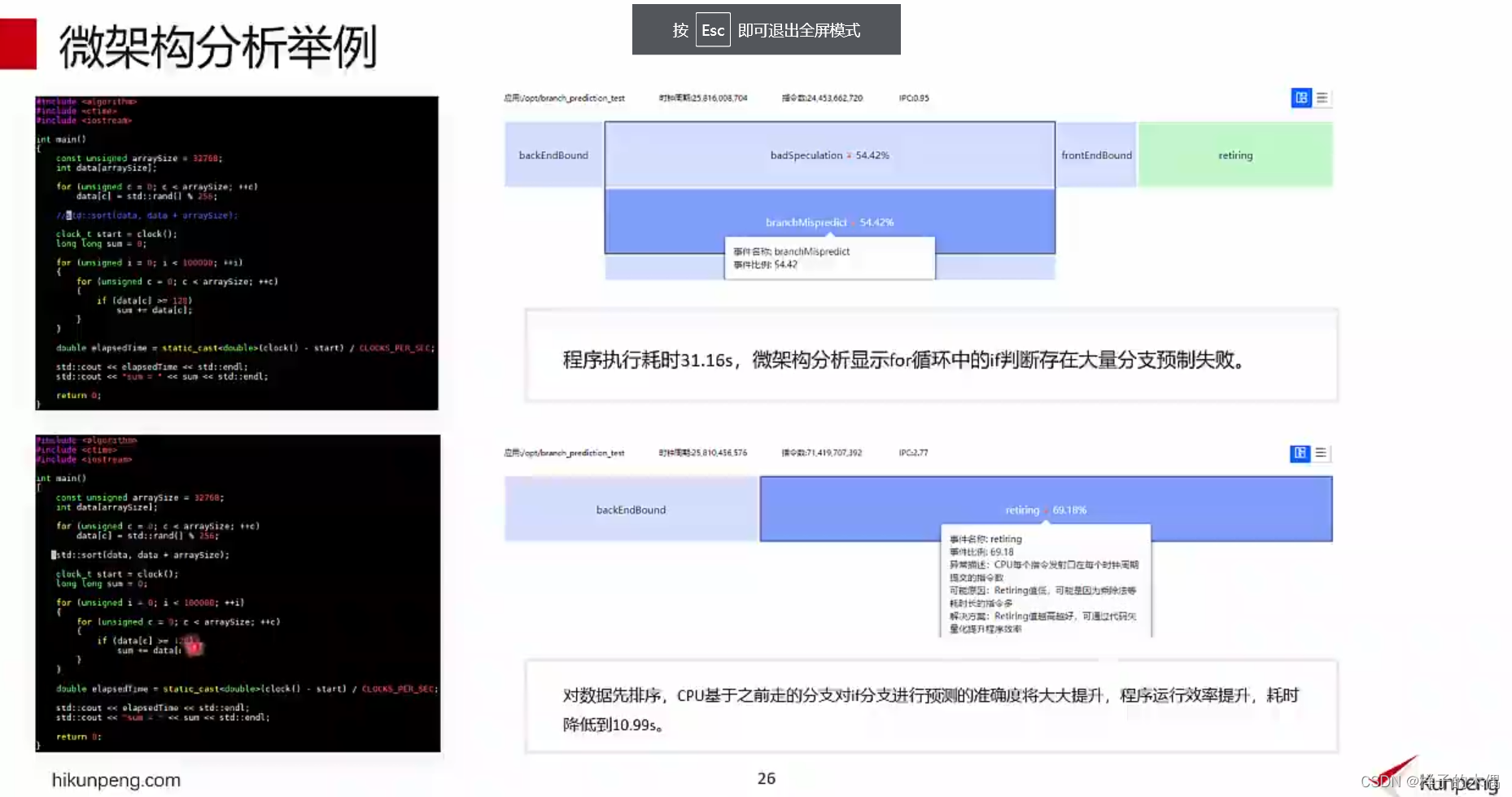
使用上面的程序累计执行耗时31.16s,在进行微架构分析时显示出了for循环中的if判断存在着大量的分支预制失败
而下面的程序采取的是根据架构分析选择的是对数据进行先排序,CPU基于之前走的分支对if分支进行预测的准确度将大大提升
这里也可以看到程序的运行效率提高,耗时也是降到了原来的三分之一只用了10.99s
















 33
33











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











