







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
目录
(1)querystring.parse(str, [sep], [eq], [options])
(2)querystring.stringify(obj, [sep], [eq])
(1)mime.getExtension()可以通过路径返回资源类型
(2) mime.getType()可以通过路径返回资源类型
1.路径(_dirname,_filname)
_dirname,_filnam都是全局变量
(1) __dirname
是一个字符串,代表当前js文件所在目录的路径(绝对路径)
__dirname:返回当前模块文件解析过后所在的文件夹(目录)的绝对路径
使用__dirname变量获得当前文件所在目录的完整目录名__dirname等同于path.dirname(__filename)
(2)__filename
是一个字符串,代表当前js文件的路径(绝对路径)
__filename:返回当前模块文件被解析过后的绝对路径,
使用__filename变量获取当前模块文件的带有完整绝对路径的文件名
2.url网址
网址的组成: 协议://ip:port/pathname?querystring#hash
域名 ==>DNS解析 会把域名解析为一个ip port
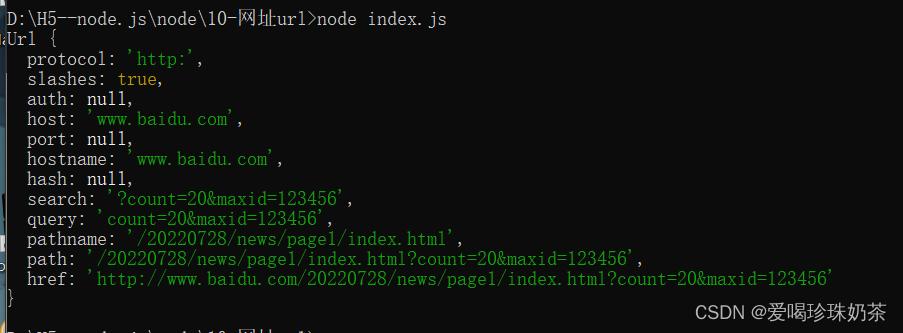
程序例如:
var url=require("url") var str="http://www.baidu.com/20220728/news/page1/index.html?count=20&maxid=123456" var obj=url.parse(str) console.log(obj);运行结果:
3.querystring模块
(1) querystring从字面上的意思就是查询字符串,一般是对http请求所带的数据进行解析。querystring模块只提供4个方法。
(2)querystring参数解析为一个对象
(3)querystring模块用于实现URL参数字符串与参数对象的互相转换
(1)querystring.parse(str, [sep], [eq], [options])
parse这个方法是将一个字符串反序列化为一个对象。
querystring.parse(str, [sep], [eq], [options])------将一个 query string 反序列化为一个对象。可以选择是否覆盖默认的分割符('&')和分配符('=')。
案例:
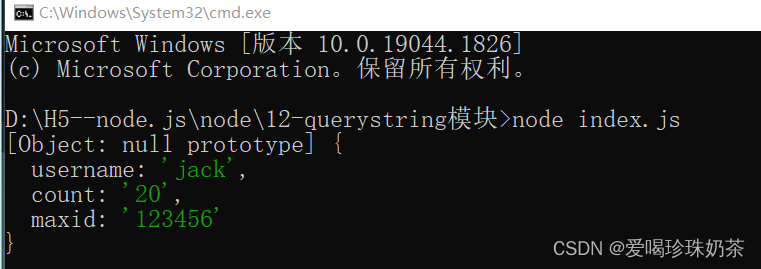
var querystring=require("querystring") var obj=querystring.parse("username=jack&count=20&maxid=123456") console.log(obj)运行结果:
(2)querystring.stringify(obj, [sep], [eq])
------序列化一个对象到一个 query string。
可以选择是否覆盖默认的分割符('&')和分配符('=')。
举例:
var querystring=require("querystring") var str2=querystring.stringify({name:"jack",age:20}) var str3=JSON.stringify({name:"jack",age:20}) console.log(str2); console.log(str3);运行结果:

4.mime模块
mime是一个互联网标准,通过设定它就可以设定文件在浏览器的打开方式
(1)mime.getExtension()可以通过路径返回资源类型
举例:
var mime=require("mime") var re=mime.getExtension("text/css") console.log(re)运行结果:
(2) mime.getType()可以通过路径返回资源类型
举例:
var mime=require("mime") var re2=mime.getType("htpp://2342354345:8080/css/sadfsdgfdfg.ttf") console.log(re2)运行结果:


5.各种路径(相对路径)
(1)本地相对路径
以"./"或者"/"开头
例如:在页面中写路径: file://x1/x2/x2/index.html
(2)本地绝对路径
从根盘符开始写路径
例如:"C:/Windows/ASUS/Shortcuts"
(3)相对网络路径
以"./"或者"/"开头
例如:
当前页面的网址: "协议://ip:port /src/news/index.html querystring hash"
页面内部的路径:
"./src/18.jpg" ==> "协议://ip:port /src/news/src/18.jpg"
(4)绝对网络路径
"以http://"或者根盘符开头写路径
格式:"协议://ip:port /src/news/src/18.jpg"
(5)本地相对根路径
"/"开头
例如:用户本地打开: "file:///c:/xx/xx2/index.html"
页面中有一个img的src是 : "/src/18.jpg"
它真正的路径:"file:///c:/src/18.jpg"
(6)网络相对根路径
"/"开头
例如:
用户输入网址: http://192.168.60.160:8080/user/20220728/newspage
打开了一个页面,在这个页面中有一个img的src是 : "/src/18.jpg"
请问192.168.60.160:8080这个服务器会受到req.url是什么?
答:"/src/18.jpg"
它真正的网址:"http://192.168.60.160:8080/src/18.jpg"
6.网页的加载(面试题*)
1.浏览器是怎么加载网页的?
==>
(1.1)浏览器的地址栏,输入网址,敲回车,会请求一次服务器,服务器会返回一个数据包,就是网页代码(html格式的文本文档)。
(1.2)浏览器开始去运行解析html文本(此时还没有外部图片,js,css,字体库资源)
(1.2.1)解析时,遇到了img标签的src属性,会异步的,开始再次网络请求服务器,服务器返回数据包(图片编码)然后渲染出来
(1.2.2)解析时,遇到了link-href会异步的,开始再次网络请求服务器,服务器返回数据包(css编码),然后加载。
(1.2.3)解析时,xxxx-url会异步的,开始再次网络请求服务器,服务器返回数据包(对应编码)然后加载。
(1.2.4)解析时,script-src会异步的,开始再次网络请求服务器,服务器返回数据包(js编码),然后用js引擎去执行编码。
(1.3 )所有资源加载完毕了,才会触发window.onload















 262
262











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









