






前言
随着机器学习领域的发展,我们的模型越来越复杂,庞大的参数量和数据量让计算量激增。为了减少训练时长,并行梯度下降进入了人们的视野。这篇文章就从技术原理的角度介绍几种实现并行梯度下降的编程模型,里面的一些图片来自王树森老师的课程。需要注意的是,文中提到的都是数据的并行,没有设计模型参数的并行。
MapReduce实现并行梯度下降
MapReduce是谷歌推出的编程模型,虽然现在已经慢慢淡出历史舞台了,但不妨碍我们去学习它的原理。
MapReduce的架构是经典的Client-Server架构,将一个节点设为Server,负责协调其他节点和整合信息,其余的节点都作为Worker Node进行计算,如图所示:
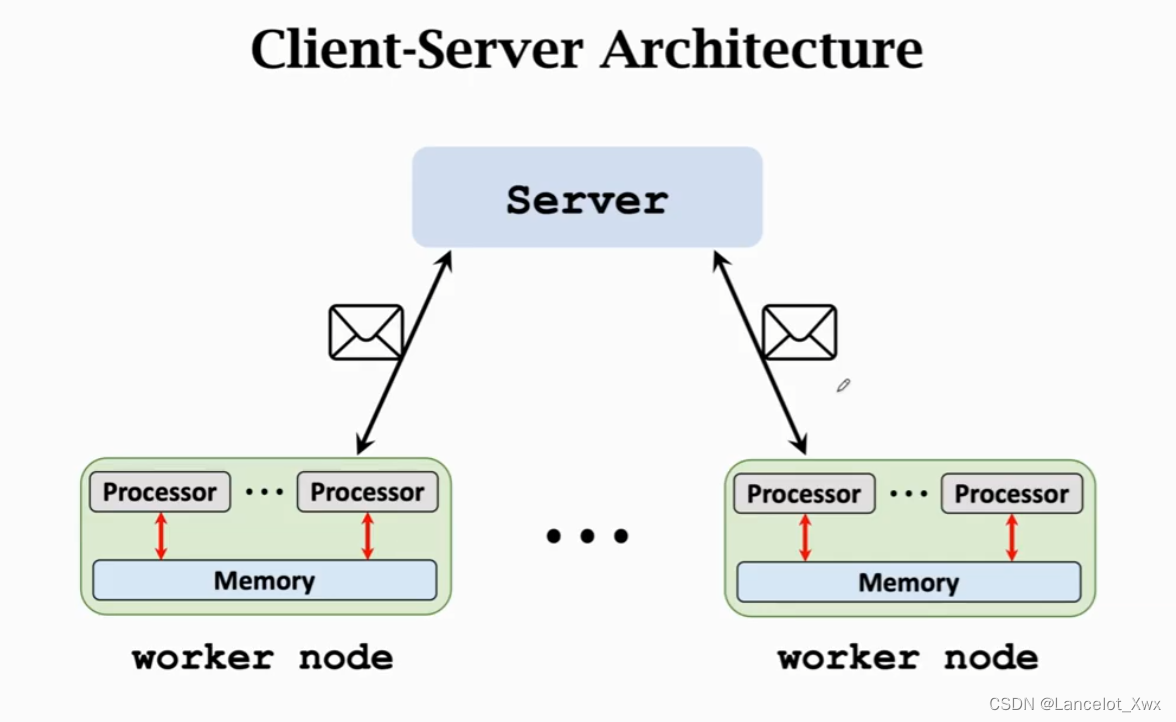
很明显,MapReduce的通信方式是Message Passing。知道了这个架构的原理后,我们来看MapReduce的结构图:
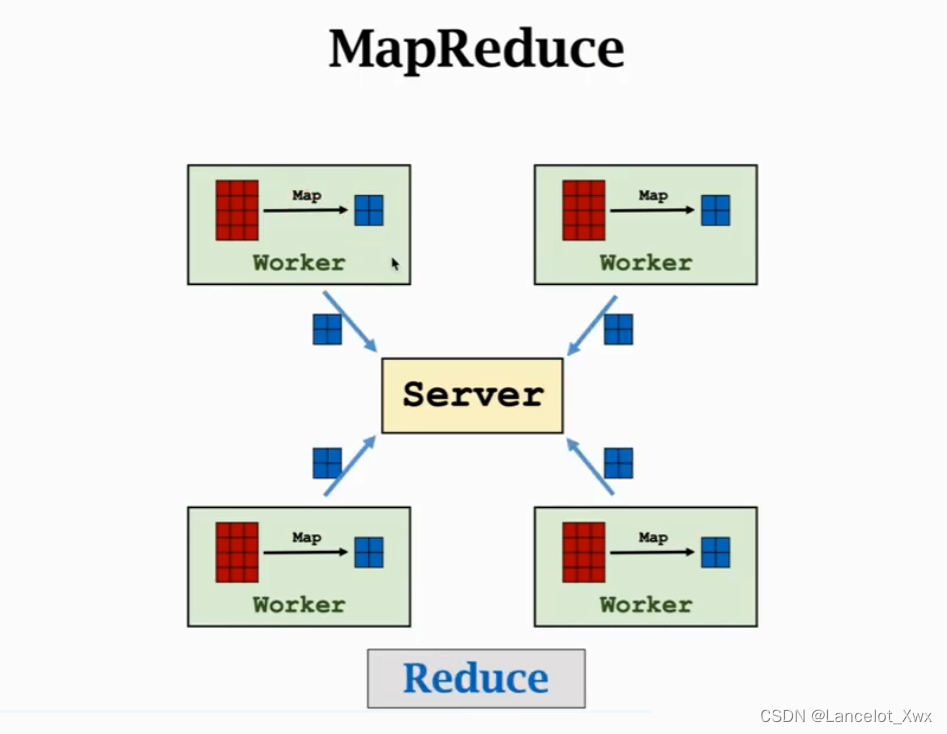
顾名思义,MapReduce的关键就是Map和Reduce,Map指的是每个Worker执行的函数,也就是梯度的计算,图中的小蓝色矩阵就是每个Worker计算出的结果。然后它们被Server接收,进行Reduce操作。Reduce使用的函数有很多种,例如Sum(求和)、Mean(算均值)和 Collect(收集各矩阵)。在实际操作时,假如我们有N个样本需要计算,然后有M个Worker Node,那么每个Worker Node 分到的样本就是
N
M
\frac{N}{M}
MN个。
除了Map和Reduce,还有一个非常重要的步骤就是Broadcast,指的是每次计算前Server都要把当前更新好的权重传播给每个Worker节点。
下图展示了使用最小二乘法作为损失函数进行梯度下降的MapReduce工作过程:
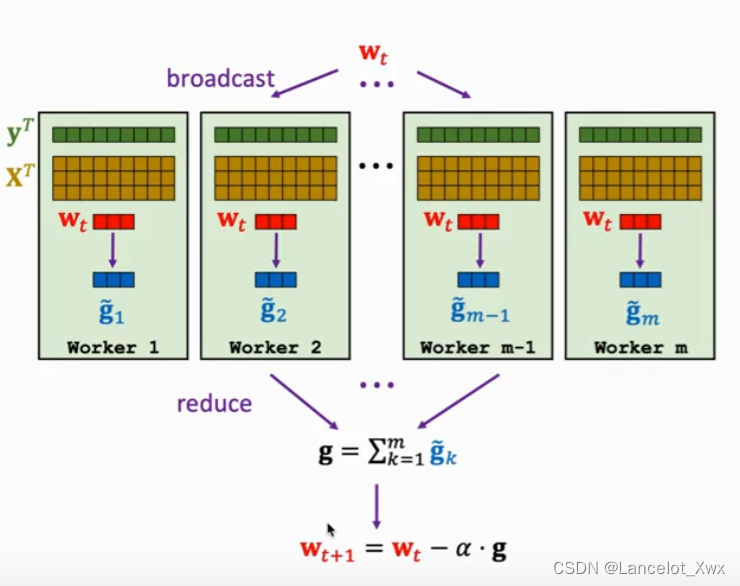
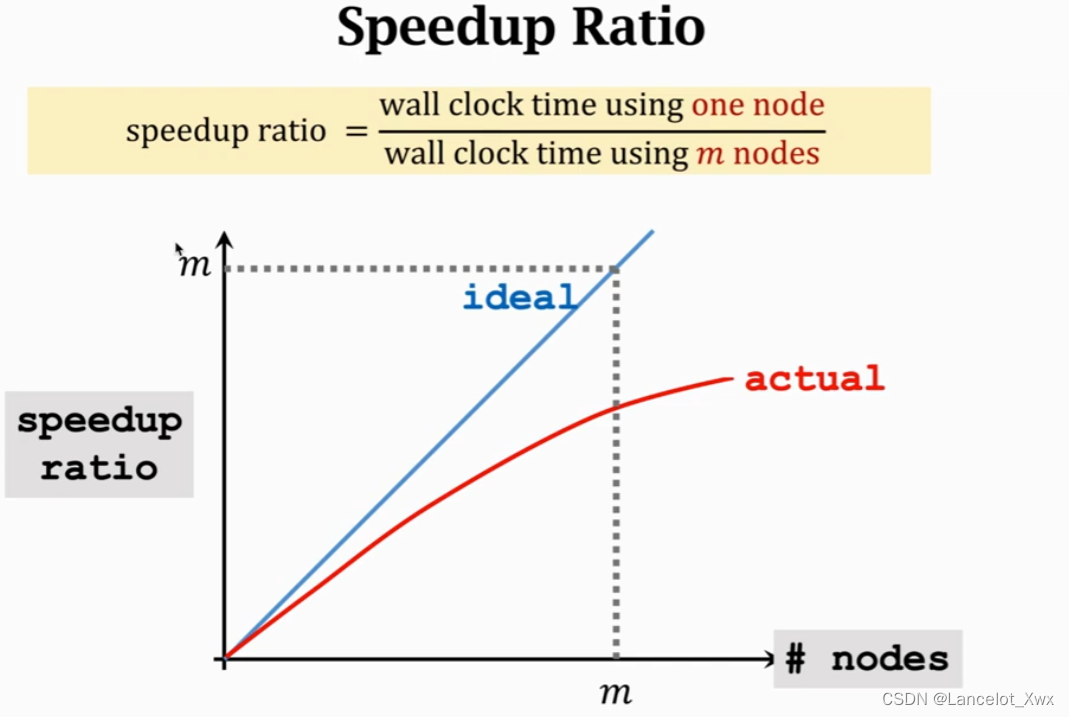
这里有个概念叫Speedup Ratio,代表我们的加速效率,理想状态下我们不考虑通讯时间和同步时间,那么就是一条直线,实际上是一条随着工作节点增多提升效果越来越小的曲线。
 那实际中我们是这么估算通讯时间的呢?通常是使用一个简单的公式,虽然它不够完善也不够准确,但能大致表示通讯所需的时间:
那实际中我们是这么估算通讯时间的呢?通常是使用一个简单的公式,虽然它不够完善也不够准确,但能大致表示通讯所需的时间:
C o m m u n i c a t i o n t i m e = c o m m u n i c a t i o n c o m p l e x i t y b a n d w i d t h + l a t e n c y Communication\ time = \frac{communication\ complexity}{bandwidth} + latency Communication time=bandwidthcommunication complexity+latency
Communication complexity: 在Server和Worker之间有多少个字(word)需要传输。
bandwidth:网络带宽
latency:网络延迟,点到点数据包的传输时延,由计算机网络系统决定
还有一个概念就是同步所需的时间,也就是Synchronization Cost。对于每一次计算,都要等所有Worder都计算完了才能进入下一步,如果这些Worder Node的计算速度有快有慢,那么快的就要等慢的结束了才能继续进行。也就是说,如果某次计算时有某个Worker节点出了问题,那么其他Worker都得在计算完自己的任务后等他复工。
The Parameter Server实现梯度下降
在上面我们提过,MapReduce模型的bulk synchronous特性使得它在每次计算时必须等全部的Worker Node计算完才能进入下一步,而现在要介绍的Parameter Server模型则解决了这个问题。
和MapReduce模型一样,Parameter Server模型的架构也是Client-Server架构,通信方式是Message Passing,不过不同的是Parameter Server是不同步的(asynchronous),这大大提高了工作效率。
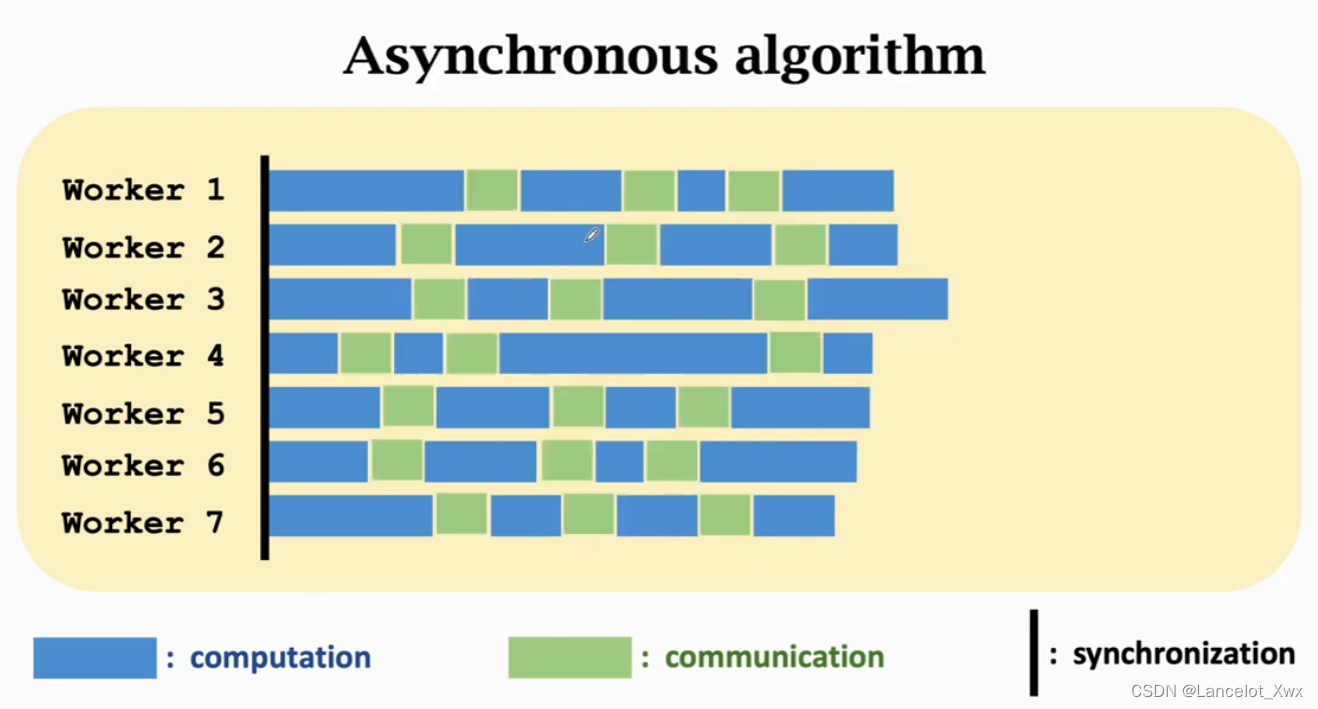 在Parameter Server模型中,每个Worker只用做好自己的事情,不需要管其他同事的进度,计算完就直接和Server进行通信,然后拿到当前更新的权重继续进行计算。同样,如果有N个样本、M个Worker Node,那么每个Worker分到的样本数就是
N
M
\frac{N}{M}
MN。具体工作流程见下图:
在Parameter Server模型中,每个Worker只用做好自己的事情,不需要管其他同事的进度,计算完就直接和Server进行通信,然后拿到当前更新的权重继续进行计算。同样,如果有N个样本、M个Worker Node,那么每个Worker分到的样本数就是
N
M
\frac{N}{M}
MN。具体工作流程见下图:
 异步算法具有效率高的优点,但是缺点也很明显,其一就是需要更大的迭代次数才能收敛,其二也是它的一个限制:所有Worker Node的计算速度应该相近,不能有某个或某些Worker的计算速度落后其他Worker很多,不然就会出现大问题。
异步算法具有效率高的优点,但是缺点也很明显,其一就是需要更大的迭代次数才能收敛,其二也是它的一个限制:所有Worker Node的计算速度应该相近,不能有某个或某些Worker的计算速度落后其他Worker很多,不然就会出现大问题。
这个大问题是什么呢?让我们假设有两个计算速度较快的Worker和一个计算速度较慢的Worker,如下图所示:
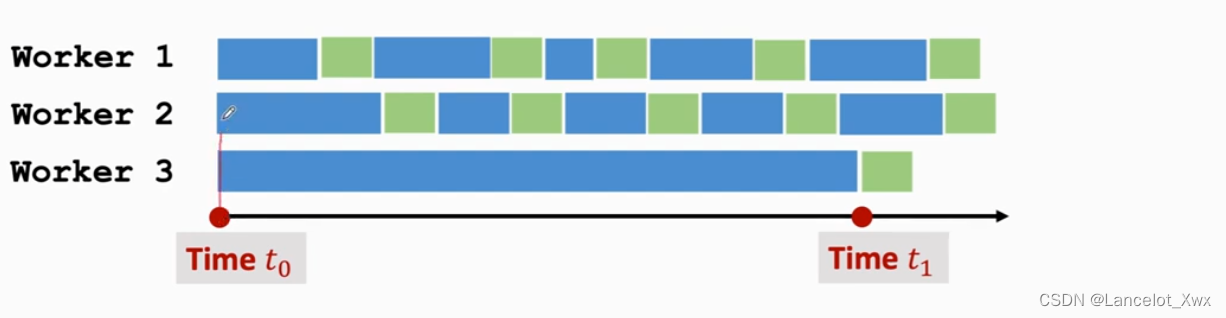
我们来看
t
1
t_1
t1时刻,这个时候Worker 3 才计算出它这批样本对应的第一个梯度,也就是基于
t
0
t_0
t0时刻拿到的权重计算出的结果,然后它会把这个结果给到Server,但是Server手上的权重已经是基于Worker 1 和 Worker 2计算出的梯度更新了好几轮的结果了。这就好比是某个军事基地已经从冷兵器慢慢发展到了核武器,然后下属的一个研究部门把做宝剑的工艺要用在造导弹上,可以说起不到什么作用甚至有害。
Decentralized Network
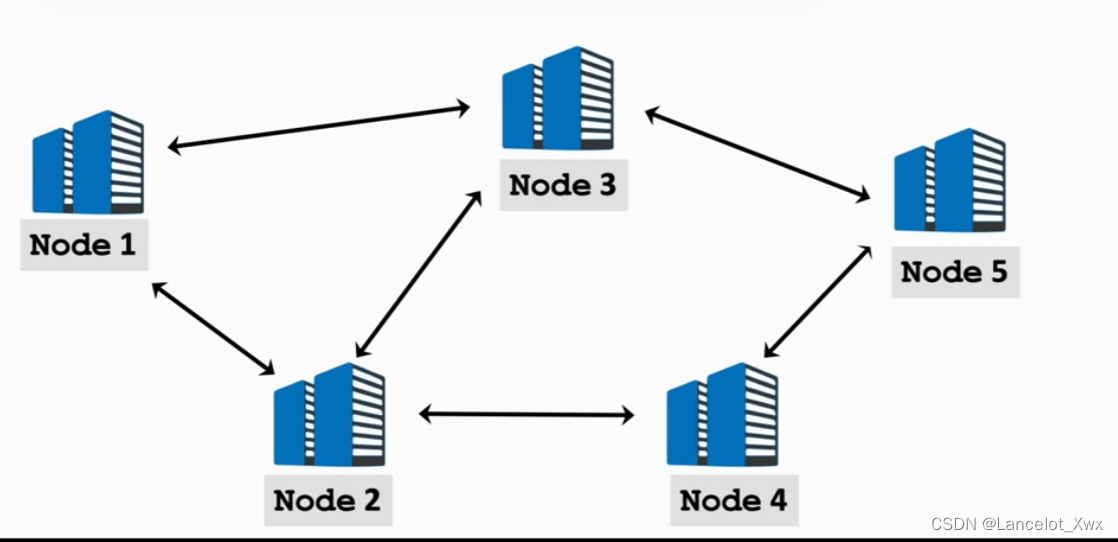
虽然通信方式还是Message Passsing,但是Decentralized Network采用的架构和前两种编程模型完全不同——peer-to-peer架构(没有Server)。里面的每个节点只能和自己的邻居通信,具有去中心化的特点,结构如下图:
同样,样本被均等分配到每个节点上,不过计算过程与前面两种有较大的区别,如图:
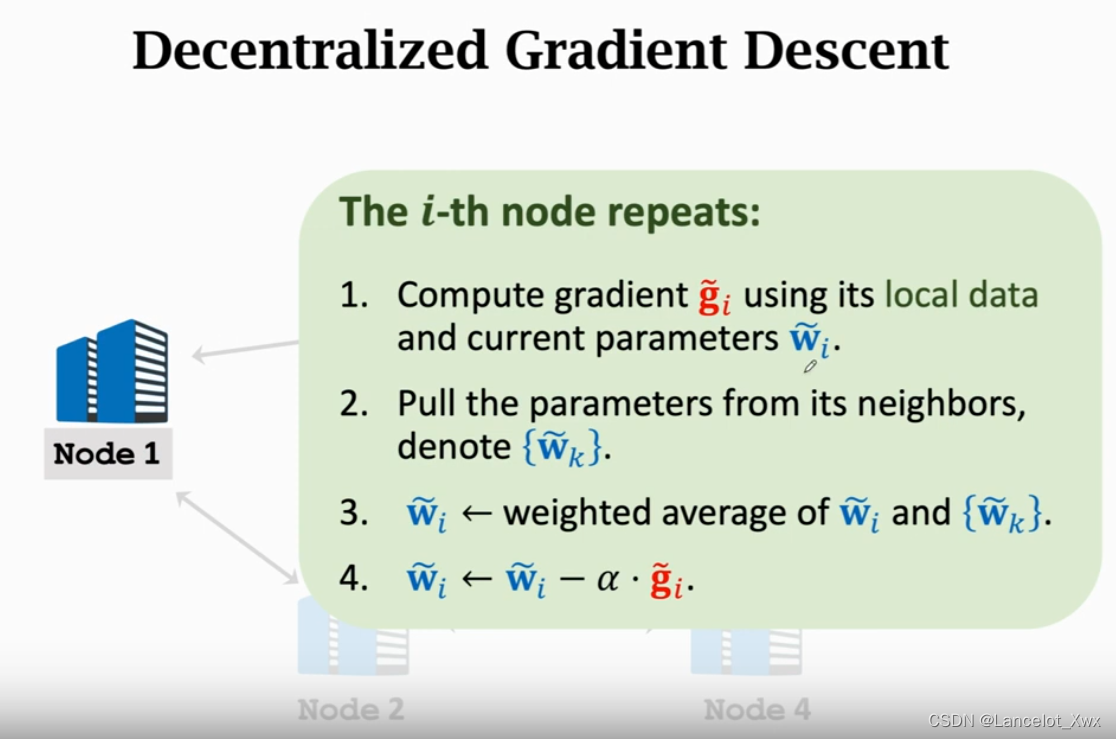
这里,每个节点都有自己当前的权重,但是各节点权重都不太一样,训练多轮后才可能收敛到一块儿。节点用自己本地的数据和自己当前的权重计算出梯度,然后获取邻接节点的权重,把权重作一个加权平均,用这个平均权重作为自己的权重来进行更新。
可以发现,对于Decentralized Network,它的收敛速率和模型构成的图的连接状况有关,连接越紧密收敛越快,如果这个图不是强连接的,那么根本不会收敛。
参考的课程链接:
[1] 王树森老师的相关课程
[2] Recht, Benjamin, et al. “Hogwild!: A lock-free approach to parallelizing stochastic gradient descent.” Advances in neural information processing systems 24 (2011).
[3] Li, Mu, et al. “Scaling distributed machine learning with the parameter server.” 11th USENIX Symposium on operating systems design and implementation (OSDI 14). 2014.















 4351
4351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









