







1、梯度下降法(Gradient Descent Algorithm)
梯度下降法,类似于贪心算法,只考虑当下,一般找到的是局部最优解。在深度学习中,大量使用梯度下降法,因为神经网络中损失函数并没有特别多的局部最优点,所以找到的一般都是全局最优解。
损失函数-如下图所示:

下面是根据所有样本的平方根误差来更新梯度。推导公式w的计算。

程序实现梯度下降法:
#梯度下降法
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0 #设置初始w值
#预测,得到的是y预测值
def forward(x):
return x * w
#损失函数,平方来表示,,,,cost为误差
def cost(xs, ys):
cost = 0
for x_val, y_val in zip(xs, ys):
y_pred = forward(x_val)
cost += (y_pred - y_val) ** 2
return cost / len(xs)
#定义梯度函数gradient function
def gradient(xs, ys):
grad = 0
for x_val, y_val in zip(xs, ys):
grad += 2 * x_val * (x_val * w - y_val)
return grad / len(xs)
epoch_list = []
cost_list = []
print('predict (before training)', 4, forward(4))
for epoch in range(100):
cost_val = cost(x_data,y_data)
grad_val = gradient(x_data,y_data)
w -= 0.01 * grad_val # 0.01 learning rate
#这种输出方法很好,不用%占位符
print('epoch:', epoch, 'w=', w, 'loss=', cost_val)
epoch_list.append(epoch)
cost_list.append(cost_val)
print('predict (after training)', '需要线性预测的值是:',4, '预测值结果为:',forward(4))
plt.plot(epoch_list,cost_list)
plt.ylabel('cost')
plt.xlabel('epoch')
plt.show()
程序执行结果:观察发现循环进行到20轮左右,损失值就基本达到平稳。

2、随机梯度下降法(Stochastic Gradient Descent Algorithm)
随机梯度下降法,其选取的是随机的一个样本的损失,Loss。而并不是平均损失,因为随机样本中可能有噪声(会导致陷入局部最优),不会再在鞍点时停止不前,并且训练量也没那么大。
下图表示所有样本进行梯度下降法(上两个图),单个样本进行随机梯度下降法(下两个图)的区别。注意仔细观察字母的区别。

程序实现随机梯度下降法:
import matplotlib.pyplot as plt
x_data = [1.0, 2.0, 3.0]
y_data = [2.0, 4.0, 6.0]
w = 1.0 #w初值
#预测,得到的是y预测值
def forward(x):
return x * w
# calculate loss function
def loss(x, y):
y_pred = forward(x)
return (y_pred - y) ** 2
#要始终记住梯度是:损失函数Loss对权重W的导数
# define the gradient function sgd,取一个样本的梯度
def gradient(x, y):
return 2 * x * (x * w - y)
epoch_list = []
loss_list = []
print('predict (before training)', 4, forward(4))
for epoch in range(100):
for x, y in zip(x_data, y_data):
grad = gradient(x, y)
w = w - 0.01 * grad # update weight by every grad of sample of training set
print("\tgrad:", x, y, grad) #打印每一个样本的梯度
l = loss(x, y)
print("progress:", epoch, "w=", w, "loss=", l)
epoch_list.append(epoch)
loss_list.append(l)
print('predict (after training)', 4, forward(4))
plt.plot(epoch_list, loss_list)
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
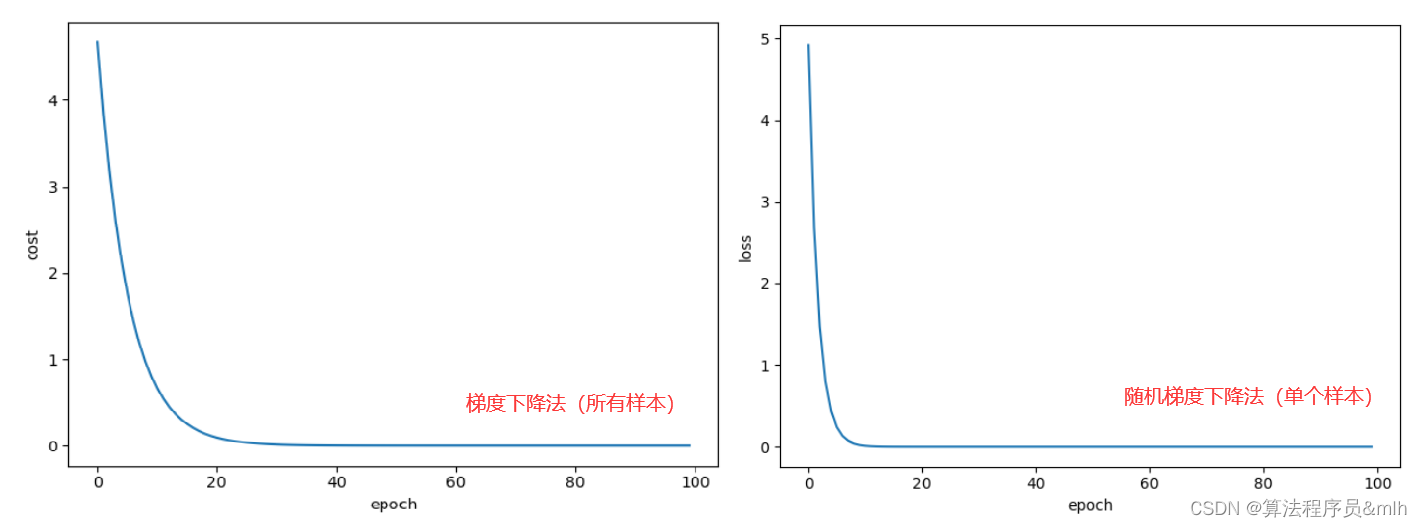
结论:可以观察到随机梯度下降法循环的轮数比所有样本进行梯度下降法的轮数少,最后的损失值也较少。故随机梯度下降算法的效果较好。
优点:训练速度快;
缺点:准确度下降,并不是全局最优;不易于并行实现
3、批量梯度下降法(Batch Gradient Descent Algorithm)
批梯度下降法(Batch Gradient Descent)针对的是整个数据集,通过对所有的样本的计算来求解梯度的方向。
批量梯度下降法的损失函数为:

进一步得到批量梯度下降的迭代式为:

每迭代一步,都要用到训练集所有的数据,如果样本数目很大,那么可想而知这种方法的迭代速度!
优点:全局最优解;易于并行实现;
缺点:当样本数目很多时,训练过程会很慢。
4、小批量梯度下降法(Mini-Batch Gradient Descent Algorithm)
在每次的迭代过程中利用部分样本代替所有的样本,基于这样的思想,便出现了mini-batch的概念。比如,假设训练集中的样本的个数为1000,则每个mini-batch只是其一个子集,假设,每个mini-batch中含有10个样本,这样,整个训练数据集可以分为100个mini-batch。
引入mini-batch后,训练速度有所提升,没有那么慢了。
5、通俗的理解梯度下降
(1)批量梯度下降—最小化所有训练样本的损失函数(对全部训练数据求得误差后再对参数进行更新),使得最终求解的是全局的最优解,即求解的参数是使得风险函数最小。批梯度下降类似于在山的某一点环顾四周,计算出下降最快的方向(多维),然后踏出一步,这属于一次迭代。批梯度下降一次迭代会更新所有θ(上面的w),每次更新都是向着最陡的方向前进。
(2)随机梯度下降—最小化每条样本的损失函数,虽然不是每次迭代得到的损失函数都向着全局最优方向, 但是大的整体的方向是向全局最优解的,最终的结果往往是在全局最优解附近。随机也就是说我用样本中的一个例子来近似我所有的样本,来调整θ(上面的w),其不会计算斜率最大的方向,而是每次只选择一个维度踏出一步;下降一次迭代只更新某个θ(上面的w),报着并不严谨的走走看的态度前进。
注意:在神经网络中默认的反向传播过程,就是计算每个计算图的梯度,也就是实现梯度下降的原理,其默认的是进行的mini-batch小批量梯度下降算法。

















 1643
1643

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









