






简单Huffman串行解码
由于Huffman不定长编码的可区分性,我们可以使用一个简单的序列检测状态机来对Huffman编码的文本进行解码。
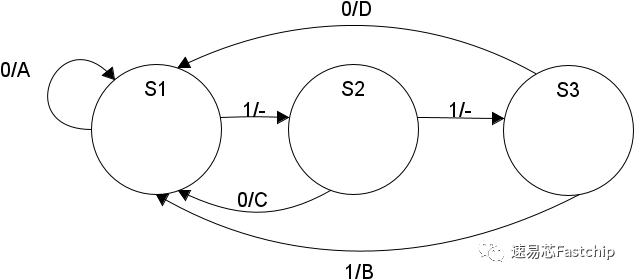
例如,对于上文提到的Huffman编码,我们可以使用以下Mealy状态机进行解码。
| B | D | C | A |
| 111 | 110 | 10 | 0 |
Huffman串行解码优化
上节中使用序列检测状态机解码的电路虽然简单,但解码的速率较低。解码一个n位的编码需要n个时钟周期。那么我们通过并行化的方式提高每个时钟周期解码的位数呢?
Keshab K. Parhi于1992在IEEE TCAS II上发表的论文(High-Speed VLSI Architecture for Huffman and Viterbi Decoders)中提出了一种对串行Huffman(Viterbi)编码解码状态机电路的优化方式。论文提出了一种基于前缀运算的串行检测并行/流水线化的方法,该方法可以用于Huffman编码和Viterbi编码的解码。本文将讲述其中改进Huffman解码电路的部分。
首先,论文中用到如下Huffman编码:
| a | b | c | d | e |
| 0 | 10 | 110 | 1111 | 1110 |
对应的解码状态机如下:

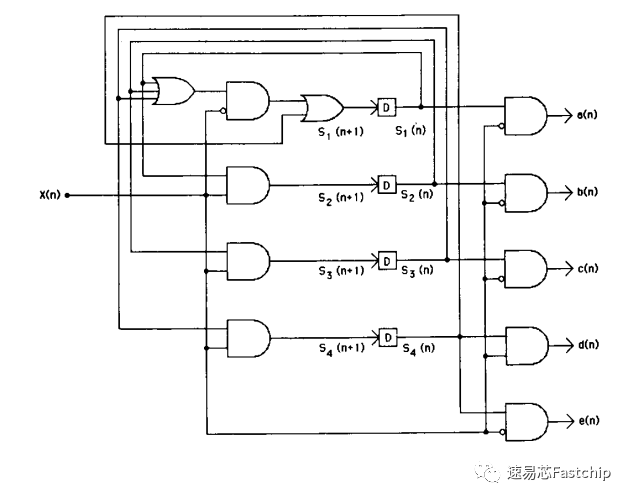
记当前状态为s(n),s(n)=[s1(n),s2(n),s3(n),s4(n)],例如s(n)=S1=[1,0,0,0],即独热编码。再记s(n+1)=s(n)T(n),则T(n)可以使用以下矩阵表示:

其中x(n)为待解码序列的第n位。
因此,对应的状态机输出(为了简单此处采用独热编码,但实际可以选取合适的编码方式)为:

例如:待解码的序列为c(110),已输入的序列为1,待输入的数据位为1,当前状态为s(n)=[0,1,0,0]=S2,T(n)如下:

则s(n+1)=s(n)T(n)=[0,0,1,0]=S3 且a(n)=b(n)=c(n)=d(n)=e(n)=0

则s(n+2)=s(n+1)T(n+1)=[1,0,0,0]=S1 且a(n)=b(n)=d(n)=e(n)=0,c(n)=1,序列解码为c。
状态机的硬件实现如下
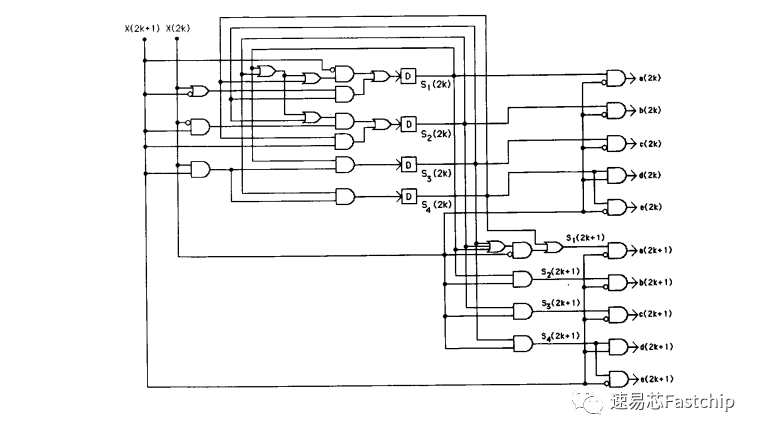
利用超前进位的技巧,上述状态转换式子可重写为s(n+2)=s(n)T(n)T(n+1),其中:

因此,我们可以在一个时钟周期内计算两次状态跳转(解码两位),同时计算s(n)和s(n+1)以及对应的a(n),b(n),c(n),d(n),e(n)以及a(n+1),b(n+1),c(n+1),d(n+1),e(n+1),以此将解码速度提升为原来的两倍。得到的状态机硬件如下:
作者:速易芯李昊翔















 4万+
4万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











