







一、单列集合继承关系

二、collection集合
API文档

注意:addAll方法,集合a.addAll(集合b),将集合b倒入到集合a中。
集合a.toArray()将集合转成数组。
遍历
1.迭代器遍历
Iterator<String> it=list.iterator();
while(it.hasNext()){
String a=it.next();
System.out.print(a);
}
//错误代码
//判断了一次,移动了两次next
Iterator<String> it=list.iterator();
while(it.hasNext()){
System.out.print(it.next());
System.out.print(it.next());
}2.增强for循环遍历
3.lamda表达式
// arr.forEach(new Consumer<String>() {
// @Override
// public void accept(String s) {
// System.out.println(s);
// }
// });
// arr.forEach((String s)->{
// System.out.println(s);
// });
// arr.forEach(s-> System.out.println(s));
arr.forEach(System.out::println);三、collection底层实现
1.ArrayList
基于数组实现,查询快、增删慢(需要移动元素)、数组长度不够会扩容到1.5倍
2.LinkedList
基于双链表实现,java中多用双向链表,查询慢(双向比单向快),增删快(不用移动)
对头尾位置进行增删改查的顺序极快,因为可以快速定位首尾
方法:增删改查快addFirst()、addLast()、getFirst()、getLast()、removeFirst()、removeLast()
业务应用:队列,栈。对首尾操作频繁。
LinkedList<Integer> a=new LinkedList<>();
//队列
// 入队
a.addLast(1);
a.addLast(2);
a.addLast(3);
a.addLast(4);
a.addLast(5);
System.out.println(a);
// 出队
a.removeFirst();
a.removeFirst();
System.out.println(a);
LinkedList<Integer> b=new LinkedList<>();
//栈
//入栈 也可以调用push
b.addFirst(1);
b.addFirst(2);
b.addFirst(3);
b.addFirst(4);
// b.addFirst(5);
b.push(5);
System.out.println(b);
//出栈 pop
b.removeFirst();
b.removeFirst();
// b.removeFirst();
b.pop();
System.out.println(b);
}3.HashSet
什么是哈希值?
每个对象都有一个哈希值,可以认为是一个标记,哈希值是一个int类型的值,不同对象的哈希值大概率不同,也有可能相同(哈希碰撞)
jdk8之前:数组+链表
哈希表:增删改查性能都较好
- 首先创建一个长度为16的数组
- 添加元素,这个元素对16求余,确定该元素存放的位置
- 判断算出来的位置有没有值,有值就调用equals方法比较,相同不存,不同使用拉链法存储
问题:如果存的数据过多怎么办?
有一个默认的加载因子0.75,当存的长度大于16X0.75时,会对数组进行扩容,一般会扩成原来的两倍。
jdk8之后:数组+链表+红黑树
如果链表过长,会影响性能。JDK8开始,当链表长度超过8,数组长度>=64时,就会将链表转成红黑树存储。
存的元素无法比较大小怎么转红黑树?
使用哈希值比较大小转红黑树。使用红黑树是因为红黑树在java内部实现是一个子平衡的二叉树,性能更好。
问题:hashset去重原理?
hashset会判断存入的对象是不是hashcode一样,hashcode一样再调用equals方法,判断值是不是一样。如果值也一样,就判断为同一个对象。
实际上,两个对象只有值一样同样会被报存两次。那么怎么实现去重呐?
要重写equals和hashcode方法。
4.Linkedhashset
有序是指的是按照放入的顺序排序
底层实现:哈希表+数组+链表
在hashset的基础上给每个结点增加了指向上一个元素和下一个元素的指针。这样每个结点存放的信息就更多了,更占内存。
5.TreeSet
默认大小排序,无索引,不重复。
按照大小排序(String按首字母)是通过红黑树实现的,输出时按照左下角最小的元素开始遍历。
问题:如果向treeset中添加自定义对象,需要定义排序顺序。
方法一:实现comparable接口,重新compareTo方法。

方法二:调用Treeset有参构造器,设置Comparator比较器对象。

集合的并发修改异常。本质原因:删除一个元素之后,集合中的后一个元素前移,遍历指针同时后移,一下子走了两步。
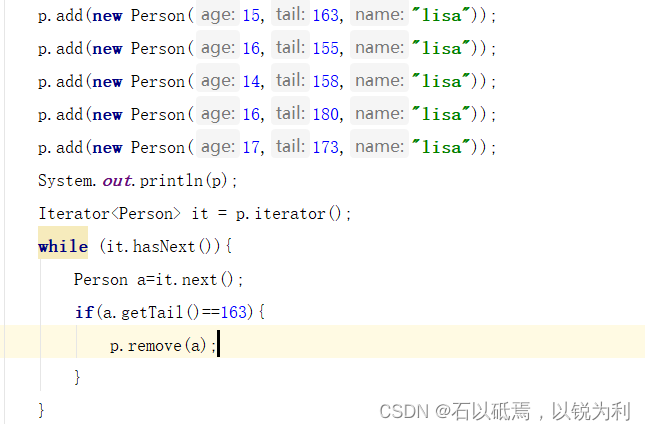

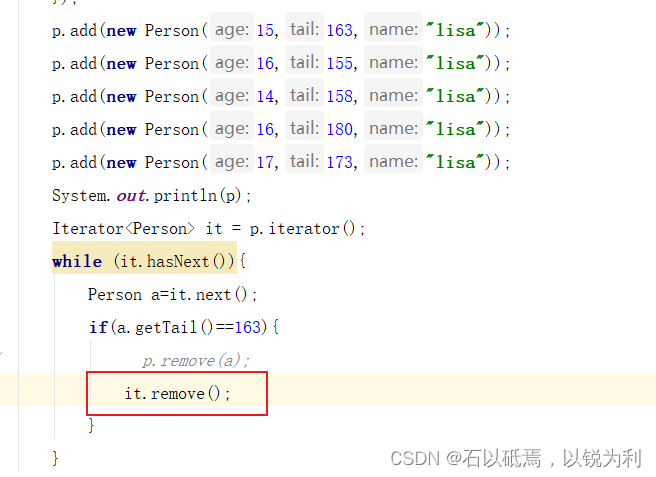
解决:使用迭代器自己的删除方法,相当于每删除一次,遍历的指针前移一位。
四、双列集合继承关系
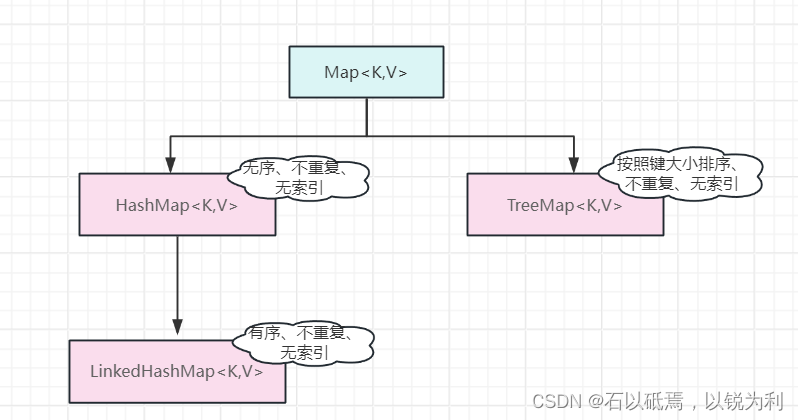
Map方法
put(K,V) size() clear() isEmpty() get(K) remove(K) containsKey(K) containsValue(V)
keySet() values() map1.putAll(map2)
遍历
//1.键找值遍历
Set<String> set = map.keySet();
for (String s : set) {
Integer k=map.get(s);
System.out.println(s+"========="+k);
}// 2.键值对遍历
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> entry : entries) {
System.out.println(entry);
} //3.lamada表达式
map.forEach((k,v)->{
System.out.println(k+"========"+v);
});原理
map的底层原理和set一样,set实际上在java底层是只要key部分的map。map每个结点存的是entry对象保存key和value。















 1125
1125

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









