







-
问题描述
平面上有两摊墨渍,它们的颜色分别是黄色和蓝色,墨渍分类问题就是是根据点的坐标,判断其染上的颜色。从Sklearn的数据库中获取墨渍数据,每条数据是平面上的一个点,特征组(即特征向量)为该点的坐标,标签为该点的颜色,0表示黄色,1表示蓝色.

-
实验目的
1、调用用Sklearn的make_blobs()读取m个墨渍数据。实验目的
2、调用Sklearn的train_test_split(),划分训练数据和测试数据分别为test_size=0.5, 0.4, 0.3, 0.2。
3、实现感知器类,在训练数据上训练感知器,输出模型的参数。用训练好的模型在测试数据上进行测试,输出模型的Accuracy。
4、分别画出训练数据、测试数据上的分离线。
-
实验内容
包括数据导入、数据预处理、算法描述、主要代码。
- 数据导入
| # 生成墨迹 |
2.数据预处理
用感知器类去解决墨渍问题:
| import numpy as np |
3.算法描述
Step1:使用sklearn工具库中的make_blobs函数为聚类产生数据集,产生一个数据集和相应的标签。并生成相应的墨渍。
Step2:生成训练模型和训练数据。使用感知器算法生成训练模型,定义一个Perceptron类,提供两个成员函数:fit函数和predict函数;函数fit的功能是训练模型并储存训练得到的参数;函数predict的功能是用训练好的模型对给定数据进行预测。
Step3:生成测试模型和测试数据。
Step4:得出结论。
4.主要代码
1、感知器算法(Perceptron.py)
| import numpy as np |
- 墨渍分类(Ink.py)
| # 墨渍数据从Sklearn获取 |
-
实验结果及分析
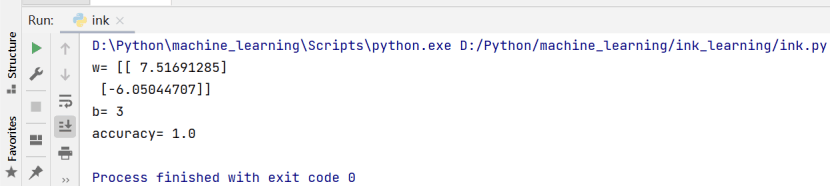
(1)训练数据和测试数据为test_size=0.5。
1、训练数据和测试数据的区分效果对比:

2、输出模型的参数w,b,Accuracy:
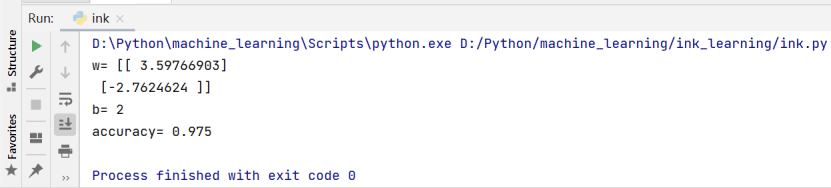
(2)划分训练数据和测试数据为test_size=0.4。
1、训练数据和测试数据的区分效果对比:

2、输出模型的参数w,b,Accuracy:
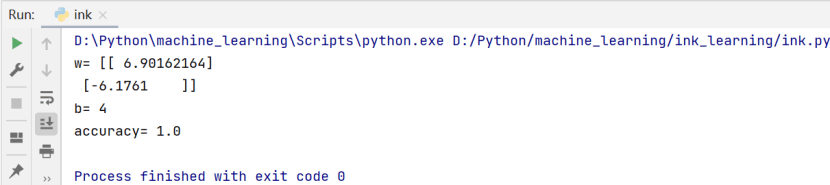
(3)划分训练数据和测试数据为test_size=0.3。
1、训练数据和测试数据的区分效果对比:

2、输出模型的参数w,b,Accuracy:
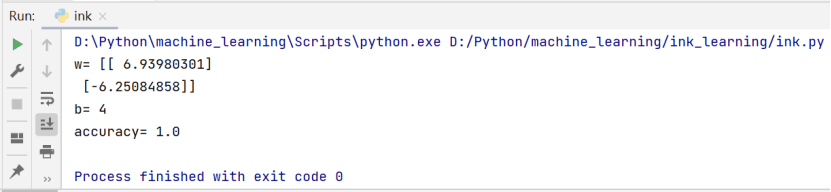
(4)划分训练数据和测试数据为test_size=0.2。
1、训练数据和测试数据的区分效果对比:

2、输出模型的参数w,b,Accuracy:
-
遇到的问题和解决方法
- 根据以上实验所得,模型虽然在训练数据上预测的是完全正确的,但是划分训练数据和测试数据为test_size=0.4时,分离直线未能完全分离墨渍的两个特征,从而出现了误差,这也说明对模型的效果的度量应该在测试数据中进行,在测试数据中的准确率才是对模型正确的度量。
- 这说明使用监督式学习算法效果的度量方法,用模型h对x的标签值做预测时,预测值与真实情况可能存在误差,会产生过度拟合。
- 如何预防过度拟合:
通过对模型进行假设,从而降低过度拟合;
使用正则化算法避免过度拟合。

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











