







01 数据容器概念
Python中的数据容器:一种可以容纳多份数据的数据类型,容纳的每一份数据称之为一个元素,每一个元素的数据类型可以是任意的,比如:字符串、数字、布尔(甚至可以还是容器)等
数据容器的不同特点:
是否可以支持重复元素
是否可以修改
是否有序
常见的数据容器:列表-list、元组-tuple、字符串-str、集合-set、字典-dict
02 列表list使用
列表的定义
示例:
# 定义空列表
list1 = []
print(list1, type(list1))
list2 = list()
print(list2, type(list2))
# 定义非空列表
list3 = [1, 2, 3, 4, 5, 6, 7, 8, 9]
print(list3, type(list3))
# 定义嵌套列表
list4 = [list1, list2, list3]
print(list4, type(list4))总结:
定义空列表:[] 或者 list()
定义非空列表:[元素1, 元素2, ........]
元素的数据类型没有限制,甚至元素本身也可以是列表(嵌套列表)
列表的索引
示例:
# 定义空列表
list1 = []
print(list1, type(list1))
list2 = list()
print(list2, type(list2))
# 定义非空列表
list3 = [1, 2, 3, 4, 5, 6]
print(list3, type(list3))
# 定义嵌套列表
list4 = [list1, list2, list3]
print(list4, type(list4))
# 需求查询list3的第一个元素
print(list3[0])
print(list3[-6])
# 需求:查询list3中的最后一个元素
print(list3[5])
print(list3[-1])
# 需求:在list4中查询list3中的倒数第二个元素
# 可以根据列表的长度取元素(从后取),更常用使用场景是遍历列表
# 固定用法取最后一个元素:-1
print(list4[2][4])
print(list4[-1][-2])
print(list4[2][-2])
print(list4[-1][4])总结:
列表的每一个元素都有一个编号称之为下标索引
编号从前向后从0开始依次递增
编号从后向前从-1开始依次递减
可以下标索引取出列表中对应位置的元素:列表[下标]
取元素时如果超出列表的下标索引位置范围,会报错:IndexError: list index out of range
列表的操作
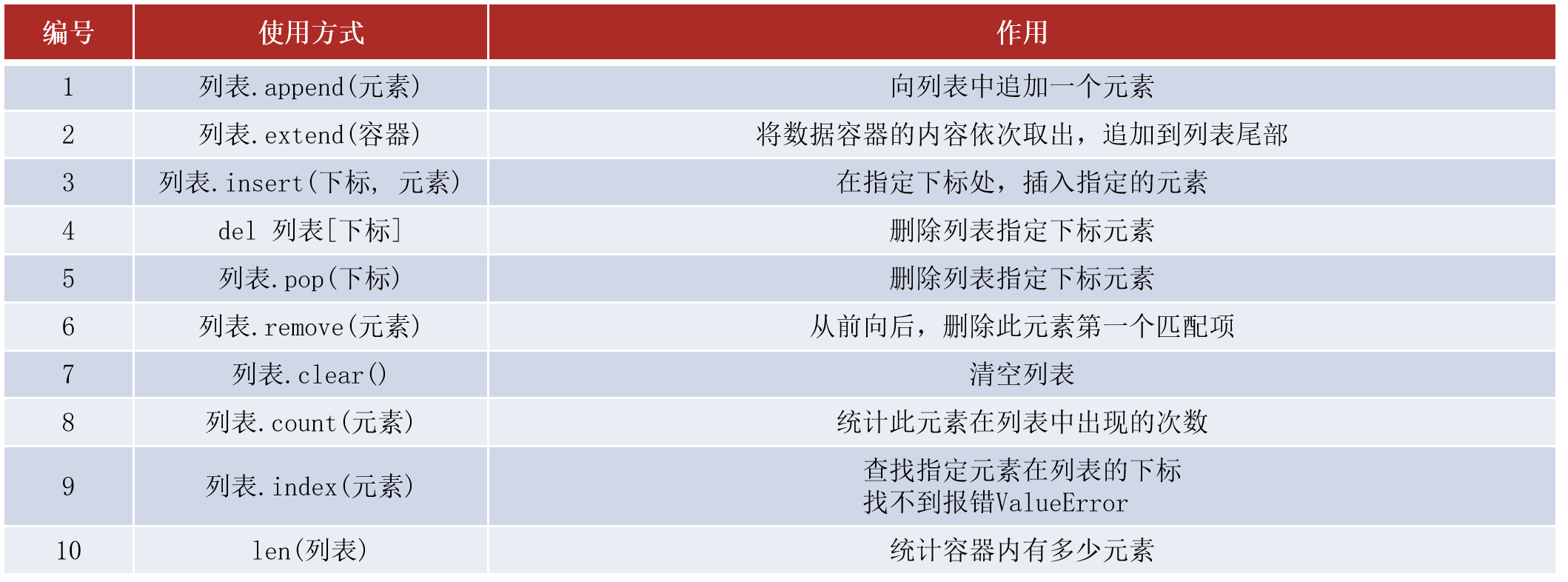
示例:
# 定义一个空列表,用于储存姓名
name_list = []
print(name_list)
"""
增加元素
insert: 插入元素到指定位置
append: 追加1个元素至列表的末尾
extend: 追加多个元素(列表中的元素)至列表的末尾
"""
name_list.insert(0, "李明")
print(name_list)
name_list.append(["张三", "李四"])
print(name_list)
name_list.extend(["赵六", "王五"])
print(name_list)
"""
修改元素
列表[下标] = 新值
"""
name_list[0] = "麻子"
print(name_list)
"""
查询元素
列表[下标]: 根据下标索引查找元素
index: 查找指定元素的下标 注意:如果没有就报错
len: 查询列表中元素的个数(列表的长度)
count: 查询某个元素的个数 注意:如果没有返回0个
"""
print(name_list[0])
print(name_list.index("麻子"))
# 可以根据列表的长度取元素(从后取),更常用使用场景是遍历列表
# 固定用法取最后一个元素:列表[len(列表) - 1]
print(len(name_list))
print(name_list[len(name_list) - 1])
"""
删除元素
del 列表名[下标]: 删除指定位置的元素
pop: 删除指定位置的元素
remove: 直接删除指定的元素
clear: 清空列表(仅删除列表中的所有元素)
del 列表名: 直接删除整个列表
"""
del name_list[0]
print(name_list)
name_list.pop(-1)
print(name_list)
name_list.remove("赵六")
print(name_list)
name_list.clear()
print(name_list)
del name_list
# print(name_list)总结:
增加元素:
append:追加1个元素至列表的末尾
extend:扩展多个元素至列表的末尾
insert:插入1个元素到列表指定位置(如果指定位置大于当前列表中的最大范围,会直接插入到最后位置,如果插入的是当前列表的中间位置,这个位置后面的所有元素都自动向后移一位)
删除元素
del 列表名[下标]:删除指定位置的元素,这个位置后面的所有元素会自动向前移位
pop:删除指定位置的元素
remove:直接删除指定的元素
clear:清空列表,删除列表中所有的元素
del 列表名:直接删除列表,列表就不可再被使用了
修改元素
列表名[下标] = 新值
查询元素
列表名[下标]:根据下标索引查找对应的元素
len(列表):查询列表的元素的个数(列表的长度)
列表名.count(元素):查询指定元素在列表中的个数 注意:如果没有返回0个
列表名.index(元素):查询指定元素对应的下标 注意:如果没有就报错
列表的遍历
示例:
# 定义列表
name_list = ['张三', '李四', 'wangwu', 3, 5, 6, True]
# 方式一while循环遍历列表
# 定义初始下标
x = 0
# 循环判断
while x < len(name_list):
# 循环体处理列表中的元素
print(name_list[x])
# 控制语句
x += 1
# 方式二
# for循环控制语句
for i in name_list:
print(i)
总结:
容器的遍历是指将容器内的元素依次全部并处理
遍历列表的方法:
while循环:
定义变量作为初始下标,从0开始
循环条件为:下标值 < 列表的元素数量
for循环:for 临时变量 in 数据容器:
for循环对比while循环
for循环更简单,while更灵活
for循环用于从容器中依次取出元素并处理
while用以任何需要循环的场景
-
取出列表中的偶数
示例:
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 方式一:while循环遍历
# 定义新的列表用于保存偶数
list2 = []
# 定义初始下标变量,从0开始
x = 0
# 使用while循环输出list1中的偶数添加到list2中
while x < len(list1):
# 循环体
if list1[x] % 2 == 0:
list2.append(list1[x])
# 控制语句
x += 1
print(list2)
# 方式二:for循环遍历
# 定义新的列表用于保存偶数
list3 = []
# 使用for循环输出list1中的偶数添加到list3中
for i in list1:
# 循环体
if i % 2 == 0:
list3.append(i)
print(list3)列表的特点
可以容纳多个元素(上限为:2**63 - 1,9,223,372,036,854,775,807)
可以容纳不同类型的元素(混装)
数据是有序存储(有下标序号)
允许重复数据存在
可以修改(可以增加或者删除数据等)
列表是可变的数据类型
03 元组tuple使用
元组的定义
示例:
# 定义空元组
t1 = ()
print(t1, type(t1))
t2 = tuple()
print(t2, type(t2))
# 定义非空元组
t3 = (10,) # 如果元组中只有一个元素,必须加逗号
print(t3, type(t3))
t4 = (1, 2, 3, 4, 5)
print(t4, type(t4))
# t4[0] = 5
# TypeError: 'tuple' object does not support item assignment
print(t4[0])
# 定义嵌套元组
t5 = (t1, t2, t3, t4)
print(t5)总结:
定义空元组:()或者tuple()
定义非空元组:(元素1, 元素2, 元素3.......)
注意:如果元素只有1个,也必须加逗号,元组中可以存储不同类型的数据
元组的索引
示例:
# 定义非空元组
name_tuple = ('张三', '李四', '王五', 3)
# 需求:获取元组中的第一个元素
print(name_tuple[0])
# 需求:获取元组中的最后一个元素
print(name_tuple[-1])
print(name_tuple[3])
print(name_tuple[len(name_tuple) - 1])
# 定义嵌套元组
big_tuple = (name_tuple, (10, 20, 30), [10, 20, 30])
print(big_tuple)
print(big_tuple[2][0])
big_tuple[2][0] = 100
print(big_tuple)
# TypeError: 'tuple' object does not support item assignment
# big_tuple[2] = 'hello'总结:
元组的下标索引同列表一样就是元组中每个元素对应的编号
注意:元组同列表一样有两套编号
正索引:从0开始从左至右依次递增
负索引:从-1开始从右至左依次递减
元组的操作
示例:
# 定义非空元组
name_tuple = ('张二', '张三', '李四', '王五', 3)
# 查询元组中有多少个元素
print(len(name_tuple))
# 查询 张三 出现的次数
# 如果没有就返回0
print(name_tuple.count('张三'))
# 查询 张三 对应的索引下标
# 如果没有就报错,如果有多个返回第一个元素的索引下标
print(name_tuple.index('张三'))
del name_tuple
# print(name_tuple)总结:
元组名[索引]:根据索引下标查找对应的元素
len(元组):查询元组中的元素个数
元组.count(元素):查询指定元素在元组中出现的次数,如果没有返回0个
元组.index(元素):查询指定元素对应的索引下标,如果没有就报错
元组的遍历
示例:
# 定义非空元组
name_tuple = ('张山', '张三', '李四', '王五', 3)
# 方式一:for循环遍历
for i in name_tuple:
print(i)
print('-' * 30)
# 方式二:while循环遍历
# 定义初始下标索引,从0开始
a = 0
# 根据条件进行循环判断
while a < len(name_tuple):
print(name_tuple[a])
# 条件控制语句
a += 1总结:
同列表一样可以使用while和for循环进行遍历
元组的特点
可以容纳多个数据
可以容纳不同类型的数据(混装)
数据是有序存储的(有下标索引)
允许重复数据存在
不可以修改
支持while和for循环
元组是不可变的数据类型
04 字符串str使用
字符串的定义
示例:
# 定义空字符串
s1 = ''
s2 = ""
s3 = """"""
s4 = ''''''
s5 = str()
print(s1, s2, s3, s4, s5)
# 定义非空字符串
s6 = 'abcd1234'
print(s6, type(s6))
# 字符串包含双引号和单引号
l1 = ['1', '2']
s7 = "'张三'"
s8 = '"张三"'
s9 = "\"张三"
s10 = "l1"
print(s7, s8, s9, s10)总结:
定义空字符串:‘’ “” “”“”“” ‘’‘’‘’ str()
注意:字符串中只能存入字符串
字符串的下标
示例:
# 定义非空字符串
s1 = 'My name is John'
# 查询字符串中第一个字符
print(s1[0])
print(s1[-15])
# 查询字符串的最后一个字符
print(s1[14:15])
print(s1[-1])
print(s1[14])总结:
字符串的下标索引其实就是字符串中每个字符元素的编号
注意:
正索引:从0开始从左至右依次递增
负索引:从-1开始从右至左依次递减
字符串的操作
示例:
# 定义非空字符串
s1 = 'My name is John'
# 需求:统计字符'a'字符出现的次数
print(s1.count('a'))
# 需求:统计字符'a'的索引下标
# 注意:如果有多个返回第一个元素的索引下标,如果没有直接报错
print(s1.index('a'))
# 需求:统计字符串中一共有多少个字符
print(len(s1))
print("-" * 30, '字符串特殊操作')
s2 = '你***的, 我###!'
# 需求:使用replace替换字符串中的敏感词:已知字符串"你***的, 我###!",将其中的敏感词替换成:"你好聪明的,我真佩服!"
s3 = s2.replace('***', '好聪明').replace('###','真佩服') # 可以采用链式编程方式调用多次replace
print(s3)
# 需求:使用split切割字符串,已知字符串:"苹果,香蕉,火龙果,西瓜",要求把各类水果放入到列表中
s4 = "苹果,香蕉,火龙果,西瓜"
# s4.split(字符串) 括号中的字符串就是切割的依据
s4_list = s4.split(',')
print(s4_list)
# 需求:使用join拼接容器中元素
s5 = '123'.join(s4_list)
print(s5, type(s5))
# 需求:去除字符串两端的空白字符,包括空格、制表符、换行符等(去除前后空白包含空格、\t等)
s6 = ' 张三,18 '
print(s6.strip())
# 需求:startswith判断是否以指定的字符串开头,判断给定的字符串是否以'it'开头
s7 = "my name is John"
print(s7.startswith('my'))
# 需求:endswith判断是否以指定的字符串结尾,判断给定的字符串是否以'it'结尾
print(s7.endswith('n'))
# 需求:将所有的小写转换大写
print(s7.upper())
# 需求:将所有的大写转换小写
print(s7.lower())
# 需求:查找指定字符在字符串中的索引
# 使用find查找字符如果没有返回-1
# print(s7.index('i'))
print(s7.find('m'))
# rfind是从后往前查找对应字符的索引位置
print(s7.rfind('m'))
s8 = s7.upper()
print(s8.isupper())字符串的遍历
示例:
# 定义非空字符串
s1 = 'abcde'
# 方式一:for循环遍历
for s in s1:
print(s)
# 方式二:while循环遍历
# 定义初始变量
i = 0
while i < len(s1):
print(s1[i])
i += 1字符串的特点
只能存储字符串(多个字符),不支持存储任意类型
字符串的长度任意(取决于内存大小)
支持下标索引
允许重复字符存在
不可以被修改,如果修改会返回一个新的字符串
支持while和for循环遍历
字符串是不可变数据类型
05 序列的切片
序列的概念
序列概念:内容连续、有序可以通过下标索引访问的数据容器
常见序列:列表、元组、字符串
序列的切片
序列都支持切片
语法:序列[起始下标:结束下标:步长]
表示从序列中,从指定位置开始,按照步长依次取出元素,到指定位置结束(不包含),得到一个新序列
起始下标表示从何处开始,可以留空,留空视作从头开始
结束下标(不包含)表示从何处结束,可以留空,留空视作截取到结尾
步长表示依次元素的间隔
默认步长为1,一个一个取出元素
步长为2,表示每次跳过1个元素
步长为N,列示每次跳过N-1个元素
步长为负数,表示反向取
示例:
# 定义非空列表
nums = ['a', 'b', 'c', 'd', 'e']
# 需求:取出所有的元素作为新的序列
print(nums)
print(nums[::])
print(nums[::1])
print(nums[0::1])
print(nums[0:len(nums):1])
# 需求:取出a b c
print(nums[:3:])
print(nums[0:3:1])
print(nums[-len(nums):3:1])
print(nums[-len(nums):-2:1])
# 需求:取出 b c
print(nums[1:3:])
print(nums[1:3:1])
print(nums[-4:-2:1])
print(nums[-4:3:1])
# 需求:取出a c e
print(nums[::2])
print(nums[0:5:2])
print(nums[-5:5:2])
print(nums[-5::2])
# 需求: d c
print(nums[-2:-4:-1])
print(nums[3:1:-1])
# 需求:反转字符串
print(nums[::-1])
# 需求:d b
print(nums[-2:-5:-2])
print(nums[-2:0:-2])
print(nums[3:0:-2])序列的拼接
示例:
# 定义字符串
s1 = 'abc'
s2 = 'bcd'
s3 = s1 + s2
print(s3)
print(s3 * 2)
# 定义列表序列
l1 = ['a', 'b', 'c']
l2 = ['b', 'e', 'g']
l3 = l1 + l2
print(l3)
print(l3 * 2)
# 定义元组序列
l1 = ('a', 'b', 'c')
l2 = ('b', 'e', 'g')
l3 = l1 + l2
print(l3)
print(l3 * 2)06 集合set操作
集合的定义
示例:
# 定义空集合
s1 = set()
s2 = {}
print(s1, type(s1))
print(s2, type(s2))
# 注意{}不能代表空集合只能代表空字典
# 定义非空集合
s3 = {'张三', '李四', '王五', '赵六'}
print(s3, type(s3))
# 定义嵌套非空集合
# set集合去重是根据元素的hash哈希值进行去重
# 嵌套列表和集合不支持,嵌套元组和字符串可以
l1 = ['a', 'b', 2]
t1 = ('a', 'b', 2)
s4 = {t1, '张三', '张三'}
print(s4, type(s4))总结:
定义空集合:set() 因为{}代表空字典
定义非空集合:{元素1, 元素2......}
set集合可以嵌套字符串和元组,不可以嵌套集合和列表
集合的操作
示例:
# 定义空集合
nums = set()
print(nums)
# 增加元素如果重复增加会被自动去重
nums.add(10)
nums.add(11)
nums.add(12)
nums.add(10)
print(nums)
# 查询元素
print(len(nums))
# 遍历集合
for num in nums:
print(num)
# 修改元素
# 求集合的差集
# difference_update是 Python 中的一个集合操作方法,用于移除一个集合中包含在另一个集合中的所有元素。
# 它与 difference 方法相似,不同的是 difference 方法返回一个新集合,
# 而 difference_update 直接在原集合上进行修改。
new_nums = nums.difference({10, 50})
print(new_nums)
nums.difference_update({10, 12})
print(nums)
# 更新增加元素
nums.update({10, 11})
print(nums)
# 求两个集合的并集
s1 = {1, 2, 3}
s2 = {4, 1, '1'}
s3 = s1.union(s2)
print(s3)
# 移除集合中的数据
print(s3.remove(3))
print(s3)
# 删除元素
print(s3.pop())
print(s3)
print(nums.clear())
print(nums)
del nums
# print(nums)总结:
增
add(元素):把指定的元素添加到集合中(无序)
删
remove(元素):删除指定元素
pop():随机删除元素
clear():清空集合中所有元素
del 集合名:删除整个集合
改
集合1.difference_update(集合2):将集合1中与集合2中相同的元素从集合1中删除
集合3=集合1.difference(集合2):将集合1中与集合2中相同的元素从集合1中删除后返回新集合
集合1.update(集合2):把指定集合中的元素添加到原有集合中
集合3=集合1.union(集合2):将集合1和集合2中的不同元素合并到一直返回一个新的集合
查
len(集合):查看集合的长度
集合的特点
可以容纳多个数据元素
可以容纳不同的数据类型(混装)
数据是无序存储的(不支持下标索引)
不允许重复数据存在
可以修改(支持增加或者删除元素)
支持for循环遍历,不支持while循环遍历
是可变的数据类型
07 字典dict使用
字典的定义
示例:
# 定义空字典
d1 = {}
print(d1, type(d1))
d2 = dict()
print(d2, type(d2))
# 定义非空字典
# 注意:如果key重复,后面的value就会覆盖前面的value
d3 = {"张三": 100, "李四": 85, "王五": 85, "李明": 56}
print(d3, type(d3))
# 定义嵌套字典
# 注意:字典的key不能是可变数据类型:列表、集合、字典
d4 = {
"张三": {"语文": 95, "数学": 69, "英语": 89},
"李四": {"语文": 97, "数学": 79, "英语": 99},
"王五": {"语文": 77, "数学": 65, "英语": 79}
}总结:
定义空字典:{} 或者dict()
定义非空字典:{k1:v1, k2:v2, k3:v3.........}
注意:
键值对的key和value可以是任意数据类型(但是key不能是可变数据类型:列表、集合、字典)
字典内的key不允许重复,如果重复添加相同的key,后面value会自动覆盖前面的value
字典不能使用下标索引,而是通过key检索value
Json字符串
JSON 是轻量级的文本数据交换格式
python中json模块:可以操作转换json字符串
json字符串与字典转换:
import json
# 将json字符串转换为字典
# 定义json字符串
json_str = '{"张三":99,"李四":100,"王五":92,"赵六":95}'
print(json_str, type(json_str))
print(json.loads(json_str))
print("-" * 90)
# 字典转为字符串
s1 = {
"张三": {"语文": 95, "数学": 79, "英语": 86},
"李四": {"语文": 98, "数学": 86, "英语": 95},
"王五": {"语文": 98, "数学": 86, "英语": 95}
}
print(s1, type(s1))
# 中文会转换为字节码
print(json.dumps(s1))字典的操作
示例:
# 定义空字典
score_dict = {}
# 添加数据
# 字典名[新的key] = 值
score_dict['张三'] = 100
score_dict['李四'] = 99
print(score_dict)
# 修改数据
# 字典名[已经存在的key] = 值
score_dict['张三'] = 66
print(score_dict)
# 查询数据
# 查询张三的分数
# 方式一:字典名[key] 返回对应的值,当key不存在时会报错
# 方式二:字典名.get(key[, 默认值]) 返回对应的值,
# 当key不存在时会返回默认值(默认是None,可以随意设置),当在语法中看[]时表示参数可选
print(score_dict['张三'])
print(score_dict.get('王五', '阿斯弗'))
# 查询字典的长度
print(len(score_dict))
# 删除数据
print(score_dict.pop('张三'))
print(score_dict)
print(score_dict.clear())
print(score_dict)
del score_dict
# print(score_dict) NameError: name 'score_dict' is not defined总结:
增加数据:字典名[新key] = 值
修改数据:字典名[旧key]=值
删除数据:
字典名.pop(key):删除指定key对应的键值对
字典名.clear():清空字典中所有的数据
del 字典名:删除整个字典
查询数据:
字典名[key]:根据指定的key返回对应的value值,当key不存在时会报错
字典名.get(key):根据指定的key返回对应的value值,当key不存在时返回默认值None(可以设置)
字典的遍历
示例:
# 定义非空字典
score_dict = {"张三": 89, "李四": 99, "王五": 91}
print(score_dict)
# 获取所有的key
keys = score_dict.keys()
print(keys, type(keys))
# 方式一:通过keys遍历字典
for key in keys:
# 根据key查询对应的value
print(key, score_dict[key])
# 获取所有的value
values = score_dict.values()
print(values, type(values))
# 方式二:通过value遍历字典
for value in values:
print(value)
# 获取所有的键值对
kvs = score_dict.items()
print(kvs, type(kvs))
# 方式三:可以通过键值对遍历字典,遍历获取到的元素是键值对元组
for kv in kvs:
print(kv, 'key为:', kv[0], ' 值为:', kv[1])
# 方式四:将键值对拆包遍历
for k, v in score_dict.items():
print(k, v)总结:
keys():获取所有的key键
values():获取所有的value值
items():获取所有的键值对,会把键和值封装成元组
可以通过for循环遍历keys、values、items,不能使用while循环
打包和拆包
所有容器都有拆包特性
示例:
# 打包
a = 10
b = 20
c = 30
my_t1 = (a, b, c)
print(my_t1)
# 拆包
x, y, z = my_t1
print(x)
print(y)
print(z)
# 需求:已知x=10和y=20,请替换两个变量的值x=20和y=10
x = 10
y = 20
# 使用第三个变量互换值
# temp = x
# x = y
# y = temp
# print(x, y)
# 使用打包和拆包的方法互换值
x, y = y, x
print(x, y)字典的特点
可以容纳多个数据
可以容纳不同的数据类型
每一份数据都keyValue键值对
可以通过key获取到对应的value值,key不能重复(重复会覆盖)
不支持下标索引
可以修改,是可变数据类型
支持for循环遍历,不支持while循环遍历
08 数据容器总结
各容器对比
| 列表 | 元组 | 字符串 | 集合 | 字典 | |
|---|---|---|---|---|---|
| 元素数量 | 支持多个 | 支持多个 | 支持多个 | 支持多个 | 支持多个 |
| 元素类型 | 任意 | 任意 | 仅字符 | 任意 | key:不可变类型 value:任意类型 |
| 下标索引 | 支持 | 支持 | 支持 | 不支持 | 不支持 |
| 重复元素 | 支持 | 支持 | 支持 | 不支持 | key:不支持 value:支持 |
| 可修改性 | 支持 | 不支持 | 不支持 | 支持 | 支持 |
| 数据有序 | 是 | 是 | 是 | 否 | 否 |
| 遍历方式 | for和while | for和while | for和while | for | for |
容器通用操作
示例:
# 定义列表
l1 = ['c', 'd', 'a', 'b']
# 定义字符串
str1 = ['c', 'd', 'a', 'b']
# 定义元组
t1 = ('c', 'd', 'a', 'b')
# 定义集合
set1 = {'c', 'd', 'a', 'b'}
# 定义字典
d1 = {'c': 1, 'd': 2, 'a': 3, 'b': 4}
# len()求元素个数
print(len(l1))
print(len(str1))
print(len(t1))
print(len(set1))
print(len(d1))
# 求容器的最大值
print(max(l1))
print(max(str1))
print(max(t1))
print(max(set1))
print(max(d1))
# 求容器的最小值
print(min(l1))
print(min(str1))
print(min(t1))
print(min(set1))
print(min(d1))
# sorted(容器):对容器中的所有元素进行排序,默认升序排序
print(sorted(l1))
print(sorted(str1))
print(sorted(t1))
print(sorted(set1))
print(sorted(d1))
# reverse默认为False,设置为True反转顺序进行倒序排序
print(sorted(l1, reverse=True))
print(sorted(str1, reverse=True))
print(sorted(t1, reverse=True))
print(sorted(set1, reverse=True))
print(sorted(d1, reverse=True))
# 拓展:列表的reverse()函数
print(sorted(l1))
print(l1.reverse())
print(l1)














 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









