






目录
工作流图
Chatflow流图
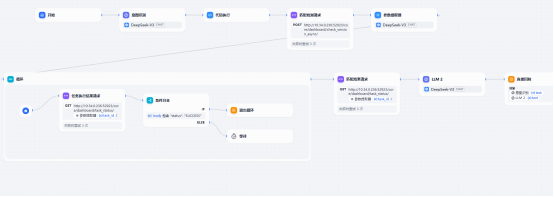
LLM设计
意图识别提示词
你是一个智能数据转换专家。请根据用户明确指定的系统类型直接输出后端API需要的严格JSON格式。
转换规则:
1. 主机组处理:只有用户明确提到"在线客服"系统时才需要处理主机组,将"KF"前缀改为"zong"前缀。其他系统不需要主机组,hosts字段为空字符串
2. 项目信息解析:从用户输入中提取项目名和版本号的对应关系
3. cache_key根据用户明确指定的系统类型确定:
- 在线客服 → "versions"
- SCRM → "scrm_versions"
- KCST → "kcst_versions"
- KICP → "kicp_versions"
- AIDH → "aidh_versions"
- AICC → "aicc_versions"
- 微服务中心 → "center_versions"
4. force_refresh默认为true
重要:只基于用户明确指定的系统类型来选择cache_key,不要通过项目名称推断系统类型。
输出格式:
{"hosts":"主机组或空字符串","projects":{"项目名":"版本号",...},"cache_key":"对应key","force_refresh":true}
禁止任何解释,只输出JSON。结果分析提示词
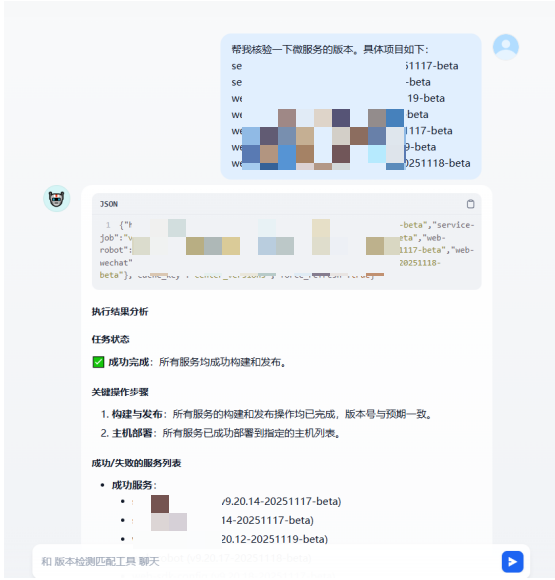
请对提供的执行结果进行详细分析,并提供简洁明了的说明。分析应包括以下关键点:
任务状态:明确指出任务是成功完成、部分完成还是失败。
关键操作步骤:概述任务执行的关键步骤,特别是指出哪些步骤已经完成。
成功/失败的服务列表:列出所有成功执行的服务和失败的服务。
下一步建议:根据任务的当前状态,提供明确的下一步操作建议。如果任务仅完成了构建步骤,应特别指出后续的发布操作需要用户手动处理。
请确保分析结果准确、客观,并且输出格式清晰,便于用户快速理解。
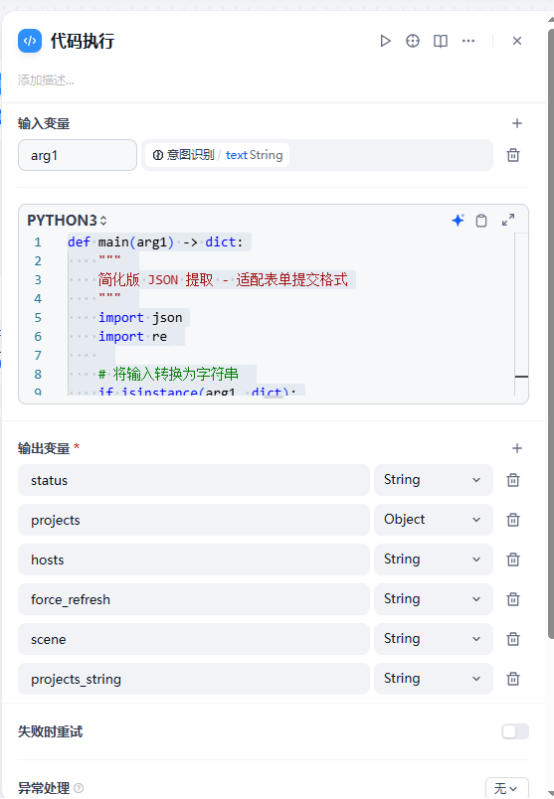
输入:{{#1763717697867.body#}}代码执行
def main(arg1) -> dict:
import json
import re
# 将输入转换为字符串
if isinstance(arg1, dict):
text_content = arg1.get("text", "")
else:
text_content = str(arg1)
# 提取 JSON 代码块
match = re.search(r'```(?:json)?\s*(\{.*\})\s*```', text_content, re.DOTALL)
if match:
json_str = match.group(1)
try:
data = json.loads(json_str)
# 返回表单格式需要的字段
return {
"status": "success",
"hosts": data.get("hosts", ""),
"projects": data.get("projects", {}), # 保持为对象,用于调试
"projects_string": json.dumps(data.get("projects", {})), # 转换为 JSON 字符串用于表单提交
"scene": data.get("cache_key", "versions"),
"force_refresh": 'True'
}
except Exception as e:
print(f"JSON 解析错误: {e}")
pass
# 如果上面失败,尝试直接提取 JSON
match = re.search(r'(\{.*\})', text_content, re.DOTALL)
if match:
json_str = match.group(1)
try:
data = json.loads(json_str)
# 返回表单格式需要的字段
return {
"status": "success",
"hosts": data.get("hosts", ""),
"projects": data.get("projects", {}), # 保持为对象,用于调试
"projects_string": json.dumps(data.get("projects", {})), # 转换为 JSON 字符串用于表单提交
"scene": data.get("cache_key", "versions"),
"force_refresh": 'True'
}
except Exception as e:
print(f"JSON 解析错误: {e}")
pass
return {
"status": "error",
"hosts": "",
"projects": {},
"projects_string": "{}",
"scene": "versions",
"force_refresh": 'True'
}
HTTP请求
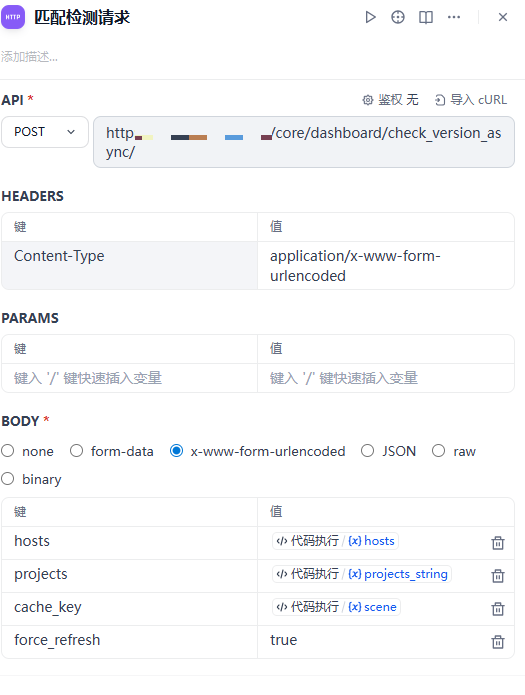
匹配检测请求
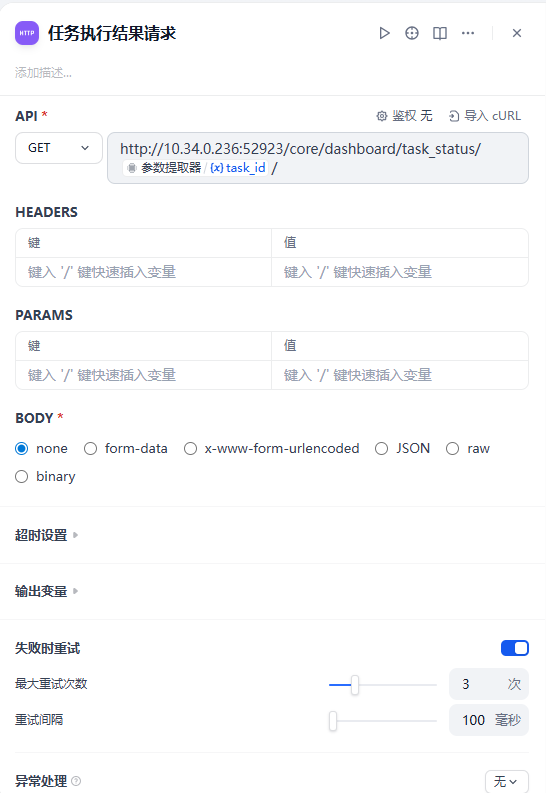
任务执行结果请求
匹配结果请求
也就是任务执行结果请求的再次请求一次确保获取任务执行结果。具体参考如上
参数提取
提取任务id
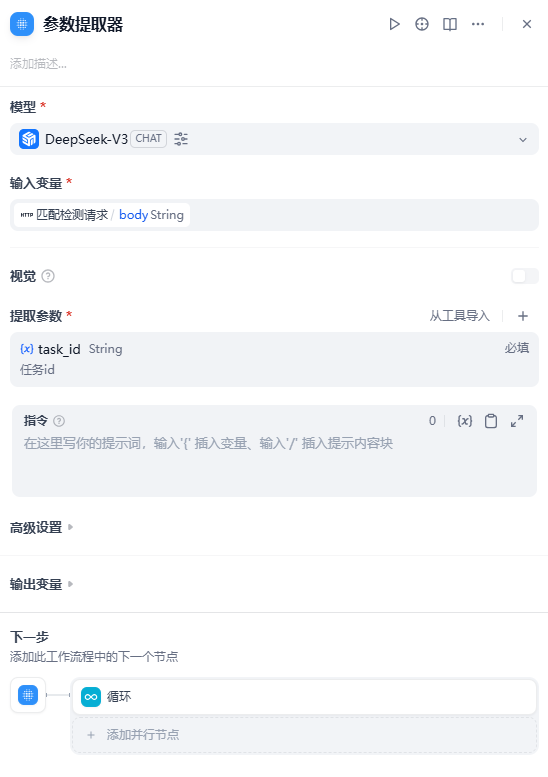
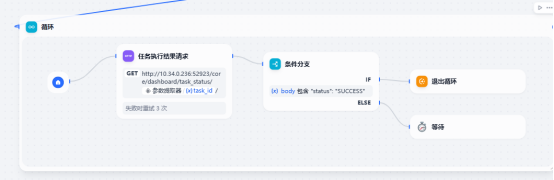
循环操作
如果任务状态包含status:SUCCESS则退出循环
运行效果
微服务

















 48
48

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









