






技术学习笔记01(乱七八糟版)
根据时间顺序记录自己在学习/实习过程中遇到的一些不明白的知识点。但是并只是通过浅显的文字说明解释了一下这些名词的大概意思,没有进行更加深入的了解和实战。
24.3.20
1. 架构
(1)架构分类:
① 业务架构
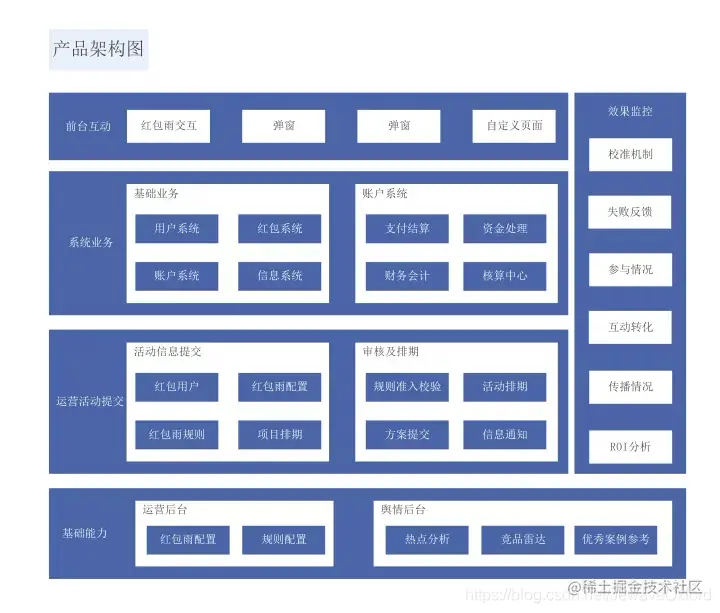
使用一套方法论或者逻辑对项目所涉及到的业务进行边界划分,业务架构的关键是熟悉业务
② 应用架构
对整个系统实现的总体架构,需要指出系统的层次,系统开发的原则,系统各个层次的应用服务
③ 数据架构
④ 技术架构
(2)项目架构设计
传送门:https://www.zhihu.com/question/340682578
① 项目开发整体的流程大致上是:需求评审、技术方案评审/项目排期、测试用例评审、开发、测试、功能预演、发布上线、线上灰度 / 放量。
② 项目整体前期设计:先理清业务核心实体/领域实体,根据核心实体确认模型,随之确定模型自身的行为以及模型之间的关系
③ 介绍整体业务流程可以使用时序图。
④ 数据模型使用ER图建立。
24.3.25
1. SaaS产品
SaaS,是Software-as-a-Service的缩写名称,意思为软件即服务,即通过网络提供软件服务。
SaaS平台供应商将应用软件统一部署在自己的服务器上,客户可以根据工作实际需求,通过互联网向厂商定购所需的应用软件服务,按定购的服务多少和时间长短向厂商支付费用,并通过互联网获得Saas平台供应商提供的服务。
总结一下 SaaS 产品的特点。
- 平台部署,不仅客户不需要购买软硬件设备,同时由平台方来维护。
- 选购灵活,客户根据服务项数和订购时长,可阶段性向厂商付费。
- 响应即时,SaaS 平台需要即时响应用户反馈,长期提供服务才能获得更多的收入。
如果一款产品同时满足上面的 3 个条件,那么这款产品就属于 SaaS 。
当然也有B端和C端不同的SaaS产品;也能分为业务SaaS产品和行业SaaS产品
- 业务 SaaS 产品,也叫通用型 SaaS 产品,即使跨行业但业务流程相似,比如爱客 CRM 、 金蝶 ERP、 Moka HRM 等。
- 行业 SaaS 产品具体聚焦于某个行业,不同行业的业务流程差别很大,比如教育行业的小鹅通、云朵课堂等。
2. 脏数据
脏数据是指从目标中取出来的已经过期、错误、或者没有意义的数据。在大数据时代,数据清洗是必要的,因为总是存在很多“脏数据”,也就是不完整、不规范、不准确的数据。数据清洗包括检查数据一致性,处理无效值和缺失值,从而提高数据质量。
24.3.26
1. 数据字典
学习链接:https://blog.csdn.net/qq_42320048/article/details/89252393
(1)数据字典分类
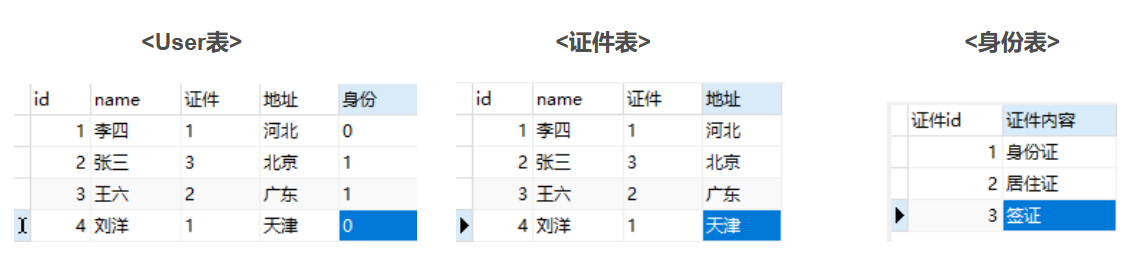
第一种:《主体表》里包含主体和属性代码,《属性表》里包含属性代码和属性Value,不同属性分别建表。
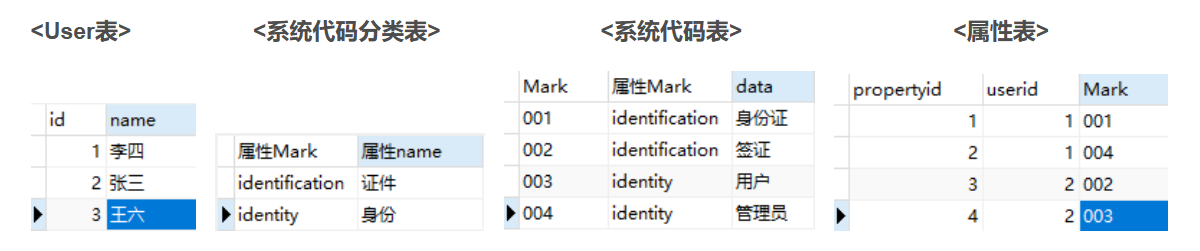
第二种:《主体表》里仅包含主体,《系统代码分类表》里存储属性标识和属性名称,《系统代码表》里包含所有属性代码、属性标识和属性Value,《属性表》是《主体》和《系统代码表》的关系表,包含属性id,主体id,属性代码。
(2)举例
第一种字典设计:
第二种字典设计:
两种设计方式分析:
1.第一种设计方式:由于属性id是存储在主体表里的,属性的数量是不变的,而属性取值的数量可以是变化的。但是如果该主体的属性非常多的话,就需要建很多的属性表,在开发中还要设计很多属性类,那当想要取得一条主体的完全数据时,那将进行几十个表的联接(join)操作。性能耗损严重。当属性的数量不多时,用第一种数据字典即可。
2.第二种设计方式:由于这种设计方式属性和主题表是分开的,所以属性的数量是可变的,而属性取值的数量可以是变化的。引入《系统代码分类表》和《系统代码表》,也解决了第一种设计方式的局限性。
24.4.10
1. 深拷贝和浅拷贝
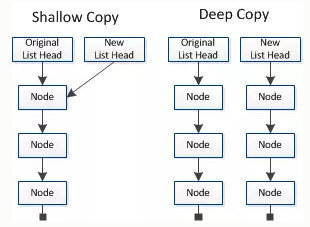
(1)浅拷贝
浅拷贝只复制指向某个对象的指针,而不复制对象本身,新旧对象还是共享同一块内存(分支)。
浅拷贝是按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。
如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。
(2)深拷贝
深拷贝会另外创造一个一模一样的对象,新对象跟原对象不共享内存,修改新对象不会改到原对象,是“值”而不是“引用”(不是分支)
- 拷贝第一层级的对象属性或数组元素
- 递归拷贝所有层级的对象属性和数组元素
- 深拷贝会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。
24.4.16
1. 回滚
(1)什么是事务回滚?
事务回滚是指将该事务已经完成对数据库的更新操作撤销,在事务中,每个正确的原子都会被顺序执行,直到遇到错误的原子操作。
(2)什么是回滚?
回滚是删除由一个或多个部分完成的事务执行的更新,为保证应用程序、数据库或系统错误后还原数据库的完整性,需要使用回滚。
回滚包括程序回滚和数据回滚等类型(泛指程序更新失败,返回上一次正确状态行为)
2. 客户端和服务端
客户端和服务端是两个相对的概念。客户端是用户直接使用的软件,例如手机上的APP或电脑上的软件。服务端是为客户端提供数据存储、数据处理等服务的程序,通常运行在服务器上。客户端和服务端的交互是通过网络协议(如HTTP)进行的。
例如,当您使用微信时,微信就是客户端,而微信服务器则是服务端。客户端发送请求到服务端,服务端处理请求并返回数据给客户端。
3. 缓存
缓存是一种用于提高应用程序性能的技术。通过将经常访问的数据存储在本地或离用户较近的服务器上,可以减少数据访问延迟并提高应用程序的响应速度。缓存可以位于多个位置,包括客户端、代理服务器和分布式缓存系统等。
例如,浏览器会缓存网页中的静态资源(如CSS、JavaScript文件),以便在用户再次访问该网页时加快加载速度。另外,分布式缓存系统(如Redis、Memcached等)可以用于存储数据库查询结果,减少对数据库的访问次数并提高整体性能。
24.4.22
1. 软删除
(1)硬删除
硬删除就是传统的物理删除,直接将该记录从数据库中删除。但是是人总会犯错误,在误操作删除了重要数据后,如果想要恢复该数据,需要锁表再去访问日志文件。这样会造成大量的人力资源浪费,现在的开发不推荐这种方式。
(2)软删除
软删除又叫逻辑删除,标记删除,与我们常说的删除不同,并不是真的从数据库中将这条记录去除,而是会设置一个字段,常见的有:isDelete或者state等字段来标记删除状态。当该字段为0的时候为未删除状态,为1时则是删除状态。
在现实情况中,很多时候我们说的删除并不是真的是删除的本意,因为站在用户的角度来看,并不是一种删除的状态:
订单不是被删除的,是被“取消”的。
员工不是被删除的,是被“解雇”的(也可能是退休或者暂时离职了)。
职位不是被删除的,是被“填补”的(或者招聘申请被撤回)。
所以这些时候,我们并不能真的把记录删除,所以软删除就出现了。
24.4.23
1. npm 和 cnpm
(1) 两者之间只是 node 中包管理器的不同,
(2) npm是node官方的包管理器。cnpm是个中国版的npm,是淘宝定制的 cnpm(gzip 压缩支持) 命令行工具代替默认的 npm:
(3)如果因为网络原因无法使用npm下载,那cnpm这个就派上用场了。
一定切记切记,npm和cnpm只是下载器的不同,好像npm用人力板车去拉包,而cnpm却使用货车去运包。 而存包的地址则在下文nrm的查看,















 507
507

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









