






问题:mmdetection训练中途中断
mmdetection 3.0.0
PyTorch 1.11.0
Python 3.8(ubuntu20.04)
Cuda 11.3解决办法:
打开./tools/train.py
看到'--resume'字段,'help'中写道:如果指定路径,那么恢复相应的模型;如果没有指定,那么默认恢复最新的模型。
因此,要从上次中断的位置或者用之前的模型训练,只需加上--resume字段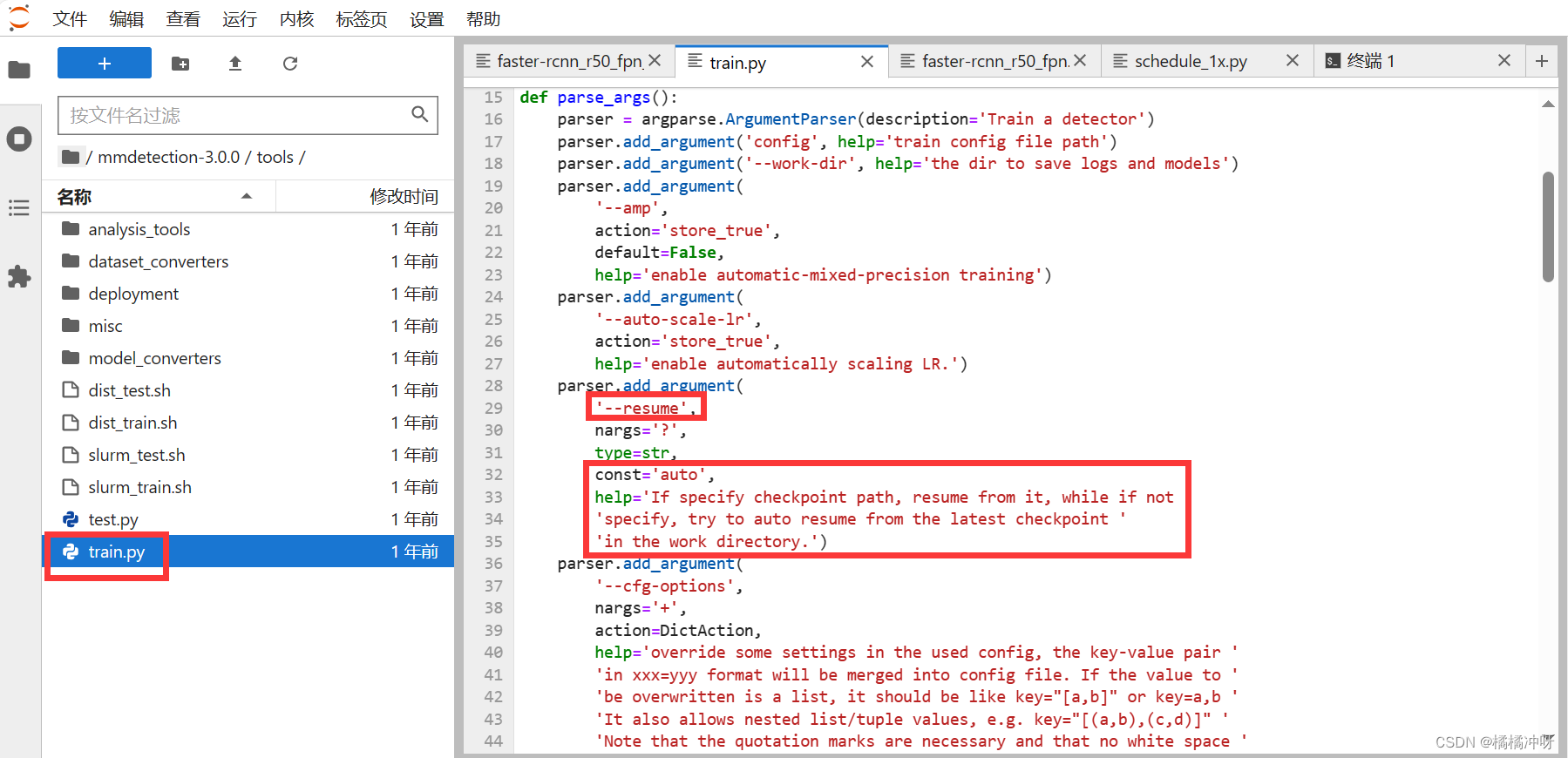
注:
①不同版本的mmdetection中,train.py中的各个字段名称可能不同,刚开始借鉴其他博客时直接按照其他博主的命令来,结果显示命令不存在。大家还是要打开自己的train文件,查看自己版本的具体命令!
②以下命令中相应的文件目录和文件名换成自己的哦!
1、指定路径,那么恢复相应的模型
python ./tools/train.py ./configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py --resume ./work_dirs/faster-rcnn_r50_fpn_1x_coco/epoch_12.pth或者
python ./tools/train.py ./work_dirs/faster-rcnn_r50_fpn_1x_coco/faster-rcnn_r50_fpn_1x_coco.py --resume ./work_dirs/faster-rcnn_r50_fpn_1x_coco/epoch_12.pth2、不指定路径,默认恢复最新的模型。不过如果最新的pth文件不小心被删了或者正好没有保存这个模型文件,那就可能会报错。比如如果之前训练后最新的pth是第11个epoch的,但是不小心把epoch_11.pth删了,程序默认找epoch_11.pth,那就找不到这个模型文件了,就会报错。
python ./tools/train.py ./configs/faster_rcnn/faster-rcnn_r50_fpn_1x_coco.py --resume或者
python ./tools/train.py ./work_dirs/faster-rcnn_r50_fpn_1x_coco/faster-rcnn_r50_fpn_1x_coco.py --resume注:对于上述指定/不指定路径来说,都有两种命令可供选择,它们的不同在于使用的模型总配置py文件来自于config文件夹还是work_dirs文件夹。前者是mmdetection自带的,后者是在最初运行后生成的配置文件,保存在work_dirs/...里。
最初用系统提供的模型来训练的命令如下:可以看到第二个py文件是configs/...目录里的
python ./tools/train.py ./configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py好啦,到此问题就解决啦!可以继续训练模型啦!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









