







 本文详细介绍了如何在MMDetection3.0.0版本中上传COCO数据集,修改配置文件(包括模型、数据集、训练计划),以及进行模型训练,包括查看训练结果和保存模型的过程。
本文详细介绍了如何在MMDetection3.0.0版本中上传COCO数据集,修改配置文件(包括模型、数据集、训练计划),以及进行模型训练,包括查看训练结果和保存模型的过程。
MMDetection版本 3.0.01、上传COCO数据集
数据集放在mmdetection-3.0.0/data/coco下
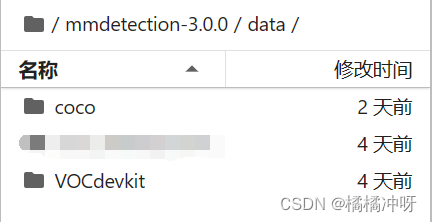
mmdetection-3.0.0/data/coco下的文件组织如下图,annotations存放json文件,test2017、train2017、train2017下分别存放图片,png或jpg格式都可以
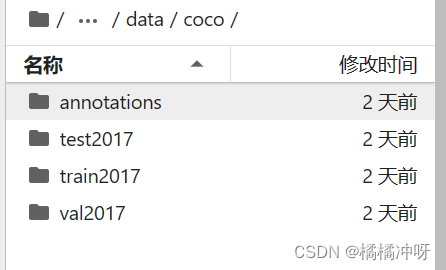
mmdetection-3.0.0/data/coco/annotations下的文件组织如下图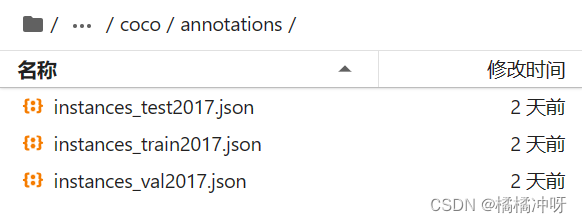
注:以上的文件命名都可以根据自己的喜好重新命名,不过会需要修改配置文件,接下来会详细介绍
2、修改配置文件
(1)打开mmdetection/configs,选择自己想要的模型总配置文件,比如我这里选择的./config/retinanet/retinanet_r50_f
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2174
2174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









