






题目:请编写一个爬虫程序,爬取https://www.zhihu.com/knowledge-plan/hot-question/hot/0/hour页面中所有的问题、热力值、关注增量、浏览增量、回答增量和赞同增量等数据,并选取其中一个问题,点击该问题的“写回答”按钮。
在这里咋们打开这个网址想要获取静态数据的话,点击审查元素咋们会发现 这些数据是看不到的,很有可能是动态数据,所以咋们从页面中下手看JSON问文件里的数据.

我们看到这些数据都是在网址页面上的数据,进入写代码环节。
import requests
# 指定API URL
url = 'https://www.zhihu.com/api/v4/creators/rank/hot?domain=0&period=hour'
# 发送GET请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 解析JSON数据
data = response.json()
# 遍历问题列表
for question in data['data']:
# 提取问题标题、新浏览量、总浏览量、关注者数量、回答数量、新增赞同数
title = question['question']['title']
new_pv = question['reaction']['new_pv']
total_pv = question['reaction']['pv']
followers = question['reaction']['follow_num']
answers = question['reaction']['answer_num']
upvotes = question['reaction']['new_upvote_num']
# 提取得分并保留三位小数
score = round(question['reaction']['score'], 1)
# 打印数据
print(f"问题标题: {title}")
print(f"新浏览量: {new_pv}")
print(f"总浏览量: {total_pv}")
print(f"关注者数量: {followers}")
print(f"回答数量: {answers}")
print(f"新增赞同数: {upvotes}")
print(f"热力值: {score}分") # 打印格式化后的得分
print("-" * 50) # 打印分隔线
else:
print("请求失败,状态码:", response.status_code)以上是获取页面中的数据,第二部是让代码自动化打开网址按写回答的按钮,在这我用到了x轴和y轴 ,学过前端的都知道有些网页上东西是可以用x轴和y轴写的,我想了想 python也可以用这个来弄一个自动化,这个需要大家自行调节x,y 轴的值 以下是完整版的代码 。
import requests
import pyautogui
import time
# 从知乎获取当前热门问题
# 获取知乎热门问题数据
def fetch_zhihu_hot_questions():
# 定义请求URL
url = 'https://www.zhihu.com/api/v4/creators/rank/hot?domain=0&period=hour'
# 发送GET请求
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
# 解析JSON响应
data = response.json()
# 遍历每个问题
for question in data['data']:
# 提取问题相关信息
title = question['question']['title']
new_pv = question['reaction']['new_pv']
total_pv = question['reaction']['pv']
followers = question['reaction']['follow_num']
answers = question['reaction']['answer_num']
upvotes = question['reaction']['new_upvote_num']
score = round(question['reaction']['score'], 1)
# 打印问题详情
print(f"问题标题: {title}")
print(f"新浏览量: {new_pv}")
print(f"总浏览量: {total_pv}")
print(f"关注者数量: {followers}")
print(f"回答数量: {answers}")
print(f"新增赞同数: {upvotes}")
print(f"热力值: {score}分")
print("-" * 50)
else:
# 请求失败时打印状态码
print("请求失败,状态码:", response.status_code)
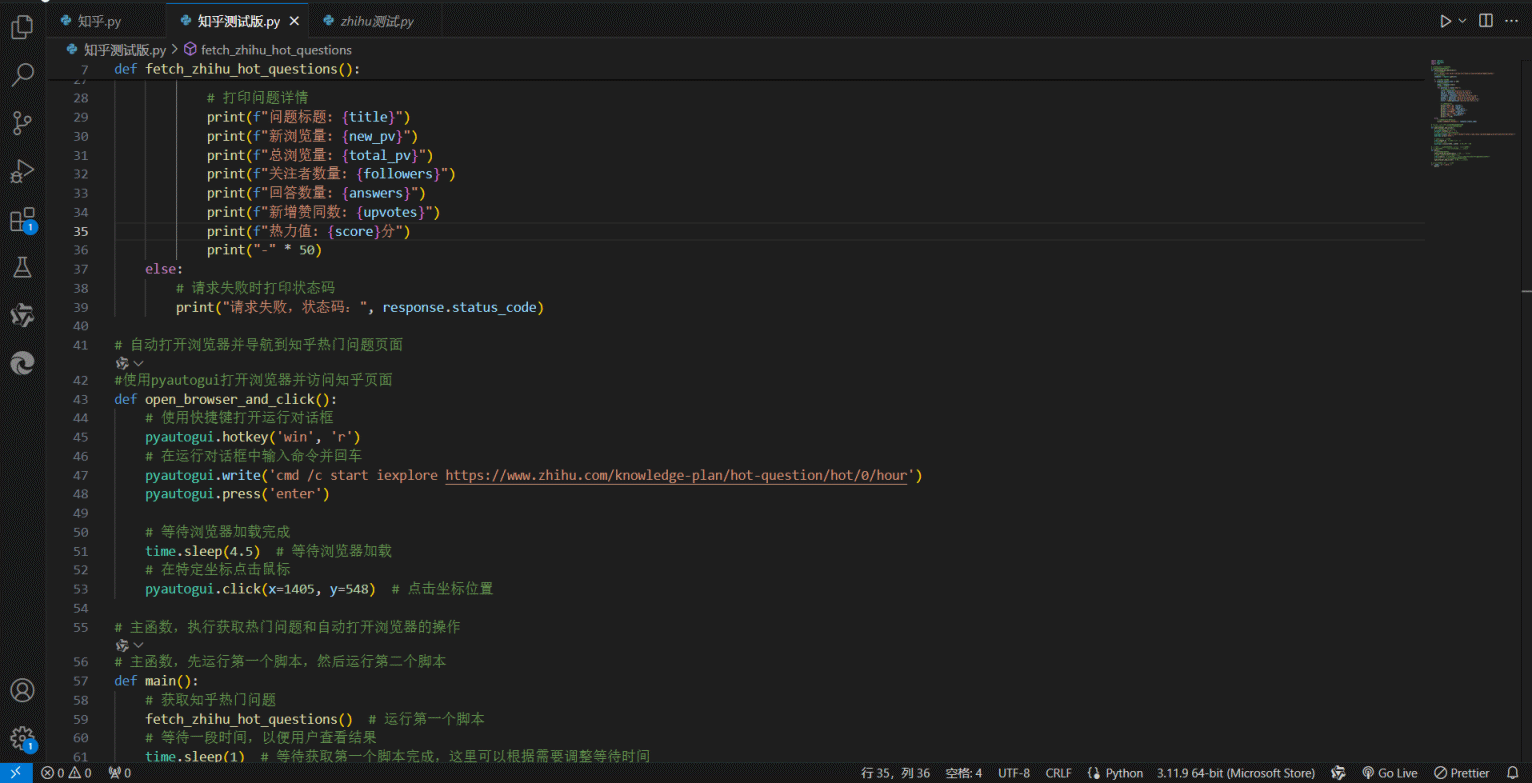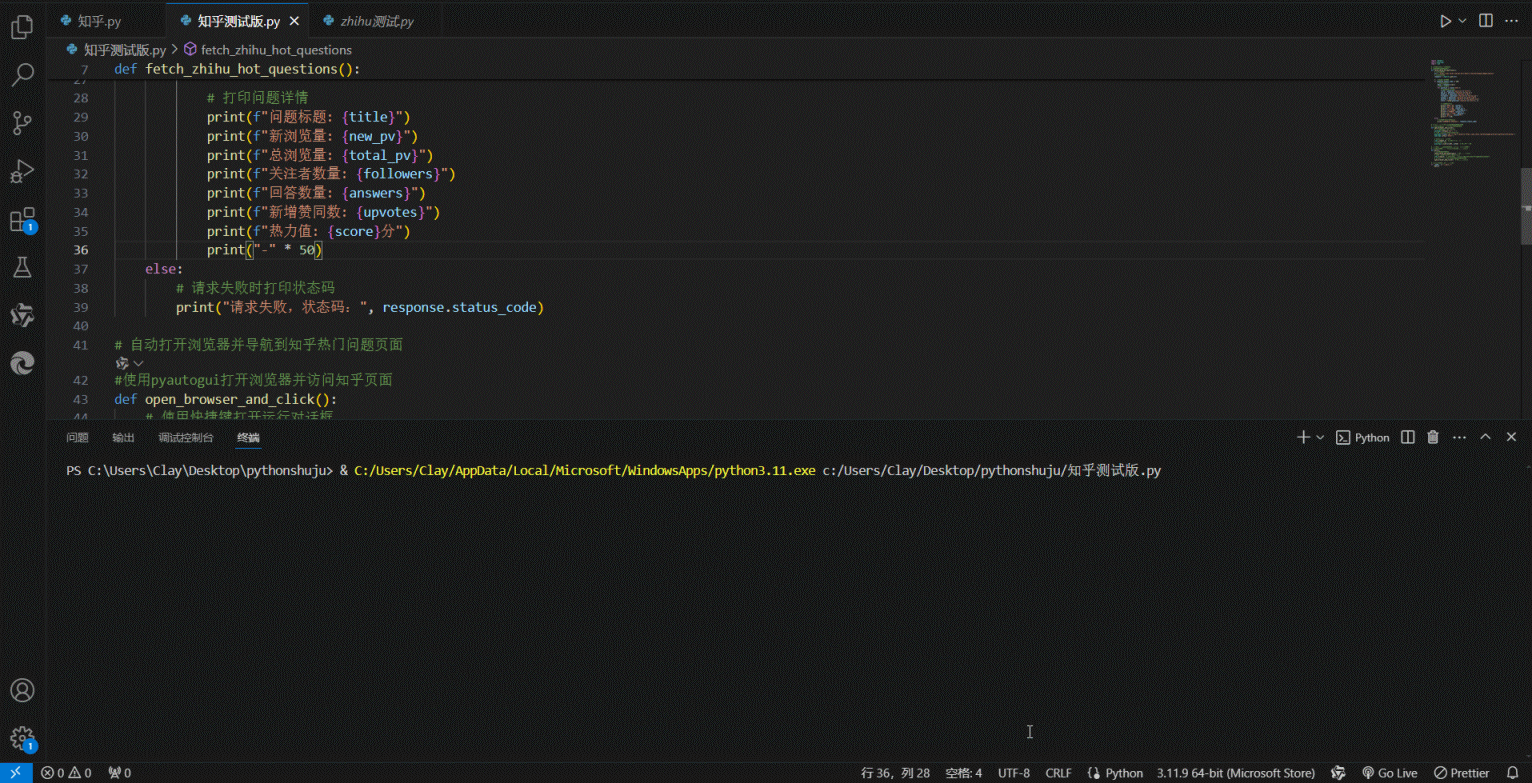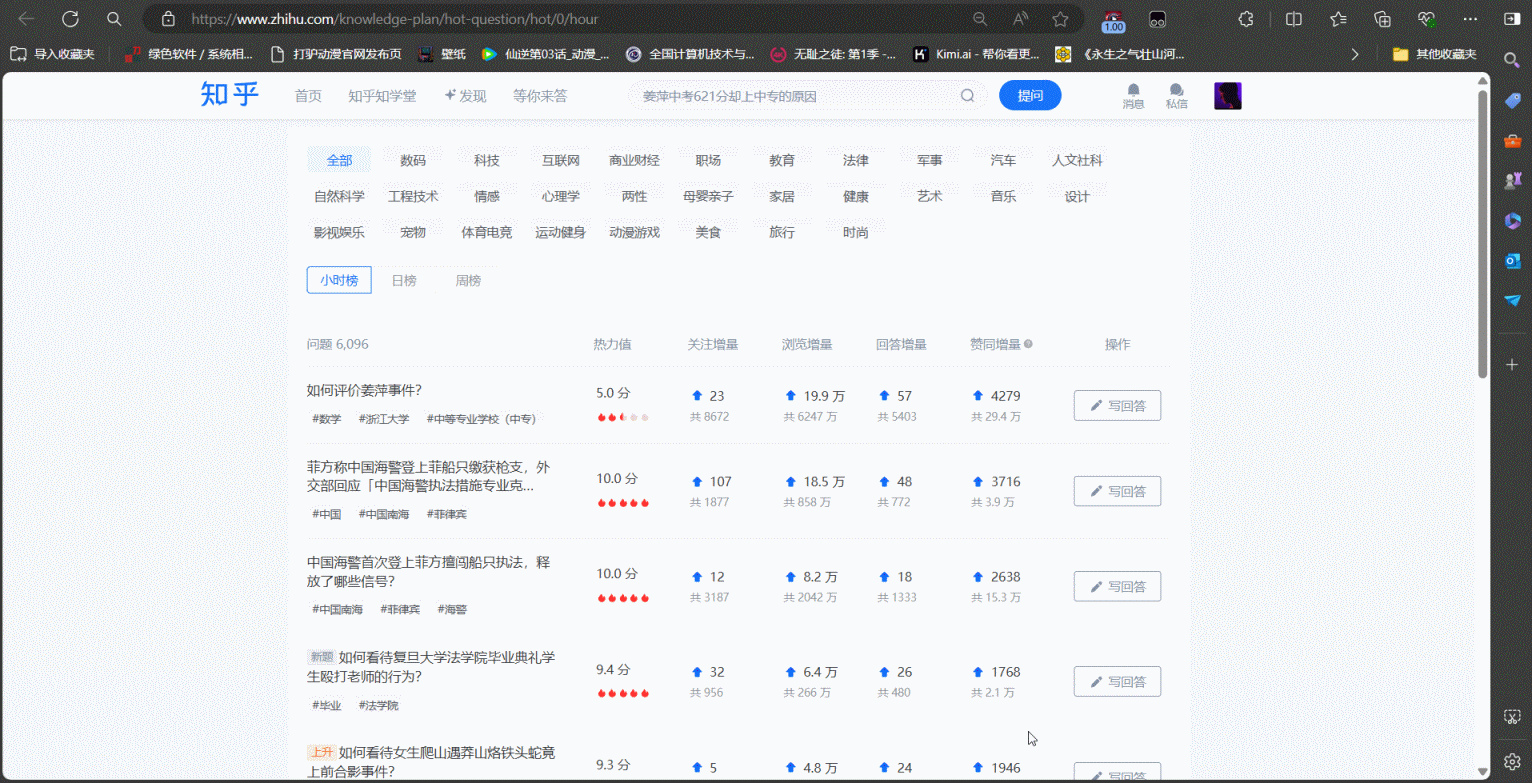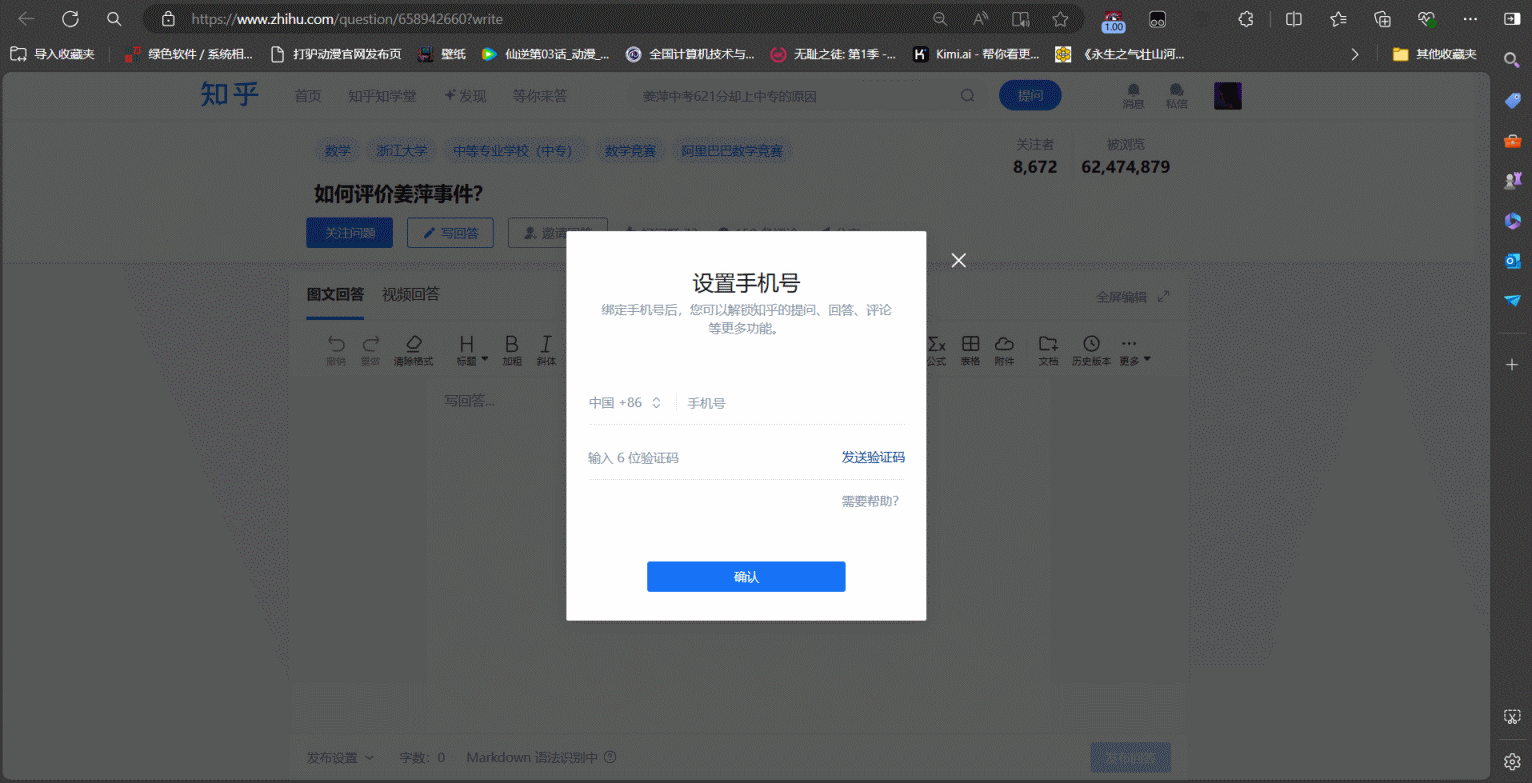
# 自动打开浏览器并导航到知乎热门问题页面
#使用pyautogui打开浏览器并访问知乎页面
def open_browser_and_click():
# 使用快捷键打开运行对话框
pyautogui.hotkey('win', 'r')
# 在运行对话框中输入命令并回车
pyautogui.write('cmd /c start iexplore https://www.zhihu.com/knowledge-plan/hot-question/hot/0/hour')
pyautogui.press('enter')
# 等待浏览器加载完成
time.sleep(4.5) # 等待浏览器加载
# 在特定坐标点击鼠标
pyautogui.click(x=1405, y=548) # 点击坐标位置
先运行第一个脚本,然后运行第二个脚本
def main():
# 获取知乎热门问题
fetch_zhihu_hot_questions() # 运行第一个脚本
# 等待一段时间,以便用户查看结果
time.sleep(1) # 等待获取第一个脚本完成,这里可以根据需要调整等待时间
# 自动打开浏览器并导航到知乎热门问题页面
open_browser_and_click() # 运行第二个脚本
# 当脚本直接运行时执行主函数
if __name__ == "__main__":
main()我在注释里写的很清楚一看便能知道 ,这个是模拟打开win+R 然后输入网址便能打开网址,这运行过程中尽量不要动鼠标。
运行的时候记得把输入法改成英文小写【演示】















 4250
4250











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









