






一、实验目的
(1)理解Hive作为数据仓库在Hadoop体系结构中的角色。
(2)熟练使用常用的HiveQL。
二、实验平台
操作系统:Ubuntu18.04(或Ubuntu16.04)。
Hadoop版本:3.1.3。
Hive版本:3.1.2。
JDK版本:1.8。
三、实验过程、内容
(一)安装Hive
$ sudo tar -zxvf ~/下载/apache-hive-3.1.2-bin.tar.gz -C /usr/local # 解压到/usr/local中
$ cd /usr/local/
$ sudo mv apache-hive-3.1.2-bin hive # 将文件夹名改为hive
$ sudo chown -R hadoop:hadoop hive # 修改文件权限
1.把hive命令加入到环境变量PATH中
$ vim ~/.bashrc
在该文件前面添加如下内容:
export HIVE_HOME=/usr/local/hive
export PATH=$PATH:$HIVE_HOME/bin
2.保存该文件并退出vim编辑器,然后,运行如下命令使得配置立即生效:
$ source ~/.bashrc
将“/usr/local/hive/conf”目录下的hive-default.xml.template文件重命名为hive-default.xml,命令如下:
$ cd /usr/local/hive/conf
$ sudo mv hive-default.xml.template hive-default.xml
3.同时,使用vim编辑器新建一个文件hive-site.xml,命令如下:
$ cd /usr/local/hive/conf
$ vim hive-site.xml
在hive-site.xml中输入如下配置信息:
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
</configuration>4.下载MySQL JDBC驱动程序
$ cd ~/下载
$ tar -zxvf mysql-connector-java-5.1.40.tar.gz #解压
$ #下面将mysql-connector-java-5.1.40-bin.jar拷贝到/usr/local/hive/lib目录下
$ cp mysql-connector-java-5.1.40/mysql-connector-java-5.1.40-bin.jar /usr/local/hive/lib
5.启动MySQL,执行如下命令启动MySQL,并进入“mysql>”命令提示符状态:
$ service mysql start #启动MySQL服务
$ mysql -u root -p #登录MySQL数据库
6.在MySQL中为Hive新建数据库
mysql> create database hive;
需要对MySQL进行权限配置,允许Hive连接到MySQL。
mysql> grant all on *.* to hive@localhost identified by 'hive';
mysql> flush privileges;
7. 启动Hive
$ cd /usr/local/hadoop
$ ./sbin/start-dfs.sh
$ cd /usr/local/hive
$ ./bin/hive
五、实验结果(运行结果截图)
进入你的 Downloads(下载)文件夹,右键解压刚下载的数据压缩包,进入 prog-hive-1st-ed-data 文件夹,右键打开终端:
cd ~/下载/prog-hive-1st-ed-data
sudo cp ./data/stocks/stocks.csv /usr/local/hive
sudo cp ./data/dividends/dividends.csv /usr/local/hive
进入 Hadoop 目录,启动 Hadoop:
cd /usr/local/hadoop
sbin/start-dfs.sh
启动 MySQL:
service mysql start
切换到 Hive 目录下,启动 MySQL 和 Hive:
cd /usr/local/hive
bin/hive
(1)创建一个内部表stocks,字段分隔符为英文逗号,表结构如表14-11所示。
表14-11 stocks表结构
| col_name | data_type |
| exchange | string |
| symbol | string |
| ymd | string |
| price_open | float |
| price_high | float |
| price_low | float |
| price_close | float |
| volume | int |
| price_adj_close | float |
create table if not exists stocks(
`exchange` string,
`symbol` string,
`ymd` string,
`price_open` float,
`price_high` float,
`price_low` float,
`price_close` float,
`volume` int,
`price_adj_close` float
)row format delimited fields terminated by ',';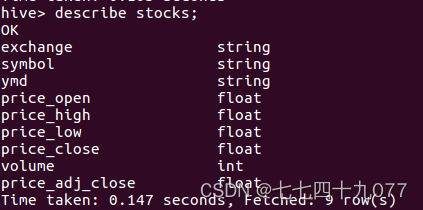
(2)创建一个外部分区表dividends(分区字段为exchange和symbol),字段分隔符为英文逗号,表结构如表14-12所示。
表14-12 dividends表结构
| col_name | data_type |
| ymd | string |
| dividend | float |
| exchange | string |
| symbol | string |
create external table if not exists dividends
(
`ymd` string,
`dividend` float
)
partitioned by(`exchange` string ,`symbol` string)
row format delimited fields terminated by ',';
(3)从stocks.csv文件向stocks表中导入数据。
load data local inpath '/usr/local/hive/stocks.csv' overwrite into table stocks;

(4) 创建一个未分区的外部表dividends_unpartitioned,并从dividends.csv向其中导入数据,表结构如表14-13所示。
表14-13 dividends_unpartitioned表结构
| col_name | data_type |
| ymd | string |
| dividend | float |
| exchange | string |
| symbol | string |
create external table if not exists dividends_unpartitioned
(
`exchange` string ,
`symbol` string,
`ymd` string,
`dividend` float
)
row format delimited fields terminated by ',';
load data local inpath '/usr/local/hive/dividends.csv' overwrite into table dividends_unpartitioned;
(4)通过对dividends_unpartitioned的查询语句,利用Hive自动分区特性向分区表dividends各个分区中插入对应数据。
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;
insert overwrite table dividends partition(`exchange`,`symbol`) select `ymd`,`dividend`,`exchange`,`symbol` from dividends_unpartitioned;(6)查询IBM公司(symbol=IBM)从2000年起所有支付股息的交易日(dividends表中有对应记录)的收盘价(price_close)。
select s.ymd,s.symbol,s.price_close
from stocks s
LEFT SEMI JOIN
dividends d
ON s.ymd=d.ymd and s.symbol=d.symbol
where s.symbol='IBM' and year(ymd)>=2000;
(7)查询苹果公司(symbol=AAPL)2008年10月每个交易日的涨跌情况,涨显示rise,跌显示fall,不变显示unchange。
select ymd,
case
when price_close-price_open>0 then 'rise'
when price_close-price_open<0 then 'fall'
else 'unchanged'
end as situation
from stocks
where symbol='AAPL' and substring(ymd,0,7)='2008-10';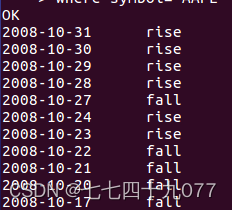
(8)查询stocks表中收盘价(price_close)比开盘价(price_open)高得最多的那条记录的交易所(exchange)、股票代码(symbol)、日期(ymd)、收盘价、开盘价及二者差价。
select `exchange`,`symbol`,`ymd`,price_close,price_open,price_close-price_open as `diff`
from
(
select *
from stocks
order by price_close-price_open desc
limit 1
)t;
(9)从stocks表中查询苹果公司(symbol=AAPL)年平均调整后收盘价(price_adj_close) 大于50美元的年份及年平均调整后收盘价。
select
year(ymd) as `year`,
avg(price_adj_close) as avg_price from stocks
where `exchange`='NASDAQ' and symbol='AAPL'
group by year(ymd)
having avg_price > 50;
查询每年年平均调整后收盘价(price_adj_close)前三名的公司的股票代码及年平均调整后收盘价。
select t2.`year`,symbol,t2.avg_price
from
(
select
*,row_number() over(partition by t1.`year` order by t1.avg_price desc) as `rank`
from
(
select
year(ymd) as `year`,
symbol,
avg(price_adj_close) as avg_price
from stocks
group by year(ymd),symbol
)t1
)t2
where t2.`rank`<=3;
四、实验心得和总结
- (列出遇到的问题和解决办法,列出没有解决的问题,可以是个人相关知识点总结,要求150字以上)
问题一:启动hive时(./bin/hive)
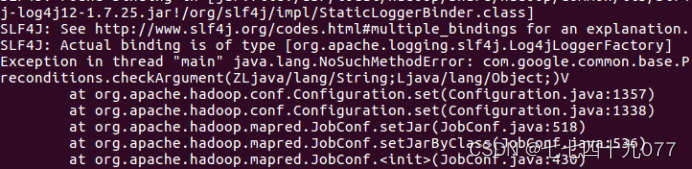
解决方案:
一般是Hadoop中的guava的相关jar包与hive中的不适配,将hive中的删除,然后Hadoop中的guava-27.0-jre.jar,复制到hive里面就可以了,操作如下:
$cd /usr/local/hadoop/share/hadoop/common/lib
$rm guava-40.jar
$cd /usr/local/hadoop/share/hadoop/common/lib
$ cp -r guava-27.0-jre.jar /usr/local/hive/lib
问题二:在hive中在确保命令语句正确的前提下,创建数据库报错

解决办法:手动初始化元数据库
$cd /usr/local/hadoop/share/hadoop/common/lib
$bin/schematool -dbType mysql -initSchema
















 3641
3641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









