






大数据基础编程、实验和教程案例(实验六)
14.6 实验六 熟悉 Hive 的基本操作
本实验对应第 8 章的内容。
14.6.1 实验目的
(1)理解 Hive 作为数据仓库在 Hadoop 体系结构中的角色。
(2)熟练使用常用的 HiveQL。
14.6.2 实验平台
| 操作系统 | Linux |
|---|---|
| Hadoop 版本 | 3.1.3 |
| Hive 版本 | 3.1.2 |
| JDK 版本 | 1.8 |
14.6.3 数据集
由《Hive 编程指南》(O’Reilly 系列,人民邮电出版社)提供,下载地址:
https://raw.githubusercontent.com/oreillymedia/programming_hive/master/prog-hive-1sted-data.zip
备用下载地址:
https://www.cocobolo.top/FileServer/prog-hive-1st-ed-data.zip
解压后可以得到本实验所需的 stocks.csv 和 dividends.csv 两个文件。
14.6.4 实验步骤
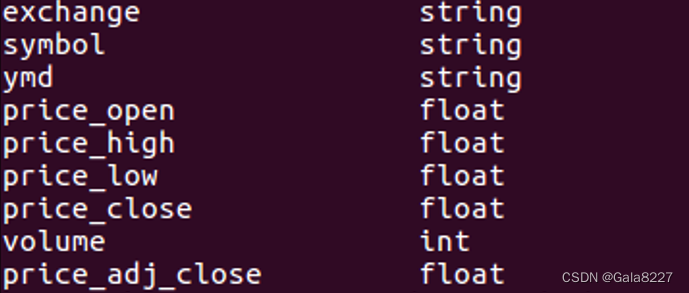
(1)创建一个内部表 stocks,字段分隔符为英文逗号
create table if not exists stocks
(
`exchange` string,
`symbol` string,
`ymd` string,
`price_open` float,
`price_high` float,
`price_low` float,
`price_close` float,
`volume` int,
`price_adj_close` float
)
row format delimited fields terminated by ',';
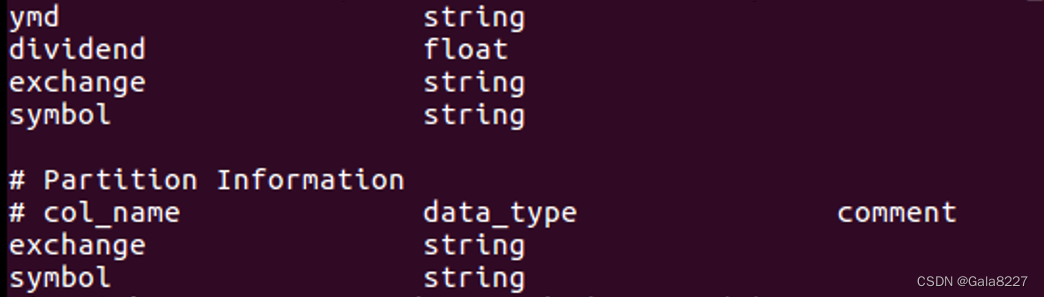
(2)创建一个外部分区表 dividends(分区字段为 exchange 和 symbol),字段分隔符为英文逗号,表结构如表 A-7 所示。
create external table if not exists dividends
(
`ymd` string,
`dividend` float
)
partitioned by(`exchange` string ,`symbol` string)
row format delimited fields terminated by ',';
(3)从 stocks.csv 文件向 stocks 表中导入数据。
load data local inpath '/home/hadoop/data/stocks/stocks.csv' overwrite into table stocks;
(4) 创建一个未分区的外部表 dividends_unpartitioned,并从 dividends.csv 向其中导入数据
create external table if not exists dividends_unpartitioned
(
`exchange` string ,
`symbol` string,
`ymd` string,
`dividend` float
)
row format delimited fields terminated by ',';
load data local inpath '/home/hadoop/data/dividends/dividends.csv'
overwrite into table dividends_unpartitioned;
(5)通过对 dividends_unpartitioned 的查询语句,利用 Hive 自动分区特性向分区表 dividends各个分区中插入对应数据。
set hive.exec.dynamic.partition=true;
set hive.exec.dynamic.partition.mode=nonstrict;
set hive.exec.max.dynamic.partitions.pernode=1000;
insert overwrite table dividends partition(`exchange`,`symbol`) select
`ymd`,`dividend`,`exchange`,`symbol` from dividends_unpartitioned;
(6)查询 IBM 公司(symbol=IBM)从 2000 年起所有支付股息的交易日(dividends 表中有对应记录)的收盘价(price_close)。
select s.ymd,s.symbol,s.price_close
from stocks s
LEFT SEMI JOIN
dividends d
ON s.ymd=d.ymd and s.symbol=d.symbol
where s.symbol='IBM' and year(ymd)>=2000;
(7)查询苹果公司(symbol=AAPL)2008 年 10 月每个交易日的涨跌情况,涨显示 rise,跌显示 fall,不变显示 unchange。
select ymd,
case
when price_close-price_open>0 then 'rise'
when price_close-price_open<0 then 'fall'
else 'unchanged'
end as situation
from stocks
where symbol='AAPL' and substring(ymd,0,7)='2008-10';
(8)查询 stocks 表中收盘价(price_close)比开盘价(price_open)高得最多的那条记录的交易所(exchange)、股票代码(symbol)、日期(ymd)、收盘价、开盘价及二者差价。
select `exchange`,symbol,ymd,price_close-price_open as `diff`
from
(
select *
from stocks
order by price_close-price_open desc
limit 1
)t;
(9)从 stocks 表中查询苹果公司(symbol=AAPL)年平均调整后收盘价(price_adj_close) 大于 50 美元的年份及年平均调整后收盘价。
select
year(ymd) as `year`,
avg(price_adj_close) as avg_price from stocks
where `exchange`='NASDAQ' and symbol='AAPL'
group by year(ymd)
having avg_price > 50;
(10)查询每年年平均调整后收盘价(price_adj_close)前三名的公司的股票代码及年平均调整后收盘价。
select t2.`year`,symbol,t2.avg_price
from
(
select
*,row_number() over(partition by t1.`year` order by t1.avg_price
desc) as `rank`
from
(
select
year(ymd) as `year`,
symbol,
avg(price_adj_close) as avg_price
from stocks
group by year(ymd),symbol
)t1
)t2
where t2.`rank`<=3;














 317
317











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









