







目录
一、找到K个最接近的元素
力扣第658题

本题采用二分查找和双指针的方法解决
1.1 具体思路
分两个主要步骤进行
(1)二分查找找到最接近 x 的数的索引:
我们首先定义一个辅助函数 binarySearch,用来找到最接近 x 的数的索引。二分查找的过程是:如果中间元素比 x 大,则索引向左移动;如果中间元素比 x 小,则索引向右移动;如果中间元素等于 x,则直接返回索引。
(2)使用双指针从这个索引开始,向两边扩展,选择最接近 x 的 k 个数:
当找到最接近 x 的数的索引后,我们使用双指针从该位置开始,向两边扩展以选择最接近 x 的 k 个数。具体过程是:根据绝对值大小比较,不断向两侧移动指针,直到找到 k 个最接近 x 的数。
1.2 思路展示
原始数组: [1, 2, 3, 4, 5, 6, 7, 8, 9]
目标数 x: 5
要选择的最接近 x 的 k 个数: 3
(1)使用二分查找找到最接近 x 的数的索引,即 5 的索引为 4 (中间值)
[1, 2, 3, 4, 5, 6, 7, 8, 9]
^
|
index = 4
(2) 使用双指针从索引 4 开始,向两边扩展,选择最接近 x 的 3 个数。
- 初始化左指针为索引 4,右指针为索引 4
- 进行迭代,并根据绝对值大小比较移动指针:
- 比较 arr[3] 和 arr[5] 的绝对值大小:
abs(4 - 5) <= abs(6 - 5) => True
左指针左移一位
- 比较 arr[2] 和 arr[5] 的绝对值大小:
abs(3 - 5) <= abs(6 - 5) => True
左指针左移一位
- 比较 arr[1] 和 arr[5] 的绝对值大小:
abs(2 - 5) <= abs(6 - 5) => True
左指针左移一位
- 此时左指针移动到索引 1,右指针仍然为索引 4,选择的最接近 x 的 3 个数为 [2, 3, 4]
1.3 代码实现
def findClosestElements(arr, k, x):
def binarySearch(arr, x):
left, right = 0, len(arr) - 1
while left < right:
mid = (left + right) // 2
if arr[mid] < x:
left = mid + 1
else:
right = mid
return left
left = binarySearch(arr, x)
right = left
while right - left < k:
if left == 0:
right += 1
elif right == len(arr):
left -= 1
elif abs(arr[left - 1] - x) <= abs(arr[right] - x):
left -= 1
else:
right += 1
return arr[left:right]
# 测试用例 1
arr1 = [1, 2, 3, 4, 5]
k1 = 4
x1 = 3
print(findClosestElements(arr1, k1, x1)) # 应输出 [1, 2, 3, 4]
# 测试用例 2
arr2 = [1, 2, 3, 4, 5]
k2 = 4
x2 = -1
print(findClosestElements(arr2, k2, x2)) # 应输出 [1, 2, 3, 4]
# 其他测试用例
arr3 = [1, 3, 5, 7, 9]
k3 = 3
x3 = 6
print(findClosestElements(arr3, k3, x3))
arr4 = [2, 4, 6, 8, 10]
k4 = 1
x4 = 7
print(findClosestElements(arr4, k4, x4)) 1.4 复杂度分析
以上代码实现了一个找到最接近 x 的 k 个数的函数。在这个函数中,首先使用二分查找找到最接近 x 的数的索引,然后使用双指针从该位置开始,向两边扩展,选择最接近 x 的 k 个数。下面是对该函数的复杂度分析:
二分查找部分的时间复杂度为 O(logn),其中 n 是数组 arr 的长度。
在找到最接近 x 的数的索引之后,双指针向两边扩展的过程中,最坏情况下需要移动 k 步,因此时间复杂度为 O(k)。
因此,该函数的总时间复杂度为 O(logn + k)。
空间复杂度上,除了输入参数外,算法中没有使用额外的数据结构,因此空间复杂度为 O(1)。
综合来看,该函数在时间复杂度上表现良好,只需要 O(logn + k) 的时间复杂度,适用于大多数规模的输入。
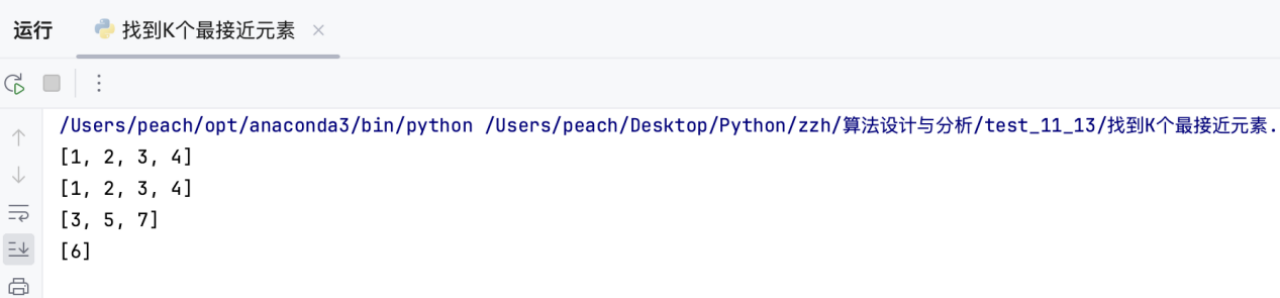
1.5 运行结果
结果均与预期结果一致
二、前K个高频元素
力扣第347题

2.1 思路一:哈希表
(1)具体思路
此处我尝试使用哈希表来统计每个元素出现的频率,并根据频率来找出前 k 高的元素。具体思路如下:
遍历数组 nums,使用哈希表 freq_map 统计每个元素的出现频率。
构建一个桶 bucket,桶的索引表示元素的出现频率,桶中存储具有相同频率的元素。
遍历哈希表 freq_map,将每个元素放入对应频率的桶中。
从桶的末尾开始遍历,取出前 k 个高频元素。
(2)思路展示
给定nums = [1, 1, 1, 2, 2, 3]
k = 2
① 统计频率:
freq_map = {1: 3, 2: 2, 3: 1}
②构建桶(以频率为索引):
bucket = [
[], # 索引为0的桶为空
[3], # 索引为1的桶中有元素3
[1, 2], # 索引为2的桶中有元素1和2
[] # 索引为3的桶为空
]
③取出前 k 个高频元素:
result = []
从桶的末尾开始遍历:
- 桶索引3为空,跳过
- 桶索引2中有元素1和2,加入result并更新k
- 桶索引1中有元素3,加入result并更新k
得到 result = [1, 2]
(3)代码实现
def topKFrequent(nums, k):
freq_map = {}
for num in nums:
if num in freq_map:
freq_map[num] += 1
else:
freq_map[num] = 1
max_freq = max(freq_map.values())
bucket = [[] for _ in range(max_freq + 1)]
for num, freq in freq_map.items():
bucket[freq].append(num)
result = []
for i in range(max_freq, 0, -1):
if k > 0 and bucket[i]:
result.extend(bucket[i])
k -= len(bucket[i])
if k <= 0:
break
return result[:k]
# 示例 1
nums1 = [1, 1, 1, 2, 2, 3]
k1 = 2
print(topKFrequent(nums1, k1)) # 输出: [1, 2]
# 示例 2
nums2 = [1]
k2 = 1
print(topKFrequent(nums2, k2)) # 输出: [1](4)复杂度分析
创建频率哈希表:遍历整个数组 nums 需要 O(n) 的时间,其中 n 是数组的长度。
创建桶和将数字放入桶中:同样需要 O(n) 的时间。
构建结果列表:对于最坏情况下的循环次数是频率的最大值,即 max_freq,所以需要 O(max_freq) 的时间。
返回结果列表的前 k 个元素:这一步最多需要 O(k) 的时间。
因此,总体时间复杂度为 O(n + max_freq + k),其中 n 是数组的长度,max_freq 表示数组中元素的最大频率。在最坏情况下,max_freq 会达到 n,此时时间复杂度为 O(n)。
空间复杂度主要取决于频率哈希表和桶的使用,因此为 O(n + max_freq)。
2.2 思路二:快速选择
(1)具体思路
首先,我们需要实现一个快速选择算法的辅助函数 partition(),用于划分数组。
在 partition() 函数中,我们选择一个枢纽元素(pivot),并将数组划分为两部分:小于等于枢纽元素的元素放在左边,大于枢纽元素的元素放在右边。同时,记录枢纽元素的位置。
如果枢纽元素的位置恰好为 k-1,那么枢纽元素就是第 k 高的元素,返回它。
如果枢纽元素的位置小于 k-1,说明第 k 高的元素在右边的子数组中,我们递归地在右边子数组中查找第 k-1 - pivot_index 高的元素。
如果枢纽元素的位置大于 k-1,说明第 k 高的元素在左边的子数组中,我们递归地在左边子数组中查找第 k 高的元素。
(2)代码实现
import random
def topKFrequent(nums, k):
freq_map = {}
for num in nums:
if num in freq_map:
freq_map[num] += 1
else:
freq_map[num] = 1
unique_nums = list(freq_map.keys())
def partition(left, right, pivot_index):
pivot_frequency = freq_map[unique_nums[pivot_index]]
# 1. Move pivot to the end
unique_nums[pivot_index], unique_nums[right] = unique_nums[right], unique_nums[pivot_index]
# 2. Move all elements with frequency greater than the pivot's frequency to the left
store_index = left
for i in range(left, right):
if freq_map[unique_nums[i]] > pivot_frequency:
unique_nums[store_index], unique_nums[i] = unique_nums[i], unique_nums[store_index]
store_index += 1
# 3. Move pivot to its final place
unique_nums[right], unique_nums[store_index] = unique_nums[store_index], unique_nums[right]
return store_index
def quickselect(left, right, k_smallest):
if left == right:
return
pivot_index = random.randint(left, right)
pivot_index = partition(left, right, pivot_index)
if k_smallest == pivot_index:
return
elif k_smallest < pivot_index:
quickselect(left, pivot_index - 1, k_smallest)
else:
quickselect(pivot_index + 1, right, k_smallest)
n = len(unique_nums)
quickselect(0, n - 1, n - k)
return unique_nums[n - k:]
# 示例 1
nums1 = [1, 1, 1, 2, 2, 3]
k1 = 2
print(topKFrequent(nums1, k1)) # 输出: [1, 2]
# 示例 2
nums2 = [1]
k2 = 1
print(topKFrequent(nums2, k2)) # 输出: [1](3)复杂度分析
时间复杂度:
构建 freq_map 字典的过程需要遍历整个 nums 列表,时间复杂度为 O(n),其中 n 是列表的长度。
在 quickselect() 中,平均情况下每次递归可以将列表划分为大约一半的大小,因此递归的时间复杂度为 O(logn)。
在最坏情况下,每次递归只能将列表划分为一个元素的大小,因此最坏情况下递归的时间复杂度为 O(n)。
综上所述,代码的总体时间复杂度为 O(n + klogn)。
空间复杂度:
除了输入和输出之外,额外使用了一个字典 freq_map 和一个列表 unique_nums 来存储数字及其频率。它们的空间复杂度为 O(n)。
递归过程中不需要额外的空间。因此,代码的总体空间复杂度为 O(n)。
2.3 思路三:堆
(1)具体思路
当解决频率前 k 高的元素问题时,堆 (Heap) 是一个非常高效的数据结构。
我打算使用最小堆来解决这类问题。
具体过程如下:
遍历数组 nums 并使用哈希表记录每个元素的出现频率。
创建一个最小堆,遍历哈希表,将元素和其频率加入堆中。当堆的大小超过 k 时,移除堆顶元素(频率最小的元素)。
最终堆中剩下的元素即为出现频率前 k 高的元素。
(2)思路展示
① 遍历数组并记录每个元素的频率

②创建最小堆并加入元素频率

③控制堆大小不超过 k,移除堆顶元素
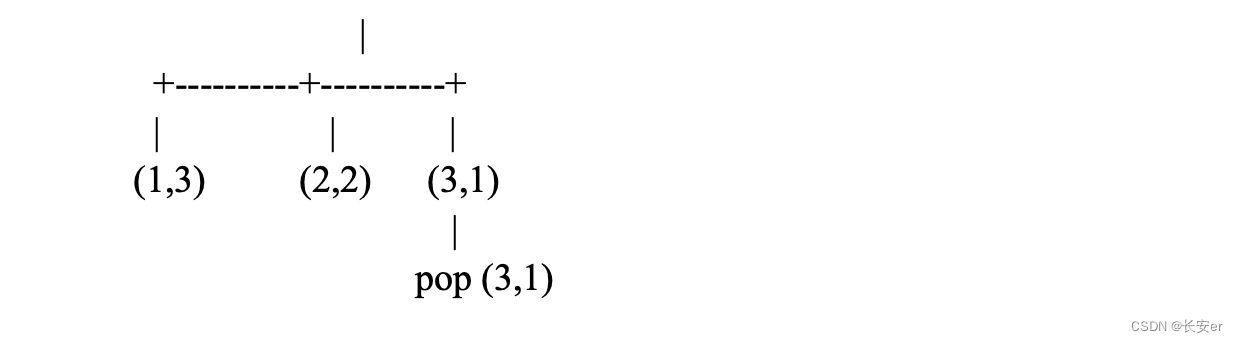
④堆中剩下的元素即为频率前 k 高的元素
在这个示意图中,首先遍历数组并记录每个元素的频率,得到哈希表。接下来,我们创建一个最小堆,并将元素和其频率加入堆中。当堆的大小超过 k 时,我们移除堆顶元素(频率最小的元素)。最终,堆中剩下的元素即为出现频率前 k 高的元素。
(3)代码实现
import heapq
from collections import Counter
def topKFrequent(nums, k):
# 使用 Counter 来计算每个元素的频率
counts = Counter(nums)
# 创建一个最小堆
heap = []
for num, count in counts.items():
heapq.heappush(heap, (count, num))
if len(heap) > k:
heapq.heappop(heap) # 弹出堆顶的最小频率元素
# 堆中剩下的元素即为出现频率前 k 高的元素
result = [x[1] for x in heap]
return result(4)运行结果
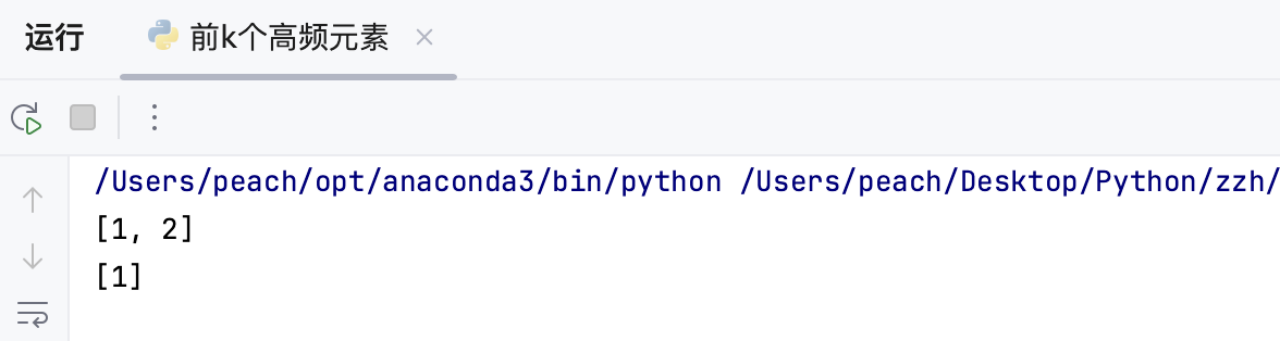
三种思路一致。
两个示例输入如下
输入: nums = [1,1,1,2,2,3], k = 2
输入: nums = [1], k = 1
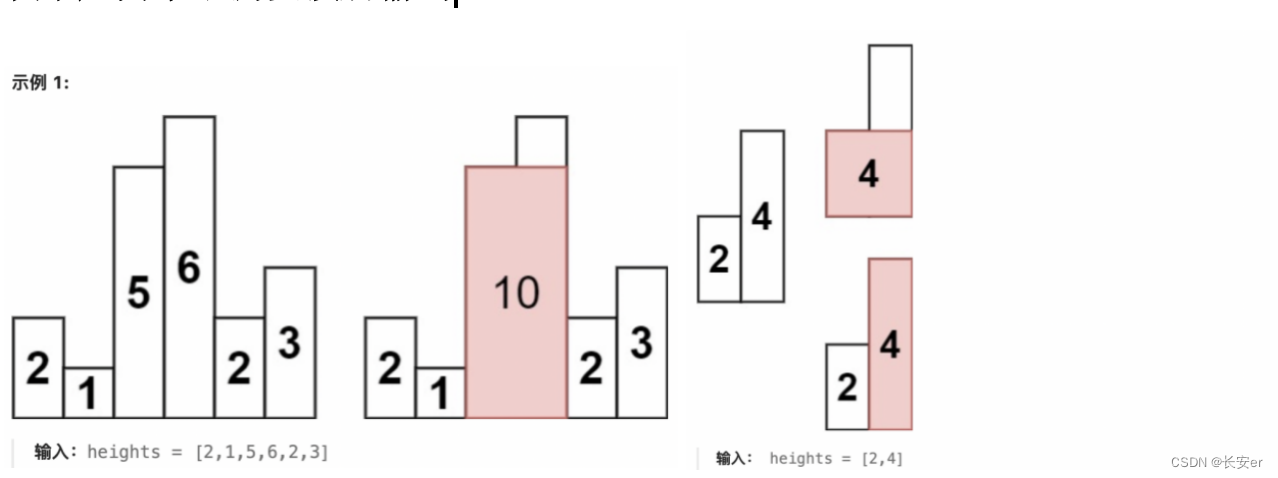
三、柱形图中的最大矩形
力扣第84题

本题采用单调栈的思想
3.1 具体思路
首先创建一个空栈和一个变量 max_area,用于记录最大面积。
遍历柱子的高度数组,并依次处理每个柱子。
如果栈为空或当前柱子的高度大于等于栈顶柱子的高度,则将当前柱子的索引入栈。
如果当前柱子的高度小于栈顶柱子的高度,则说明栈顶柱子的右边界确定了,可以计算以栈顶柱子为高的矩形的面积。
弹出栈顶柱子,并获取其高度 h 和左边界 left。
计算以栈顶柱子为高的矩形的面积为 area = h * (current_index - left - 1)。
更新 max_area 的值为 max(max_area, area)。
重复上述步骤直到栈为空或当前柱子的高度大于栈顶柱子的高度。
遍历结束后,如果栈中还有剩余的柱子,则按照上述步骤计算以这些柱子为高的矩形的面积,并更新max_area 的值。
返回 max_area 作为结果。
3.2 思路展示
给定
柱子高度数组: [2, 1, 5, 6, 2, 3]
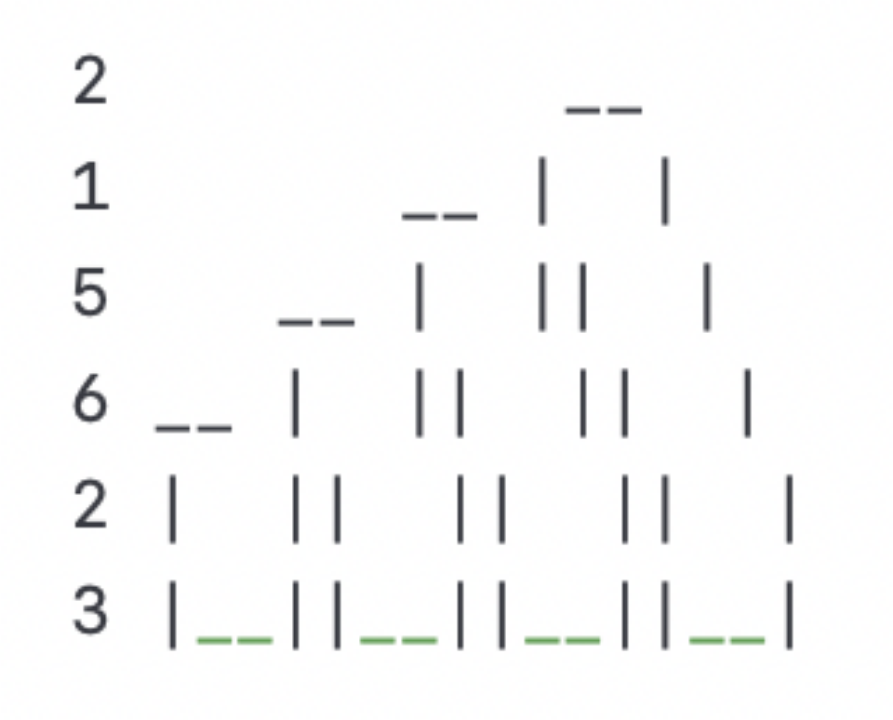
给定了一个柱子高度数组为 [2, 1, 5, 6, 2, 3]。
按照思路进行:
创建一个空栈和变量 max_area。
遍历柱子高度数组:
第一个柱子高度为 2,将其索引 0 入栈。
第二个柱子高度为 1,小于栈顶柱子的高度 2,因此可以确定栈顶柱子的右边界。弹出栈顶柱子,计算面积为 2 * (当前索引 1 - 左边界 0 - 1) = 2。更新 max_area 的值为 2。
第三个柱子高度为 5,大于栈顶柱子的高度 1,将其索引 2 入栈。
第四个柱子高度为 6,大于栈顶柱子的高度 5,将其索引 3 入栈。
第五个柱子高度为 2,小于栈顶柱子的高度 6,可以确定栈顶柱子的右边界。弹出栈顶柱子,计算面积为 6 * (当前索引 4 - 左边界 2 - 1) = 6。更新 max_area 的值为 6。
第六个柱子高度为 3,小于栈顶柱子的高度 2,可以确定栈顶柱子的右边界。弹出栈顶柱子,计算面积为 2 * (当前索引 5 - 左边界 4 - 1) = 2。更新 max_area 的值为 6。
遍历结束后,栈中还剩下两个柱子的索引,分别是 2 和 3。按照上述步骤分别计算以这些柱子为高的矩形的面积。
第一个柱子索引为 2,计算面积为 5 * (当前索引 6 - 左边界 0 - 1) = 10。更新 max_area 的值为 10。
第二个柱子索引为 3,计算面积为 6 * (当前索引 6 - 左边界 0 - 1) = 12。更新 max_area 的值为 12。
返回 max_area 的值 12 作为最大矩形面积的结果。
3.3 代码实现
def largestRectangleArea(heights):
stack = [] # 单调栈
max_area = 0 # 最大面积
# 遍历柱子的高度数组
for i in range(len(heights)):
while stack and heights[i] < heights[stack[-1]]:
# 弹出栈顶柱子并计算面积
h = heights[stack.pop()]
left = stack[-1] if stack else -1 # 左边界(栈顶柱子的右边柱子)
area = h * (i - left - 1)
max_area = max(max_area, area)
stack.append(i) # 将当前柱子索引入栈
# 处理剩余的柱子
while stack:
h = heights[stack.pop()]
left = stack[-1] if stack else -1
area = h * (len(heights) - left - 1)
max_area = max(max_area, area)
return max_area
# 示例测试
heights = [2, 1, 5, 6, 2, 3]
result = largestRectangleArea(heights)
print("最大矩形面积为:", result)
heights = [2, 4]
result = largestRectangleArea(heights)
print("最大矩形面积为:", result)3.4 复杂度分析
时间复杂度分析:
在代码中,我们使用了一个循环来遍历柱子的高度数组,这部分的时间复杂度为 O(n),其中 n 是柱子的个数。
在遍历过程中,对于每根柱子,我们进行了一些入栈和出栈操作,这些操作的时间复杂度可以视作 O(1) 的常数级操作。
因此,整体上,该算法的时间复杂度为 O(n)。
空间复杂度分析:
我们使用了一个栈来存储柱子的索引,因此空间复杂度取决于栈的大小。
最坏情况下,所有的柱子会依次入栈并弹出,此时栈的大小将达到柱子的个数,因此空间复杂度为 O(n)。
综上所述,该算法的时间复杂度为 O(n),空间复杂度为 O(n)。这意味着该算法在处理较大规模的柱状图时也能够保持较好的效率。
3.5 运行结果
以下是两个示例及预期输出
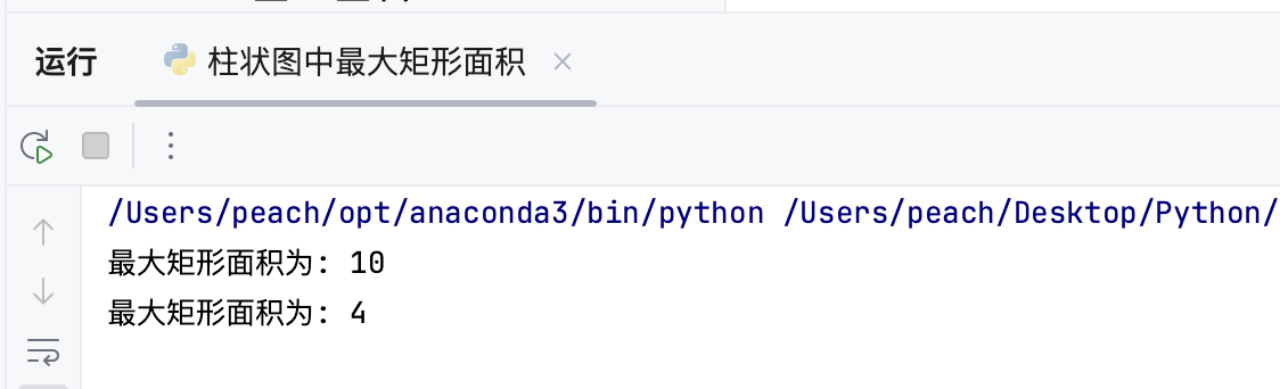
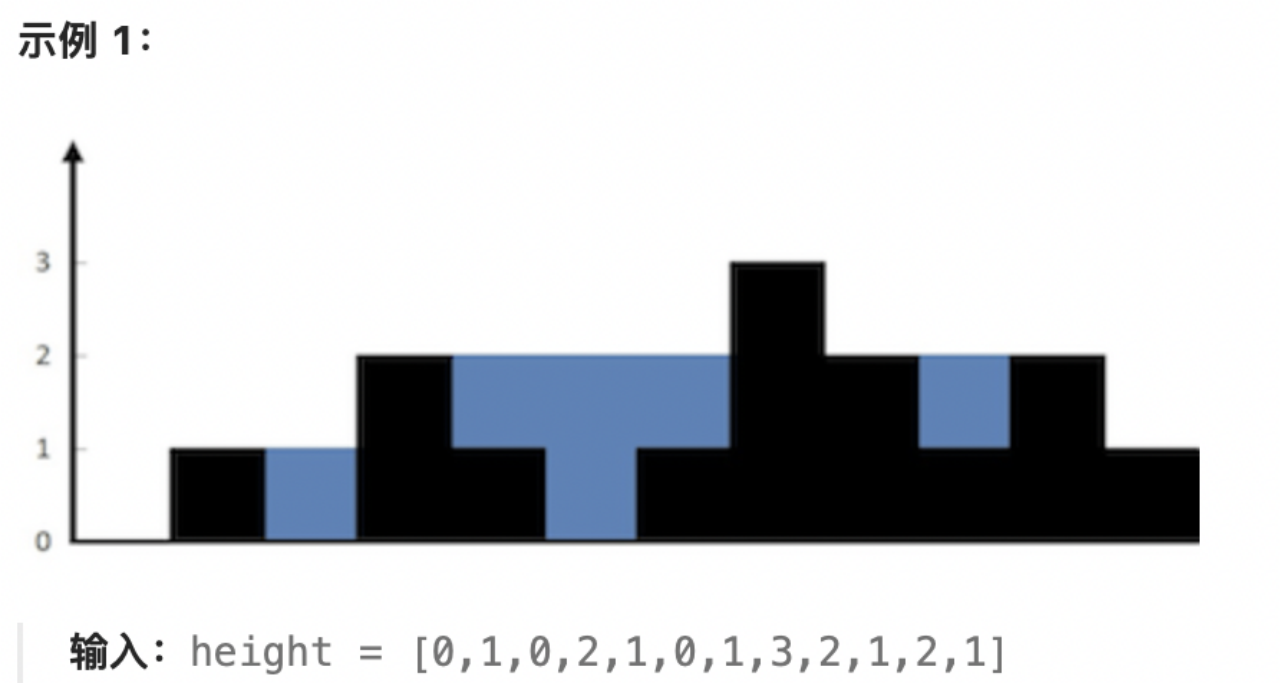
四、接雨水
力扣第42题
本题依旧采用单调栈的思想解决
4.1 具体思想
初始化一个栈 stack 和变量 water,用来存储柱子的索引和计算雨水的总量。
遍历柱子的高度数组 height:
如果栈为空,或者当前柱子的高度小于等于栈顶柱子的高度,则将当前柱子的索引入栈。
如果当前柱子的高度大于栈顶柱子的高度,说明有可能可以接到雨水。
弹出栈顶柱子的索引,并记为 cur。
如果栈为空,则跳过后续操作。
计算当前能接到的雨水量:水平宽度为 i - stack[-1] - 1,垂直高度为 min(height[i], height[stack[-1]]) - height[cur]。 将水平宽度乘以垂直高度得到雨水量,并累加到 water 中。
遍历结束后,返回 water 的值即为能接到的雨水总量。
4.2 代码实现
# 定义 trap 函数
def trap(height):
stack = []
water = 0
for i in range(len(height)):
while stack and height[i] > height[stack[-1]]:
cur = stack.pop()
if not stack:
break
width = i - stack[-1] - 1
h = min(height[i], height[stack[-1]]) - height[cur]
water += width * h
stack.append(i)
return water
# 示例 1的测试
height1 = [0, 1, 0, 2, 1, 0, 1, 3, 2, 1, 2, 1]
result1 = trap(height1)
print("示例 1的测试结果:", result1)
# 示例 2的测试
height2 = [4, 2, 0, 3, 2, 5]
result2 = trap(height2)
print("示例 2的测试结果:", result2)4.3 复杂度分析
代码中的 trap 函数使用了单调栈的思想,其时间复杂度为 O(n),其中 n 为输入列表 height 的长度。下面是对该算法的复杂度分析:
时间复杂度:遍历一次输入列表 height 需要 O(n) 的时间,而在每个索引上,最多进行了两次出栈操作和一次入栈操作。因此总的时间复杂度为 O(n)。
空间复杂度:额外使用了一个栈来存储柱子的索引,当柱子高度单调递减时,栈可能会达到最大长度为 n。因此空间复杂度也为 O(n)。
综上所述,这段代码的时间复杂度为 O(n),空间复杂度为 O(n)。这意味着在处理长度为 n 的输入列表时,算法的执行时间和所需的内存空间都与 n 成线性关系。
4.4 运行结果
示例 2:
输入:height = [4,2,0,3,2,5]
输出:9
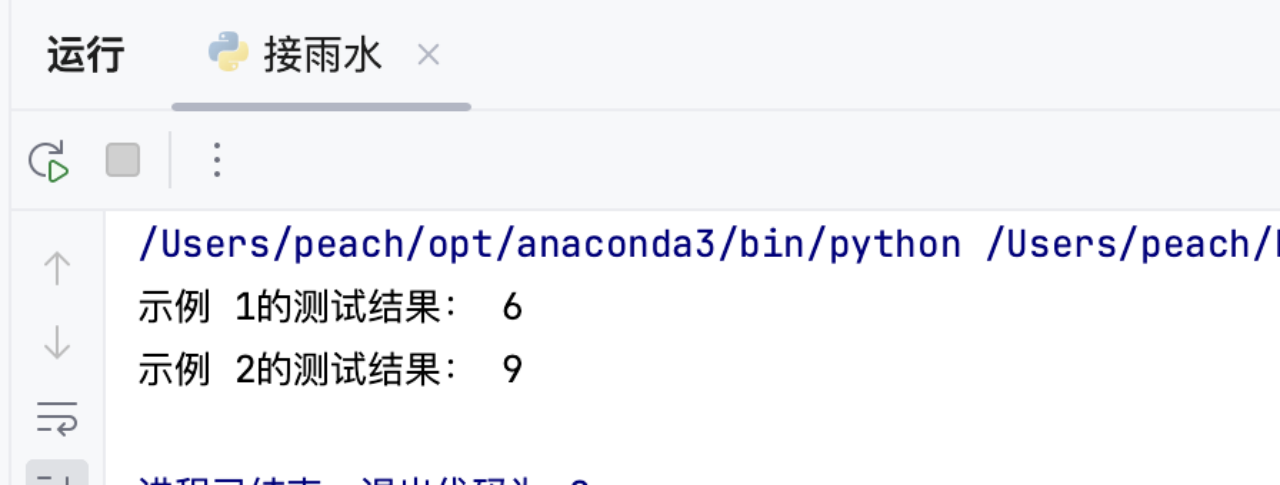
输出均与预期结果一致
结尾语
人总是无限接近幸福的时候最幸福
“𝓢𝓱𝓮 𝓬𝓮𝓻𝓽𝓪𝓲𝓷𝓵𝔂 𝓬𝓸𝓶𝓯𝓸𝓻𝓽𝓮𝓭 𝓪𝓷𝓭 𝓮𝓷𝓬𝓸𝓾𝓻𝓪𝓰𝓮𝓭 𝓱𝓮𝓻 𝓹𝓪𝓼𝓽 𝓼𝓮𝓵𝓯, 𝓪𝓷𝓭 𝓼𝓱𝓮 𝓲𝓼 𝓪𝓵𝓼𝓸 𝓯𝓲𝓻𝓶𝓵𝔂 𝓭𝓮𝓽𝓮𝓻𝓶𝓲𝓷𝓮𝓭 𝓽𝓸 𝓫𝓮𝓬𝓸𝓶𝓮 𝓱𝓮𝓻 𝓯𝓾𝓽𝓾𝓻𝓮 𝓼𝓮𝓵𝓯.”
天天开心!
2024-2-1

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











