







目录
一、编辑距离
力扣第72题

本题采用动态规划的思路
1.1 具体思路
我们可以创建一个二维数组 dp,其中 dp[i][j] 表示将 word1 的前 i 个字符转换成 word2 的前 j 个字符所需的最少操作数。
步骤如下:
①初始化:首先,我们需要初始化 dp 数组。特别地,dp[0][j] 表示将空字符串转换成 word2 的前 j 个字符所需的操作数,显然需要 j 次插入操作;同样地,dp[i][0] 表示将 word1 的前 i 个字符转换成空字符串所需的操作数,需要 i 次删除操作。
②填充 dp 数组:接下来,我们按行填充 dp 数组。对于每一对字符 word1[i] 和 word2[j],我们有以下几种情况:
如果 word1[i] 等于 word2[j],则当前字符不需要任何操作,dp[i][j] 就等于 dp[i-1][j-1]。
如果 word1[i] 不等于 word2[j],则我们可以通过三种操作中的一种将 word1 的前 i 个字符转换为 word2 的前 j 个字符:
插入:从 dp[i][j-1] 转换过来,即在 word1 中插入 word2[j],因此操作数加一。
删除:从 dp[i-1][j] 转换过来,即删除 word1[i],因此操作数加一。
替换:从 dp[i-1][j-1] 转换过来,即将 word1[i] 替换为 word2[j],因此操作数加一。 我们选择这三种操作中的最小操作数作为 dp[i][j] 的值。
③返回结果:最后,dp[m][n] 就是将整个 word1 转换为整个 word2 所需的最少操作数,其中 m 和 n 分别是两个字符串的长度。
1.2 思路展示
假设我们有两个单词 word1 和 word2,长度分别为 m 和 n。我们将创建一个 (m+1) 行 (n+1) 列的二维数组 dp,其中 dp[i][j] 表示将 word1 的前 i 个字符转换成 word2 的前 j 个字符所需的最少操作数。
这里是 dp 数组的初始化和填充过程的文字描述:
"" w2[0] w2[1] w2[2] ... w2[n-1]
"" 0 1 2 3 ... n
w1[0] 1
w1[1] 2
w1[2] 3
...
w1[m-1] m
初始化:
第一行:dp[0][j] = j,意味着将空字符串转换为 word2 的前 j 个字符需要 j 次插入操作。
第一列:dp[i][0] = i,意味着将 word1 的前 i 个字符转换为空字符串需要 i 次删除操作。
填充:
对于每个 i(从 1 到 m)和 j(从 1 到 n):
如果 word1[i-1] == word2[j-1](注意数组下标从 0 开始),则 dp[i][j] = dp[i-1][j-1]。
否则,dp[i][j] = min(dp[i-1][j], dp[i][j-1], dp[i-1][j-1]) + 1,分别对应删除、插入和替换操作。
最后,dp[m][n] 就是从 word1 转换到 word2 所需的最少操作数。
如果我们用实际的单词例如 "horse" 和 "ros" 来填充一个 dp 表格,它可能看起来像这样:
"" r o s
"" 0 1 2 3
h 1 1 2 3
o 2 2 1 2
r 3 2 2 2
s 4 3 3 2
e 5 4 4 3
在这个例子中,dp[5][3] 是最终结果,表示将 "horse" 转换为 "ros" 需要的最少操作数是 3。
1.3 代码实现
def minDistance(word1, word2):
m, n = len(word1), len(word2)
# 创建一个(m+1) x (n+1)的二维数组dp,用于保存从word1的前i个字符转换到word2的前j个字符需要的最小操作数
dp = [[0] * (n + 1) for _ in range(m + 1)]
# 初始化边界条件
for i in range(m + 1):
dp[i][0] = i # word1的前i个字符转换到空字符串需要i步(全部删除)
for j in range(n + 1):
dp[0][j] = j # 空字符串转换到word2的前j个字符需要j步(全部插入)
# 动态规划填表
for i in range(1, m + 1):
for j in range(1, n + 1):
if word1[i - 1] == word2[j - 1]:
dp[i][j] = dp[i - 1][j - 1] # 字符相同,无需操作,继承上一状态的操作数
else:
dp[i][j] = 1 + min(dp[i - 1][j], # 删除
dp[i][j - 1], # 插入
dp[i - 1][j - 1]) # 替换
return dp[m][n]
# 示例测试
word1 = "horse"
word2 = "ros"
print(minDistance(word1, word2)) # 输出应该是3
word1 = "intention"
word2 = "execution"
print(minDistance(word1, word2)) # 输出应该是51.4 复杂度分析
我们使用了二维动态规划的方法来计算两个字符串之间的最小编辑距离。现在,我们来对这个函数的时间复杂度和空间复杂度进行分析。
①时间复杂度
时间复杂度主要由双重循环决定。外层循环遍历word1的长度m,内层循环遍历word2的长度n。每个循环体内的操作是常数时间复杂度。因此,总的时间复杂度为O(m * n)。
②空间复杂度
空间复杂度主要由用于存储动态规划状态的二维数组dp决定。这个数组的大小是(m+1) x (n+1),所以总的空间复杂度为O(m * n)。
综上所述,minDistance函数的时间复杂度和空间复杂度都是O(m * n),其中m是字符串word1的长度,n是字符串word2的长度。
1.5 运行结果
示例一
word1 = "horse"
word2 = "ros"
示例二
word1 = "intention"
word2 = "execution"

二、买卖股票的最佳时机
力扣第122题

本题采用贪心算法的思路求解
2.1 具体思路
贪心算法是一种在每一步选择中都采取当前状态下最好或最优(即最有利)的选择,从而希望导致结果是全局最好或最优的算法策略。
在这个问题中,贪心算法的策略是:
遍历价格数组,从第二天开始比较。
如果第i天的价格比第i-1天的价格高,那么我们就可以假设在第i-1天买入,在第i天卖出,所以我们将这个差值(prices[i] - prices[i-1])加到我们的总利润中。
重复这个过程,直到遍历完整个数组。
*如何理解此逻辑?
这种方法之所以有效,是因为它累加了所有连续的增长期间的利润,这与多次买入和卖出的总利润是相同的。换句话说,如果股票价格是连续上升的,那么在开始时买入并在结束时卖出与每天买入卖出获得的利润是相同的。如果我们把每天的小利润加起来,就等于最初买入和最后卖出的利润。
2.2 思路展示
假设我们有以下股票价格数组:
prices = [7, 1, 5, 3, 6, 4]
我们通过以下步骤来计算最大利润:
从第一天开始,比较相邻两天的价格。
第一天价格为7,第二天价格为1,价格下降,所以不进行交易。
第二天价格为1,第三天价格为5,价格上升,我们假设第二天买入,第三天卖出,获得利润5 - 1 = 4。
第三天价格为5,第四天价格为3,价格下降,所以不进行交易。
第四天价格为3,第五天价格为6,价格上升,我们假设第四天买入,第五天卖出,获得利润6 - 3 = 3。
第五天价格为6,第六天价格为4,价格下降,所以不进行交易。
总利润为第三天和第五天获得的利润之和:4 + 3 = 7。
这个过程可以用下面的图表来表示:
| Day | Price | Action | Profit | Total Profit |
| 1 | 7 | - | - | 0 |
| 2 | 1 | Buy | - | 0 |
| 3 | 5 | Sell (5 - 1) | 4 | 4 |
| 4 | 3 | Buy | - | 4 |
| 5 | 6 | Sell (6 - 3) | 3 | 7 |
| 6 | 4 | - | - | 7 |
在这个表格中,"Day"列代表天数,"Price"列代表当天的股票价格,"Action"列描述了我们采取的行动(买入、卖出或不操作),"Profit"列显示了当天的利润(如果有的话),而"Total Profit"列则累计了到目前为止的总利润。如表格所示,通过在价格上升时买入和卖出,我们最终获得了7元的最大利润。
2.3 代码实现
def maxProfit(prices):
# 初始化最大利润为0
max_profit = 0
# 遍历价格数组,从第二天开始
for i in range(1, len(prices)):
# 如果今天的价格比昨天高
if prices[i] > prices[i - 1]:
# 我们可以获得昨天买入、今天卖出的利润
max_profit += prices[i] - prices[i - 1]
# 返回计算出的最大利润
return max_profit
# 示例测试
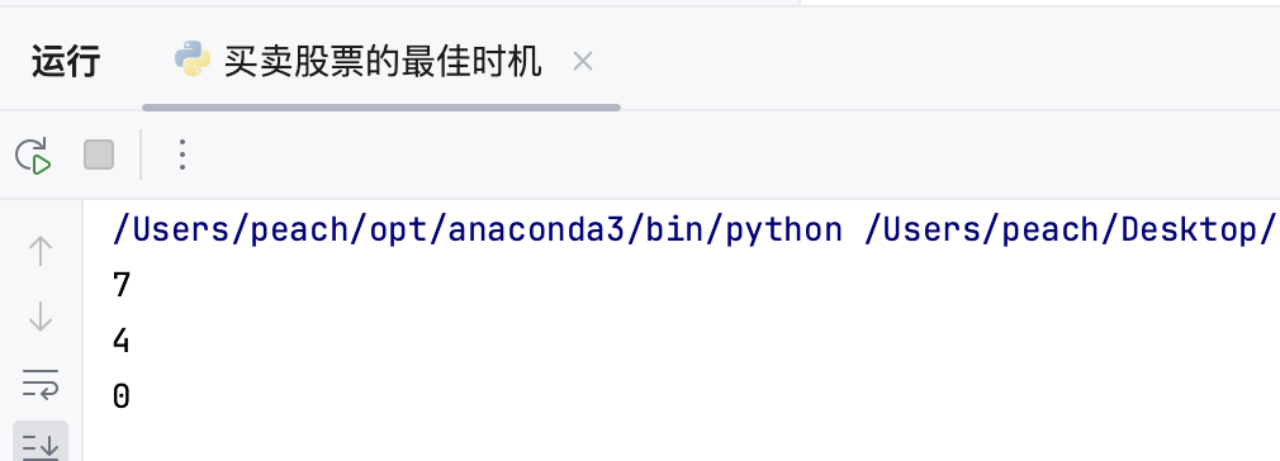
prices1 = [7,1,5,3,6,4]
print(maxProfit(prices1)) # 应输出7
prices2 = [1,2,3,4,5]
print(maxProfit(prices2)) # 应输出4
prices3 = [7,6,4,3,1]
print(maxProfit(prices3)) # 应输出02.4 复杂度分析
·时间复杂度
时间复杂度是指算法执行的时间与输入数据之间的关系。在这个函数中,我们有一个主要的循环(第5行),它遍历了一次输入数组prices。
循环从索引1开始,直到数组的长度len(prices)结束。因此,循环会运行(len(prices) - 1)次。
在循环体内(第6-9行),所有操作(包括比较和加法)都是常数时间操作。
因此,整个函数的时间复杂度为O(n),其中n是数组prices的长度。
·空间复杂度
空间复杂度度量的是算法在执行过程中临时占用存储空间的大小。在这个函数中:
我们只使用了一个变量max_profit来存储最大利润,它是一个整数类型,占用的空间是常数大小。
循环变量i也是常数空间。
因此,整个函数的空间复杂度为O(1),也就是说,它只需要常数的额外空间。
综上所述,maxProfit函数的时间复杂度是O(n),空间复杂度是O(1)。
2.5 运行结果
# 示例测试
prices1 = [7,1,5,3,6,4]
prices2 = [1,2,3,4,5]
prices3 = [7,6,4,3,1]
三、单词拆分
力扣第140题

本题将采用回溯法加上动态规划的剪枝进行求解
3.1 具体思路
首先,我们需要一个方法来判断字符串 s 的任意子串是否可以被分割成字典 wordDict 中的单词。这可以通过动态规划实现,创建一个布尔数组 dp,其中 dp[i] 表示字符串 s 的前 i 个字符是否可以用 wordDict 中的单词表示。
详细思路如下:
①动态规划预处理:
创建一个布尔数组 dp 长度为 len(s) + 1,并初始化 dp[0] = True,因为空字符串总是可以被表示。
对于每个 i 从 1 到 len(s),对于每个单词 word 在 wordDict 中:
如果 i >= len(word) 并且 s[i-len(word):i] == word 并且 dp[i-len(word)] 是 True,那么 dp[i] 应该被设置为 True。
这样,dp[len(s)] 就告诉我们 s 是否可以被分割成字典中的单词。
②回溯法构建句子:
定义一个回溯函数 backtrack(start, path),其中 start 是当前考虑的子串的起始索引,path 是到目前为止形成的单词列表。
如果 start == len(s),则将 path 加入结果列表中,因为我们已经到达了字符串的末尾。
否则,遍历字符串 s,从索引 start 到 len(s):
如果 s[start:i+1] 在 wordDict 中,并且 dp[start] 是 True(表示从 s[0] 到 s[start-1] 的子串可以被分割成字典中的单词),那么:
将 s[start:i+1] 添加到当前 path 中。
递归调用 backtrack(i+1, path + [s[start:i+1]])。
回溯,即从 path 中移除 s[start:i+1]。
③初始化和调用回溯:
创建一个结果列表 res 来存储所有可能的句子。
调用 backtrack(0, []) 开始回溯过程。
返回 res。
3.2 思路展示
假设我们有如下输入:
s = "catsanddog"
wordDict = ["cat", "cats", "and", "sand", "dog"]
①动态规划过程:
我们创建一个布尔数组dp,长度为len(s) + 1,初始化dp[0] = True(空字符串是可以被分割的)。
dp = [False] * (len(s) + 1)
dp[0] = True
我们的dp数组初始状态如下:
dp = [True, False, False, False, False, False, False, False, False, False, False, False]
现在我们开始填充dp数组:
遍历字符串s中的每个字符。
对于每个位置i,遍历wordDict中的每个单词word。
如果子串s[i-len(word):i]等于word并且dp[i-len(word)]是True,则将dp[i]设置为True。
完成这一步后,dp数组状态如下:
dp = [True, False, False, False, True, False, False, True, False, False, True, True]
dp[len(s)]为True,表示整个字符串s可以被分割成字典中的单词。
②回溯过程:
接下来,我们使用回溯法来构建所有可能的句子。我们定义一个辅助函数backtrack(start, path),其中start是当前考虑的子串的起始索引,path是到目前为止形成的单词列表。
我们从start = 0和空路径path = []开始调用backtrack函数。回溯函数的执行流程如下:
backtrack(0, [])
-> s[0:3] == "cat" and dp[3] is True:
-> backtrack(3, ["cat"])
-> s[3:6] == "sand" and dp[6] is False: skip
-> s[3:7] == "and" and dp[7] is True:
-> backtrack(7, ["cat", "and"])
-> s[7:10] == "dog" and dp[10] is True:
-> add ["cat", "and", "dog"] to res
-> s[0:4] == "cats" and dp[4] is True:
-> backtrack(4, ["cats"])
-> s[4:7] == "and" and dp[7] is True:
-> backtrack(7, ["cats", "and"])
-> s[7:10] == "dog" and dp[10] is True:
-> add ["cats", "and", "dog"] to res
最终,我们得到两个可能的句子,即res = [["cat", "and", "dog"], ["cats", "and", "dog"]]。
3.3 代码实现
1.def wordBreak(s, wordDict):
2. wordSet = set(wordDict)
3. n = len(s)
4.
5. # 动态规划预处理
6. dp = [False] * (n + 1)
7. dp[0] = True
8. for i in range(1, n + 1):
9. for word in wordDict:
10. if dp[i - len(word)] and s[i - len(word):i] == word:
11. dp[i] = True
12. break
13.
14. # 回溯法构建句子
15. def backtrack(start, path):
16. if start == n:
17. res.append(' '.join(path))
18. return
19. for end in range(start + 1, n + 1):
20. if dp[end] and s[start:end] in wordSet:
21. backtrack(end, path + [s[start:end]])
22.
23. # 初始化和调用回溯
24. res = []
25. backtrack(0, [])
26. return res
27.
28.# 示例
29.print(wordBreak("catsanddog", ["cat","cats","and","sand","dog"]))
3.4 复杂度分析
我们需要分析两部分的复杂度:动态规划预处理部分和回溯法构建句子部分。
①动态规划预处理的复杂度:
时间复杂度:我们有一个外层循环遍历字符串s的每个字符,这个循环的次数为n。内层循环遍历字典wordDict中的每个单词,假设字典中平均单词长度为m,最坏情况下,我们可能需要比较n次。因此,动态规划部分的时间复杂度大约为O(n * m * k),其中k是字典中单词的数量。
空间复杂度:我们使用了长度为n + 1的布尔数组dp来存储状态,因此空间复杂度为O(n)。
①回溯法构建句子的复杂度:
时间复杂度:在最坏情况下,如果字符串可以被分割成字典中所有单词的所有组合,我们可能需要探索所有可能的分割方式。这将导致指数级的时间复杂度,因为每个位置都可以是一个潜在的分割点。具体来说,时间复杂度为O(2^n),因为每个位置都有两种选择:分割或不分割。
空间复杂度:回溯法在递归时会占用额外的空间,最坏情况下,递归的深度可以达到n,因此递归栈的空间复杂度为O(n)。此外,我们还需要存储中间路径path和最终结果res。在最坏情况下,这些可能包含字符串s的所有子串,因此空间复杂度也可能相当高,取决于字符串s的分割方式。
综上所述,整个wordBreak函数的总时间复杂度是O(n * m * k + 2^n),总空间复杂度是O(n + n * L),其中L是结果列表res中所有字符串长度的总和。然而,在实际应用中,由于动态规划数组dp的存在,很多不可能的分割会被提前排除,实际的时间复杂度可能会低于理论的最坏情况。
3.5 运行结果
# 示例
print(wordBreak("catsanddog", ["cat", "cats", "and", "sand", "dog"]))
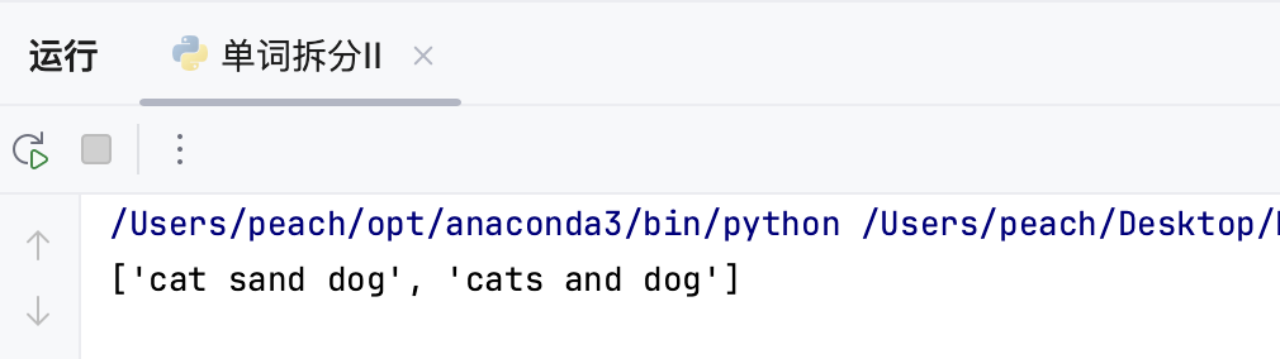
运行结果与预期结果一致
四、打家劫舍
力扣第337题

本题将使用树形动态规划(也称为后序遍历)的思想进行求解。
4.1 具体思路
我们可以为每个节点定义一个两元素数组,表示:
当前节点不被偷时,以该节点为根的子树能够盗取的最高金额。
当前节点被偷时,以该节点为根的子树能够盗取的最高金额。
对于二叉树中的任意节点 root,有两种情况:
如果偷 root 节点,那么不能偷它的左右子节点,但可以偷它的四个孙子节点。
如果不偷 root 节点,那么可以偷它的左右子节点。
详细思路如下:
①对于每个节点,返回一个大小为 2 的数组 amount,其中 amount[0] 表示不偷这个节点所能获得的最大金额,amount[1] 表示偷这个节点所能获得的最大金额。
②后序遍历这棵树,对于每个节点 root:
③先计算它的左子节点提供的两种选择,再计算它的右子节点提供的两种选择。
如果偷 root 节点,那么最大金额是 root.val + left[0] + right[0]。
如果不偷 root 节点,那么最大金额是 max(left[0], left[1]) + max(right[0], right[1])。
最后,根节点的最大金额就是 max(root[0], root[1])。
4.2 思路展示
假设我们有以下的二叉树结构:

在这个例子中,我们需要计算出不触发警报的情况下,小偷能够盗取的最高金额。按照上述算法,我们会后序遍历这棵树,并为每个节点计算两个值:amount[0](不偷这个节点时的最大金额)和 amount[1](偷这个节点时的最大金额)。
逐步分析
对于叶子节点(值为 3 和 1 的节点),它们没有孩子节点,所以 amount[0] = 0(不偷叶子节点时的最大金额为 0),amount[1] = node.val(偷叶子节点时的最大金额为节点本身的值)。
对于值为 2 的节点,它只有一个右孩子(值为 3 的节点):
如果不偷这个节点(即 amount[0]),我们可以选择偷或者不偷它的孩子节点,所以 amount[0] = max(孩子节点的 amount[0], 孩子节点的 amount[1])。
如果偷这个节点(即 amount[1]),我们不能偷它的孩子节点,所以 amount[1] = node.val + 孩子节点的 amount[0]。
对于值为 3 的根节点,它有两个孩子(值为 2 和 3 的节点):
如果不偷根节点(即 amount[0]),我们可以选择偷或者不偷它的左右孩子节点,所以 amount[0] = max(左孩子的 amount[0], 左孩子的 amount[1]) + max(右孩子的 amount[0], 右孩子的 amount[1])。
如果偷根节点(即 amount[1]),我们不能偷它的左右孩子节点,所以 amount[1] = node.val + 左孩子的 amount[0] + 右孩子的 amount[0]。
最后,我们比较根节点不被偷和被偷时的金额,取最大值即可。
以下是具体的计算过程:
叶子节点:
节点3:amount[0] = 0, amount[1] = 3
节点1:amount[0] = 0, amount[1] = 1
节点2:
amount[0] = max(3的 amount[0], 3的 amount[1]) = max(0, 3) = 3
amount[1] = 2 + 3的 amount[0] = 2 + 0 = 2
节点3:
amount[0] = max(2的 amount[0], 2的 amount[1]) + max(1的 amount[0], 1的 amount[1]) = max(3, 2) + max(0, 1) = 3 + 1 = 4
amount[1] = 3 + 2的 amount[0] + 1的 amount[0] = 3 + 3 + 0 = 6
根节点的最大金额:
max(amount[0], amount[1]) = max(4, 6) = 6
因此,小偷能够盗取的最高金额是 6。
4.3 代码实现
# Definition for a binary tree node.
class TreeNode:
def __init__(self, val=0, left=None, right=None):
self.val = val
self.left = left
self.right = right
def rob(root):
# res[0] 表示不偷 root 的情况下,最大金额
# res[1] 表示偷 root 的情况下,最大金额
def dfs(node):
if not node:
return [0, 0]
left = dfs(node.left)
right = dfs(node.right)
# 不偷当前节点,左右孩子可以偷或不偷,取最大值
rob_current = node.val + left[0] + right[0]
# 偷当前节点,左右孩子都不能偷
not_rob_current = max(left[0], left[1]) + max(right[0], right[1])
return [not_rob_current, rob_current]
result = dfs(root)
return max(result[0], result[1])
# 示例
root = TreeNode(3)
root.left = TreeNode(2)
root.right = TreeNode(3)
root.left.right = TreeNode(3)
root.right.right = TreeNode(1)
print(rob(root)) # 输出: 74.4 复杂度分析
代码中的 rob 函数使用了深度优先搜索(DFS)来实现树形动态规划。对于每个节点,dfs 函数都会计算两个值:不偷这个节点时的最大金额和偷这个节点时的最大金额。这个过程会对每个节点访问一次,因此时间复杂度和空间复杂度都与树中节点的数量有关。
时间复杂度:对于每个节点,我们只访问一次,并且在每次访问时只进行常数时间的操作(除了递归调用)。因此,时间复杂度是 O(N),其中 N 是树中节点的数量。
空间复杂度:空间复杂度主要由递归栈的深度决定,这取决于树的高度。在最坏的情况下(树完全不平衡,退化为链表),空间复杂度为 O(N)。在最好的情况下(树完全平衡),空间复杂度为 O(logN)。因此,空间复杂度介于 O(logN) 到 O(N) 之间,具体取决于输入树的形状。
4.5 运行结果
示例
输入: root = [3,2,3,null,3,null,1]
对应的树结构如下

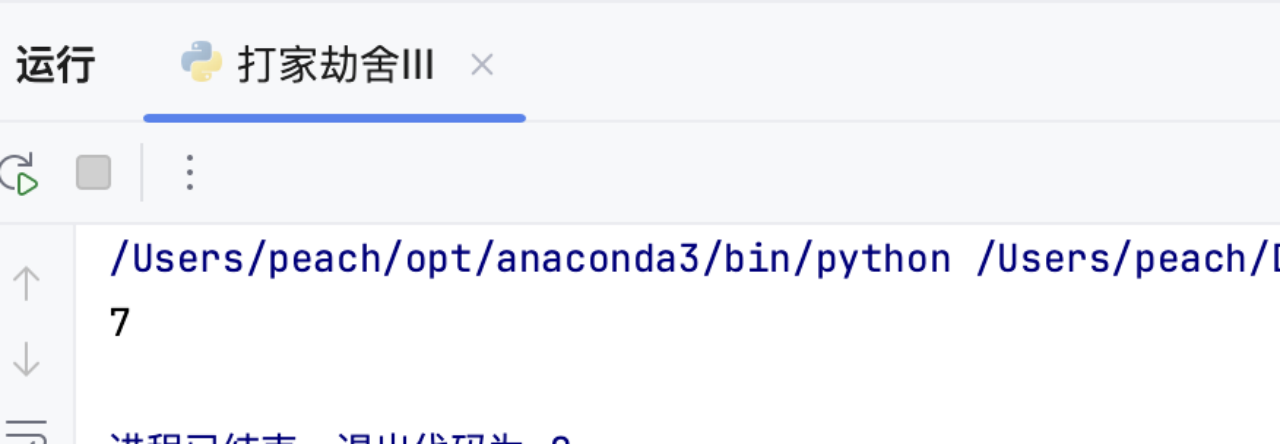
运行结果与预期一致。
结尾语

















 646
646











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











