






相关术语理解和什么是数据挖掘的解释
- 数据挖掘:加工数据得到想要的
- 数据挖掘步骤:数据的清理,集成,选择,变换,挖掘;模式评估,知识表示。
- 挖掘什么类型数据:任何数据,基本的有数据库数据,数据仓库数据,事务数据等。
- 数据仓库:从多个数据源搜集的信息储存库。
- 挖掘什么类型的模式:特征化与区分,频繁模式(数据频繁出现后的模式,例如频繁项集就是频繁在事务数据集中一起出现的商品的集合),关联和相关性挖掘,分类与回归,聚类分析,离群点分析。
数据挖掘功能用于指定数据挖掘任务发现的模式(指定模式)。这些任务可分为描述性(分类与回归)和预测性(聚类)。描述性是刻画数据一般性质,预测性是归纳后预测
-
分类:找出描述和区分数据类或概念的模型的一个过程。以便于用该模型去预测类标号未知的对象的类标号。
-
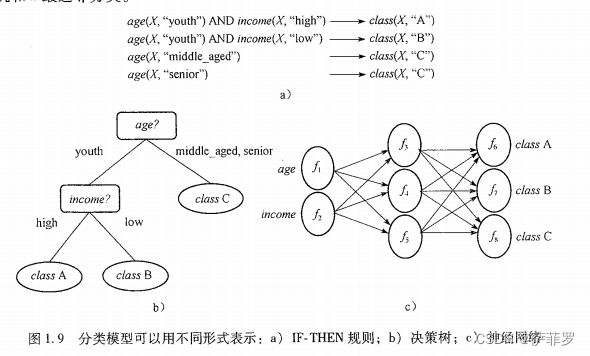
导出的模型:基于训练数据集(数据划分为一些用来训练,一些用来做)的分析。表现形式有分类规则(IF-THEN)。决策树(类似流程图的树结构),数学公式或神经网络。
-
构造分类模型的其它方法:朴素贝叶斯分类,支持向量机和k最近邻分类。
-
回归:分类是预测类别(离散的,无序的)标号,而回归是建立连续值函数模型。即用来预测缺失或难以获得(就比如知道他的大体趋势,推测想要的数据,高中有教回归方程)的数据值。回归分析是最常用的数值预测的统计学方法。回归也包含基于可用数据的分布趋势识别。
-
相关分析:可能需要在分类和回归之前进行,就是是试图识别与分类和回归过程显著相关的属性,选取这些属性用于分类和回归过程。
所以分类可想成是找出模型对数据集进行分类打上对应类标号,回归就是借助趋势规律预测需要的数据值,相关分析为找分类和回归显著相关的属性。
-
聚类(clustering)分析:不是标记类的训练数据集,而是分析数据对象不考虑类标号→许多情况开始并不存在标记类的数据,而是使用聚类产生数据组群的类标号,对象根据最大化类相似性,最小化类间相似性的原则进行聚类或分组,得到簇(cluster)。所形成的簇可以看做一个对象类,由它可以导出规则。聚类也便于分类法形成(taxonomy formation)

-
离群点分析:与数据的一般行为或模型不一致的数据对象称为离群点,大部分数据挖掘方法视为噪声或异常而丢弃,在一些应用(如欺诈检测)中需要。离群点数据分析称为离群点分析或异常挖掘。
-
支持度support:事务数据库中满足规则的事务的百分比。
-
置信度confidence:确信程度。
-
监督学习:基本是分类的同义词,监督来自于训练数据集中标记的实例。
-
无监督学习:本质是聚类的同义词
-
半监督学习:一类机器学习技术,标记的实例用来学习类模型,未标记的实例用来进一步改进类边界















 1002
1002











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









