







准备工作
-
准备一个微信公众号的账号:https://mp.weixin.qq.com/
没有的话这里注册一个:

-
之后点这个文章
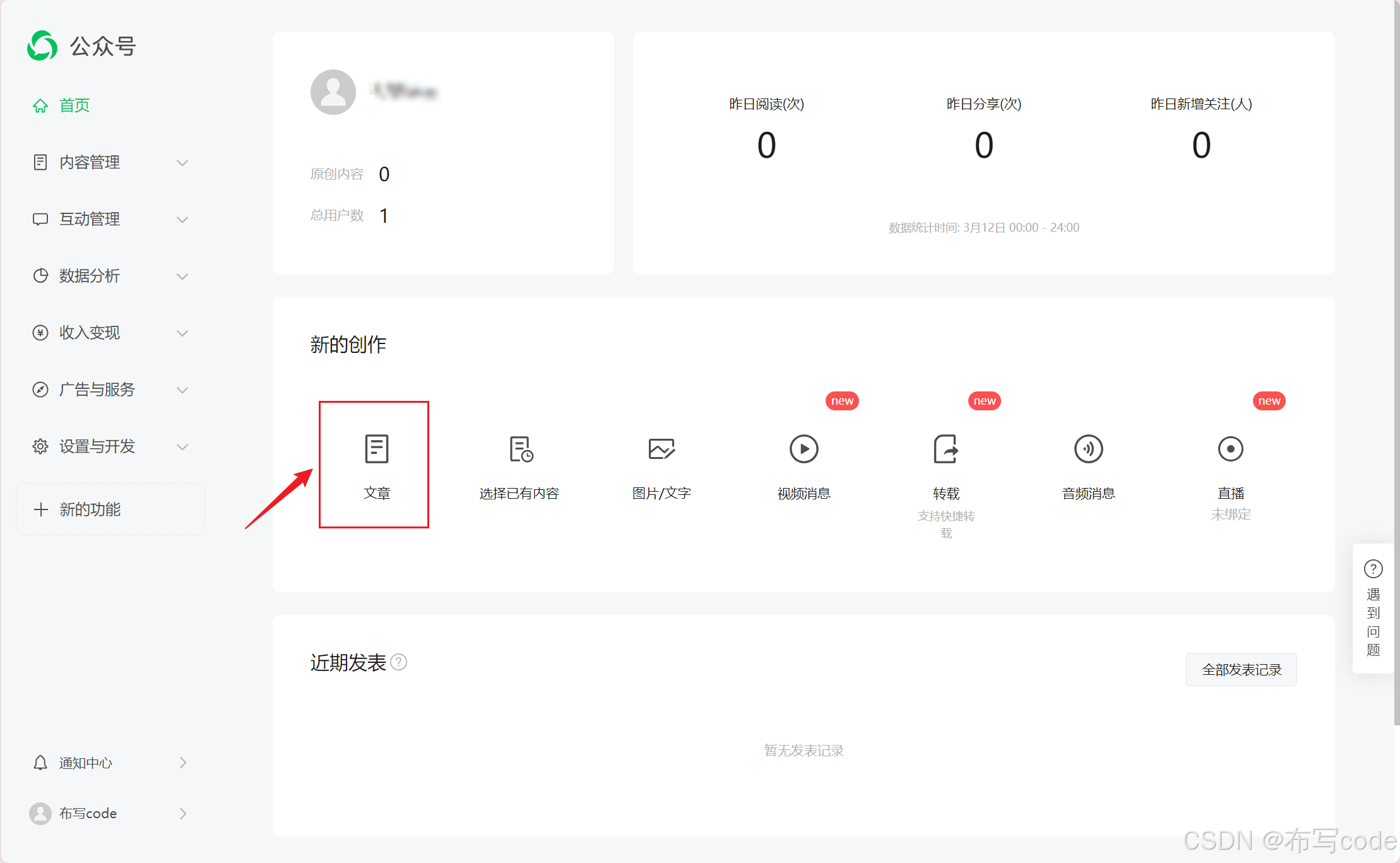
-
再点击超链接
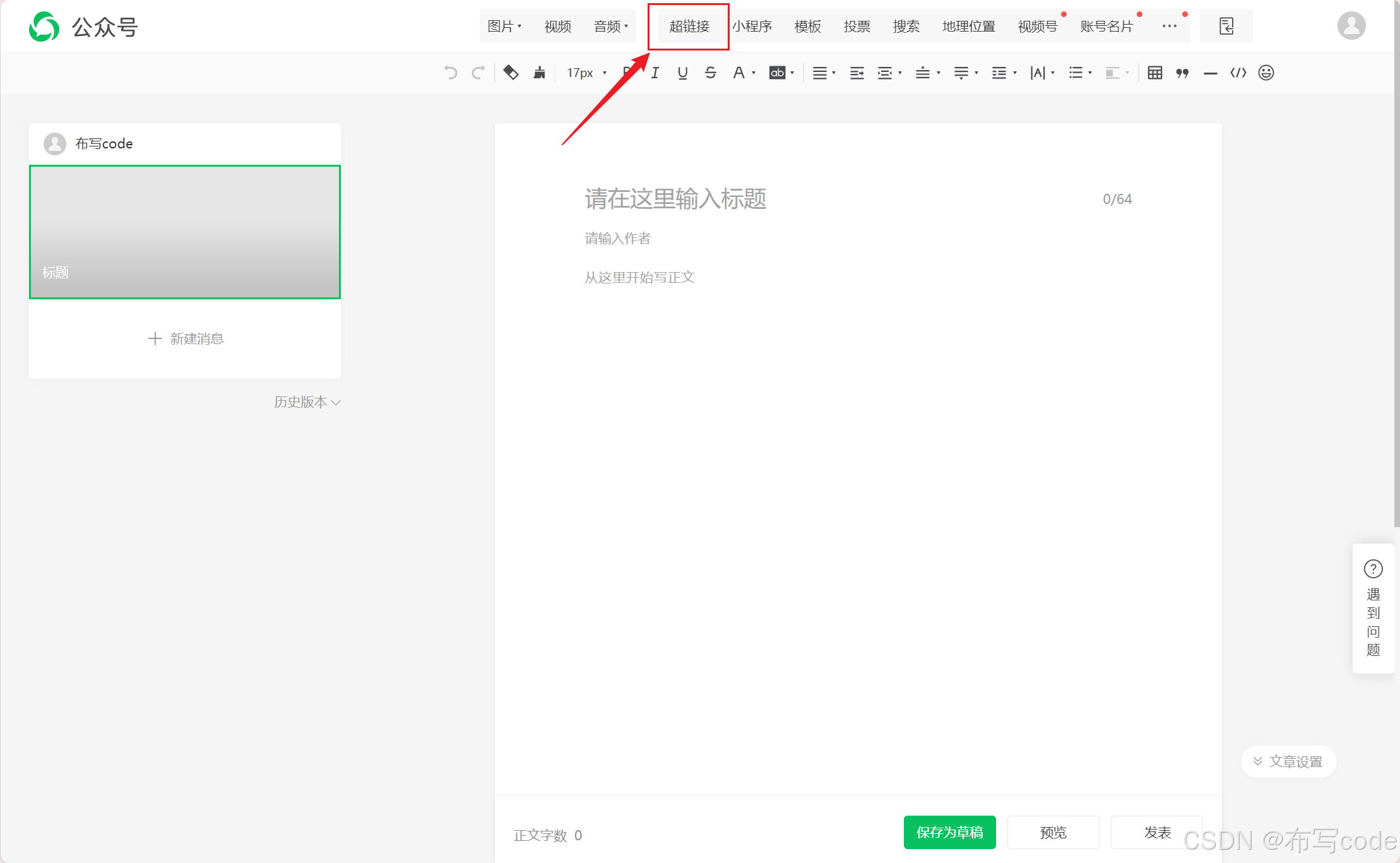
-
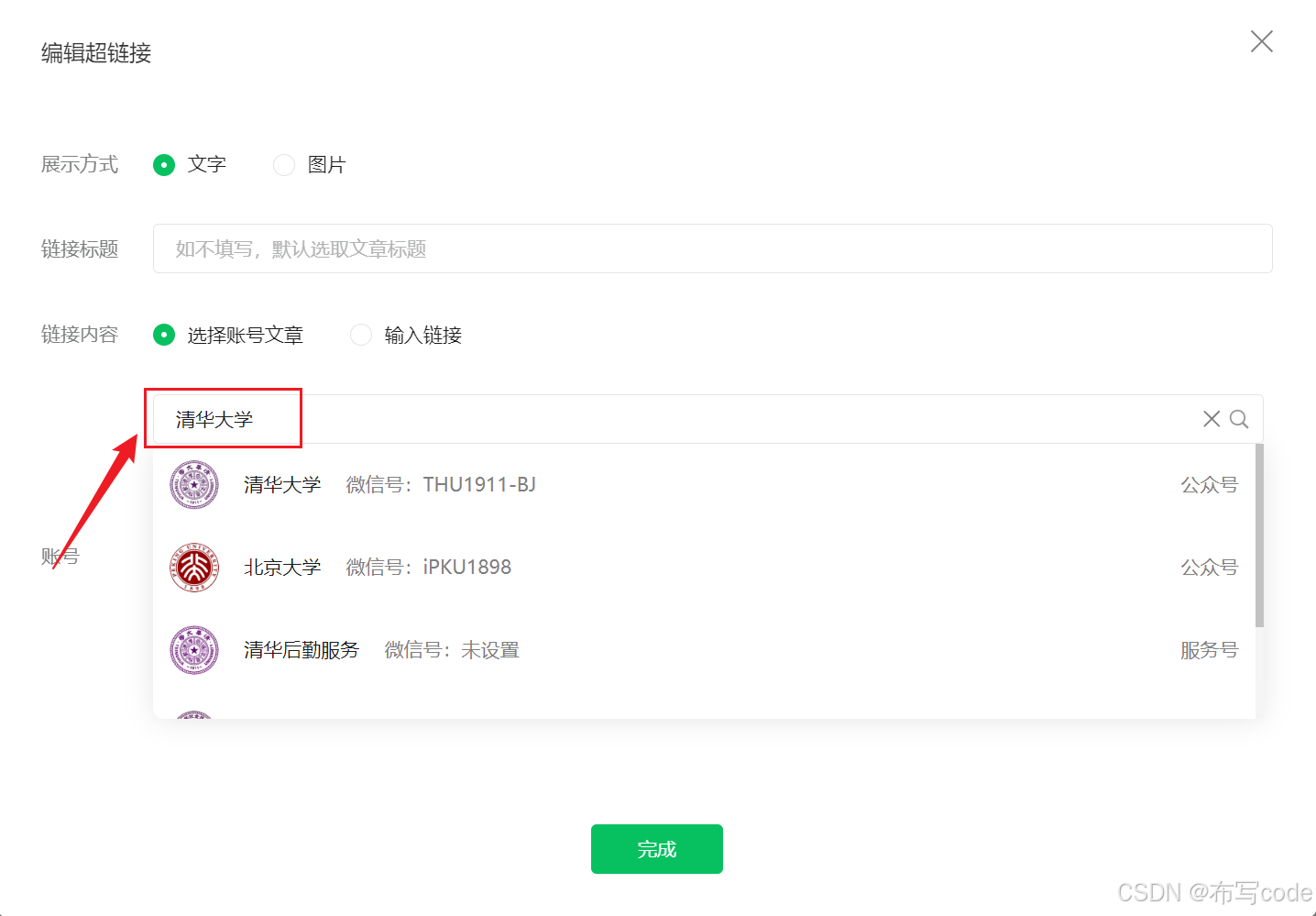
点击选择其他账号:

-
输入你想爬取的公众号名称,例如我们搜索清华大学:
-
鼠标右键检查代码,找到对应的网络,然后检索search
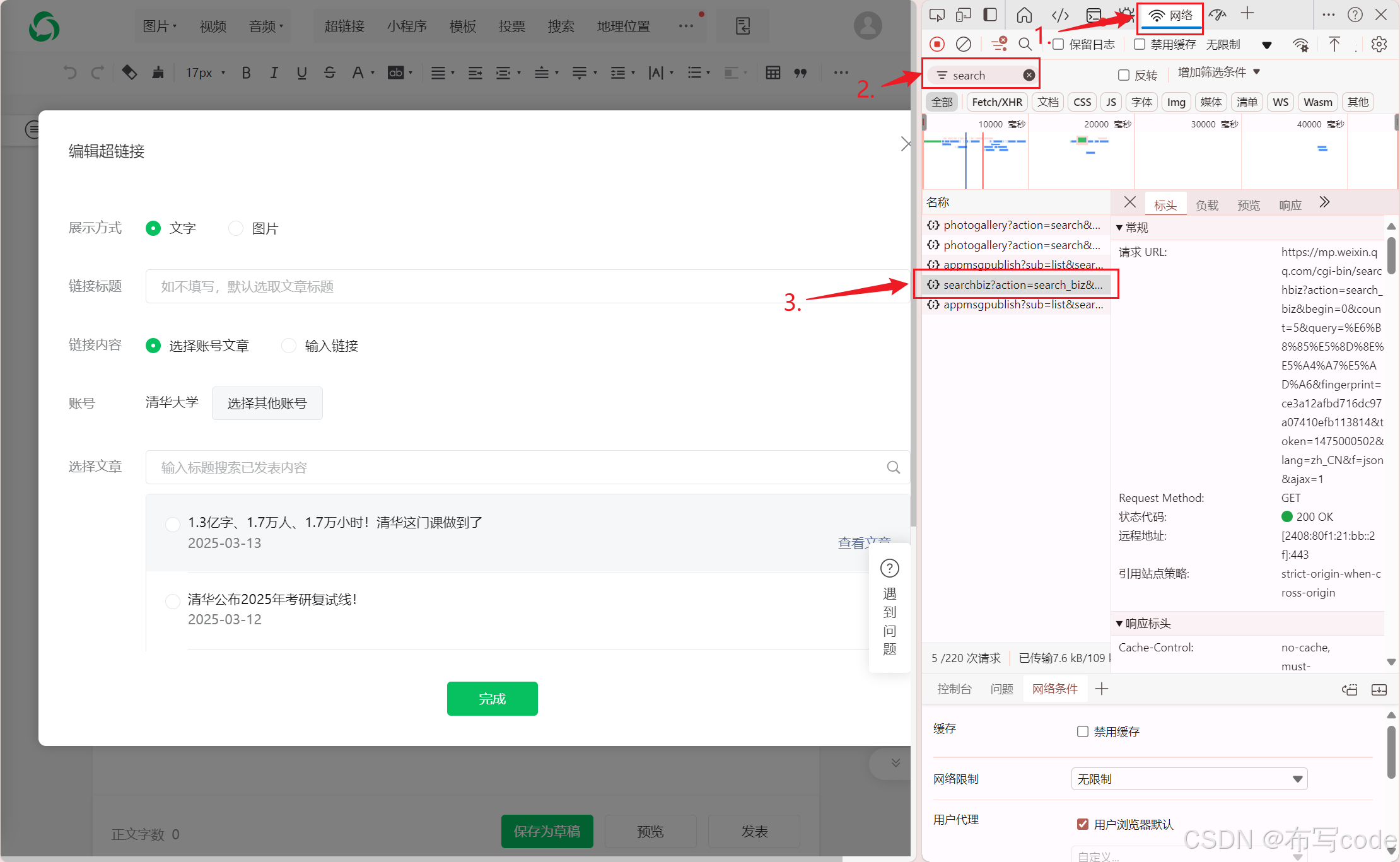
-
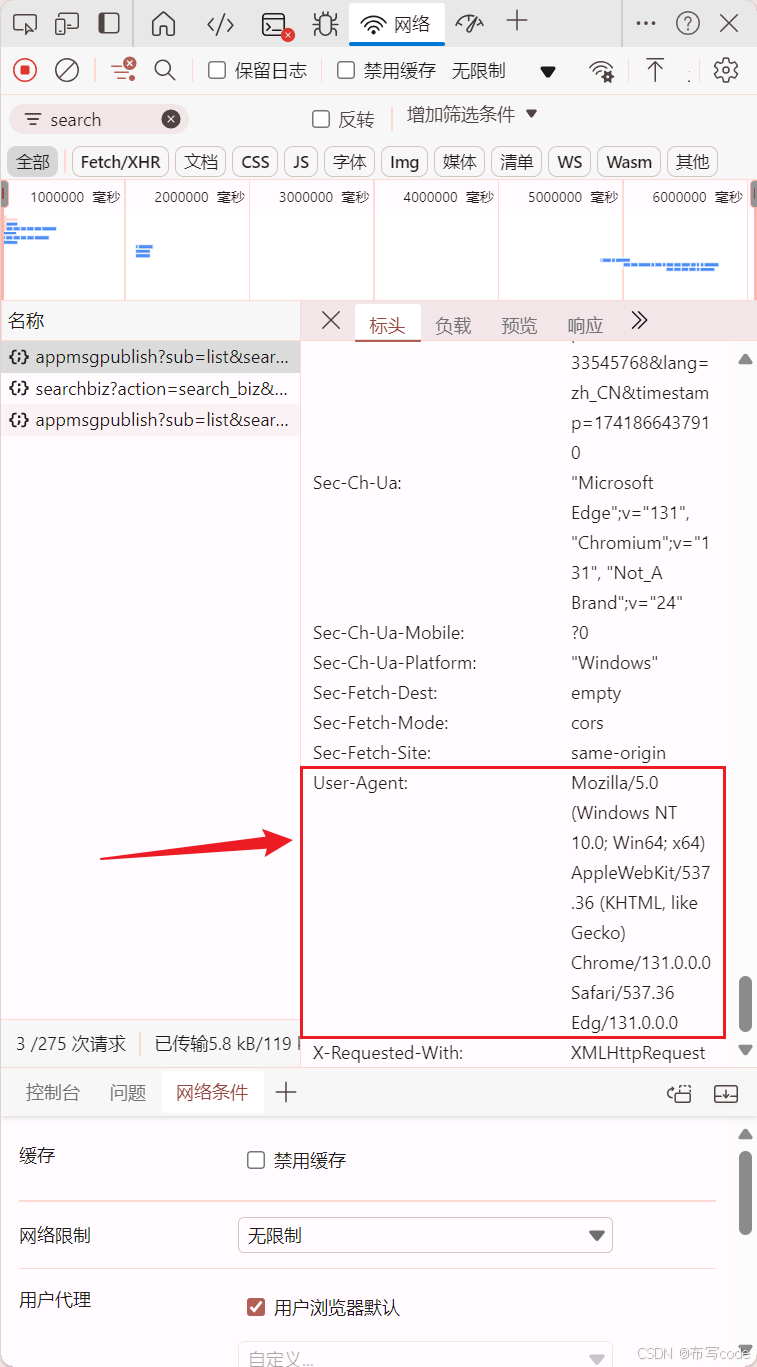
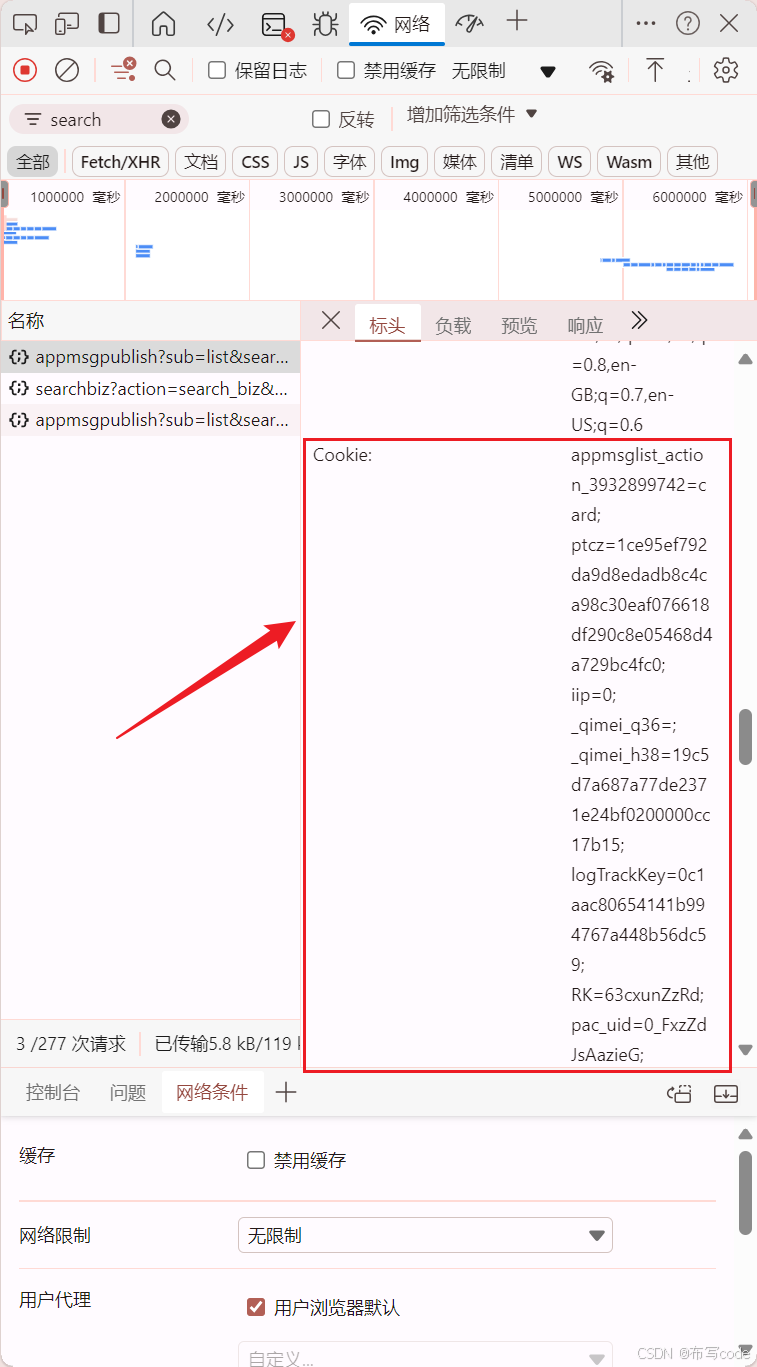
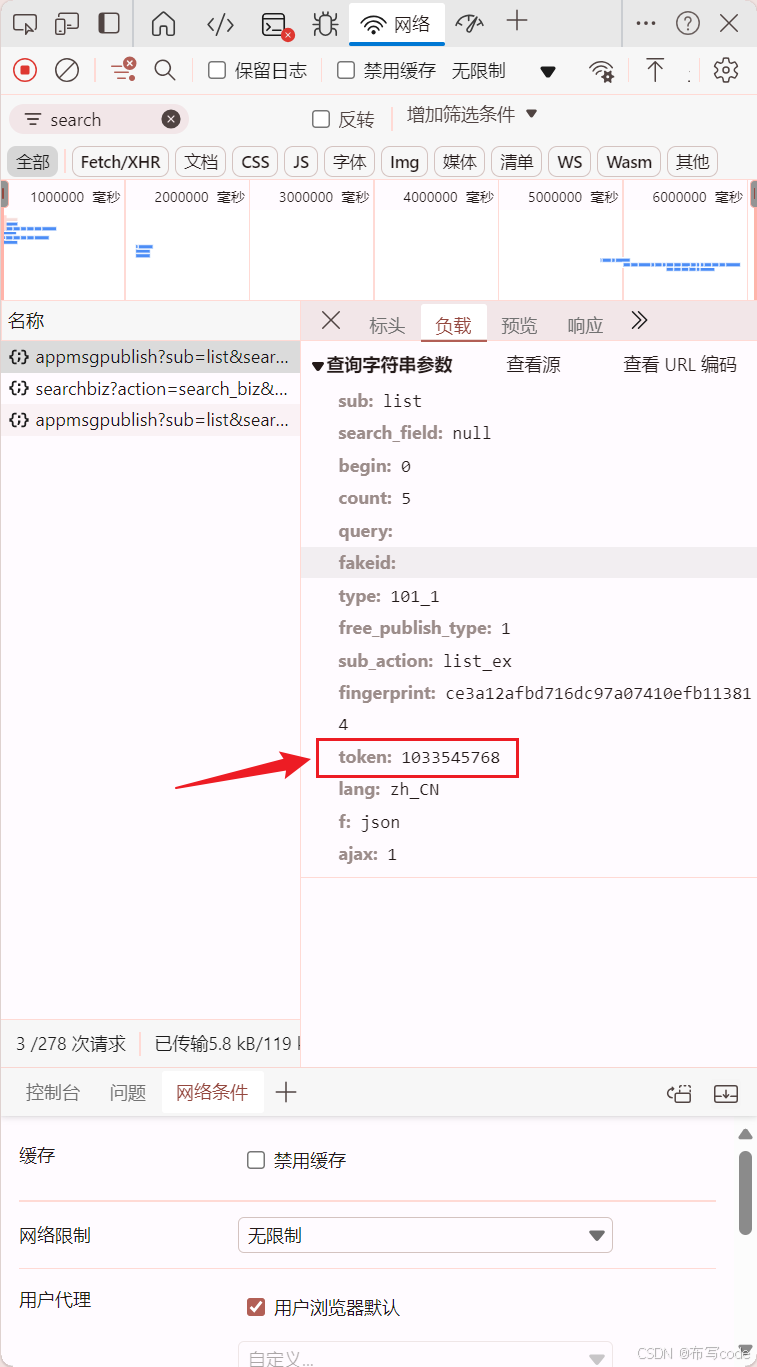
找到User-Agent、Cookie、token,之后在代码进行更换
代码模块
import traceback
import requests
import pandas as pd # 引入 pandas 处理数据
from pprint import pprint
# 创建 requests 会话
__session = requests.Session()
__headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36 Edg/131.0.0.0',
}
__params = {
"lang": "zh_CN",
"f": "json",
}
def get_fakeid(nickname):
"""获取微信公众号的 fakeid"""
search_url = "https://mp.weixin.qq.com/cgi-bin/searchbiz"
params = {
"action": "search_biz",
"query": nickname,
"begin": 0,
"count": 1,
"ajax": "1",
"lang": "zh_CN",
"f": "json",
"token": __params.get("token"),
}
try:
response = __session.get(search_url, headers=__headers, params=params)
response.raise_for_status()
data = response.json()
if "list" in data and data["list"]:
return data["list"][0].get('fakeid')
return None
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
return None
except Exception as e:
print(f"解析公众号 {nickname} 的 fakeid 失败: {traceback.format_exc()}")
return None
def get_all_articles(nickname, fakeid, max_pages=20):
"""自动翻页获取公众号的所有文章"""
if not fakeid:
print(f"无效的 fakeid,无法获取 {nickname} 文章。")
return []
art_url = "https://mp.weixin.qq.com/cgi-bin/appmsg"
begin = 0 # 从第 0 条开始
all_articles = []
page = 1 # 记录当前爬取的页数
while page <= max_pages:
params = {
"query": '',
"begin": begin,
"count": 20, # 每页尝试获取最多20篇
"type": 9,
"action": 'list_ex',
"fakeid": fakeid,
"lang": "zh_CN",
"f": "json",
"token": __params.get("token"),
}
try:
response = __session.get(art_url, headers=__headers, params=params)
response.raise_for_status()
msg_json = response.json()
if 'app_msg_list' not in msg_json or not msg_json['app_msg_list']:
print(f"第 {page} 页没有更多文章,爬取结束!")
break # 没有更多文章,跳出循环
# 解析文章信息,存入列表
for item in msg_json.get('app_msg_list', []):
all_articles.append({
"标题": item.get('title', ''),
"链接": item.get('link', ''),
"发布时间": item.get('update_time', ''),
})
print(f"已获取 {len(all_articles)} 篇文章,正在获取第 {page+1} 页...")
# 翻页
begin += len(msg_json['app_msg_list']) # 适配不同页数的文章数量
page += 1
except requests.exceptions.RequestException as e:
print(f"请求失败: {e}")
break
except Exception as e:
print(f"解析文章失败: {traceback.format_exc()}")
break
return all_articles
def save_to_excel(articles, filename="公众号文章.xlsx"):
"""保存文章数据为 Excel 文件"""
df = pd.DataFrame(articles)
df.to_excel(filename, index=False, engine="openpyxl") # ✅ 移除 encoding
print(f"✅ 文章数据已保存为 Excel 文件: {filename}")
def main():
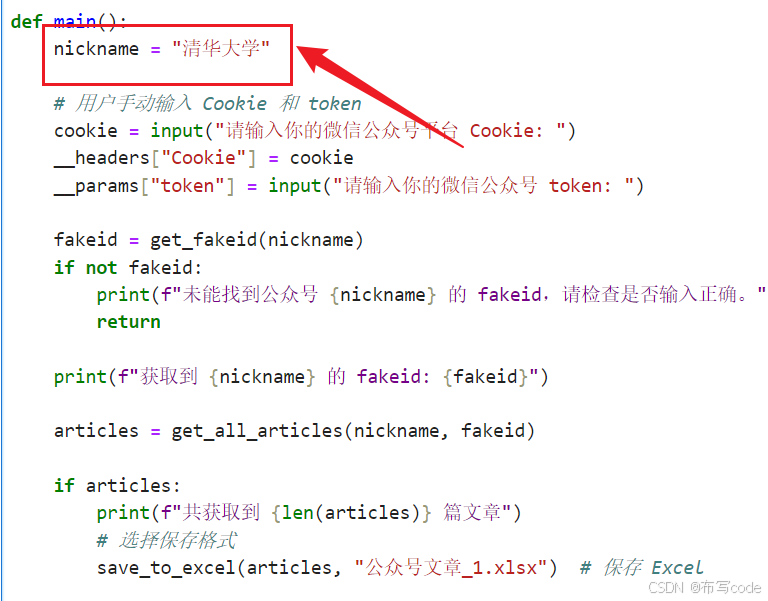
nickname = "清华大学"
# 用户手动输入 Cookie 和 token
cookie = input("请输入你的微信公众号平台 Cookie: ")
__headers["Cookie"] = cookie
__params["token"] = input("请输入你的微信公众号 token: ")
fakeid = get_fakeid(nickname)
if not fakeid:
print(f"未能找到公众号 {nickname} 的 fakeid,请检查是否输入正确。")
return
print(f"获取到 {nickname} 的 fakeid: {fakeid}")
articles = get_all_articles(nickname, fakeid)
if articles:
print(f"共获取到 {len(articles)} 篇文章")
# 选择保存格式
save_to_excel(articles, "公众号文章_1.xlsx") # 保存 Excel
if __name__ == '__main__':
main()
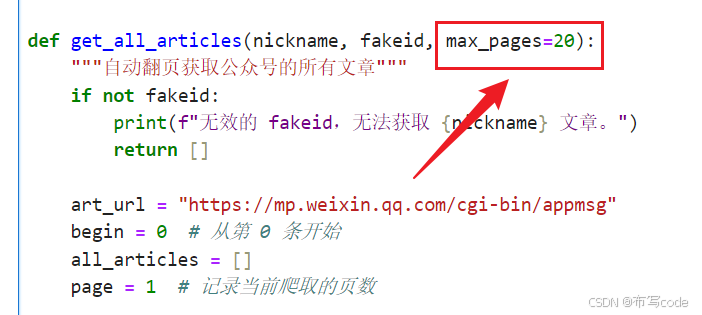
在这里只需要将User-Agent进行更改,将页数更改为想要爬取的页数,即可,在这里我只爬取了前20页。并将主函数中的公众号“清华大学”改为你想爬取的公众号。
运行代码
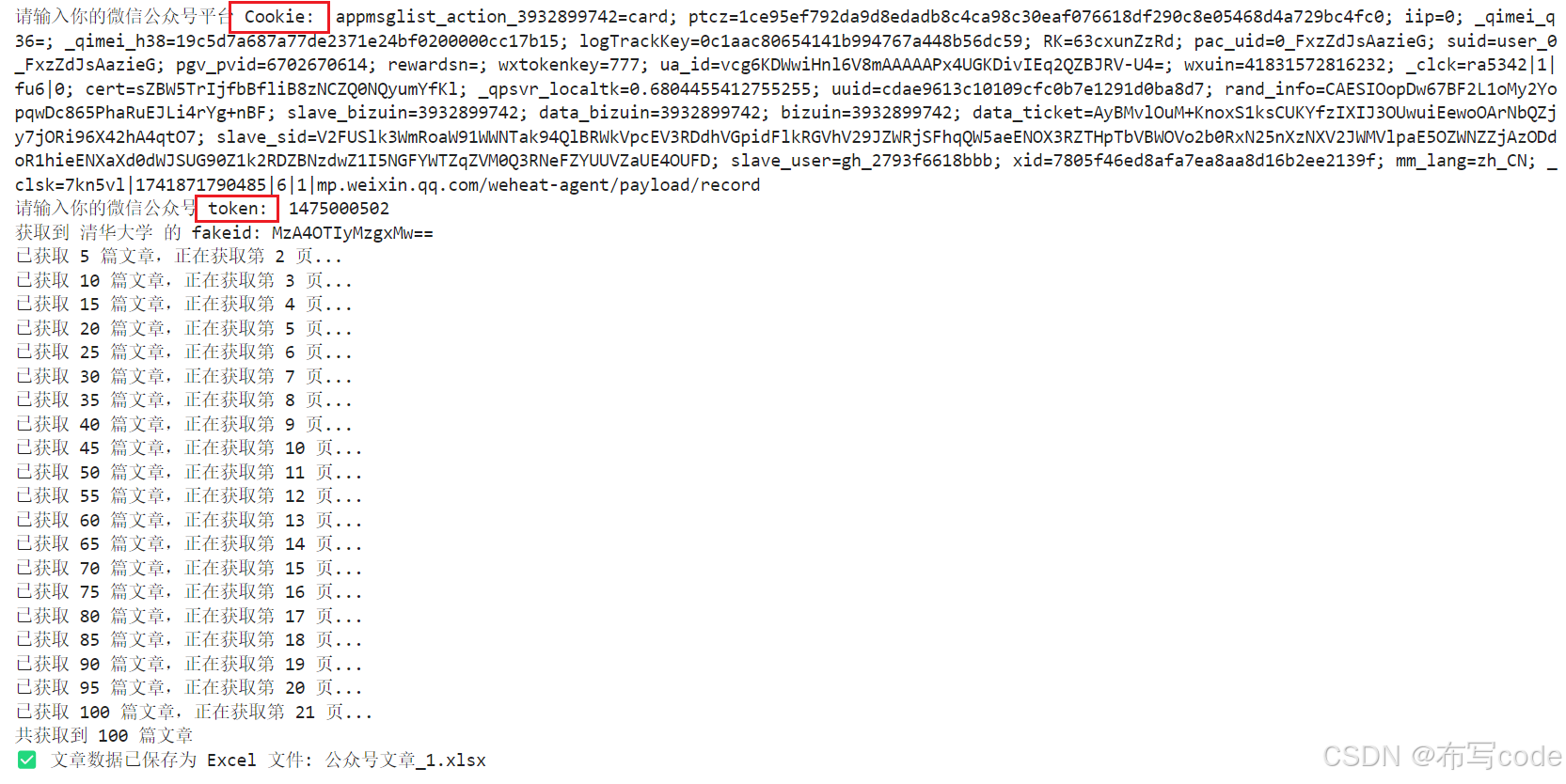
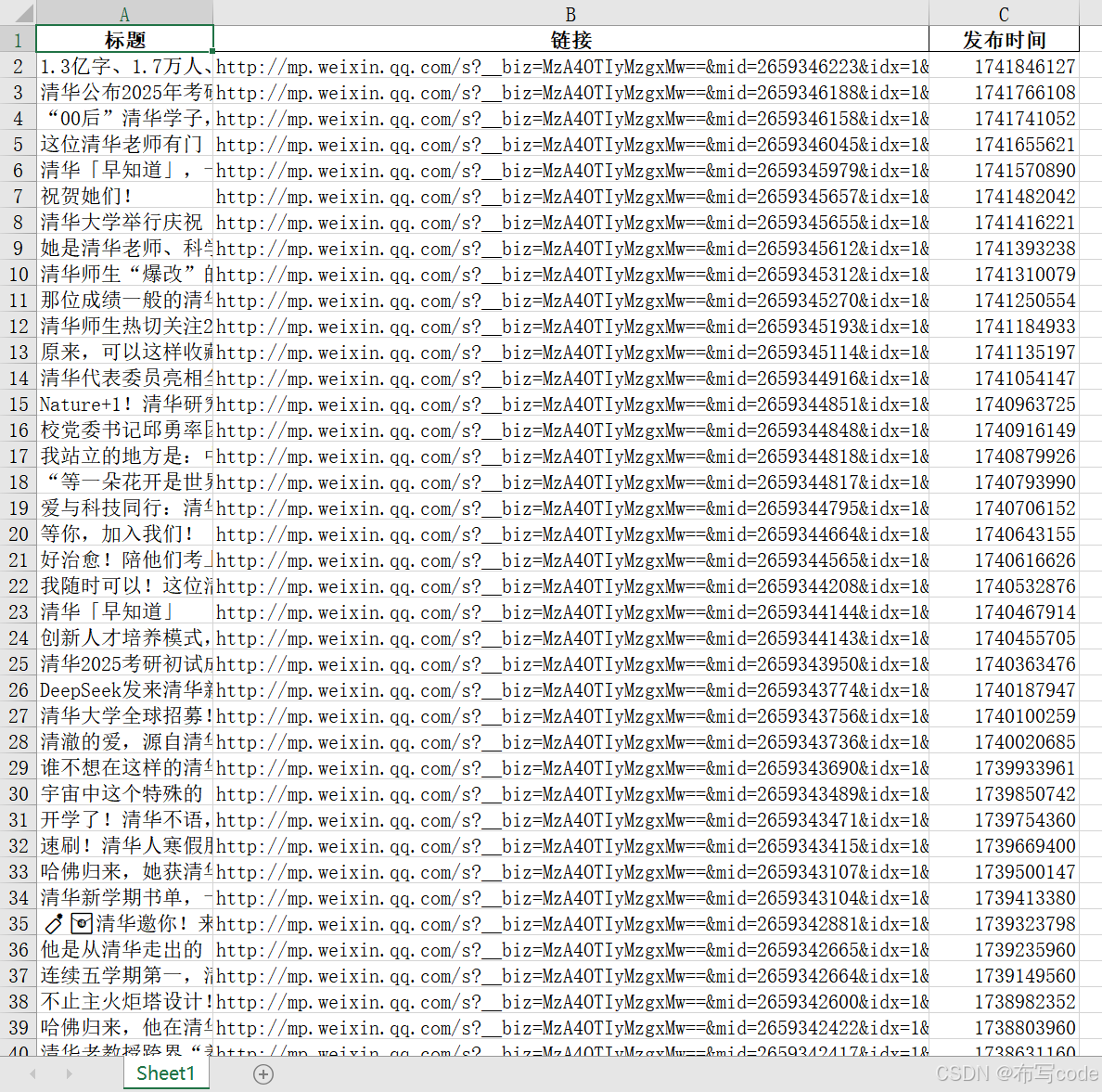
输入Cookie和token,即可得到"公众号文章_1"的excel,可以看到只有三列,并且链接不是超链接,发布时间也不是正常格式。
这个时候我们执行以下代码:
import pandas as pd
from openpyxl import load_workbook
from openpyxl.utils import get_column_letter
def add_hyperlinks_and_save_new(filename="公众号文章_1.xlsx", new_filename="公众号文章_2.xlsx"):
"""从现有 Excel 文件中读取数据,添加超链接列,转换时间格式,并保存到新文件"""
# 读取 Excel 数据
df = pd.read_excel(filename, engine="openpyxl")
# 确保表头符合预期
if "链接" not in df.columns or "发布时间" not in df.columns:
print("❌ Excel 文件格式错误,缺少 '链接' 或 '发布时间' 列!")
return
# 转换时间戳为日期格式
df["发布时间"] = pd.to_datetime(df["发布时间"], unit="s") # 转换时间格式
# 创建新的 Excel 并先存储时间格式转换
df.to_excel(new_filename, index=False, engine="openpyxl")
# 加载 Excel 文件,修改"链接"列为超链接
wb = load_workbook(new_filename)
ws = wb.active
for row in range(2, len(df) + 2): # 从第2行开始(表头在第1行)
link = df.iloc[row - 2]["链接"] # 获取原始链接
ws[f"B{row}"].value = f'=HYPERLINK("{link}", "点击查看")' # 变为超链接
# 自动调整列宽
for col in range(1, ws.max_column + 1):
col_letter = get_column_letter(col)
ws.column_dimensions[col_letter].width = 30 # 设定固定列宽
# 保存修改后的 Excel
wb.save(new_filename)
print(f"✅ 已成功生成新 Excel 文件: {new_filename}")
# ✅ 运行函数,不会覆盖原 Excel,而是生成一个新文件
add_hyperlinks_and_save_new("公众号文章_1.xlsx", "公众号文章_2.xlsx")
这样就重新得到了“公众号文章_2.xlsx”,并且链接也修改成超链接,时间更改成正常格式:

结束

















 4129
4129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









