






1.矩阵的形式
下面为一个矩阵的基本形式

1.“矩”的意思是矩形,由数字组成的矩形;
2.“阵”的意思是整齐,这些数字排列起来是非常整齐的,并不会歪歪扭扭;
3.矩阵中,横向的数字是行,竖向的数字是列,行和列都是整数,可以是1或者是n(n是整数);
4.矩阵中,通过“第几行、第几列”这种简便的方式来确定某个数字的具体位置。
2.矩阵的相关运算
矩阵+矩阵

常数×矩阵
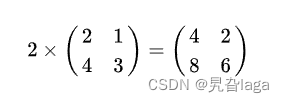
阵矩×矩阵
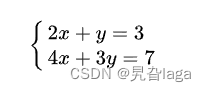
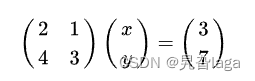
以下矩阵为例

y1 = a11 * x1 + a12 * x2
y2 = a21 * x1 + a22 * x2
方程组如下

要计算矩阵乘法,请将第一个矩阵行元素(或数字)乘以第二个矩阵列元素,然后计算其总和。
所以第一个矩阵的行数需要与第二个矩阵的列数对应
m×k的矩阵和k×n的矩阵相乘,结果就是得到一个m×n的矩阵
而三个矩阵甚至多个矩阵相乘也符合这个道理

先将前两个举着进行相乘,变成一个矩阵,如图所示

于是就变成了两个矩阵相乘
矩阵的转置
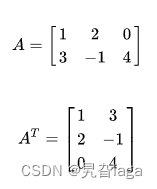
3.分解矩阵
矩阵分解,直观上来说就是把原来的大矩阵,近似分解成两个小矩阵的乘积,在实际推荐计算时不再使用大矩阵,而是使用分解得到的两个小矩阵。
import numpy as np
import math
import matplotlib.pyplot as plt
#定义矩阵分解函数
def Matrix_decomposition(R,P,Q,N,M,K,alpha=0.0002,beta=0.02):
Q = Q.T #Q 矩阵转置
loss_list = [] #存储每次迭代计算的 loss 值
for step in range(5000):
#更新 R^
for i in range(N):
for j in range(M):
if R[i][j] != 0:
#计算损失函数
error = R[i][j]
for k in range(K):
error -= P[i][k]*Q[k][j]
#优化 P,Q 矩阵的元素
for k in range(K):
P[i][k] = P[i][k] + alpha*(2*error*Q[k][j]-beta*P[i][k])
Q[k][j] = Q[k][j] + alpha*(2*error*P[i][k]-beta*Q[k][j])
loss = 0.0
#计算每一次迭代后的 loss 大小,就是原来 R 矩阵里面每个非缺失值跟预测值的平方损失
for i in range(N):
for j in range(M):
if R[i][j] != 0:
#计算 loss 公式加号的左边
data = 0
for k in range(K):
data = data + P[i][k]*Q[k][j]
loss = loss + math.pow(R[i][j]-data,2)
#得到完整 loss 值
for k in range(K):
loss = loss + beta/2*(P[i][k]*P[i][k]+Q[k][j]*Q[k][j])
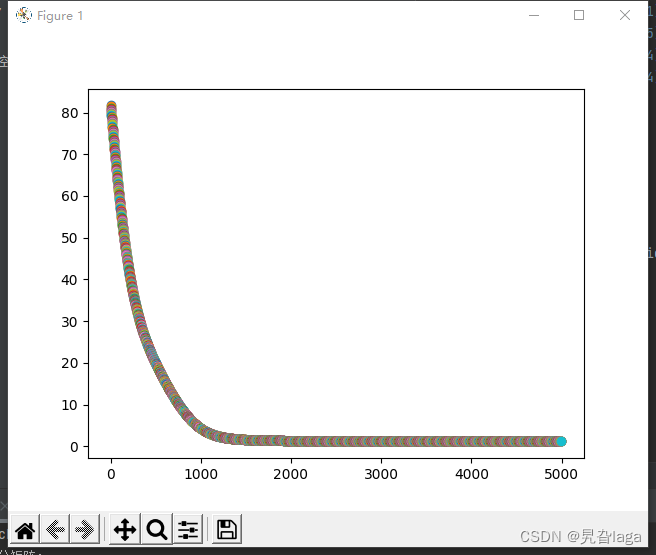
loss_list.append(loss)
plt.scatter(step,loss)
#输出 loss 值
if (step+1) % 1000 == 0:
print("loss={:}".format(loss))
#判断
if loss < 0.001:
print(loss)
break
plt.show()
return P,Q
if __name__ == "__main__":
N = 5
M = 4
K = 5
R = np.array([[5,3,0,1],
[4,0,0,1],
[1,1,0,5],
[1,0,0,4],
[0,1,5,4]]) #N=5,M=4
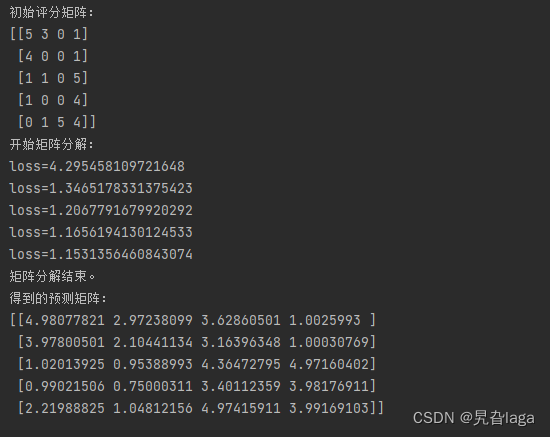
print("初始评分矩阵:")
print(R)
#定义 P 和 Q 矩阵
P = np.random.rand(N,K) #N=5,K=2
Q = np.random.rand(M,K) #M=4,K=2
print("开始矩阵分解:")
P,Q = Matrix_decomposition(R,P,Q,N,M,K)
print("矩阵分解结束。")
print("得到的预测矩阵:")
print(np.dot(P,Q))
运行结果为:















 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









