







(记录学习第八天)
1、PDF文档
安装模块,最好是这个版本的
pip install PyPDF2==1.26.01.1提取文本
meetingminutes.pdf的内容是英文的,运用如下代码可以输出
import PyPDF2
pdfFileObj = open('meetingminutes.pdf', 'rb')
pdfReader = PyPDF2.PdfFileReader(pdfFileObj)
print(pdfReader.numPages)
pageObj = pdfReader.getPage(0)
print(pageObj.extractText())
pdfFileObj.close()但是,如果内容是中文的,这个代码就不行了
需要用另一个代码
import pdfplumber
pdfFileObj = pdfplumber.open('文章.pdf')
pdf_reader = pdfFileObj.pages[0]
text = pdf_reader.extract_text()
pdfFileObj.close()
print(text)'r':表示只读模式,用于读取文件的内容。'b':表示二进制模式,用于处理二进制文件
输出结果
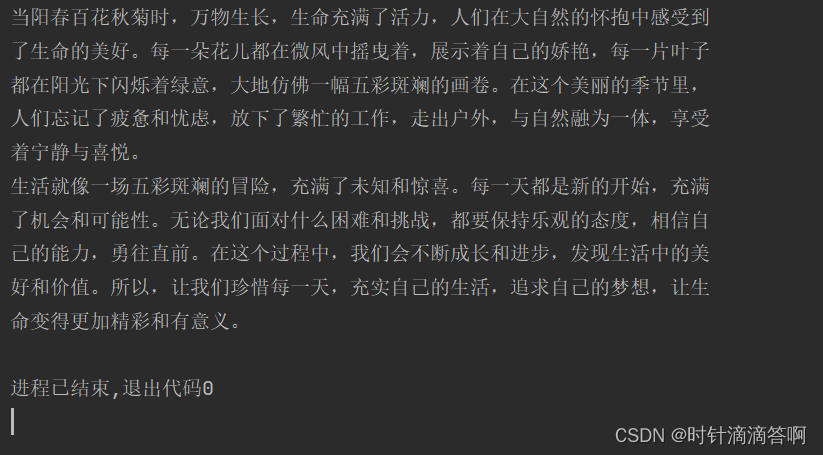
后面的我们以英文为例
1.2解密PDF
isEncrypted属性用来判断是否是加密的
decrypt()函数用来传入口令字符串
import PyPDF2
pdfReader = PyPDF2.PdfFileReader(open('encrypted.pdf', 'rb'))
print(pdfReader.isEncrypted)#判断是否是加密的,如果是,返回True
pdfReader.decrypt('rosebud')#输入密码
print(pdfReader.getPage(0))#如果在输入密码前输出这行,会报错1.3创建PDF
PyPDF2不能将任意文本写入PDF
仅限于从其他PDF中复制页面、旋转页面、重叠页面和加密文件
以复制页面为例:
import PyPDF2
pdf1File = open('meetingminutes.pdf', 'rb') # 打开第一个PDF文件
pdf2File = open('meetingminutes2.pdf', 'rb') # 打开第二个PDF文件
pdf1Reader = PyPDF2.PdfFileReader(pdf1File)
pdf2Reader = PyPDF2.PdfFileReader(pdf2File)
pdfWriter = PyPDF2.PdfFileWriter()
# 将第一个PDF文件的页面添加到PdfFileWriter
for pageNum in range(pdf1Reader.numPages):
pageObj = pdf1Reader.getPage(pageNum)
pdfWriter.addPage(pageObj)
# 将第二个PDF文件的页面添加到PdfFileWriter
for pageNum in range(pdf2Reader.numPages):
pageObj = pdf2Reader.getPage(pageNum)
pdfWriter.addPage(pageObj)
# 创建一个新的PDF文件并保存合并后的内容
mergedPdfFile = open('merged.pdf', 'wb')
pdfWriter.write(mergedPdfFile)
# 关闭文件
pdf1File.close()
pdf2File.close()
mergedPdfFile.close()














 136
136











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









