







1.引言
一个国家有若干个州,统计连续三天的新冠情况和戴口罩情况,居家办公情况等特征。现在有前两天的情况,要求估计第三天的情况。现有训练集covid.train.csv,测试集covid.test.csv。
2.模型框架
a.数据类(Data):数据集应包含训练集,测试集和验证集。理论上,训练集和验证集为同一文档。
b.模型类(Model):模型类定义了神经网络框架模型,并引入激活函数,构建全连接网络。
c.超参数定义:如学习率、优化器、损失函数等。
3.代码
1>相关包
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
import csv
import numpy as np
import time
import matplotlib.pyplot as plt
import pandas as pd
from torch import optim
import torch.nn as nn
import torch
from torch.utils.data import Dataset,DataLoader2>数据类
数据类包含三个函数:__init__()、__getitem__()、__len__()。其中,初始化函数用于根据判断是训练集、测试集、验证集得出所需要的数据;__getite__()在取值时会被自动调用;__len__()函数用于取得数据集的长度。
class covidDataset(Dataset):
def __init__(self, file_path, mode, dim=4, all_feature=False):
with open(file_path, "r") as f:
#打开文件操作与V语言类似
csv_data = list(csv.reader(f))
#应该转化为矩阵形式,第一行数据为标签,应该略过
data = np.array(csv_data[1:])
if mode == "train":
indices = [i for i in range(len(data)) if i % 5 !=0]
elif mode == "val":
indices = [i for i in range(len(data)) if i % 5 ==0]
#是否选择考虑全部特征,若是,则所有列都要选择;反之根据优化算法选择最重要的列
if all_feature:
col_idx = [i for i in range(0,93)]
else:
_, col_idx = get_feature_importance(data[:,1:-1], data[:,-1], k=dim,column =csv_data[0][1:-1])
if mode == "test":
#测试集没有标签,直接取所有行,但第一列id无关紧要,应省略。
#数据应转化为float类型
x = data[:, 1:].astype(float)
#将选中的列的数据作为测试内容,并转化为张量
x = torch.tensor(x[:, col_idx])
else:
#不是测试集,则输入输出都要得到,一般输入x是一个矩阵,输出y是一个向量
x = data[indices, 1:-1].astype(float)
x = torch.tensor(x[:, col_idx])
y = data[indices, -1].astype(float)
只有使用self才能在这个方法内部使用这里定义的x, y
self.y = torch.tensor(y)
"""
mean表示求均值,std表示求方差。dim=0表示在行维度进行求均制/方差,keepdim=True表示不 打乱图形
我们需要对同一列不同行的数据归一化。即减去平均制比上标准差
"""
self.x = (x-x.mean(dim=0,keepdim=True))/x.std(dim=0,keepdim=True)
self.mode = mode
#给定一个下标,返回一个值
def __getitem__(self, item):
if self.mode == "test":
#测试集只有输入,返回一个值
return self.x[item].float()
else:
#非测试集,既有输出又有输出,返回两个
return self.x[item].float(), self.y[item].float()
#返回数据长度
def __len__(self):
return len(self.x) 3>模型类
全连接网络的模型在这里定义。__init__()函数中定义了神经网络的方法、激活函数与参数等内容。forward函数利用之前定义的方法来实现前向过程。
# 通过继承nn.Module类,可以使用其提供的函数构建自己的神经网络模型
class myNet(nn.Module):
#初始化函数需要定义维度,例如inDim=93则nn.Linear就会生成93*128的模型,同时需要遵守矩阵乘法的规则
def __init__(self, inDim):
#必须调用父类的构造函数,因为想要使用父类的方法,这也是继承Module的目的
#同时,初始化也仅仅是设计模型架构,并没有让数据通过
super(myNet,self).__init__()
#nn.Linear用于设置网络中的全连接层
self.fc1 = nn.Linear(inDim, 128)
#relu激活函数
self.relu = nn.ReLU()
# self.fc3 = nn.Linear(128, 128)
self.fc2 = nn.Linear(128,1)
#前向过程
def forward(self, x):
x = self.fc1(x)
x = self.relu(x)
# x = self.fc3(x)
x = self.fc2(x)
if len(x.size()) > 1:
return x.squeeze(1)
else:
return x注意:为什么要用squeeze函数。例如y为32*1的张量,每一个数据都包含了一个[],形如:[[1], [2], [3], [4], ......, [32]]。squeeze(1)表示去掉一维,最后得到的结果为[1, 2, 3, 4, ..., 32]
4.训练
1>相关数据函数
#判断在gpu还是cpu上执行
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print(device)
#选择训练集、测试集文件
train_path = 'covid.train.csv'
test_path = 'covid.test.csv'
file = pd.read_csv(train_path)
#用pandas查看数据长什么样
file.head()
#是否使用所有的列,默认只选择重要的列
all_col = False
if all_col == True:
feature_dim = 93
else:
feature_dim = 6
#训练集,验证集,测试集定义
trainset = covidDataset(train_path, 'train', feature_dim, all_feature=all_col)
valset = covidDataset(train_path, 'val', feature_dim, all_feature=all_col)
testset = covidDataset(test_path, 'test', feature_dim, all_feature=all_col)
loss = nn.MSELoss()
"""
相比于上一章节,torch包提供了MSELoss计算损失值,这里loss是一个方法
比如loss = loss(input, target) 表示input与target两个张量的平方差的均值
"""
#设置字典,超参数都存放在其中
config = {
'n_epochs': 50, #训练轮数。所有模型训练一次叫做一个epoch
'batch_size': 32, #一个模型又分为很多个batch,一批处理32个数据
'lr': 0.0001, #学习率,即每次参数更新时的步长
'momentum': 0.9, #动量,用来加速模型收敛速度,避免模型陷入局部最优解
'early_stop': 200,
'save_path': 'model_save/model.pth', #训练的最好的那个模型保存地址
}
#实例化模型,放在之前约定的设备上(cpu/gpu)
model = myNet(feature_dim).to(device)
optimizer = optim.SGD(model.parameters(), lr=0.001, momentum=0.9)
"""
optim.SGD()是pytorch中的随机梯度下降优化器
可以调整神经网络中的参数以最小化损失函数
它的基本思想是,在每次迭代中,每个参数都会沿着梯度的反方向移动一小步,以期望最小化损失函数
model.parameters()表示需要更新的参数,lr为学习率,momentum为动量
注意:必须借助动量才能跳过局部最优(极小值点),找到全局最优点(最小值点)。动量有点类似惯性
"""
#将数据装入loader方便取一个batch的数据
#DataLoader类似上一章节的data_provider,把数据集分为若干批。遍历输出trainloader的每一组数据x, y,一组由batch_size*feature_dim的矩阵x和batch_size维的向量y组成。shuffle=True意味着顺序打乱
trainloader = DataLoader(trainset, batch_size=config['batch_size'], shuffle=True)
valloader = DataLoader(valset, batch_size=config['batch_size'], shuffle=True)
#训练
train_val(model, trainloader, valloader, optimizer, loss, config['n_epochs'], device, save_path=config['save_path'])2>训练代码
训练->验证
def train_val(model, trainloader, valloader, optimizer, loss, epoch, device, save_path):
#把模型放在约定的设备上,gpu/cpu。gpu更快
model = model.to(device)
#训练集,测试集,验证集的损失值存放在以下列表中
plt_train_loss = []
plt_val_loss = []
val_rel = []
#记录训练验证loss 以及验证loss和结果
min_val_loss = 100000
#训练epoch轮
for i in range(epoch):
start_time = time.time()
#模型设置为训练状态,当模型足够复杂时,不同状态下的功能不一定相同
model.train()
#每一轮初始化损失值,然后开始累加
train_loss = 0.0
val_loss = 0.0
#从训练集中取出一批数据
for data in trainloader:
optimizer.zero_grad() #梯度清0
"""
根据pytorch中的backward()函数的计算,当网络参量进行反馈时,梯度是被积累的而不是被替换掉。
但是在每一个batch时毫无疑问并不需要将两个batch的梯度混合起来累积
因此这里就需要每个batch设置一遍zero_grad
"""
#将数据放到设备上,data[0]表示矩阵张量x,data[1]表示向量张量target
x, target = data[0].to(device), data[1].to(device)
#前向过程,这里会调用forward方法
pred = model(x)
#求出目标值y与前向过程所求的y_hat的平方差均值
bat_loss = loss(pred, target)
#反向传播
bat_loss.backward() #梯度回传,反向传播,得到每一个要更新的参数的梯度
optimizer.step() #用优化器更新模型,轮到SGD出手
"""
bat_loss是一个张量且存放在gpu上,而train_loss是一个数
所以需要将其取到cpu上因为不计算就不要放在gpu上占用资源了,并通过item()使其成为数值
detach()函数是将该值从张量上取下来,不要计算梯度
"""
train_loss += bat_loss.detach().cpu().item()
#记录loss到列表,注意是平均的loss,因此要除以数据集长度
plt_train_loss.append(train_loss/trainloader.dataset.__len__())
#模型设置为验证状态
model.eval()
#只要数据通过模型,就会积攒梯度。而验证集中,模型不能计算梯度。所以需要这条代码
with torch.no_grad():
#从验证集中取出一个batch的数据
for data in valloader:
#同理训练集,将数据放在约定设备上
val_x, val_target = data[0].to(device), data[1].to(device)
val_pred = model(val_x) #用模型预测数据
val_bat_loss = loss(val_pred, val_target) #同理训练集,计算loss
val_loss += val_bat_loss.detach().cpu().item()
val_rel.append(val_pred) #记录预测结果到列表
if val_loss < min_val_loss:
torch.save(model, save_path) #如果loss比之前更小,说明模型更优,取而代之
plt_val_loss.append(val_loss/valloader.dataset.__len__()) #记录平均loss到列表
#打印训练结果
print('[%03d/%03d] %2.2f sec(s) TrainLoss: %.6f | ValLoss: %.6f' %(i, epoch, time.time()-start_time, plt_train_loss[-1], plt_val_loss[-1]))
#画图
plt.plot(plt_train_loss) #向图中放入训练loss数据
plt.plot(plt_val_loss) #向图中放入验证loss数据
plt.title('loss') #标题
plt.legend(['train', 'val']) #图例
plt.show() #展示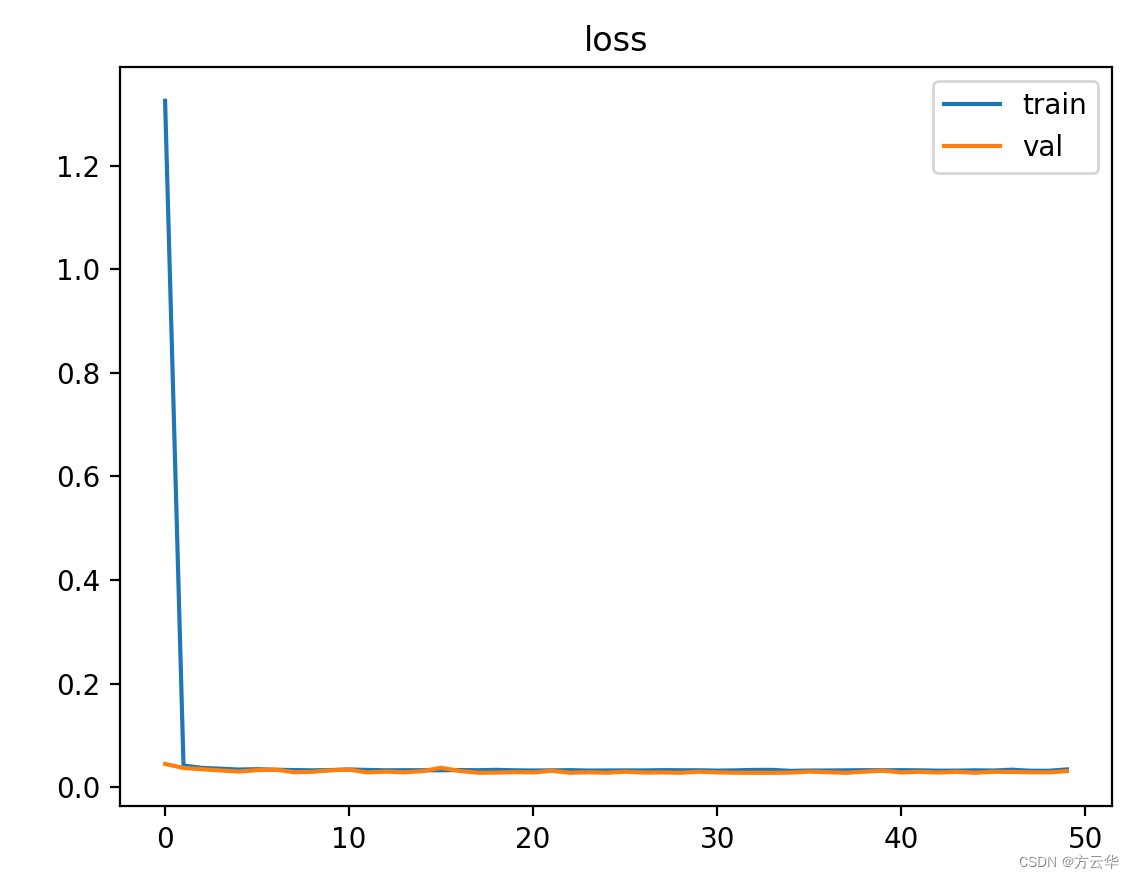
5.测试
万事俱备,只欠东风
#用测试集测试
def evaluate(model_path, testset, rel_path, device):
#模型放在设备上,加载模型
model = torch.load(model_path).to(device)
#测试集数据不可打乱,且一次只能取一个
testloader = DataLoader(testset, batch_size=1, shuffle=False)
val_rel = []
#模式设置为验证状态
model.eval()
#测试模型不再计算梯度
with torch.no_grad():
#从测试集取一个batch的数据。因为test模式下__getitem__()函数只返回一个值,所以只需要一个data来接
for data in testloader:
x = data.to(device)
pred = model(x)
val_rel.append(pred.item())
print(val_rel)
#打开保存的文件
with open(rel_path, 'w') as f:
#初始化一个写文件器writer
csv_writer = csv.writer(f)
#第一行写'id'和'tested_positive'
csv_writer.writerow(['id', 'tested_positive'])
for i in range(len(testset)):
#写在文件里面,肯定是字符串形式
#把测试集每一行放入输出的excel表中
csv_writer.writerow([str(i), str(val_rel[i])])
print("rel已经保存到"+rel_path)#验证
evaluate(config['save_path'], testset, 'pred.csv', device)最终pred.csv的文档中,记录了每一行的预测值:
6.优化
通过相关系数值筛选出最重要的列,从而不必将所有数据投入运算,具体代码如下。
#这个函数理解即可,可以直接复制
#相关系数优化
def get_feature_importance(feature_data, label_data, k=4, column=None):
"""
feature_data与label_data要求字符串形式
k为选择的特征数量
如果需要打印column,需要传入行名
此处省略feature_data,label_data的生成代码
如果是CSV文件,可以通过read_csv()函数,获得特征和标签
这个函数的目的是,找到所有特征值,比较有用的k个特征,并打印这些列的名字
"""
model = SelectKBest(chi2, k=k) #定义一个选择k个最佳特征的函数-model
X_new = model.fit_transform(feature_data, label_data) #用这个函数选择k个最佳特征
#feature_data是特征数据,label_data是标签数据,该函数可以选择出k个特征
# print('x_new', X_new)
scores = model.scores_ #scores即每一列与结果的相关性,即得到了每一列的相关系数
#按相关系数由大到小排序,选出最重要的k个
indices = np.argsort(scores)[::-1]
"""
argsort()这个函数,用于将一个数组从小到大排序,得出的结果是这个数组的下标数组。
比如indices[0]表示的是,scores中最小值的下标。
[::-1]表示反转一个列表或者矩阵。
比如indices = [1, 2, 3, 4, 5],则argsort后得到的则是[0, 1, 2, 3, 4],再[::-1]后得到的便是[4, 3, 2, 1, 0]
简要来说,argsort以数组数值为参考排序,返回的是对应下标的数组
"""
if column:
k_best_features = [column[i] for i in indices[0:k].tolist()] #选中这些重要的列,转化为列表并打印
# print('k best features are: ', k_best_features)
return X_new, indices[0:k] #返回选中列的特征和他们的下标














 985
985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









