






JVM:垃圾收集器
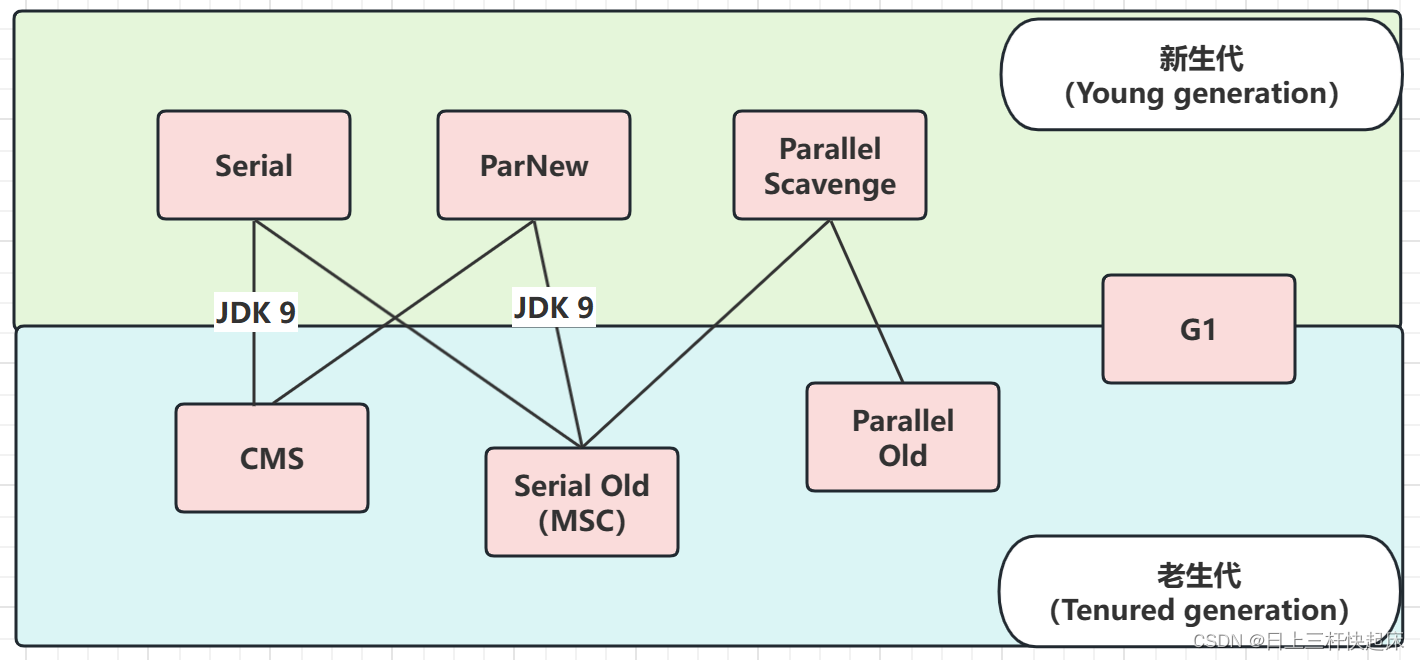
一、垃圾收集器关系图
(Young generation) 新生代:Serial、ParNew、Parallel Scavenge
(Tenured generation) 老年代:Serial Old、Parallel Old、CMS、G1
搭配关系:若两个收集器之间存在连线,则可搭配使用。
二、各垃圾收集器详解
1. Serial收集器
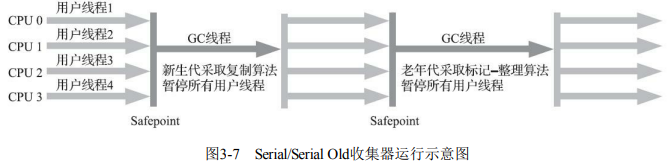
- 特点:最基础、历史最悠久的单线程新生代收集器,垃圾收集时需暂停所有工作线程(Stop The World)。
- 算法:
- 新生代:复制算法
- 老年代:标记-整理算法(搭配Serial Old时)
- 优势:
- 简单高效,额外内存消耗最小,适合客户端模式或内存受限环境(如几十兆~几百兆新生代)。
- 单线程无线程交互开销,单核/少核心处理器下效率高。
- 应用场景:客户端默认新生代收集器,桌面应用或小型程序。
2. ParNew收集器
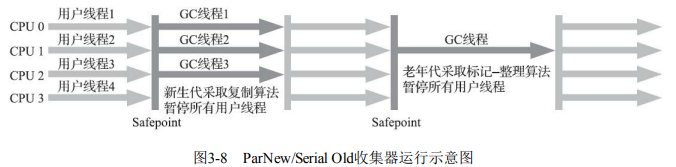
- 特点:Serial收集器的多线程并行版本,除并行收集外,其余行为(参数、算法、回收策略)与Serial完全一致。
- 算法:新生代复制算法,暂停所有用户线程。
- 地位:
- 早期唯一可与CMS收集器配合的新生代收集器,奠定其服务端地位。
- 随G1兴起逐渐被取代,JDK 9后仅与CMS搭配使用,可视为CMS的新生代处理模块。
- 缺点:单核心环境效率可能低于Serial,线程交互有额外开销。
3. Parallel Scavenge收集器

- 特点:新生代并行收集器,基于标记-复制算法,专注于 可控吞吐量(吞吐量=运行用户代码时间 /(运行用户代码时间+GC时间))。
- 核心参数:
-XX:MaxGCPauseMillis:控制最大GC停顿时间(牺牲吞吐量换取低延迟)。-XX:GCTimeRatio:直接设置GC时间占比(如19表示GC时间≤5%)。
- 优势:自适应调节策略(
-XX:+UseAdaptiveSizePolicy),自动优化新生代参数,减少手工调优。 - 适用场景:后台计算任务,优先高效利用CPU资源,无需频繁交互。
4. Serial Old收集器
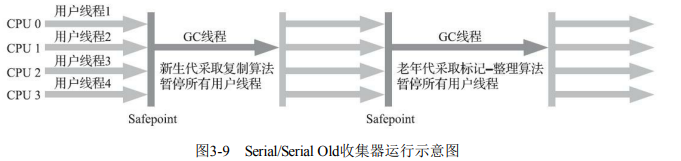
- 特点:Serial收集器的老年代版本,单线程,基于标记-整理算法。
- 应用场景:
- 客户端模式默认老年代收集器。
- 服务端:JDK 5及以前与Parallel Scavenge搭配;作为CMS收集器失败时的后备预案(Concurrent Mode Failure时触发)。
- 缺点:单线程效率低,大内存环境下停顿时间长。
5. Parallel Old收集器
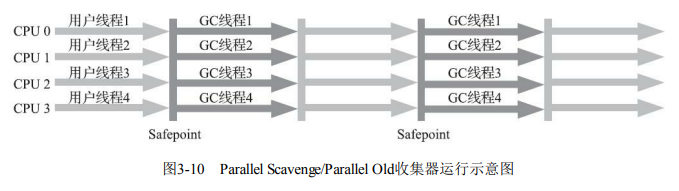
- 特点:Parallel Scavenge的老年代版本,多线程并发收集,标记-整理算法,JDK 6后引入。
- 优势:与Parallel Scavenge组成“吞吐量优先”组合,充分利用多核处理器,减少老年代GC停顿。
- 适用场景:注重吞吐量或处理器资源稀缺的服务端应用,如批量数据处理。
6. CMS收集器(Concurrent Mark Sweep)
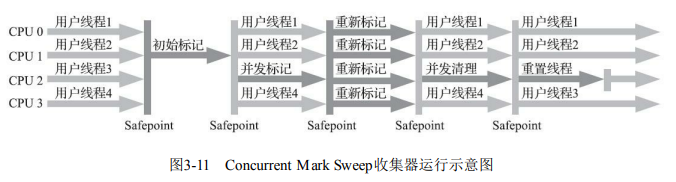
- 特点:老年代收集器,目标是最短回收停顿时间,基于标记-清除算法,首次实现垃圾收集线程与用户线程并发执行。
- 工作阶段:
- 初始标记:标记GC Roots直接关联对象(STW,耗时短)。
- 并发标记:遍历对象图(与用户线程并发,增量更新处理引用变化)。
- 重新标记:修正并发标记期间变动的引用(STW,耗时较初始标记长)。
- 并发清除:清理死亡对象(与用户线程并发)。
- 缺点:
- CPU敏感:默认线程数=(核心数+3)/4,低核心环境下占用过多CPU资源。
- 空间碎片:标记-清除算法导致碎片,大对象分配可能触发Full GC。
- 浮动垃圾:并发阶段产生的垃圾无法处理,需预留内存,可能引发Concurrent Mode Failure。
- 适用场景:高交互应用(如Web服务),追求低延迟响应。
7. G1收集器(Garbage First)
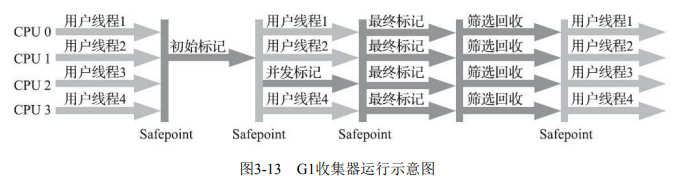
- 特点:面向服务端的“停顿时间模型”收集器,基于Region分区,优先回收垃圾最多的Region(Garbage First),支持混合回收(Mixed GC)。
- 内存布局:将堆划分为多个大小相等的Region,动态扮演Eden、Survivor、Old或Humongous(大对象)区域。
- 工作阶段:
- 初始标记:标记GC Roots直接关联对象(STW,短暂)。
- 并发标记:可达性分析(与用户线程并发,SATB算法记录引用变动)。
- 最终标记:处理剩余SATB记录(STW,短暂)。
- 筛选回收:按回收价值排序Region,并行复制存活对象到空Region(STW,可控制停顿时间)。
- 优势:
- 可通过
-XX:MaxGCPauseMillis设定目标停顿时间(默认200ms),平衡吞吐量与延迟。 - 标记-整理+复制算法,无内存碎片,适合大内存环境。
- 可通过
- 缺点:内存占用较高(Region元数据、记忆集开销),小内存场景效率低于CMS。
- 适用场景:大内存(6GB+)、追求可控停顿时间的服务端应用,如微服务、分布式系统。
三、总结
| 收集器 | 类型 | 算法 | 核心目标 | 适用场景 | 关键参数 |
|---|---|---|---|---|---|
| Serial | 新生代 | 复制+标记-整理 | 简单高效 | 客户端、小内存环境 | -XX:+UseSerialGC |
| ParNew | 新生代 | 复制算法 | 多线程并行 | 配合CMS的服务端早期组合 | -XX:+UseParNewGC |
| Parallel Scavenge | 新生代 | 复制算法 | 高吞吐量 | 后台计算任务 | -XX:MaxGCPauseMillis |
| Serial Old | 老年代 | 标记-整理 | 单线程兼容 | 客户端、CMS后备预案 | -XX:+UseSerialOldGC |
| Parallel Old | 老年代 | 标记-整理 | 多线程吞吐量 | 吞吐量优先组合 | -XX:+UseParallelOldGC |
| CMS | 老年代 | 标记-清除 | 低停顿 | 高交互Web服务 | -XX:+UseConcMarkSweepGC |
| G1 | 全堆 | 分区标记-整理 | 可控停顿时间 | 大内存、低延迟服务端 | -XX:+UseG1GC |
选择建议:
- 小内存/客户端:Serial(新生代)+ Serial Old(老年代)。
- 吞吐量优先:Parallel Scavenge(新生代)+ Parallel Old(老年代)。
- 低延迟优先:G1(全堆)或CMS(老年代)+ ParNew(新生代,JDK 9前)。
- 超大内存/极致低延迟:ZGC/Shenandoah(需JDK 11+,实验特性)。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









