






目录
前言
聚类是机器学习中一种重要的无监督算法(Unsupervised Learning),它可以将数据点归结为一系列特定的组合。理论上归为一类的数据点具有相同的特性,而不同类别的数据点则具有各不相同的属性。
与监督学习(如分类器)相比,无监督学习的训练集没有人为标注的结果。在非监督式学习中,数据并不被特别标识,学习模型是为了推断出数据的一些内在结构。
一、聚类分析的概念
聚类分析是根据在数据中发现的描述对象及其关系的信息,将数据对象分组。目的是,组内的对象相互之间是相似的(相关的),而不同组中的对象是不同的(不相关的)。组内相似性越大,组间差距越大,说明聚类效果越好。
也就是说, 聚类的目标是得到较高的簇内相似度和较低的簇间相似度,使得簇间的距离尽可能大,簇内样本与簇中心的距离尽可能小。
聚类得到的簇可以用聚类中心、簇大小、簇密度和簇描述等来表示- 聚类中心是一个簇中所有样本点的均值(质心)
- 簇大小表示簇中所含样本的数量
- 簇密度表示簇中样本点的紧密程度
- 簇描述是簇中样本的业务特征
聚类的过程
- 数据准备:包括特征标准化和降维;
- 特征选择:从最初的特征中选择最有效的特征,并将其存储于向量中;
- 特征提取:通过对所选择的特征进行转换形成新的突出特征;
- 聚类(或分组):首先选择合适特征类型的某种距离函数(或构造新的距离函数)进行接近程度的度量,而后执行聚类或分组;
- 聚类结果评估:是指对聚类结果进行评估,评估主要有3种:外部有效性评估、内部有效性评估和相关性测试评估。
良好聚类算法的特征
- 良好的可伸缩性
- 处理不同类型数据的能力
- 处理噪声数据的能力
- 对样本顺序的不敏感性
- 约束条件下的表现
- 易解释性和易用性
聚类分析的要求
不同的聚类算法有不同的应用背景,有的适合于大数据集,可以发现任意形状的聚簇;有的算法思想简单,适用于小数据集。总的来说,数据挖掘中针对聚类的典型要求包括:
(1)可伸缩性:当数据量从几百上升到几百万时,聚类结果的准确度能一致。
(2)处理不同类型属性的能力:许多算法针对的数值类型的数据。但是,实际应用场景中,会遇到二元类型数据,分类/标称类型数据,序数型数据。
(3)发现任意形状的类簇:许多聚类算法基于距离(欧式距离或曼哈顿距离)来量化对象之间的相似度。基于这种方式,我们往往只能发现相似尺寸和密度的球状类簇或者凸型类簇。但是,实际中类簇的形状可能是任意的。
(4)初始化参数的需求最小化:很多算法需要用户提供一定个数的初始参数,比如期望的类簇个数,类簇初始中心点的设定。聚类的结果对这些参数十分敏感,调参数需要大量的人力负担,也非常影响聚类结果的准确性。
(5)处理噪声数据的能力:噪声数据通常可以理解为影响聚类结果的干扰数据,包含孤立点,错误数据等,一些算法对这些噪声数据非常敏感,会导致低质量的聚类。
(6)增量聚类和对输入次序的不敏感:一些算法不能将新加入的数据快速插入到已有的聚类结果中,还有一些算法针对不同次序的数据输入,产生的聚类结果差异很大。
(7)高维性:有些算法只能处理2到3维的低纬度数据,而处理高维数据的能力很弱,高维空间中的数据分布十分稀疏,且高度倾斜。
(8)可解释性和可用性:我们希望得到的聚类结果都能用特定的语义、知识进行解释,和实际的应用场景相联系。
聚类的分类
-
K均值聚类
适用于大规模数据集的聚类分析,常用于市场分析、图像分析、语音分析、医学分析等领域。
-
均值漂移算法
-
基于密度的聚类算法(DBSCAN)
适用于大规模数据集中密度不均匀的聚类分析,常用于空间数据分析、异常检测等领域。
-
利用高斯混合模型进行最大期望估计
适用于数据集中存在多个高斯分布的聚类分析,常用于图像分析、语音分析、信号处理等领域。
-
凝聚层次聚类
适用于小规模数据集,常用于生物学研究、社会学研究等领域。
-
谱聚类模型:适用于大规模数据集的聚类分析,常用于图像分析、社交网络分析等领域。
聚类分析的度量
聚类分析的度量指标用于对聚类结果进行评判,分为内部指标和外部指标两大类
- 外部指标指用事先指定的聚类模型作为参考来评判聚类结果的好坏
- 内部指标是指不借助任何外部参考,只用参与聚类的样本评判聚类结果好坏
二、K均值聚类
主要基于数据点之间的均值和与聚类中心的聚类迭代而成。它主要的优点是十分的高效,由于只需要计算数据点与聚类中心的距离,其计算复杂度只有O(n)。其工作原理主要分为以下四步:
- 首先我们需要预先给定聚类的数目同时随机初始化聚类中心。我们可以初略的观察数据并给出较为准确的聚类数目;
- 每一个数据点通过计算与聚类中心的距离了来分类到最邻近的一类中;
- 根据分类结果,利用分类后的数据点重新计算聚类中心;
- 重复步骤二三直到聚类中心不再变化。(可以随机初始化不同的聚类中心以选取最好的结果)
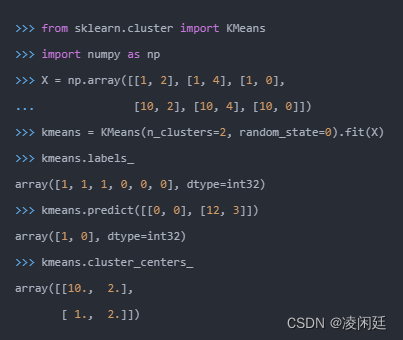
这种方法在理解和实现上都十分简单,但缺点却也十分明显,十分依赖于初始给定的聚类数目;同时随机初始化可能会生成不同的聚类效果,所以它缺乏重复性和连续性。和K均值类似的K中值算法,在计算过程中利用中值来计算聚类中心,使得局外点对它的影响大大减弱;但每一次循环计算中值矢量带来了计算速度的大大下降。
优缺点及拓展
k‐均值++算法的优缺点
- 优点:
提高了局部最优点的质量
收敛更快 - 缺点:
相比随机选择中心点计算较大
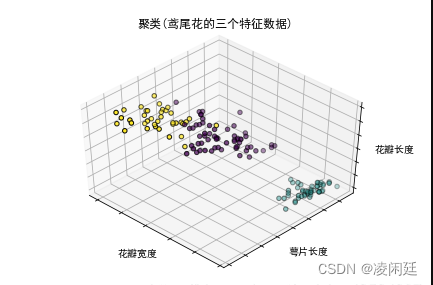
鸢尾花的三个特征聚类
# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn.cluster import KMeans
from sklearn import datasets
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
def visual(X, labels):
fig = plt.figure(1, figsize=(6, 4))
ax = Axes3D(fig, rect=[0, 0, .95, 1], elev=48, azim=134)
ax.scatter(X[:, 3], X[:, 0], X[:, 2], c=labels.astype(float), edgecolor='k')
ax.set_xticklabels([])
ax.set_yticklabels([])
ax.set_zticklabels([])
ax.set_xlabel('花瓣宽度')
ax.set_ylabel('萼片长度')
ax.set_zlabel('花瓣长度')
ax.set_title("聚类(鸢尾花的三个特征数据)")
ax.dist = 12
plt.show()
if __name__=='__main__':
np.random.seed(5)
iris = datasets.load_iris()
X = iris.data
y = iris.target
est = KMeans(n_clusters=3)
est.fit(X)
labels = est.labels_
visual(X, labels)
使用k‐均值聚类的注意事项
- 模型的输入数据为数值型数据(如果是离散变量,需要作哑变量处理
- 需要将原始数据作标准化处理(防止不同量纲对聚类产生影响)
对k值的选取,主要有以下几种:
- 与层次聚类算法结合,先通过层次聚类算法得出大致的聚类数目,并且获得一个初始聚类结果,然后再通过k‐均值算法改进聚类结果
- 基于系统演化的方法,将数据集视为伪热力学系统,在分裂和合并过程中,将系统演化到稳定平衡状态从而确定k值
三、均值飘逸算法
一种基于滑动窗口的均值算法,用于寻找数据点中密度最大的区域。其目标是找出每一个类的中心点,并通过计算滑窗内点的均值更新滑窗的中心点。最终消除临近重复值的影响并形成中心点,找到其对应的类别。
- 首先以随机选取的点为圆心r为半径做一个圆形的滑窗。其目标是找出数据点中密度最高点并作为中心;
- 在每个迭代后滑动窗口的中心将为想着较高密度的方向移动;
- 连续移动,直到任何方向的移动都不能增加滑窗中点的数量,此时滑窗收敛;
- 将上述步骤在多个滑窗上进行以覆盖所有的点。当过个滑窗收敛重叠时,其经过的点将会通过其滑窗聚类为一个类;

与K均值相比最大的优点是我们无需指定指定聚类数目,聚类中心处于最高密度处也是符合直觉认知的结果。但其最大的缺点在于滑窗大小r的选取,对于结果有着很大的影响。

DBSCAN
DBSCAN同样是基于密度的聚类算法,但其原理却与均值漂移大不相同:
- 首先从没有被遍历的任一点开始,利用邻域距离epsilon来获取周围点;
- 如果邻域内点的数量满足阈值则此点成为核心点并以此开始新一类的聚类。(如果不是则标记为噪声);
- 其邻域内的所有点也属于同一类,将所有的邻域内点以epsilon为半径进行步骤二的计算;
- 重复步骤二、三直到变量完所有核心点的邻域点;
- 此类聚类完成,同时又以任意未遍历点开始步骤一到四直到所有数据点都被处理;最终每个数据点都有自己的归属类别或者属于噪声。
高斯混合模型
- 首先确定聚类的数量,并随机初始化每一个聚类的高斯分布参数;
- 通过计算每一个点属于高斯分布的概率来进行聚类。与高斯中心越近的点越有可能属于这个类;
- 基于上一步数据点的概率权重,通过最大似然估计的方法计算出每一类数据点最有可能属于这一聚类的高斯参数;
- 基于新的高斯参数,重新估计每一点归属各类的概率,重复并充分2,3步骤直到参数不再变化收敛为止。
在使用高斯混合模型时有两个关键的地方,首先高斯混合模型十分灵活,可以拟合任意形状的椭圆;其次这是一种基于概率的算法,每个点可以拥有属于多类的概率,支持混合属性。
凝聚层次聚类
层次聚类法主要有自顶向下和自底向上两种方式。其中自底向上的方式,最初将每个点看做是独立的类别,随后通过一步步的凝聚最后形成独立的一大类,并包含所有的数据点。这会形成一个树形结构,并在这一过程中形成聚类。
- 首先将每一个数据点看成一个类别,通过计算点与点之间的距离将距离近的点归为一个子类,作为下一次聚类的基础;
- 每一次迭代将两个元素聚类成一个,上述的子类中距离最近的两两又合并为新的子类。最相近的都被合并在一起;
- 重复步骤二直到所有的类别都合并为一个根节点。基于此我们可以选择我们需要聚类的数目,并根据树来进行选择。
总结
聚类分析是一种无监督学习方法,旨在将数据集中的对象划分为若干个不相交的子集(簇),使得同一簇内的对象之间具有较高的相似度,而不同簇之间的对象相似度较低。
参考文献















 6758
6758

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









