






本文所使用的数据集为经典的鸢尾花三分类数据集:
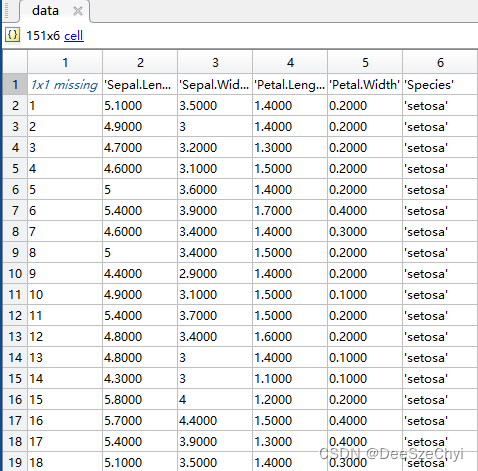
该数据集有四个特征维度,最后一列为标签,标签取值范围为{'setosa','versicolor','virginica'}。显然这是个三分类问题,本文使用支持向量机模型。matlab代码如下:
% 加载数据集
data = readcell("C:\Users\27734\Desktop\Iris数据集\iris.csv");
% 分割特征和标签
X = cell2mat(data(2:end, 2:end-1)); % 特征列,排除第一列序号和最后一列标签
y = categorical(data(2:end, end)); % 标签列,将字符型标签转换为分类变量
% 随机分割数据集为训练集和测试集
cv = cvpartition(size(X, 1), 'HoldOut', 0.3); % 将数据集按照70:30的比例分割为训练集和测试集
trainIdx = training(cv); % 训练集索引
testIdx = test(cv); % 测试集索引
trainX = X(trainIdx, :); % 训练集的各个特征维度
trainY = y(trainIdx, :); % 训练集标签
testX = X(testIdx, :); % 测试集的各个特征维度
testY = y(testIdx, :); % 测试集标签
% 本文在此使用的fitcecoc函数为matlab内置函数
svmModel = fitcecoc(trainX, trainY);
% 在测试集上进行预测
predictions = predict(svmModel, testX);
% 计算准确率(查准率)
accuracy = sum(predictions == testY) / numel(testY);
% 显示准确率(查准率)
fprintf('准确率(查准率): %.2f%%\n', accuracy * 100);
下面为实验结果:
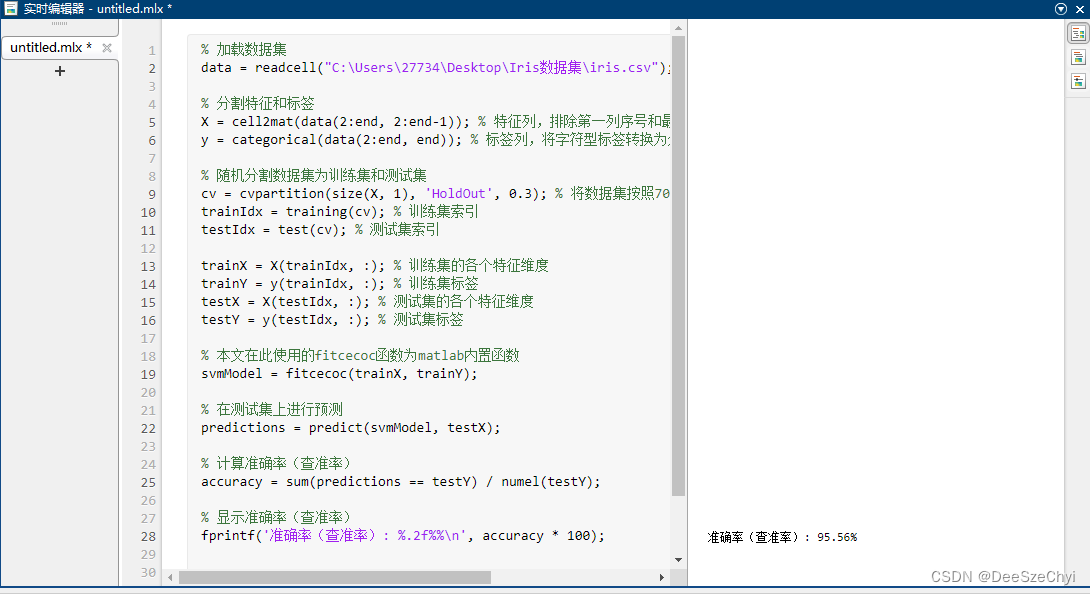
查全率为95.56%,该支持向量机模型对鸢尾花三分类问题的准确率较高。
C = confusionmat(testY, predictions);
figure;
imagesc(C);
colorbar;
textStrings = num2str(C(:));
textStrings = strtrim(cellstr(textStrings));
[x, y] = meshgrid(1:size(C, 1), 1:size(C, 2));
hStrings = text(x(:), y(:), textStrings(:), 'HorizontalAlignment', 'center');
midValue = mean(get(gca, 'CLim'));
textColors = repmat(C(:) > midValue, 1, 3);
set(hStrings, {'Color'}, num2cell(textColors, 2));
title('混淆矩阵');
xlabel('预测标签');
ylabel('真实标签');
colormap('cool');
我们绘制出混淆矩阵,查看拟合效果:
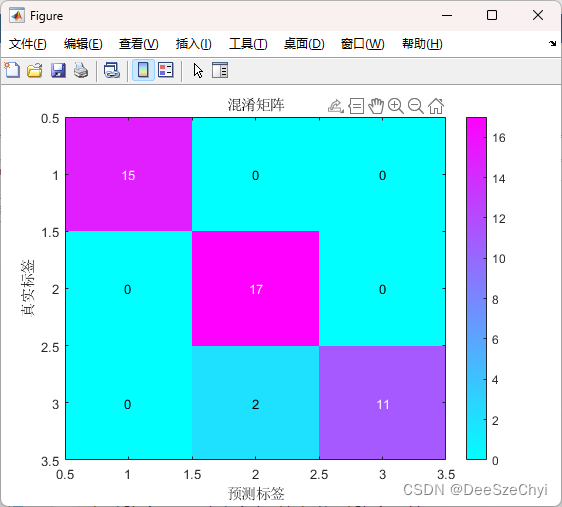
从混淆矩阵可知:本次预测只有两次错误,其他均预测正确。














 1150
1150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









