







Hbase的集群部署
文章目录
前言
Spark是遥远东方的一个游士,与其说是一位游士,不如称其为一个侠客,一位万花丛中过,片叶不沾身的风流侠者。spark来无影、去无踪,在他心里不知道方向在哪儿,也不清楚在他心里,谁才是他真正的方向。
他也曾经拥有一位柔情似水的姑娘,名曰Hive,他们也曾恩爱,或许现在也很恩爱,但毕竟spark多情于世,所到之处,遍地温柔。雨,是暮春的雨;夜,是孤独的夜。spark只身一人来到了分布式数据库,遇到了他曾经畅想过却又未曾相见过的女孩儿——hbase。
提示:以下是本篇文章正文内容,下面案例可供参考
一、HBase是什么?
HBase是一个高可靠性、面向列、可伸缩的分布式数据库,利用HBase可存储并处理大型的数据。HBase存在单点故障问题,可以通过zookeeper部署一个高可用的HBase集群解决。下面,以三台服务器为例(hadoop01、hadoop02和hadoop03)讲解如何安装部署HBase集群。
二、部署步骤
1.环境集群
安装JDK1.8、Hadoop2.7.4,以及zookeeper3.4.10
2.下载HBase安装包
官网下载地址:https://archive.apache.org/dist/hbase/。这里下载的版本是1.2.1
(本版本张医师也会上传到csdn上)
3.上传并解压HBase安装包
将HBase安装包上传至Linux系统的/export/software/目录下,然后解压到/export/servers/目录。
解压安装包的具体命令如下:
tar -zxvf hbase-1.2.1-bin.tar.gz -C /export/servers/
4.备份hdfs-site.xml和core-site.xml
将/hadoop-2.7.4/etc/hadoop目录下的hdfs-site.xml和core-site.xml配置文件,复制到/hbase-1.2.1/conf目录下
复制文件的具体命令如下:
cp /export/servers/hadoop-2.7.4/etc/hadoop/{hdfs-site.xml,core-site.xml} /export/servers/hbase-1.2.1/conf
5.指定环境变量
进入/hbase-1.2.1/conf目录修改相关配置文件。打开hbase-env.sh配置文件,指定jdk环境变量并配置Zookeeper,修改后hbase-env.sh的文件如下
#jdk环境变量
export JAVA_HOME=/root/export/servers/jdk
#外部Zookeeper
export HBASE_MANAGES_ZK=false
打开hbase-site.xml配置文件,指定HBase在HDFS的存储路径、HBase在分布式存储方式以及Zookeeper地址,修改后的hbase-site.xml文件内容具体如下:
<configuration>
<!--指定hbase在HDFS上存储的路径-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop01:9000/hbase</value>
</property>
<!--指定hbase是分布式的-->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!--指定zk的地址,多个用“,”分割-->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01:2181,hadoop02:2181,hadoop03:2181</value>
</property>
</configuration>
修改regionservers配置文件,配置HBase的从节点角色(hadoop02和hadoop03)。具体内容如下:
hadoop02
hadoop03
修改(创建)backup-masters配置文件,为防止单点故障备用的主节点角色,具体内容如下:
hadoop02
修改profile配置文件,通过vim /etc/profile命令进入系统环境变量配置文件,配置HBase的环境变量(服务器hadoop01、hadoop02和hadoop03都需要配置),具体内容如下:
export HBASE_HOME=/export/servers/hbase-1.2.1
export PATH=$PATH:$HBASE_HOME/bin
将HBase的安装目录分发至hadoop02和hadoop03服务器上。具体命令如下:
scp -r /export/servers/hbase-1.2.1/ hadoop02:/export/servers/
scp -r /export/servers/hbase-1.2.1/ hadoop03:/export/servers/
分别执行source /etc/profile(一定执行)
6.启动zookeeper和hdfs
#启动zookeeper
zkServer.sh start
#启动HDFS
start-all.sh
7.启动HBase
start-hbase.sh
这里需要注意的是,在启动hbase之前,必须保证集群个节点时间是相同的,若不同步会抛出ClockOutOfSyncException异常,导致从节点无法启动。因此需要在集群各节点中执行如下命令来保证时间同步。
ntpdate -u cn.pool.ntp.org
当然张医师行走江湖也留有一手简单且粗暴的方式 date -s(强制更改,逆天改命)
8.jps检查
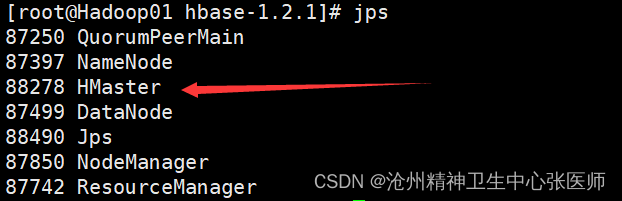
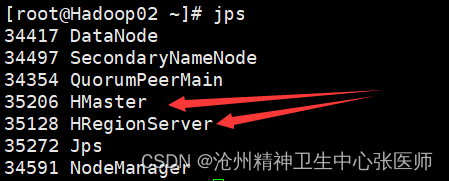
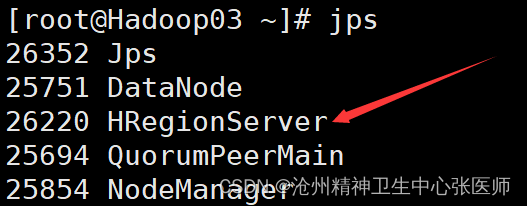
若出现以上所示,证明hbase集群部署成功。若需要停止HBase集群,则执行stop-hbase.sh命令
下面通过访问https://hadoop01:16010,查看HBase集群状态
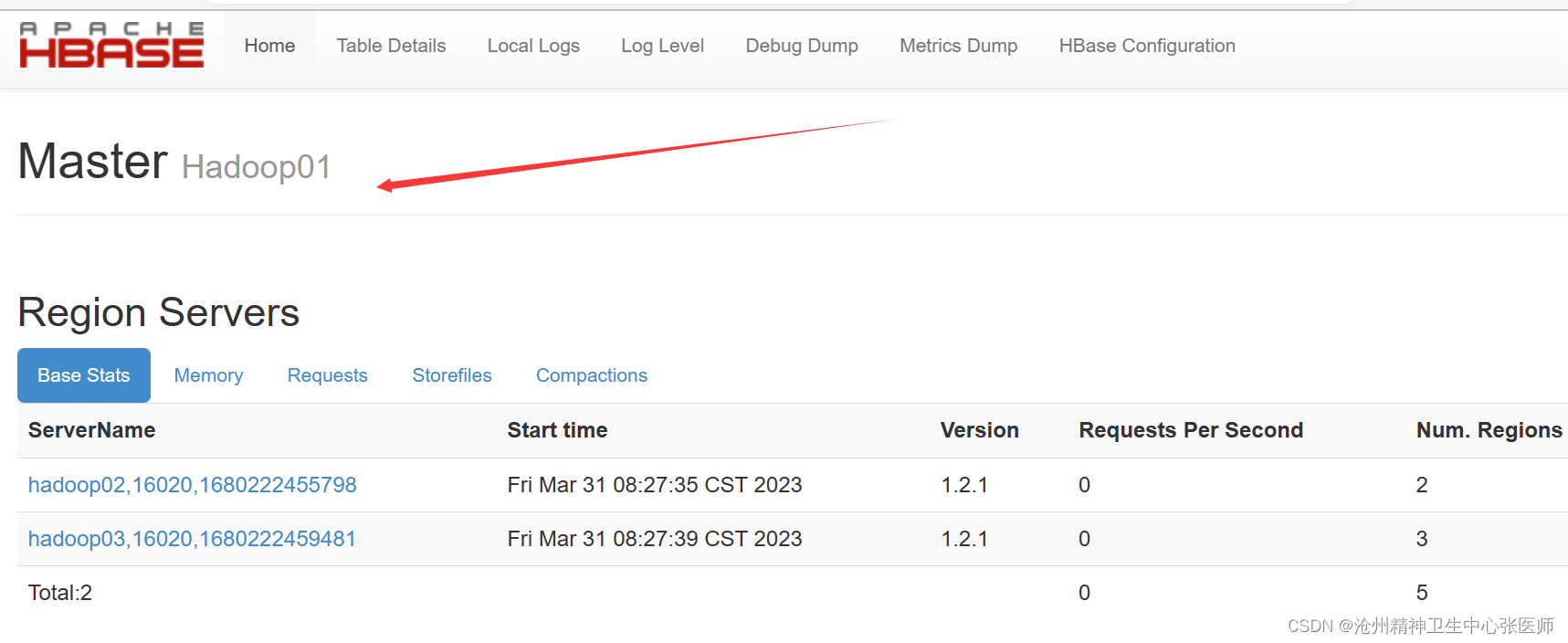
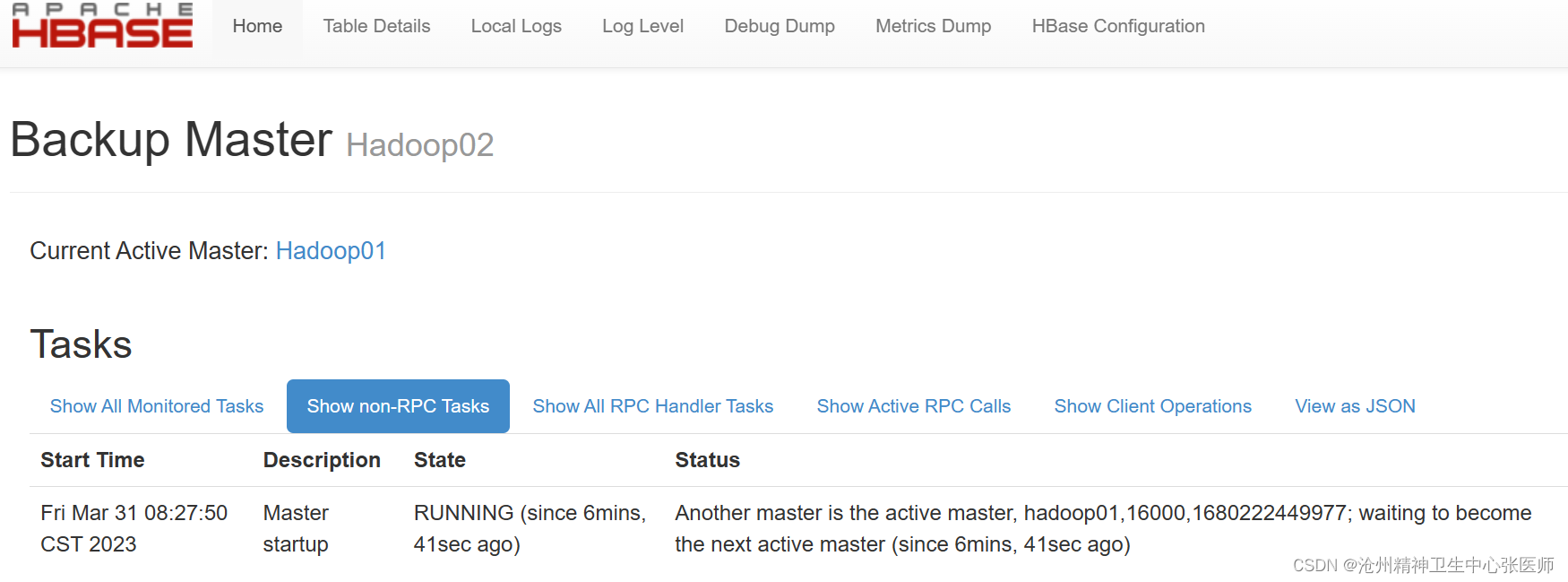
从上图可以看出,Hadoop01是主节点,hadoop02是备份主节点,并且可以从Active Master看出主节点在正常工作。
总结
窗外的雨还在下,今夜的春风仿佛也知晓spark的心事与烦恼,也悄悄的躲了起来。孤独的夜,spark把酒醉春风,卧倚键盘街边,笑看hbase浅斟低唱。举头无月,空吟无门,spark却以明了心的方向。
















 651
651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











