






神经网络学习笔记:
1.第一次从机器学习角度走进深度学习,那什么是神经网络?
答:神经网络是由简单单元组成的广泛并行互联的网络,能够模拟生物神经系统对真实世界做出的交互反应。

神经网络属于机器学习的无监督学习。(回顾机器学习的三种:有监督学习、无监督学习、强化学习)
2.感知机在神经网络中的作用?
答:感知机是单层神经网络,感知机有两层,分别是输入层和输出层。感知机可以解决线性可分的问题,例如我们说的与、或、非,这些均可以用感知机解决。但是感知机无法解决类似于异或的问题,此时问题已经从线性可分转化为非线性可分。
注意感知机的激活函数仅仅是作用于输出层(与问题3对比)。
在这之后发现感知机是存在问题的,其无法解决非线性可分的问题,例如异或,所以我们需要提出新的方式来解决这个问题。
虽然低维度的神经网络无法解决,我们可以选择转化为高维度神经网络来解决。
(多层前馈神经网络)
这在神经网络中较为常见:主要就是每层神经元与下一层神经元全连接,但是同层、跨层均不相连。
3.高维神经网络?
当我们把感知机的层数增加,从原来的一层转化为两层时。其发生了改变,可以解决异或问题。在输入层和输出层之间存在隐含层,多层神经网络与感知机的不同:
隐含层和输出层均含有激活函数的作用,而原来的激活函数仅仅作用于输出层。
神经网络的链接参数个数?(相关时间复杂度)

(有待继续解决)
4.神经网络和之前学过的线性回归、逻辑回归和支持向量机、决策树有什么关系和联系?
答:逻辑回归是神经网络的基础,比如说逻辑回归的输出可能是某一神经网络的未经激活的输出。

逻辑回归可以看作是两层神经元,激活函数是sigmoid函数的神经网络。
相同点:逻辑回归和感知机均为线性分类器,只能处理线性可分的数据。
5.神经网络的误差是如何处理的?
答:神经网络计算输出的节点误差之后,会在出现误差时将会反向传播计算梯度(从错误中进行学习,这里之后会进行详细推导见问题8),并将误差传回之前的网络层,进行权重的更新。而权重更新的一种方法是梯度下降算法。
6.那什么是梯度下降算法呢?
梯度下降算法是机器学习中常用的的最小化误差的方法,可以拆解为:梯度+下降。
梯度:在一维时可以理解为导数,(多维理解为偏导)
也就是导数下降:求某个函数(损失函数/误差函数)最小值时自变量对应的取值。导数是变化率,所以当导数为0时变化率也为0,一般为极值点。所以选择导数或者偏导来求解最小误差(最小误差函数的导数也就是误差的变化率)。
梯度下降的数学原理:
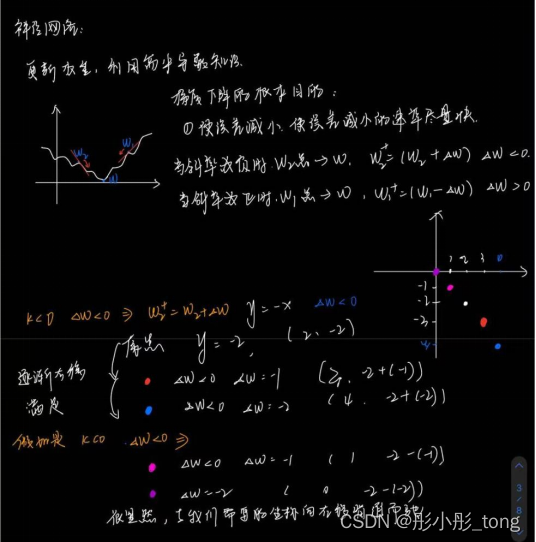
在梯度下降算法中,主要使用的是反向传播以及误差函数的求偏导,为什么误差函数选择的是E = (tk-ok)^2?
其实误差函数主要有三种,分别是:
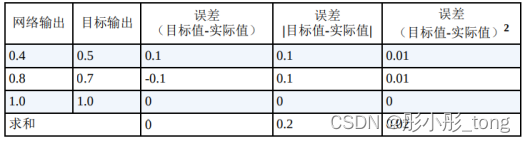
按照道理来讲,这三种误差函数都是正确的,可是在神经网络中主要选择了第三种误差函数,因为其有以下几个优点:
1.很容易代数计算梯度下降的斜率
2.其函数平滑连续,没有间断也没有跳跃(这非常适应于梯度下降)
3.越接近最小值,梯度越小,说明其基本没有超调的风险。
所以选择了第三种误差函数。
更新权重具体过程如下:


综上所述可以解决这样一个问题,神经网络究竟是通过什么来学习的呢?
神经网络是通过由误差引导,调整链接权重来进行学习的。
运用上述梯度下降算法来举例进行计算:

计算过程如下:

计算时需要注意的问题:
- 注意直接是ek,不是ek的平方
- 注意计算的是哪个w就要找对应的oj不要找错了。
7.神经网络对噪声是否敏感?
首先回顾支持向量机是否对噪声敏感:支持向量机对噪声是十分敏感的。
从支持向量机的定理着手,支持向量机最终需要的是:与支持向量有最大化距离的直线,我们以样本为圆心做圆,支持向量机需要在圆上的所有的样本点都属于相同分类。当产生了噪声,支持向量机依旧会对其进行分类,所以错误分类也将最大化,所以SVM对噪声是非常敏感的。
8.那神经网络对噪声是否敏感呢?
神经元对噪声我认为可以理解为不敏感。举个例子,神经元是如何传输信号的呢?
神经元输出信号的过程就像是一个杯子,在不断输入信号的过程中,神经元不会立即产生反应,而是会抑制其输入,就像水溢出才会有神经元的反应。
神经元不希望传递的是微弱的噪声信号,而是希望传递明显的信号。
9.如果可以增加节点,是增加进入宽度更好还是深度更好?
首先需要明确的是深度和宽度在神经网络中究竟代表什么。
深度:也就是神经网络的层数。
宽度:神经网络每层的通道数。
如果增加了深度:
其会有更好的非线性表达能力,可以拟合更复杂的特征,泛化能力更强。(通过数据对新数据进行预测)
但是也会有一些弊端:比如浅层的学习能力下降,加深深度可能会带来梯度不稳定等等。
如果增加了宽度:
其可以保证每一层都仔细学习,学到了丰富的特征,但是因为宽度过宽可能会出现部分重复的数据,导致其最终学习是因为记忆,对模型的拟合效果不是很好。但是宽度过低也不是很好,因为可能部分特征提取不够充分,不能够完全学习,模型的性能会降低。
课后题部分解决记录:
- 试述将线性函数 f(x)=wTx 用作神经元激活函数的缺陷。
答:在使用激活函数之前,无论传递几层,其单元值一直属于x的线性组合。这个时候等价于逻辑回归中的对率回归(详情见机器学习作业2解题思路),主要是通过求对数来求概率,并求未知参数w,b,使用概率进行二分类。输出层如果也使用线性回归函数,那直接等价于线性回归。
- 论述图5.2(b)激活函数的神经元与对率回归的联系。
答:使用sigmoid函数的时候,基本和对率回归相同。唯一不同的是,对率回归在sigmoid>0.5时输出1,神经元是直接输出sigmoid的值(详情见梯度下降部分)
- 学习率的取值对神经网络训练的影响?
答:学习率太低会导致其收敛过慢,而学习率过高会导致误差函数大幅度震荡,learning rate的取值太高的时候会导致参数迅速震荡到有效范围之外。在网上找到了一个非常直观的图像如下:

(注意epoch:所有数据完成一次前向计算和反向传播。)















 1670
1670











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









