






聚类
聚类的提出
聚类的是目标通过对无标记训练样本的学习来揭示数据内部潜在性质及规律。
在机器学习中有:
- 监督学习
- 无监督学习
- 强化学习
聚类则属于无监督学习,挖掘数据之间的隐含特征,其作为其他学习任务的前驱学习,主要是进行特征选择,特征抽取。
特征选择的过程:
- 按照某种特定的标准将数据集分为不同的簇。
- 找寻数据之间的潜在联系,需要达到“簇内相似度高”但“簇间相似度低”。
“簇内相似度高”通俗一点也可以理解为同一类数据进行聚在一起,不同数据尽量分离。
聚类算法过程:
- 在数据集中找到k个聚类中心(也作为其均值向量)
- 计算点到每一个k聚类中心的距离
- 将每个点归为其距离最小的聚类中心
- 再重新计算新的均值向量
- 不断反复迭代,直到聚类中心(新的均值向量)不再改变
例:西瓜书P202 表9.1
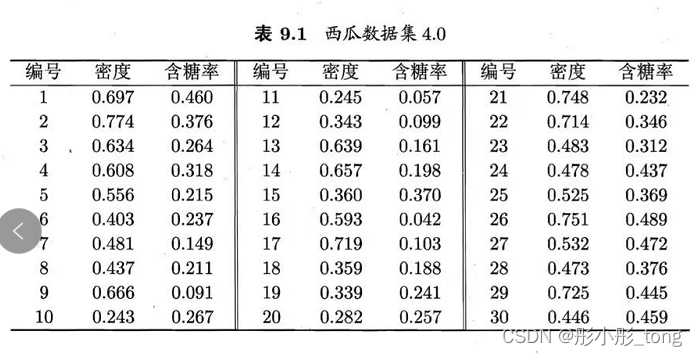
1.找到k个数据中心
将x6、x12、x27作为聚类中心,此时K=3
2.计算点到中心的距离,从编号x1开始,使用距离计算公式:

3.其第一次划分结果如下:

4.根据以上结果划分,计算新的均值向量

补充几种计算相似度的方法:
目前所有的相似度计算方法,通常都是基于向量的,所以相似度的计算也等同于向量距离,距离越小越相似
- Jaccard系数
主要计算符号度量或者布尔值度量的样本间相似度
计算方法:样本间交集的个数和样本间并集个数的比值

其中a为交集个数,a+b+c为并集个数
根据距离计算相似度:
-
欧氏距离
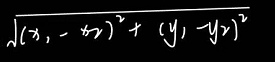
-
曼哈顿距离
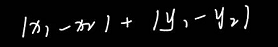
-
皮尔逊相关系数

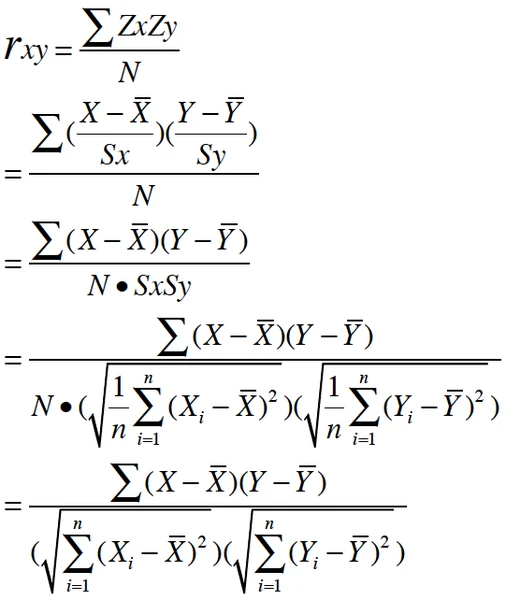
在皮尔逊系数中,相关系数有如下三种情况:
1)当相关系数为0时,X和Y两变量无关系。
2)当X的值增大(减小),Y值增大(减小),两个变量为正相关,相关系数在0.00与1.00之间。
3)当X的值增大(减小),Y值减小(增大),两个变量为负相关,相关系数在-1.00与0.00之间。
皮尔逊系数的适用范围:
当两个变量的标准差都不为零时(分母不为0),相关系数才有定义,皮尔逊相关系数适用于:
1)两个变量之间是线性关系,都是连续数据。
2)两个变量的总体是正态分布,或接近正态的单峰分布。
3)两个变量的观测值是成对的,每对观测值之间相互独立。
-
余弦相似度

-
切比雪夫距离

K-means代码实现:
首先介绍几个代码中会使用到的函数用法:
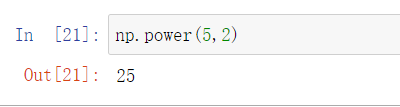
- np.power()
- np.random.choice()

- np.zeros()

-
[[]for i in range k]

-
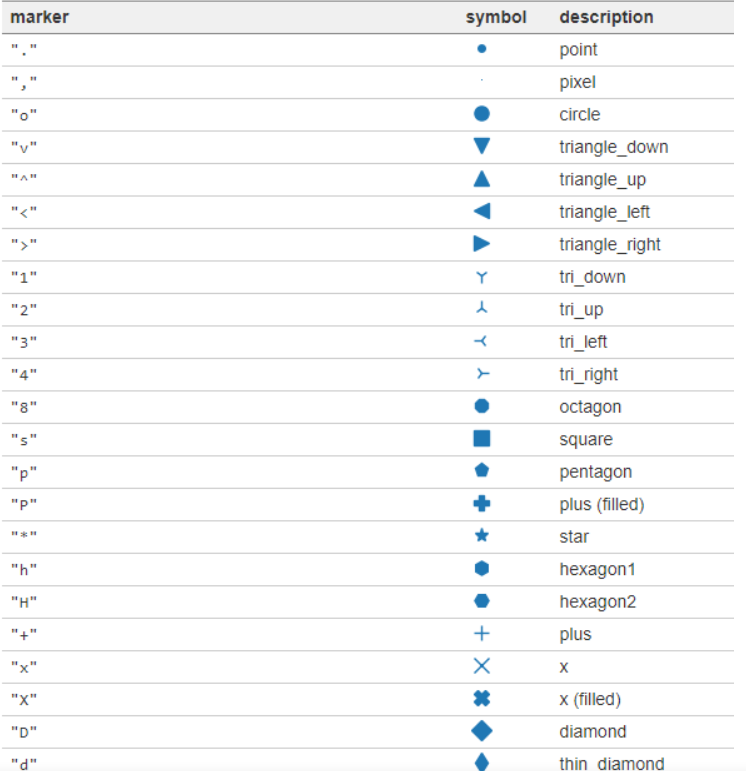
matplotlib 图像marker
-
pyplot.figure()
matplotlib.pyplot.figure(num=None,
figsize=None,
dpi=None,
facecolor=None,
edgecolor=None,
frameon=True,
FigureClass=<class 'matplotlib.figure.Figure'>,
clear=False,
**kwargs)
其中:
num:图像编号或名称,数字为编号 ,字符串为名称。不指定调用figure时就会默认从1开始。
figsize:指定figure的宽和高,单位为英寸
dpi参数指定绘图对象的分辨率,即每英寸多少个像素
facecolor:背景颜色
edgecolor:边框颜色
frameon:是否显示边框
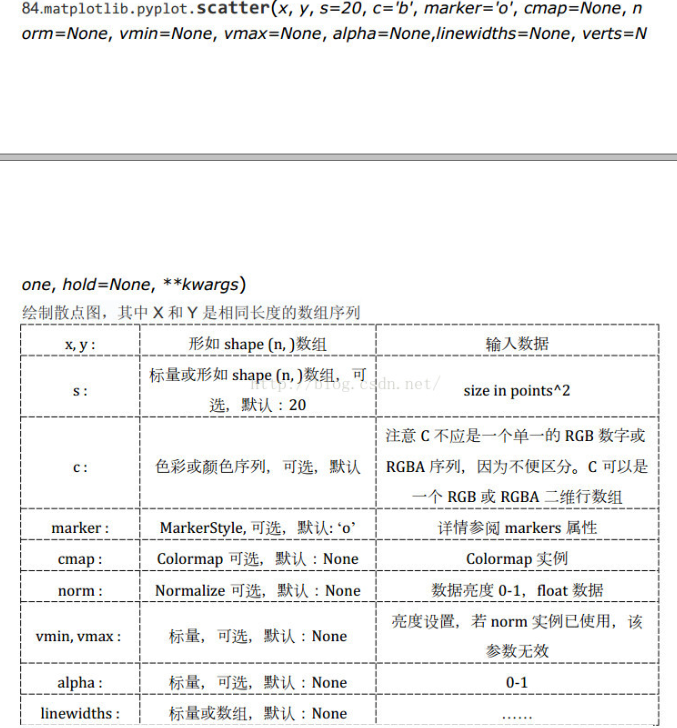
- plt.scatter()
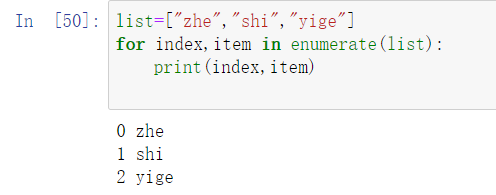
- numerate()
完整代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from numpy import * # 导入numpy的库函数
from scipy.spatial.distance import pdist
def seed():
np.random.seed(30)
def distance(sample, centers):
d = np.power(sample - centers, 2).sum(axis=1)
fin = d.argmin()
return fin
def distance(sample, centers):
d = np.power(sample - centers, 2).sum(axis=1)
fin = d.argmin()
return fin
def k_means(samples, k):
data_number = len(samples)
centers_flag = np.zeros((k,))
centers = samples[np.random.choice(data_number, k, replace=False)]
print(centers)
epoch = 0
while True:
clusters = [[] for i in range(k)]
for sample in samples:
ci = distance(sample, centers)
clusters[ci].append(sample)
show(clusters, epoch)
for i, sub_clusters in enumerate(clusters):
new_center = np.array(sub_clusters).mean(axis=0)
if (centers[i] != new_center).all():
centers[i] = new_center
else:
centers_flag[i] = 1
epoch = epoch + 1
print("epoch:{}".format(epoch), "\n", "centers:{}".format(centers))
if centers_flag.all():
break
return centers
def show(clusters, epoch):
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
color = ["yellow", "pink", "orange"]
marker = ["P", "X", "."]
plt.figure(figsize=(8, 8),facecolor='pink')
plt.title("epoch: {}".format(epoch))
plt.xlabel("密度", loc="center",fontsize=15)
plt.ylabel("含糖率", loc="center",fontsize=15)
for index, cluster in enumerate(clusters):
cluster = np.array(cluster)
plt.scatter(cluster[:, 0], cluster[:, 1], c=color[index], marker=marker[index], s=150)
plt.show()
def classification_data(samples, centers):
k = len(centers)
clusters = [[] for i in range(k)]
for sample in samples:
ci = distance(sample, centers)
clusters[ci].append(sample)
return clusters
if __name__ == '__main__':
seed()
# 导入数据
data = pd.read_excel(r"D:/大三上课程资料/机器学习/数据集/melon_data.xlsx")
samples = data[["密度", "含糖率"]].values
# print(samples)
centers = k_means(samples=samples, k=3)
clusters = classification_data(samples=samples, centers=centers)
print(clusters)
结果显示:
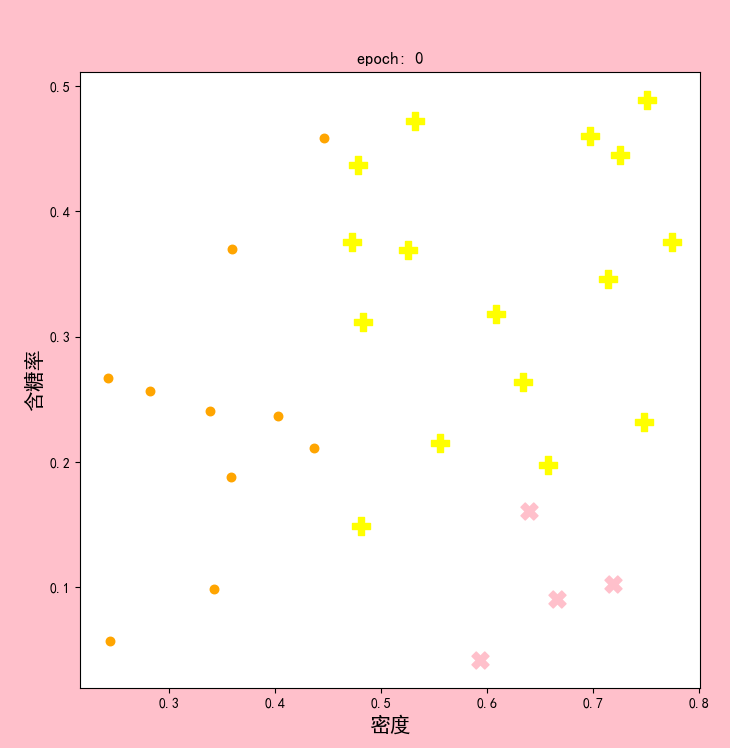
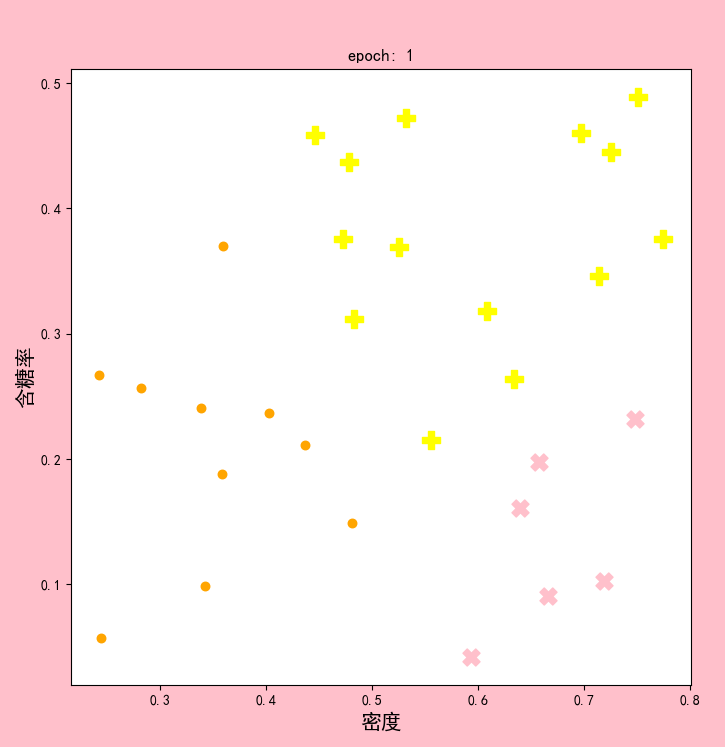
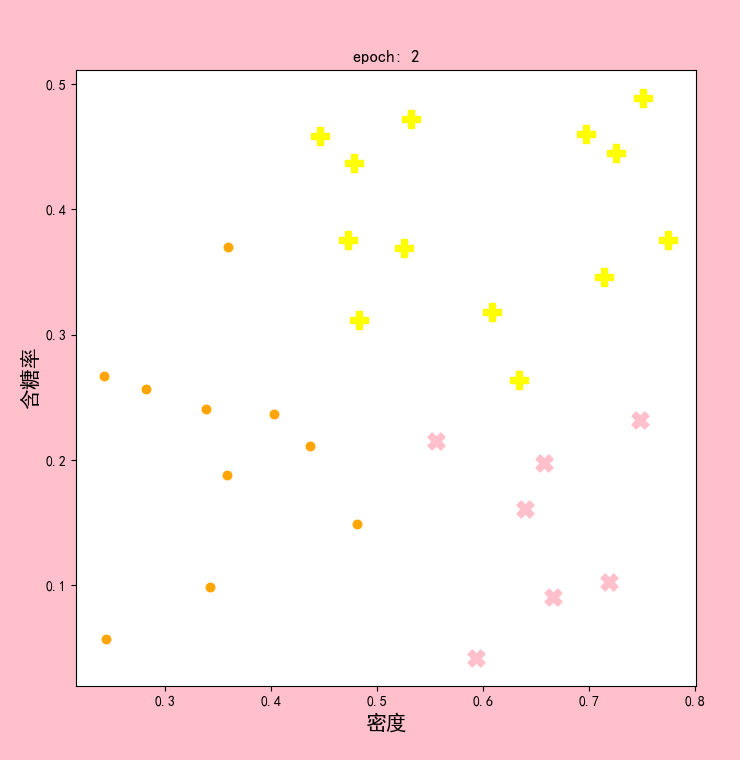
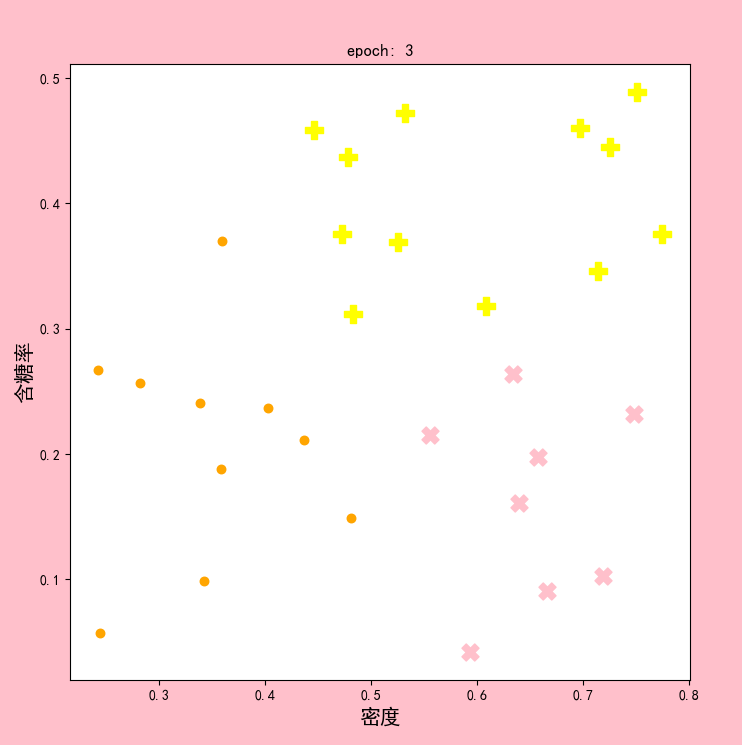
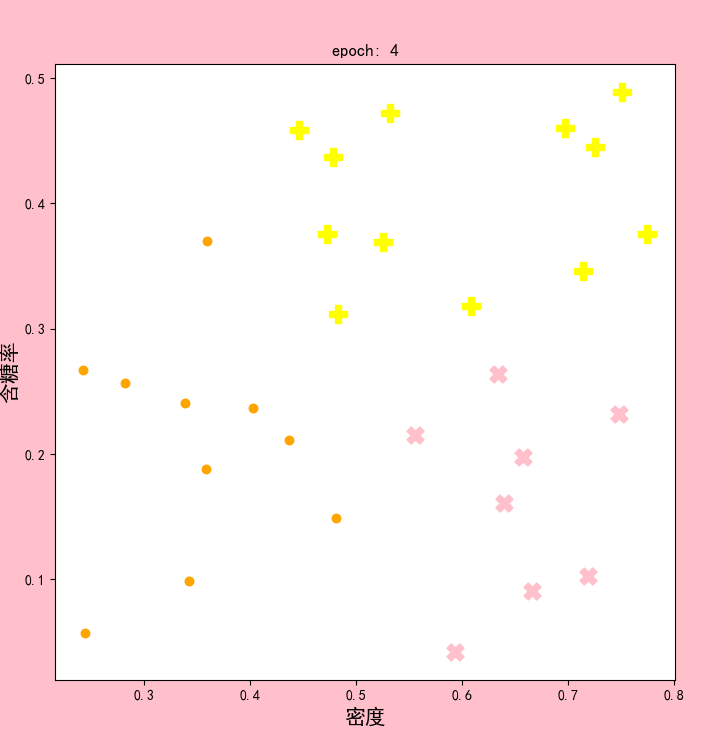
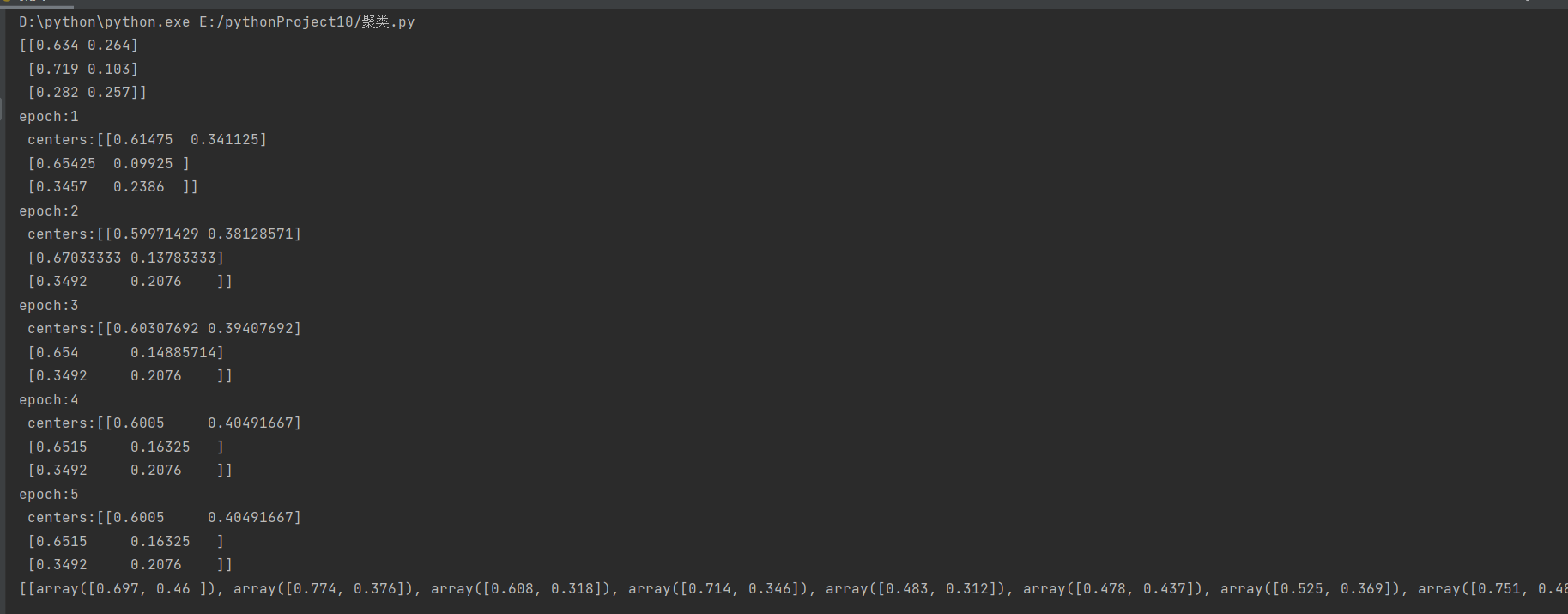 可以发现,在epoch4和epoch5时,聚类中心已经不再改变。
可以发现,在epoch4和epoch5时,聚类中心已经不再改变。















 139
139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









