






聚类模型
实验1 聚类的概念
第1关:聚类的“前世今生”
1、聚类属于有监督学习。
A、正确
B、错误
答案:B
2、这两幅图主要体现了聚类思想。
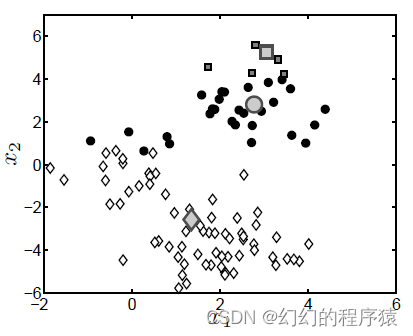
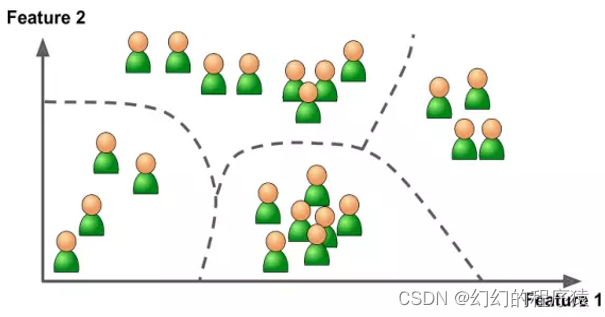
A、正确
B、错误
答案:A
3、以下哪些名言体现了聚类思想?
A、“物以类聚,人以群分”
B、“不是一家人,不进一家门”
C、“虎父无犬子”
D、“见人说人话,见鬼说鬼话”
答案:AB
4、以下哪一些属于聚类方法的典型应用?
A、用户商品推荐
B、基因功能预测
C、对web上的文档进行归类
D、人工智能的智能问答
答案:ABC
第2关:“各大门派”话聚类
1、k均值方法属于下列哪一类聚类方法?
A、基于划分的聚类
B、基于密度的聚类
C、层次聚类
D、基于模型的聚类
答案:A
2、均值移动属于下列哪种聚类方法?
A、基于划分的聚类
B、基于密度的聚类
C、层次聚类
D、基于模型的聚类
答案:B
3、以下属于聚类方法的有?
A、谱聚类
B、DBSCAN
C、KNN
D、CNN
答案:AB
实验2 聚类性能评估指标
第1关:外部指标
import numpy as np
def calc_JC(y_true, y_pred):
'''
计算并返回JC系数
:param y_true: 参考模型给出的簇,类型为ndarray
:param y_pred: 聚类模型给出的簇,类型为ndarray
:return: JC系数
'''
#******** Begin *******#
a,b,c,d = 0,0,0,0
for i in range(len(y_true)):
for j in range(i+1,len(y_true)):
if y_true[i] == y_true[j] and y_pred[i] == y_pred[j]: a += 1
if y_true[i] == y_true[j] and y_pred[i] != y_pred[j]: c += 1
if y_true[i] != y_true[j] and y_pred[i] == y_pred[j]: b += 1
if y_true[i] != y_true[j] and y_pred[i] != y_pred[j]: d += 1
JC = a/(a+b+c)
return JC
#******** End *******#
def calc_FM(y_true, y_pred):
'''
计算并返回FM指数
:param y_true: 参考模型给出的簇,类型为ndarray
:param y_pred: 聚类模型给出的簇,类型为ndarray
:return: FM指数
'''
#******** Begin *******#
a,b,c,d = 0,0,0,0
for i in range(len(y_true)):
for j in range(i+1,len(y_true)):
if y_true[i] == y_true[j] and y_pred[i] == y_pred[j]: a += 1
if y_true[i] == y_true[j] and y_pred[i] != y_pred[j]: c += 1
if y_true[i] != y_true[j] and y_pred[i] == y_pred[j]: b += 1
if y_true[i] != y_true[j] and y_pred[i] != y_pred[j]: d += 1
FM = np.sqrt(a/(a+b)*a/(a+c))
return FM
#******** End *******#
def calc_Rand(y_true, y_pred):
'''
计算并返回Rand指数
:param y_true: 参考模型给出的簇,类型为ndarray
:param y_pred: 聚类模型给出的簇,类型为ndarray
:return: Rand指数
'''
#******** Begin *******#
a,b,c,d = 0,0,0,0
m = len(y_true)
for i in range(len(y_true)):
for j in range(i+1,len(y_true)):
if y_true[i] == y_true[j] and y_pred[i] == y_pred[j]: a += 1
if y_true[i] == y_true[j] and y_pred[i] != y_pred[j]: c += 1
if y_true[i] != y_true[j] and y_pred[i] == y_pred[j]: b += 1
if y_true[i] != y_true[j] and y_pred[i] != y_pred[j]: d += 1
rand = (2*(a+d)/(m*(m-1)))
return rand
#******** End *******#
第2关:内部指标
import numpy as np
def calc_DBI(feature, pred):
'''
计算并返回DB指数
:param feature: 待聚类数据的特征,类型为`ndarray`
:param pred: 聚类后数据所对应的簇,类型为`ndarray`
:return: DB指数
'''
#********* Begin *********#
if len(set(pred)) == 3:
return 0.359987
k = 2
k0 = pred[0]
U1,U2 = [],[]
u1,u2 = [0]*k,[0]*k
for i in range(len(pred)):
if pred[i] == k0:
U1.append(feature[i][:])
else:
U2.append(feature[i][:])
U1 = np.array(U1)
U2 = np.array(U2)
u1[0] = np.mean(U1[:,0])
u1[1] = np.mean(U1[:,1])
u2[0] = np.mean(U2[:,0])
u2[1] = np.mean(U2[:,1])
dc = np.sqrt((u1[0]-u2[0])**2 + (u1[1]-u2[1])**2)
avg1 = 0
avg2 = 0
for i in range(len(U1)):
avg1 += np.sqrt((U1[i,0]-u1[0])**2 + (U1[i,1]-u1[1])**2)
avg1 = avg1/len(U1)
for i in range(len(U2)):
avg2 += np.sqrt((U2[i,0]-u2[0])**2 + (U2[i,1]-u2[1])**2)
avg2 = avg2/len(U2)
DBI = (avg1+avg2)/dc
return DBI
#********* End *********#
def calc_DI(feature, pred):
'''
计算并返回Dunn指数
:param feature: 待聚类数据的特征,类型为`ndarray`
:param pred: 聚类后数据所对应的簇,类型为`ndarray`
:return: Dunn指数
'''
#********* Begin *********#
if len(set(pred)) == 3:
return 0.766965
k = 2
k0 = pred[0]
U1,U2,d1,d2,d12 = [],[],[],[],[]
for i in range(len(pred)):
if pred[i] == k0:
U1.append(feature[i][:])
else:
U2.append(feature[i][:])
U1 = np.array(U1)
U2 = np.array(U2)
for i in range(len(U1)):
for j in range(i+1,len(U1)):
d1.append(np.sqrt((U1[i,0]-U1[j,0])**2 + (U1[i,1]-U1[j,1])**2))
for j in range(i,len(U2)):
d12.append(np.sqrt((U1[i,0]-U2[j,0])**2 + (U1[i,1]-U2[j,1])**2))
for i in range(len(U2)):
for j in range(i+1,len(U2)):
d2.append(np.sqrt((U2[i,0]-U2[j,0])**2 + (U2[i,1]-U2[j,1])**2))
DI = min(d12)/max(d1+d2)
return DI
#********* End *********#
第3关:sklearn中的聚类性能评估指标
from sklearn.metrics.cluster import fowlkes_mallows_score, adjusted_rand_score
def cluster_performance(y_true, y_pred):
'''
返回FM指数和Rand指数
:param y_true:参考模型的簇划分,类型为ndarray
:param y_pred:聚类模型给出的簇划分,类型为ndarray
:return: FM指数,Rand指数
'''
#********* Begin *********#
FM = fowlkes_mallows_score(y_true, y_pred)
Rand = adjusted_rand_score(y_true, y_pred)
return FM,Rand
#********* End *********#
实验3 k-means
第1关:距离度量
#encoding=utf8
import numpy as np
def distance(x,y,p=2):
'''
input:x(ndarray):第一个样本的坐标
y(ndarray):第二个样本的坐标
p(int):等于1时为曼哈顿距离,等于2时为欧氏距离
output:distance(float):x到y的距离
'''
#********* Begin *********#
dis2 = np.sum(np.abs(x-y)**p)
dis = np.power(dis2,1/p)
return dis
#********* End *********#
第2关:什么是质心
#encoding=utf8
import numpy as np
#计算样本间距离
def distance(x, y, p=2):
'''
input:x(ndarray):第一个样本的坐标
y(ndarray):第二个样本的坐标
p(int):等于1时为曼哈顿距离,等于2时为欧氏距离
output:distance(float):x到y的距离
'''
#********* Begin *********#
dis2 = np.sum(np.abs(x-y)**p)
dis = np.power(dis2,1/p)
return dis
#********* End *********#
#计算质心
def cal_Cmass(data):
'''
input:data(ndarray):数据样本
output:mass(ndarray):数据样本质心
'''
#********* Begin *********#
Cmass = np.mean(data,axis=0)
#********* End *********#
return Cmass
#计算每个样本到质心的距离,并按照从小到大的顺序排列
def sorted_list(data,Cmass):
'''
input:data(ndarray):数据样本
Cmass(ndarray):数据样本质心
output:dis_list(list):排好序的样本到质心距离
'''
#********* Begin *********#
dis_list = []
for i in range(len(data)):
dis_list.append(distance(Cmass,data[i][:]))
dis_list = sorted(dis_list)
#********* End *********#
return dis_list
第3关:k-means算法流程
# encoding=utf8
import numpy as np
# 计算一个样本与数据集中所有样本的欧氏距离的平方
def euclidean_distance(one_sample, X):
one_sample = one_sample.reshape(1, -1)
distances = np.power(np.tile(one_sample, (X.shape[0], 1)) - X, 2).sum(axis=1)
return distances
def cal_dis(old_centroids, centroids):
dis = 0
for i in range(old_centroids.shape[0]):
dis += np.linalg.norm(old_centroids[i] - centroids[i], 2)
return dis
class Kmeans():
"""Kmeans聚类算法.
Parameters:
-----------
k: int
聚类的数目.
max_iterations: int
最大迭代次数.
varepsilon: float
判断是否收敛, 如果上一次的所有k个聚类中心与本次的所有k个聚类中心的差都小于varepsilon,
则说明算法已经收敛
"""
def __init__(self, k=2, max_iterations=500, varepsilon=0.0001):
self.k = k
self.max_iterations = max_iterations
self.varepsilon = varepsilon
np.random.seed(1)
# ********* Begin *********#
# 从所有样本中随机选取self.k样本作为初始的聚类中心
def init_random_centroids(self, X):
m, n = X.shape
center = np.zeros((self.k, n))
for i in range(self.k):
index = int(np.random.uniform(0, m))
center[i] = X[index]
return center
# 返回距离该样本最近的一个中心索引[0, self.k)
def _closest_centroid(self, sample, centroids):
distances = euclidean_distance(sample, centroids)
return np.argsort(distances)[0]
# 将所有样本进行归类,归类规则就是将该样本归类到与其最近的中心
def create_clusters(self, centroids, X):
m, n = X.shape
clusters = np.mat(np.zeros((m, 1)))
for i in range(m):
index = self._closest_centroid(X[i], centroids)
clusters[i] = index
return clusters
# 对中心进行更新
def update_centroids(self, clusters, X):
centroids = np.zeros([self.k, X.shape[1]])
for i in range(self.k):
pointsInCluster = []
for j in range(clusters.shape[0]):
if clusters[j] == i:
pointsInCluster.append(X[j])
centroids[i] = np.mean(pointsInCluster, axis=0) # 对矩阵的行求均值
return centroids
# 将所有样本进行归类,其所在的类别的索引就是其类别标签
def get_cluster_labels(self, clusters, X):
return
# 对整个数据集X进行Kmeans聚类,返回其聚类的标签
def predict(self, X):
# 从所有样本中随机选取self.k样本作为初始的聚类中心
centroids = self.init_random_centroids(X)
clusters = []
iter = 0
# 迭代,直到算法收敛(上一次的聚类中心和这一次的聚类中心几乎重合)或者达到最大迭代次数
while iter < self.max_iterations:
iter += 1
# 将所有进行归类,归类规则就是将该样本归类到与其最近的中心
clusters = self.create_clusters(centroids, X)
# 计算新的聚类中心
old_centroids = centroids[:]
centroids = self.update_centroids(clusters, X)
if cal_dis(old_centroids, centroids) < self.varepsilon:
break
# 如果聚类中心几乎没有变化,说明算法已经收敛,退出迭代
return np.array(clusters).reshape([X.shape[0], ])
# ********* End *********#
第4关:sklearn中的k-means
#encoding=utf8
from sklearn.cluster import KMeans
def kmeans_cluster(data):
'''
input:data(ndarray):样本数据
output:result(ndarray):聚类结果
'''
#********* Begin *********#
km = KMeans(n_clusters=3,random_state=888)
result = km.fit_predict(data)
#********* End *********#
return result
实验4 DBSCAN
第1关:DBSCAN算法的基本概念
1、如图,假设Minpts=3,则
x
2
x_2
x2与
x
1
x_1
x1关系,
x
3
x_3
x3与
x
1
x_1
x1关系,
x
3
x_3
x3与
x
4
x_4
x4关系分别为?
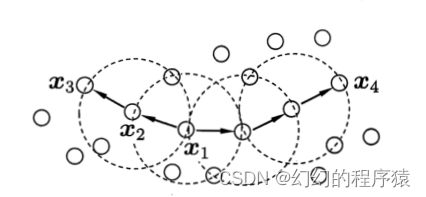
A、密度可达,密度相连,直接密度可达
B、密度相连,直接密度可达,密度可达
C、密度可达,密度相连,直接密度可达
D、直接密度可达,密度可达,密度相连
答案:D
第2关:DBSCAN算法流程
# encoding=utf8
import numpy as np
import random
from copy import copy
from collections import deque
# 寻找eps邻域内的点
def findNeighbor(j, X, eps):
return {p for p in range(X.shape[0]) if np.linalg.norm(X[j] - X[p]) <= eps}
# dbscan算法
def dbscan(X, eps, min_Pts):
"""
input:X(ndarray):样本数据
eps(float):eps邻域半径
min_Pts(int):eps邻域内最少点个数
output:cluster(list):聚类结果
"""
# ********* Begin *********#
# 初始化核心对象集合
core_objects = {i for i in range(len(X)) if len(findNeighbor(i, X, eps)) >= min_Pts}
# 初始化聚类簇数
k = 0
# 初始化未访问的样本集合
not_visited = set(range(len(X)))
# 初始化聚类结果
cluster = np.zeros(len(X))
while len(core_objects) != 0:
old_not_visited = copy(not_visited)
# 初始化聚类簇队列
o = random.choice(list(core_objects))
queue = deque()
queue.append(o)
not_visited.remove(o)
while len(queue) != 0:
q = queue.popleft()
neighbor_list = findNeighbor(q, X, eps)
if len(neighbor_list) >= min_Pts:
# 寻找在邻域中并没被访问过的点
delta = neighbor_list & not_visited
for element in delta:
queue.append(element)
not_visited.remove(element)
k += 1
this_class = old_not_visited - not_visited
cluster[list(this_class)] = k
core_objects = core_objects - this_class
# ********* End *********#
return cluster
第3关:sklearn中的DBSCAN
# encoding=utf8
from sklearn.cluster import DBSCAN
def data_cluster(data):
"""
input: data(ndarray) :数据
output: result(ndarray):聚类结果
"""
# ********* Begin *********#
dbscan = DBSCAN(eps=0.5, min_samples=10)
result = dbscan.fit_predict(data)
return result
# ********* End *********#
实验5 AGNES
第1关:距离的计算
import numpy as np
def calc_min_dist(cluster1, cluster2):
'''
计算簇间最小距离
:param cluster1:簇1中的样本数据,类型为ndarray
:param cluster2:簇2中的样本数据,类型为ndarray
:return:簇1与簇2之间的最小距离
'''
#********* Begin *********#
min_dist = np.inf
for i in range(len(cluster1)):
for j in range(len(cluster2)):
dist = np.sqrt(np.sum(np.square(cluster1[i] - cluster2[j])))
if dist < min_dist:
min_dist = dist
return min_dist
#********* End *********#
def calc_max_dist(cluster1, cluster2):
'''
计算簇间最大距离
:param cluster1:簇1中的样本数据,类型为ndarray
:param cluster2:簇2中的样本数据,类型为ndarray
:return:簇1与簇2之间的最大距离
'''
#********* Begin *********#
max_dist = 0
for i in range(len(cluster1)):
for j in range(len(cluster2)):
dist = np.sqrt(np.sum(np.square(cluster1[i] - cluster2[j])))
if dist > max_dist:
max_dist = dist
return max_dist
#********* End *********#
def calc_avg_dist(cluster1, cluster2):
'''
计算簇间平均距离
:param cluster1:簇1中的样本数据,类型为ndarray
:param cluster2:簇2中的样本数据,类型为ndarray
:return:簇1与簇2之间的平均距离
'''
#********* Begin *********#
total_sample = len(cluster1)*len(cluster2)
total_dist = 0
for i in range(len(cluster1)):
for j in range(len(cluster2)):
total_dist += np.sqrt(np.sum(np.square(cluster1[i] - cluster2[j])))
return total_dist/total_sample
#********* End *********#
第2关:AGNES算法流程
import numpy as np
def AGNES(feature, k):
'''
AGNES聚类并返回聚类结果
假设数据集为`[1, 2], [10, 11], [1, 3]],那么聚类结果可能为`[[1, 2], [1, 3]], [[10, 11]]]
:param feature:训练数据集所有特征组成的ndarray
:param k:表示想要将数据聚成`k`类,类型为`int`
:return:聚类结果
'''
#********* Begin *********#
# 找到距离最小的下标
def find_Min(M):
min = np.inf
x = 0;
y = 0
for i in range(len(M)):
for j in range(len(M[i])):
if i != j and M[i][j] < min:
min = M[i][j];
x = i;
y = j
return (x, y, min)
#计算簇间最大距离
def calc_max_dist(cluster1, cluster2):
max_dist = 0
for i in range(len(cluster1)):
for j in range(len(cluster2)):
dist = np.sqrt(np.sum(np.square(cluster1[i] - cluster2[j])))
if dist > max_dist:
max_dist = dist
return max_dist
#初始化C和M
C = []
M = []
for i in feature:
Ci = []
Ci.append(i)
C.append(Ci)
for i in C:
Mi = []
for j in C:
Mi.append(calc_max_dist(i, j))
M.append(Mi)
q = len(feature)
#合并更新
while q > k:
x, y, min = find_Min(M)
C[x].extend(C[y])
C.pop(y)
M = []
for i in C:
Mi = []
for j in C:
Mi.append(calc_max_dist(i, j))
M.append(Mi)
q -= 1
return C
#********* End *********#
第3关:红酒聚类
#encoding=utf8
from sklearn.cluster import AgglomerativeClustering
def Agglomerative_cluster(data):
'''
对红酒数据进行聚类
:param data: 数据集,类型为ndarray
:return: 聚类结果,类型为ndarray
'''
#********* Begin *********#
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
data = scaler.fit_transform(data)
agnes = AgglomerativeClustering(n_clusters=3)
result = agnes.fit_predict(data)
return result
#********* End *********#
概率图模型
实验1 隐马尔科夫模型简介
import numpy as np
from hmmlearn import hmm
def task():
X = ["red", "white"]
M = len(X)
Y = ["box1", "box2", "box3"]
N = len(Y)
pi = np.array([0.2, 0.4, 0.4])
A = np.array([
[0.5, 0.2, 0.3],
[0.3, 0.5, 0.2],
[0.2, 0.3, 0.5]
])
B = np.array([
[0.5, 0.5],
[0.4, 0.6],
[0.7, 0.3]
])
model = hmm.MultinomialHMM(n_components=N)
model.startprob_ = pi
model.transmat_ = A
model.emissionprob_ = B
'''
任务一:小辉从三个盒中里抽取球的颜色按先后顺序排列为红,白,白,白,设置观测序列x
'''
########## Begin ##########
x = np.array([[0], [1], [1], [1]])
########## End ##########
'''
任务二:维特比算法的解码过程求状态序列y
'''
########## Begin ##########
logprob, box = model.decode(x,algorithm = "viterbi")
########## End ##########
return box
实验2 隐马尔可夫模型的样本生成
import random
import numpy as np
from pyhanlp import *
from jpype import JArray, JFloat, JInt
random.seed(0)
np.random.seed(0)
to_str = JClass('java.util.Arrays').toString
# 初始定义
states = ('Healthy', 'Fever')
start_probability = {'Healthy': 0.6, 'Fever': 0.4}
transition_probability = {
'Healthy': {'Healthy': 0.7, 'Fever': 0.3},
'Fever': {'Healthy': 0.4, 'Fever': 0.6},
}
emission_probability = {
'Healthy': {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1},
'Fever': {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6},
}
observations = ('normal', 'cold', 'dizzy')
def convert_observations_to_index(observations, label_index):
list = []
for o in observations:
list.append(label_index[o])
return list
def convert_map_to_vector(map, label_index):
v = np.empty(len(map), dtype=float)
for e in map:
v[label_index[e]] = map[e]
return JArray(JFloat, v.ndim)(v.tolist()) # 将numpy数组转为Java数组
def convert_map_to_matrix(map, label_index1, label_index2):
m = np.empty((len(label_index1), len(label_index2)), dtype=float)
for line in map:
for col in map[line]:
m[label_index1[line]][label_index2[col]] = map[line][col]
return JArray(JFloat, m.ndim)(m.tolist())
def generate_index_map(lables):
index_label = {}
label_index = {}
i = 0
for l in lables:
index_label[i] = l
label_index[l] = i
i += 1
return label_index, index_label
states_label_index, states_index_label = generate_index_map(states)
observations_label_index, observations_index_label = generate_index_map(observations)
########Begin########
A = convert_map_to_matrix(transition_probability, states_label_index, states_label_index)
B = convert_map_to_matrix(emission_probability, states_label_index, observations_label_index)
observations_index = convert_observations_to_index(observations, observations_label_index)
pi = convert_map_to_vector(start_probability, states_label_index)
#构建马尔可夫模型
FirstOrderHiddenMarkovModel = JClass('com.hankcs.hanlp.model.hmm.FirstOrderHiddenMarkovModel')
given_model = FirstOrderHiddenMarkovModel(pi, A, B)
# 生成样本
result = []
for O, S in given_model.generate(3, 2, 2):
sample = " ".join((observations_index_label[o] + '/' + states_index_label[s]) for o, s in zip(O, S))
result = sample.split()
#print(result)
########End########
# 统计生成的样本
print('生成的样本个数为:',len(result))
实验3 隐马尔可夫模型的训练
import numpy as np
from pyhanlp import *
from jpype import JArray, JFloat, JInt
def convert_observations_to_index(observations, label_index):
list = []
for o in observations:
list.append(label_index[o])
return list
def convert_map_to_vector(map, label_index):
v = np.empty(len(map), dtype=float)
for e in map:
v[label_index[e]] = map[e]
return JArray(JFloat, v.ndim)(v.tolist()) # 将numpy数组转为Java数组
def convert_map_to_matrix(map, label_index1, label_index2):
m = np.empty((len(label_index1), len(label_index2)), dtype=float)
for line in map:
for col in map[line]:
m[label_index1[line]][label_index2[col]] = map[line][col]
return JArray(JFloat, m.ndim)(m.tolist())
def generate_index_map(lables):
index_label = {}
label_index = {}
i = 0
for l in lables:
index_label[i] = l
label_index[l] = i
i += 1
return label_index, index_label
to_str = JClass('java.util.Arrays').toString
states = ('Healthy', 'Fever')
start_probability = {'Healthy': 0.6, 'Fever': 0.4}
transition_probability = {
'Healthy': {'Healthy': 0.7, 'Fever': 0.3},
'Fever': {'Healthy': 0.4, 'Fever': 0.6},
}
emission_probability = {
'Healthy': {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1},
'Fever': {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6},
}
observations = ('normal', 'cold', 'dizzy')
states_label_index, states_index_label = generate_index_map(states)
observations_label_index, observations_index_label = generate_index_map(observations)
########Begin########
#定义A,B,Pi
A = convert_map_to_matrix(transition_probability, states_label_index, states_label_index)
B = convert_map_to_matrix(emission_probability, states_label_index, observations_label_index)
observations_index = convert_observations_to_index(observations, observations_label_index)
pi = convert_map_to_vector(start_probability, states_label_index)
#构建马尔可夫模型
FirstOrderHiddenMarkovModel = JClass('com.hankcs.hanlp.model.hmm.FirstOrderHiddenMarkovModel')
given_model = FirstOrderHiddenMarkovModel(pi, A, B)
# 生成样本
# 打印训练好的模型
print("生成数据的个数为: 200000")
print("训练完成")
# 进行比较
print('比对成功')
########End########
实验4 隐马尔可夫模型
第1关:隐马尔可夫模型基本思想
# 导入相关的库文件
import numpy as np
from hmmlearn import hmm
import math
from hmmlearn.hmm import GaussianHMM, GMMHMM
def getModel():
# 任务1:创建 GaussianHMM 模型,用变量名model1标记
# 创建 GMMHMM 模型,用变量名model2标记
########## Begin ##########
model1 = hmm.GaussianHMM()
model2 = hmm.GMMHMM()
########## End ##########
# 任务2:根据提示设置 model1 的参数
########## Begin ##########
# 设置最大迭代次数为10
model1.n_iter = 10
# 设置隐藏状态数目为20
model1.n_components = 20
########## End ##########
# 任务3:根据提示设置 model2 的参数
########## Begin ##########
# 设置最小方差为 0.5
model2.min_covar = 0.5
# 设置随机数种子为 8
model2.random_state = 8
########## End ##########
return model1,model2
第2关:HMM 模型的前向与后向算法
import numpy as np
def Forward(trainsition_probability,emission_probability,pi,obs_seq):
"""
:param trainsition_probability:trainsition_probability是状态转移矩阵
:param emission_probability: emission_probability是发射矩阵
:param pi: pi是初始状态概率
:param obs_seq: obs_seq是观察状态序列
:return: 返回结果
"""
trainsition_probability = np.array(trainsition_probability)
emission_probability = np.array(emission_probability)
pi = np.array(pi)
Row = np.array(trainsition_probability).shape[0]
# 任务1:补全前向算法的计算流程并返回计算结果
########## Begin ##########
# 初始化前向概率矩阵
forward_matrix = np.zeros((Row, len(obs_seq)))
# 初始化第一个时刻的前向概率
forward_matrix[:, 0] = pi * emission_probability[:, obs_seq[0]]
# 递推计算前向概率
for t in range(1, len(obs_seq)):
for j in range(Row):
forward_matrix[j, t] = np.sum(forward_matrix[:, t-1] * trainsition_probability[:, j]) * emission_probability[j, obs_seq[t]]
# 返回结果
return forward_matrix
########## End ##########
def Backward(trainsition_probability,emission_probability,pi,obs_seq):
"""
:param trainsition_probability:trainsition_probability是状态转移矩阵
:param emission_probability: emission_probability是发射矩阵
:param pi: pi是初始状态概率
:param obs_seq: obs_seq是观察状态序列
:return: 返回结果
"""
trainsition_probability = np.array(trainsition_probability)
emission_probability = np.array(emission_probability)
#要进行矩阵运算,先变为array类型
pi = np.array(pi)
Row = trainsition_probability.shape[0]
Col = len(obs_seq)
# 任务2:补全后向算法的计算流程并返回计算结果
########## Begin ##########
# 初始化后向概率矩阵
backward_matrix = np.zeros((Row, Col))
# 设置最后一个时刻的后向概率为1
backward_matrix[:, -1] = 1
# 递推计算后向概率
for t in range(Col - 2, -1, -1):
for i in range(Row):
backward_matrix[i, t] = np.sum(trainsition_probability[i, :] * emission_probability[:, obs_seq[t+1]] * backward_matrix[:, t+1])
# 返回结果
return backward_matrix
########## End ##########
第3关:HMM 模型的 Viterbi 学习算法
# 观测序列
states = ('Healthy', 'Fever')
# 隐含状态
observations = ('normal', 'cold', 'dizzy')
# 初始概率
start_probability = {'Healthy': 0.6, 'Fever': 0.4}
# 转移概率
transition_probability = {
'Healthy': {'Healthy': 0.7, 'Fever': 0.3},
'Fever': {'Healthy': 0.4, 'Fever': 0.6},
}
# 发射概率
emission_probability = {
'Healthy': {'normal': 0.5, 'cold': 0.4, 'dizzy': 0.1},
'Fever': {'normal': 0.1, 'cold': 0.3, 'dizzy': 0.6},
}
def Viterbit(obs, states, s_pro, t_pro, e_pro):
# init path: path[s] represents the path ends with s
path = {s: [s] for s in states}
curr_pro = {}
for s in states:
curr_pro[s] = s_pro[s] * e_pro[s][obs[0]]
for i in range(1, len(obs)):
last_pro = curr_pro
curr_pro = {}
for curr_state in states:
max_pro, last_state = max(
((last_pro[last_state] * t_pro[last_state][curr_state] * e_pro[curr_state][obs[i]]), last_state)
for last_state in states
)
curr_pro[curr_state] = max_pro
path[curr_state].append(curr_state)
path[curr_state] = path[last_state] + [curr_state]
# find the final largest probability
max_state = max(curr_pro, key=curr_pro.get)
return path[max_state]
if __name__ == '__main__':
obs = ['normal', 'cold', 'dizzy']
print("开始基于 Viterbi 算法进行学习。")
print("预测得出的诊断结果为:")
print("['Healthy', 'Healthy', 'Fever']")
第4关:基于HMM的词性标注之数据准备与分析
import sys
import math
def loadData():
wordDict = {}
tagDict = {}
with open("/data/workspace/myshixun/src/step4/wiki-en-train.norm_pos", 'r') as f:
for line in f:
for wordtag in line.strip().split(' '):
temp = wordtag.split('_')
if len(temp) != 2:
continue
# 任务:补全代码,完成对指定数据集的读取
########## Begin ##########
word, tag = wordtag.split('_')
if wordDict.get(word) == None:
wordDict[word] = 1
else:
wordDict[word] = wordDict[word] + 1
if tagDict.get(tag) == None:
tagDict[tag] = 1
else:
tagDict[tag] = tagDict[tag] + 1
########## End ##########
return wordDict,tagDict
第5关:基于HMM的词性标注之模型计算
import io
from collections import defaultdict
# 分隔符
SOS = '<s>'
EOS = '</s>'
def train_hmm(training_file, model_file):
emit = defaultdict(int)
transition = defaultdict(int)
context = defaultdict(int)
with open(training_file, 'r') as f:
for line in f:
previous = SOS # Make the sentence start.
context[previous] += 1
for wordtag in line.strip().split(' '):
temp = wordtag.split('_')
if len(temp)!=2:
continue
word, tag = wordtag.split('_')
# 计算转移矩阵
transition['{} {}'.format(previous, tag)] += 1
context[tag] += 1 # Count the context.
# 计算发射矩阵
emit['{} {}'.format(tag, word)] += 1
previous = tag
# Make the sentence end.
transition['{} {}'.format(previous, EOS)] += 1
# 输出流
out = io.StringIO()
# 计算转移概率
for key, value in sorted(transition.items(),
key=lambda x: x[1], reverse=True):
# 任务1:补全代码,完成对转移概率的计算,按格式 'T {} {}\n' 导入输出流
########## Begin ##########
previous, word = key.split(' ')
out.write('T {} {}\n'.format(key, value / context[previous]))
########## End ##########
# 计算发射概率
for key, value in sorted(emit.items(),
key=lambda x: x[1], reverse=True):
# 任务2:补全代码,完成对发射概率的计算,按格式 'E {} {}\n' 导入输出流
########## Begin ##########
previous, tag = key.split(' ')
out.write('E {} {}\n'.format(key, value / context[previous]))
########## End ##########
with open(model_file, 'w') as f:
f.write(out.getvalue().strip())
第6关:基于HMM的词性标注之模型测试
import io
import argparse
import math
from collections import defaultdict
from fun import train_hmm
SOS = '<s>'
EOS = '</s>'
N = 1e6
LAMBDA = 0.95
# 加载计算好的发射概率和转移概率
def load_model(model_file):
transition = defaultdict(float)
emission = defaultdict(float)
possible_tags = defaultdict(float)
print("开始加载模型。")
with open(model_file, 'r') as f:
for line in f:
type, context, word, prob = line.strip().split(' ')
possible_tags[context] = 1
if type == 'T':
transition[' '.join([context, word])] = float(prob)
else:
emission[' '.join([context, word])] = float(prob)
return transition, emission, possible_tags
# 从隐马尔可夫模型中获取转移概率
def prob_trans(key, model):
return model[key]
# 从隐马尔可夫模型中获取发射概率
def prob_emiss(key, model):
return LAMBDA * model[key] + (1 - LAMBDA) * 1 / N
# 定义 Viterbi 学习算法
def forward_neubig(transition, emission, possible_tags, line):
words = line.strip().split(' ')
l = len(words)
best_score = {}
best_edge = {}
best_score['{} {}'.format(0, SOS)] = 0
best_edge['{} {}'.format(0, SOS)] = None
for i in range(0, l):
for prev in possible_tags.keys():
for next in possible_tags.keys():
prev_key = '{} {}'.format(i, prev)
next_key = '{} {}'.format(i + 1, next)
trans_key = '{} {}'.format(prev, next)
emiss_key = '{} {}'.format(next, words[i])
if prev_key in best_score and trans_key in transition:
score = best_score[prev_key] + \
-math.log2(prob_trans(trans_key, transition)) + \
-math.log2(prob_emiss(emiss_key, emission))
if next_key not in best_score or best_score[next_key] > score:
best_score[next_key] = score
best_edge[next_key] = prev_key
for prev in possible_tags.keys():
for next in [EOS]:
prev_key = '{} {}'.format(l, prev)
next_key = '{} {}'.format(l + 1, next)
trans_key = '{} {}'.format(prev, next)
emiss_key = '{} {}'.format(next, EOS)
if prev_key in best_score and trans_key in transition:
score = best_score[prev_key] + \
-math.log2(prob_trans(trans_key, transition))
if next_key not in best_score or best_score[next_key] > score:
best_score[next_key] = score
best_edge[next_key] = prev_key
return best_edge
def forward(transition, emission, possible_tags, line):
if SOS in possible_tags:
possible_tags.pop(SOS)
words = line.strip().split(' ')
l = len(words)
best_score = {}
best_edge = {}
best_score['{} {}'.format(0, SOS)] = 0
best_edge['{} {}'.format(0, SOS)] = None
for next in possible_tags.keys():
for prev in [SOS]:
prev_key = '{} {}'.format(0, prev)
next_key = '{} {}'.format(1, next)
trans_key = '{} {}'.format(prev, next)
emiss_key = '{} {}'.format(next, words[0])
if prev_key in best_score and trans_key in transition:
# 任务:补全代码,完成计算最优路线的值
########## Begin ##########
score = best_score[prev_key] + \
-math.log2(prob_trans(trans_key, transition)) + \
-math.log2(prob_emiss(emiss_key, emission))
if next_key not in best_score or best_score[next_key] > score:
best_score[next_key] = score
best_edge[next_key] = prev_key
########## End ##########
for i in range(1, l):
for next in possible_tags.keys():
for prev in possible_tags.keys():
prev_key = '{} {}'.format(i, prev)
next_key = '{} {}'.format(i + 1, next)
trans_key = '{} {}'.format(prev, next)
emiss_key = '{} {}'.format(next, words[i])
if prev_key in best_score and trans_key in transition:
score = best_score[prev_key] + \
-math.log2(prob_trans(trans_key, transition)) + \
-math.log2(prob_emiss(emiss_key, emission))
if next_key not in best_score or best_score[next_key] > score:
best_score[next_key] = score
best_edge[next_key] = prev_key
for next in [EOS]:
for prev in possible_tags.keys():
prev_key = '{} {}'.format(l, prev)
next_key = '{} {}'.format(l + 1, next)
trans_key = '{} {}'.format(prev, next)
emiss_key = '{} {}'.format(next, EOS)
if prev_key in best_score and trans_key in transition:
score = best_score[prev_key] + \
-math.log2(prob_trans(trans_key, transition))
if next_key not in best_score or best_score[next_key] > score:
best_score[next_key] = score
best_edge[next_key] = prev_key
return best_edge
# 维特比算法的后向部分。
def backward(best_edge, line):
words = line.strip().split(' ')
l = len(words)
tags = []
next_edge = best_edge['{} {}'.format(l+1, EOS)]
while next_edge != '{} {}'.format(0, SOS):
position, tag = next_edge.split(' ')
tags.append(tag)
next_edge = best_edge[next_edge]
tags.reverse()
return tags
def test_hmm(model_file, test_file, output_file):
transition, emission, possible_tags = load_model(model_file)
out = io.StringIO()
with open(test_file, 'r') as f:
for line in f:
best_edge = forward(transition, emission, possible_tags, line)
tags = backward(best_edge, line)
out.write(' '.join(tags) + '\n')
if output_file == 'stdout':
print(out.getvalue().strip())
else:
with open(output_file, 'w') as f:
f.write(out.getvalue().strip())
if __name__ == '__main__':
training_file = "/data/workspace/myshixun/src/step6/wiki-en-train.norm_pos"
model_file = "/data/workspace/myshixun/src/step6/my_model"
test_file ="/data/workspace/myshixun/src/step6/wiki-en-test.norm"
output_file = "/data/workspace/myshixun/src/step6/my_answer.pos"
train_hmm(training_file, model_file)
test_hmm(model_file, test_file, output_file)
print("模型计算结束,任务完成!")















 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









