









关键词
PIL,OpenCV,Blob分析,STN网络,滤波器,插值,RandAugment,SIFT算法
图像处理,图像增强,图像分类
Ⅰ. 图像处理
一、常用库📕
1. PIL (pillow)
1.1 Image模块
- PIL.Image.new(mode, size, color=0)
- PIL.Image.open(fp, mode='r', formats=None)
- PIL.Image.fromarray(obj, mode=None)
- PIL.Image.blend(im1, im2, alpha):融合图片
- Image.convert(mode=None, matrix=None, dither=None, palette=0, colors=256)
- Image.resize(size, resample=None, box=None, reducing_gap=None)
- Image.rotate(angle)
- Image.transpose(Image.FLIP_LEFT_RIGHT):左右翻转
- Image.transform(size, method, data=None, resample=0, fill=1, fillcolor=None)
- Image.crop(box=None):区域裁剪,返回矩形区域,传入box元组(x,y,x2,y2)
- Image.thumbnail(size, resample=3, reducing_gap=2.0):返回缩略图
- Image.split():拆分图片的通道
'''resample:可选参数,指图像重采样滤波器,有四种过滤方式,分别是
Image.BICUBIC(双立方插值法)
PIL.Image.NEAREST(最近邻插值法)
PIL.Image.BILINEAR(双线性插值法)
PIL.Image.LANCZOS(下采样过滤插值法),默认为 Image.BICUBIC'''
# box四元组指的是像素坐标 (左,上,右,下)
#(0,0,120,180),表示以原图的左上角为原点,选择宽和高分别是(120,180)的图像区域
image=im.resize((550,260),resample=Image.LANCZOS,box=(0,0,120,180))1.2 ImageFilter模块
1.2.1 滤波器
ImageFilter模块提供了滤波器相关定义;这些滤波器主要用于Image类的filter()方法。
img = img.filter(ImageFilter.BLUR)- ImageFilter.BLUR为模糊滤波,处理之后的图像会整体变得模糊。
- ImageFilter.CONTOUR为轮廓滤波,将图像中的轮廓信息全部提取出来。
- ImageFilter.DETAIL为细节增强滤波,会使得图像中细节更加明显。
- ImageFilter.EDGE_ENHANCE为边缘增强滤波,突出、加强和改善图像中不同灰度区域之间的边界和轮廓的图像增强方法。经处理使得边界和边缘在图像上表现为图像灰度的突变,用以提高人眼识别能力。
- ImageFilter.EDGE_ENHANCE_MORE为深度边缘增强滤波,会使得图像中边缘部分更加明显。
- ImageFilter.EMBOSS为浮雕滤波,会使图像呈现出浮雕效果。
- ImageFilter.FIND_EDGES为寻找边缘信息的滤波,会找出图像中的边缘信息。
- ImageFilter.SMOOTH为平滑滤波,突出图像的宽大区域、低频成分、主干部分或抑制图像噪声和干扰高频成分,使图像亮度平缓渐变,减小突变梯度,改善图像质量。
- ImageFilter.SMOOTH_MORE为深度平滑滤波,会使得图像变得更加平滑。
- ImageFilter.SHARPEN为锐化滤波,补偿图像的轮廓,增强图像的边缘及灰度跳变的部分,使图像变得清晰。
1.2.2 kernel函数
- Kernel(size,kernel, scale=None, offset=0)
- RankFilter(size,rank)
- MinFilter(size=3)
- MedianFilter(size=3)
- MaxFilter(size=3)
- ModeFilter(size=3)
1.3 ImageEnhance模块
ImageEnhance 模块包含许多可用于图像增强的类
- PIL.ImageEnhance.Color(image)
- PIL.ImageEnhance.Contrast(image)
- PIL.ImageEnhance.Brightness(image)
- PIL.ImageEnhance.Sharpness(image)
1.4 ImageDraw
能给图像化圆弧,画横线,写上文字等。
2. OpenCV
2.0 代码演示
# 导入 OpenCV 库
import cv2 as cv
# 读取图片
src = cv.imread("./1.jpg")
# 创建窗口
cv.namedWindow("input image",cv.WINDOW_AUTOSIZE)
# 将图片显示在窗口上
cv.imshow("input image",src)
# 等待用户操作
cv.waitKey(0)
# 关掉窗口
cv.destroyAllWindows()
2.1 加载图像
- imread 功能是加载图像文件成为一个 Mat 对象,其中第一个参数表示图像文件名称,第二个参数表示加载的图像是什么类型,支持常见的三个参数值
- IMREAD_UNCHANDED(<0) 表示加载原图,不做任何改变
- IMREAD_GRAYSCALE(0) 表示吧原图作为灰度图像加载进来
- IMREAD_COLOR(>0) 表示把原图作为 RGB 图像加载进来
2.2 边界填充
- BORDER_REPLICATE : 复制法,也就是复制最边缘像素
- BORDER_REFLECT :反射法,对感兴趣的图像中的像素在两边进行复制例如:fedcbajabcdefghjhgfedcb(这里我也不是很明白,会的朋友请在评论区解释下,感谢)
- BORDER_REFLECT_101 : 反射法,也就是以最边缘像素为轴、对称、gfedcbjabcdefghigfedcba
- BORDER_WRAP : 外包装法
- BORDER_CONSTANT : 常量法,常数值填充
2.3 特征检测和提取算法
- Harris:该算法用于检测角点;
- SIFT:该算法用于检测斑点;
- SURF:该算法用于检测角点;
- FAST:该算法用于检测角点;
- BRIEF:该算法用于检测斑点;
- ORB:该算法代表带方向的FAST算法与具有旋转不变性的BRIEF算法;
2.4 特征匹配
- 暴力(Brute-Force)匹配法;
- 基于FLANN匹配法;
- 可以采用单应性进行空间验证。
2.5 形态学转换
- cv2.erode():腐蚀
- cv2.dilate():膨胀
- cv2.morphologyEx(src, op, kernel):形态学操作,op包含:
| cv2.MORPH_ERODE | 腐蚀 |
| cv2.MORPH_DILATE | 膨胀 |
| cv2.MORPH_ OPEN | 开运算,先腐蚀后膨胀,抹除了图像的外部细节 |
| cv2.MORPH_CLOSE | 闭运算,先膨胀后腐蚀,抹除图像的内部细节 |
| cv2.MORPH_GRADIENT | 梯度运算,膨胀图减腐蚀图,得到一个大概的、不精准的轮廓 |
| cv2.MORPH_TOPHAT | 顶帽运算,原始图减开运算图,结果也就只剩外部细节 |
| cv2.MORPH_BLACKHAT | 黑帽运算,原始图减闭运算图,结果只剩下内部细节 |



3. skimage(scikit-image)
二、分析方法🔧
1. Blob分析
Blob(Binary large object)是指图像中的具有相似颜色、纹理等特征所组成的一块连通区域,一般来说,该区域就是图像中的前景。Blob分析目的在于对图像中的2-D形状进行检测和分析,得到诸如目标位置、形状、方向和目标间的拓扑关系(即包含关系)等信息。根据这些信息可对目标进行识别。在某些应用中我们不仅需要利用2D的形状特征,还要利用Blob分析之间的特征关系。
Blob分析的主要内容包括:(1)图像分割:将图像中的目标和背景分离。(2)去噪:消除或减弱噪声对目标的干扰:(3)场景描述:对目标之间的拓扑关系进行描述。(4)特征量计算:计算目标的2-D形状特征。
Blob的实现流程大致可分为3个步骤:获取图像、提取Blob、Blob分析。
- 获取图像:获取图像是指通过相机设备得到原始图像
- 提取Blob:提取Blob是根据需求提取要分析的目标二指区域
- Blob分析:对提取出来的二值区域进行特征分析
三、网络模型🚆
1. Spatial Transformer Networks(STN)
STN提出的空间网络变换层STL,具有平移不变性、旋转不变性及缩放不变性等强大的性能。这个网络可以加在现有的卷积网络中,提高分类的准确性。
将 spatial transformers 模块集成到 cnn 网络中,允许网络自动地学习如何进行 feature
map 的转变,从而有助于降低网络训练中整体的代价。定位网络中输出的值,指明了如何对
每个训练数据进行转化。
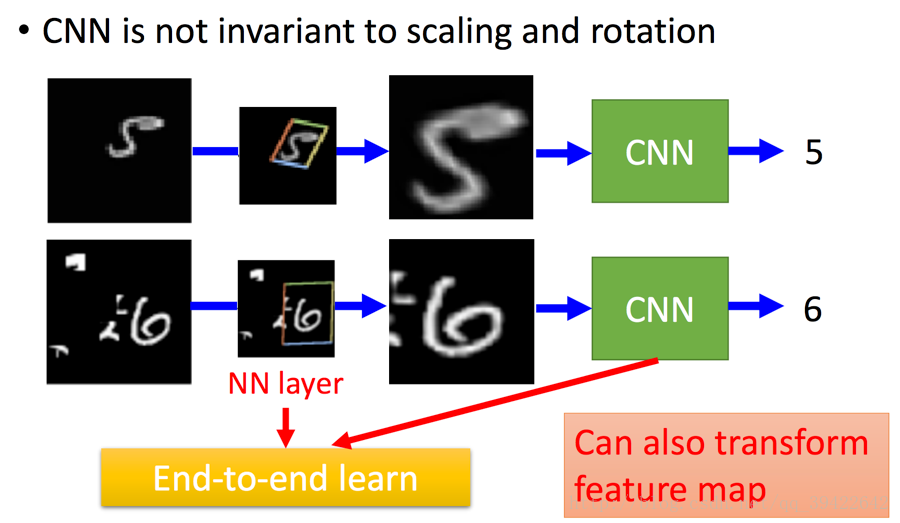
1.1 STN基本架构
- Localisation net:参数预测
- Grid generator:坐标映射
- Sampler:像素的采集

1.1.1 参数的选择(仿射矩阵就可以实现旋转平移放缩):
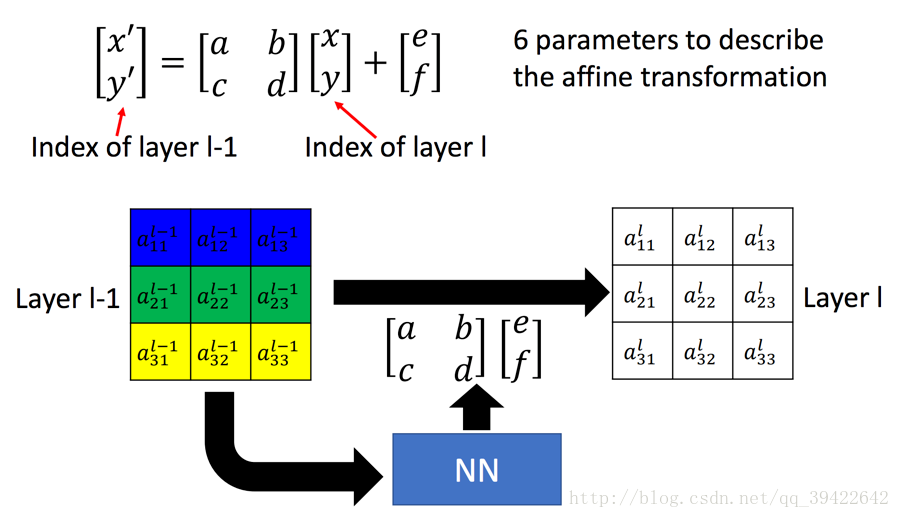
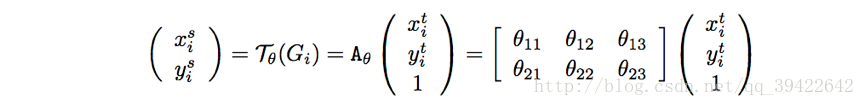
1.1.2 Sampler对目标权值计算(考虑小数对图片的对应, 以便反向传播计算),整个公式:
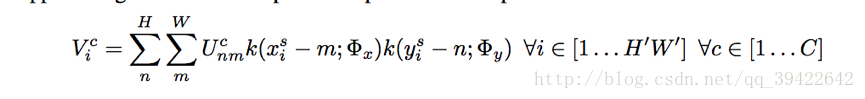
其中,kernel k表示一种线性插值方法,比如双线性插值:
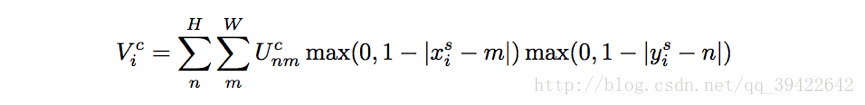
举个例子:
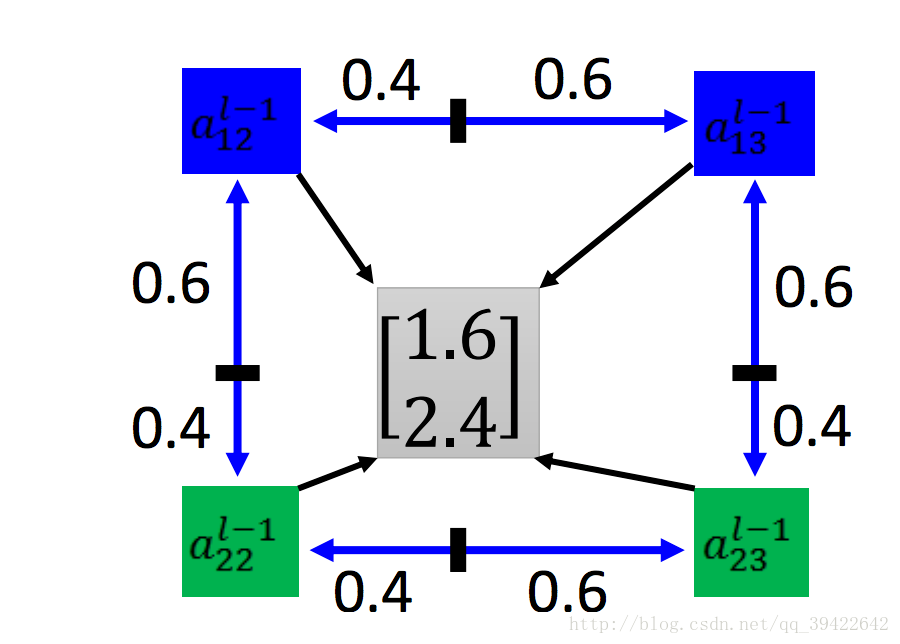
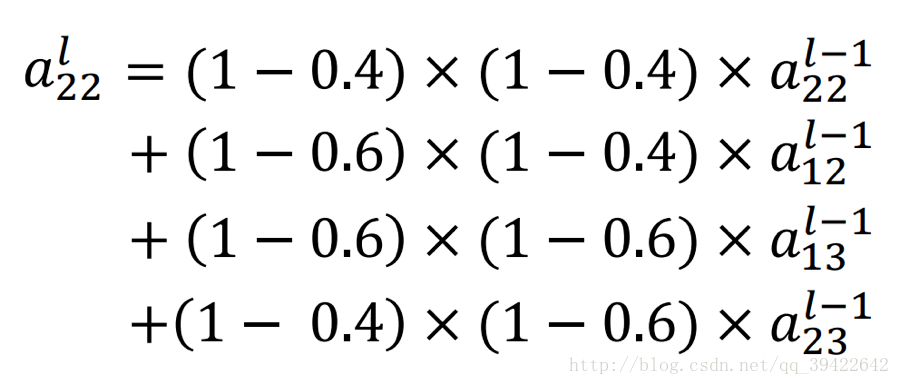
详细解读Spatial Transformer Networks(STN)-一篇文章让你完全理解STN了_黄小猿的博客-CSDN博客_stn算法
Ⅱ. 图像增强
图像增强是有目的地强调图像的整体或局部特性,例如改善图像的颜色、亮度和对比度等,将原来不清晰的图像变得清晰或强调某些感兴趣的特征,扩大图像中不同物体特征之间的差别,抑制不感兴趣的特征,提高图像的视觉效果。传统的图像增强已经被研究了很长时间,现有的方法可大致分为三类,空域方法是直接对像素值进行处理,如直方图均衡,伽马变换;频域方法是在某种变换域内操作,如小波变换;混合域方法是结合空域和频域的一些方法。传统的方法一般比较简单且速度比较快,但是没有考虑到图像中的上下文信息等,所以取得效果不是很好。
一、技术原理🔧
1. 滤波器
1.1 加权最小二乘(WLS)图像滤波
加权最小二乘滤波器是一种保边滤波器,其目标是是滤波结果尽可能接近原图,同时在梯度较小区域尽可能平滑,而强梯度的边缘部分尽可能保持。(图像u 与原始图像 p经过平滑后尽量相似,但是在边缘部分尽量保持原状)

1.2. 卡尔曼平滑(Kalman smoother)
2. 插值Interpolation
2.1 线性插值
已知(x0, y0) 与 (x1, y1),求(x,y)
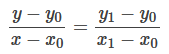
2.2 双线性插值 Bilinear Interpolation
双线性插值本质上就是在两个方向上做线性插值。比如说已知四个Q点的值,求P点:
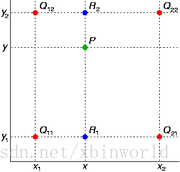
先在x方向线性插值,得到两个R值:
![]()
![]()
然后再y方向线性插值得到P值:
综合一下:![]()
![]()
二、常用库📚
1、albumentations
albumentations包是一种针对数据增强专门写的API,里面基本包含大量的数据增强手段,比起pytorch自带的transform更丰富,搭配使用效果更好。
Index - Albumentations Documentation https://albumentations.ai/docs/api_reference/
https://albumentations.ai/docs/api_reference/
1.1 代码样例
import albumentations as A
# 定义增强
transform = A.Compose([
A.RandomCrop(width=256, height=256, p=1),
A.HorizontalFlip(p=0.5),
])
#图像增强
transformed = transform(image=image, mask=mask)1.2 函数方法
- VerticalFlip:水平翻转
- HorizontalFlip:垂直翻转
- ShiftScaleRotate:平移缩放旋转,随机平移、缩放、旋转图片。
- RandomScale:随机缩放图像大小
- Resize:将输入图像调整为给定的高度和宽度
- RandomSizedCrop:随机裁剪图像并缩放到固定大小
- Transpose:将图像行和列互换
- Normalize
- Blur:图像均值平滑滤波
- GaussianBlur:图像高斯平滑滤波
- GaussNoise:给图像增加高斯噪声
- RandomCrop:随机从图像裁剪一块区域(参数是高宽,而且必须是整数
- CenterCrop:随机中心裁剪图片
- Rotate:随机旋转图片(默认使用reflect方法扩充图片
- RandomRotate90:随机旋转0个或多个90度
- OpticalDistortion:对图像进行光学畸变
- GridDistortion:对图像进行网格失真
- ElasticTransform:随机对图像进行弹性变换
- PiecewiseAffine:以控制点的方式随机形变(扭曲图像···)
- RandomGridShuffle:随机网格洗牌,将图像以网格方式生成几块,并随机打乱。
- Cutout:在图像中生成正方形区域(黑块噪点)
- CoarseDropout:在图像上生成矩形区域
- HueSaturationValue:随机色调、饱和度、值变化。
- RGBShift:随机平移R、G、B通道值。
- ChannelShuffle:随机改变RGB三个通道的顺序
- RandomBrightness:随机亮度变化
- RandomContrast:随机对比度变化
- RandomBrightnessContrast:随机更改输入图像的亮度和对比度
- CLAHE:将对比度受限的自适应直方图均衡化应用于输入图像
1.3 PyTorch的pipeline中自定义数据集使用
from torch.utils.data import Dataset
from albumentations.pytorch import ToTensorV2 #转换为张量
class CustomDataset(Dataset):
def __init__(self, images, masks):
self.images = images # 假设这是一个numpy图像列表
self.masks = masks # 假设这是一个numpy掩码列表
self.transform = A.Compose([
A.RandomCrop(width=256, height=256, p=1),
A.HorizontalFlip(p=0.5),
ToTensorV2,
])
def __len__(self):
return len(self.images)
def __getitem__(self, idx):
"""返回单个样本"""
image = self.images[idx]
mask = self.masks[idx]
transformed = self.transform(image=image, mask=mask)
transformed_image = transformed["image"]
transformed_mask = transformed["mask"]
return transformed_image, transformed_mask2. AutoAugment(2018)
首个采用搜索技术进行自动数据增广的方法
from torchvision.transforms import autoaugment, transforms
train_transform = transforms.Compose([
transforms.RandomResizedCrop(crop_size, interpolation=interpolation),
transforms.RandomHorizontalFlip(hflip_prob),
# 这里policy属于torchvision.transforms.autoaugment.AutoAugmentPolicy,
# 对于ImageNet就是 AutoAugmentPolicy.IMAGENET
# 此时aa_policy = autoaugment.AutoAugmentPolicy('imagenet')
autoaugment.AutoAugment(policy=aa_policy, interpolation=interpolation),
transforms.PILToTensor(),
transforms.ConvertImageDtype(torch.float),
transforms.Normalize(mean=mean, std=std)
])3. RandAugment(2019)
随机自动增广,展示了根据模型和数据集大小的数据增强最优强度,说明在小代理任务中的增强策略是正常增强策略的子最优。
具体地,RandAugment共包含两个超参数:图像增强操作的数量N和一个全局的增强幅度M。每次从候选操作集合(共14种策略)随机选择N个操作(等概率),然后串行执行(这里没有判断概率,是一定执行)。这里的M取值范围为{0, . . . , 30}(每个图像增强操作归一化到同样的幅度范围),而N取值范围一般为 {1, 2, 3}。
from torchvision.transforms import autoaugment, transforms
train_transform = transforms.Compose([
transforms.RandomResizedCrop(crop_size, interpolation=interpolation),
transforms.RandomHorizontalFlip(hflip_prob),
autoaugment.RandAugment(interpolation=interpolation),
transforms.PILToTensor(),
transforms.ConvertImageDtype(torch.float),
transforms.Normalize(mean=mean, std=std)
])4. TrivialAugment
虽然RandAugment的搜索空间极小,但是对于不同的数据集还是需要确定最优的N和M,这依然有较大的实验成本。TrivialAugment每次随机选择一个图像增强操作,然后随机确定它的增强幅度,并对图像进行增强。由于没有任何超参数,所以不需要任何搜索。
from torchvision.transforms import autoaugment, transforms
train_transform = transforms.Compose([
transforms.RandomResizedCrop(crop_size, interpolation=interpolation),
transforms.RandomHorizontalFlip(hflip_prob),
autoaugment.TrivialAugmentWide(interpolation=interpolation),
transforms.PILToTensor(),
transforms.ConvertImageDtype(torch.float),
transforms.Normalize(mean=mean, std=std)
])Ⅲ. 图像分类
BOW(bag of words)模型
BOW模型主要包含以下四个步骤:
- 提取训练集中图片的feature:有SIFT、SUFR算法
- 将这些feature聚成n类。这n类中的每一类就相当于是图片的“单词”,所有的n个类别构成“词汇表”。我的实现中n取1000,如果训练集很大,应增大取值。
- 对训练集中的图片构造bag of words,就是将图片中的feature归到不同的类中,然后统计每一类的feature的频率。这相当于统计一个文本中每一个单词出现的频率
- 训练一个多类分类器,将每张图片的bag of words作为feature vector,将该张图片的类别作为label。
对于未知类别的图片,计算它的bag of words,使用训练的分类器进行分类。
Ⅳ. 图像分割
一、常用库📕
1. segmentation_models_pytorch
- 高级API(只需两行即可创建神经网络);
- 用于二分类和多类分割的9种模型架构(包括传奇的Unet)(Unet、Unet++、MAnet、Linknet、FPN、PSPNet、PAN、DeepLabV3、DeepLabV3+);
- 每种架构有113种可用的编码器;
- 所有编码器均具有预训练的权重,以实现更快更好的收敛。
import segmentation_models_pytorch as smp
model = smp.Unet(
encoder_name="resnet34", # choose encoder, e.g. mobilenet_v2 or efficientnet-b7
encoder_weights="imagenet", # use `imagenet` pre-trained weights for encoder initialization
in_channels=1, # model input channels (1 for gray-scale images, 3 for RGB, etc.)
classes=3, # model output channels (number of classes in your dataset)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









