







目录
- STN的作用
1.1 灵感来源
1.2 什么是STN? - STN的基本架构
- Localisation net是如何实现参数的选取的?
3.1 实现平移
3.2 实现缩放
3.3 实现旋转
3.4 实现剪切
3.5 小结 - Grid generator实现像素点坐标的对应关系
4.1 为什么会有坐标的问题?
4.2 仿射变换关系 - Sampler实现坐标求解的可微性
5.1 小数坐标问题的提出
5.2 解决输出坐标为小数的问题
5.3 Sampler的数学原理 - Spatial Transformer Networks(STN)
- STN 实现代码
- reference
1.STN的作用
1.1 灵感来源
普通的CNN能够显示的学习平移不变性,以及隐式的学习旋转不变性,但attention model 告诉我们,与其让网络隐式的学习到某种能力,不如为网络设计一个显式的处理模块,专门处理以上的各种变换。因此,DeepMind就设计了Spatial Transformer Layer,简称STL来完成这样的功能。
1.2 什么是STN?
关于平移不变性 ,对于CNN来说,如果移动一张图片中的物体,那应该是不太一样的。假设物体在图像的左上角,我们做卷积,采样都不会改变特征的位置,糟糕的事情在我们把特征平滑后后接入了全连接层,而全连接层本身并不具备 平移不变性 的特征。但是 CNN 有一个采样层,假设某个物体移动了很小的范围,经过采样后,它的输出可能和没有移动的时候是一样的,这是 CNN 可以有小范围的平移不变性 的原因。
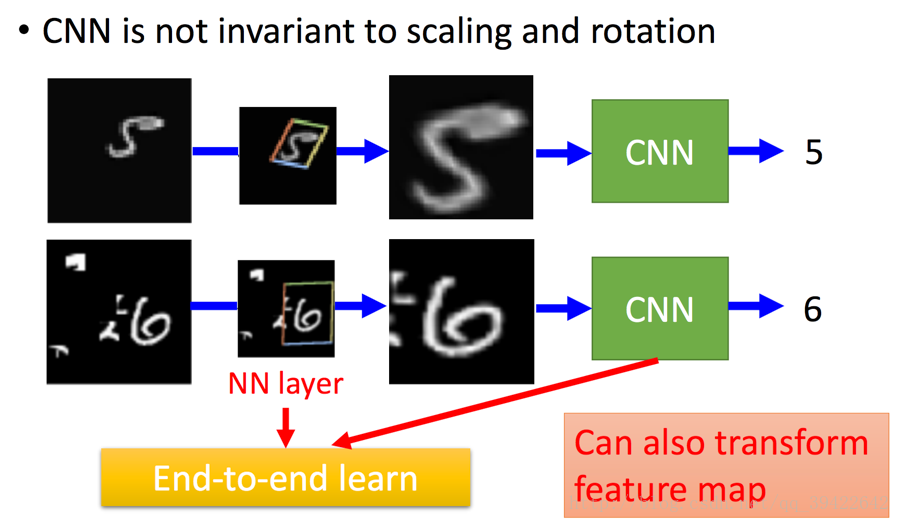
如图所示,如果是手写数字识别,图中只有一小块是数字,其他大部分地区都是黑色的,或者是小噪音。假如要识别,用Transformer Layer层来对图片数据进行旋转缩放,只取其中的一部分,放到之后然后经过CNN就能识别了。
我们发现,它其实也是一个layer,放在了CNN的前面,用来转换输入的图片数据,其实也可以转换feature map,因为feature map说白了就是浓缩的图片数据,所以Transformer layer也可以放到CNN里面。
2. STN的基本架构
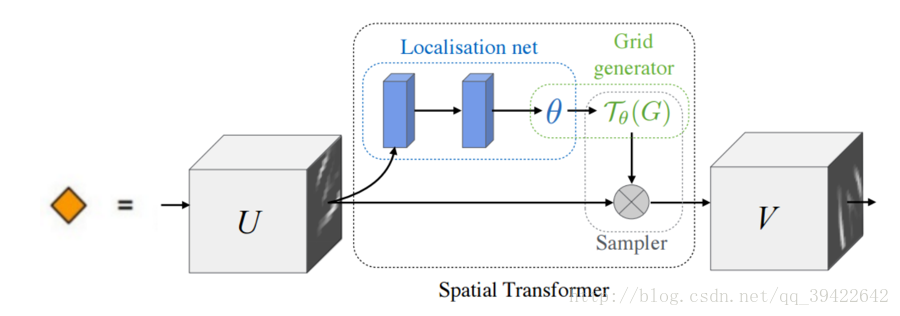
如图是Spatial Transformer Networks的结构,主要的部分一共有三个,它们的功能和名称如下:
如下图是完成的一个平移的功能,这其实就是Spatial Transformer Networks要做一个工作。
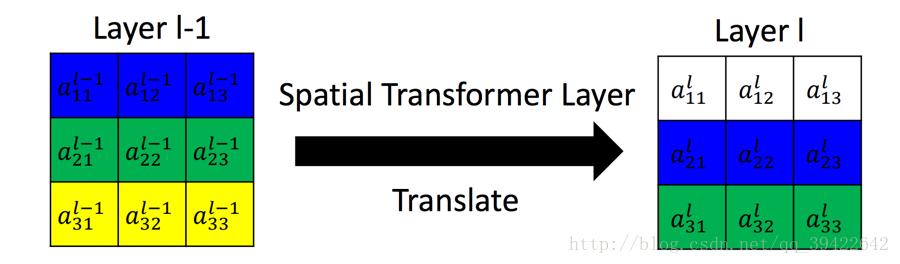
假设左边是 Layer l−1 的输出,也就是当前要做Transform的输入,最右边为Transform后的结果。这个过程是怎么得到的呢?
假设是一个全连接层,n,m代表输出的值在输出矩阵中的下标,输入的值通过权值w,做一个组合,完成这样的变换。
- 举个例子,假如要生成 al11 ,那就是将左边矩阵的九个输入元素,全部乘以一个权值,加权相加:
al11=wl1111al−111+wl1112al−112+wl1113al−113+⋯+wl1133al−133这仅仅是 al11
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 7077
7077

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









