







学习路径:自然语言处理怎么最快入门? - 知乎
0. NLP自然语言处理简史
1950 年代
- Computing Machinery and Intelligence(计算机器与智能), Alan Turing
- Turing test(图灵测试):通过一个对话测试来测量机器智能
- Syntactic Structures(句法结构), Noam Chomsky
- Formal language theory(形式语言理论):使用代数和集合论将形式语言定义为符号序列
- 例如:Colourless green ideas sleep furiously.(无色的绿色思想激烈地沉睡。)
- 该句子从意义上讲不通
- 但它的语法似乎还不错
- 强调了语义(含义)和句法(句子结构)二者的区别
1960-1970 年代
- Symbolic paradigm(符号范式)
- Generative grammar(生成式语法):发现生成语法句子的规则系统
- Parsing algorithms(解析算法)
- Stochastic paradigm(随机范式)
- 贝叶斯方法用于光学字符识别(optical character recognition, OCR)和作者身份署名(authorship attribution)
- 第一个在线语料库:Brown corpus of American English(美式英语布朗语料库)
- 100 万个单词,覆盖 500 种不同类型的文档(新闻、小说等等)
1970-1980 年代
- Stochastic paradigm(随机范式)
- Hidden Markov models(隐马尔可夫模型)、noisy channel decoding(噪声信道解码)
- Speech recognition and synthesis(语音识别与合成)
- Logic-based paradigm(基于逻辑的范式)
- 更多的语法系统:例如,Lexical functional Grammar(词汇功能语法)
- Natural language understanding(自然语言理解)
- Terry Winograd 教授 在 MIT 人工智能实验室创建的 SHRDLU(积木世界)系统
- 嵌入玩具积木世界的机器人
- 程序采用自然语言命令,例如:
move the red block to the left of the blue block(将红色块移动到蓝色块的左侧) - 激发了对 semantics(语义)和 discourse(话语)领域的研究
1980-1990 年代
- Finite-state machines(有限状态机)
- Phonology(语音学)、morphology(词法)和 syntax(句法)
- Return of empiricism(经验主义的回归)
- IBM 为语音识别开发的概率模型
- 在 part-of-speech tagging(词性标注)、parsing(解析)和 semantics(语义)方面启发了其他的数据驱动方法
- 基于 held-out data(保留数据)、quantitative metrics(定量指标),以及和最新技术进行比较的经验主义评估
1990-2000 年代:机器学习的崛起
- 更好的计算能力
- 逐渐减少 Chomskyan theories of linguistics(乔姆斯基语言学理论)的主导地位
- 开发了更多的语料库
- Penn Treebank, PropBank, RSTBank 等
- 涵盖各种形式的 syntactic(句法)、semantic(语义)和 discourse annotations(话语注释)的语料库
- 来自机器学习社区的更好的模型:支持向量机、Logistic 回归
2000 年代:深度学习
- 深度神经网络(即具有许多层的网络)的出现
- 从计算机视觉社区开始进行图像分类
- 优势:使用原始数据作为输入(例如仅是文字和文档),而无需开发手动特征工程
- 计算上昂贵:依靠 GPU 在大型模型和训练数据上进行扩展
- 促进了我们现在正在经历的 AI 浪潮
- 家庭助理和聊天机器人
Ⅰ. 统计机器学习
- 标准定义:对于语言序列 w1,w2,...,wm,语言模型就是计算该序列的概率,即 P(w1,w2,...,wn) 。
- 从机器学习的角度来看:语言模型是对语句的概率分布的建模。
- 通俗解释:判断一个语言序列是否是正常语句,即是否是人话,例如 P(I am Light)> P(Light I am) 。
一、HMM隐含马尔科夫模型
在NLP领域, HMM用来解决文本序列标注问题. 如分词, 词性标注, 命名实体识别都可以看作是序列标注问题。一般以文本序列数据为输入, 以该序列对应的隐含序列为输出。HMM属于生成模型,是有向图。
1. HMM的基本定义: HMM是用于描述由隐藏的状态序列和显性的观测序列组合而成的双重随机过程
2. HMM的假设
- 马尔科夫性假设(Markov assumption)。当前时刻的状态值,仅依赖于前一时刻的状态值,而不依赖于更早时刻的状态值。(“无记忆性”)
- 齐次性假设。状态转移概率矩阵与时间无关。即所有时刻共享同一个状态转移矩阵。
- 观测独立性假设。当前时刻的观察值,仅依赖于当前时刻的状态值。
3. HMM的应用目的:通过可观测到的数据,预测不可观测到的数据。标注任务中,状态值对应着标记,任务会给定观测序列,以预测其对应的标记序列。
4. 使用HMM的三个问题:
- 概率计算问题:给定模型参数和观测序列,计算该观测序列的概率。是后面两个问题的基础。
HMM三个参数:A:状态转移概率矩阵。表征转移概率,维度为N*N。B:观测概率矩阵。表征发射概率,维度为N*M。π:初始状态概率向量。维度为N*1。
- 学习训练问题:给定观测序列,估计模型参数。
HMM两种学习方式:如果训练数据包含观测序列和状态序列则为有监督(通过统计方法,求得模型的状态转移概率矩阵A、观测概率矩阵B、初始状态概率向量π),
如果训练数据只包含观测序列则为无监督(模型使用Baum-Welch算法来求得模型参数)
- 解码预测问题:给定模型参数和观测序列,求概率最大的状态序列。(维特比算法)
5. N-grams 语言模型
- 假设有一个字符串s,那么该字符串的N-Grams就表示按长度 N 切分原词得到的词段,也就是s中所有长度为 N 的子字符串。
- N元模型(N-gram Model)假定文本中每个词w和前N-1个词有关系,而与更前面的词无关,这样当前词w的概率p只取决于前N-1个词P,这个假设叫做N-1阶马尔可夫假设
- N元模型基于语料库 corpus计算条件概率
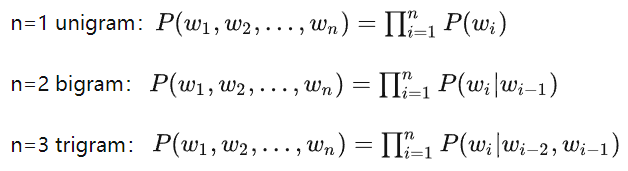
总结下基于统计的 n-gram 语言模型的优缺点:
优点:(1) 采用极大似然估计,参数易训练;(2) 完全包含了前 n-1 个词的全部信息;(3) 可解释性强,直观易理解。
缺点:(1) 缺乏长期依赖,只能建模到前 n-1 个词;(2) 随着 n 的增大,参数空间呈指数增长;(3) 数据稀疏,难免会出现OOV的问题;(4) 单纯的基于统计频次,泛化能力差。
二、CRF模型
CRF(Conditional Random Fields), 中文称作条件随机场, 同HMM一样, 它一般也以文本序列数据为输入, 以该序列对应的隐含序列为输出。CRF用来解决文本序列标注问题. 如分词, 词性标注, 命名实体识别.
- (1)CRF是判别模型,是黑箱模型,不关心概率分布情况,只关心输出结果。
- (2)CRF最重要的工作,是提取特征,构建特征函数。
- (3)CRF使用特征函数给不同的标注网络打分,根据分数选出可能性最高的标注网络。
- (4)CRF模型的计算过程,使用的是以e为底的指数。这个建模思路和深度学习输出层的softmax是一致的。先计算各个可能情况的分数,再进行softmax归一化操作。
学习训练问题:CRF模型采用正则化的极大似然估计最大化概率。
预测解码问题:和HMM完全一样,采用维特比算法进行预测解码
HMM与CRF模型之间差异
- HMM模型存在隐马假设, 而CRF不存在, 因此HMM的计算速度要比CRF模型快很多, 适用于对预测性能要求较高的场合.
- 同样因为隐马假设, 当预测问题中隐含序列单元并不是只与上一个单元有关时, HMM的准确率会大大降低, 而CRF不受这样限制, 准确率明显高于HMM.
- CRF能够获取长文本的远距离依赖的信息,并规避了齐次性,模型能够获取序列的位置信息,并且序列的位置信息会影响预测出的状态序列。
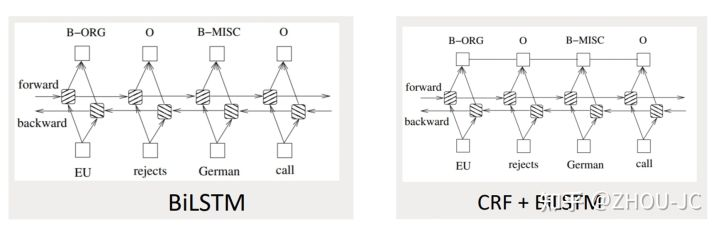
命名实体识别任务要在特征编码层(如RNN、CNN、BERT等 )后接CRF:
双向的LSTM后面接softmax,但此时输出标签之间是没有关系的,加了CRF后,可以建立起输出标签之间的关联关系。
Ⅱ. HuggingFace实战
多种多样的NLP模型
1. BERT:处理各式NLP 任务的通用架构
NLP领域非常流行的两阶段迁移学习:
- 先以LM Pretraining 的方式预先训练出一个对自然语言有一定「理解」的通用模型(*无监督预训练*)
- 再将该模型拿来做特征撷取或是fine tune 下游的(监督式)任务(*监督微调*)
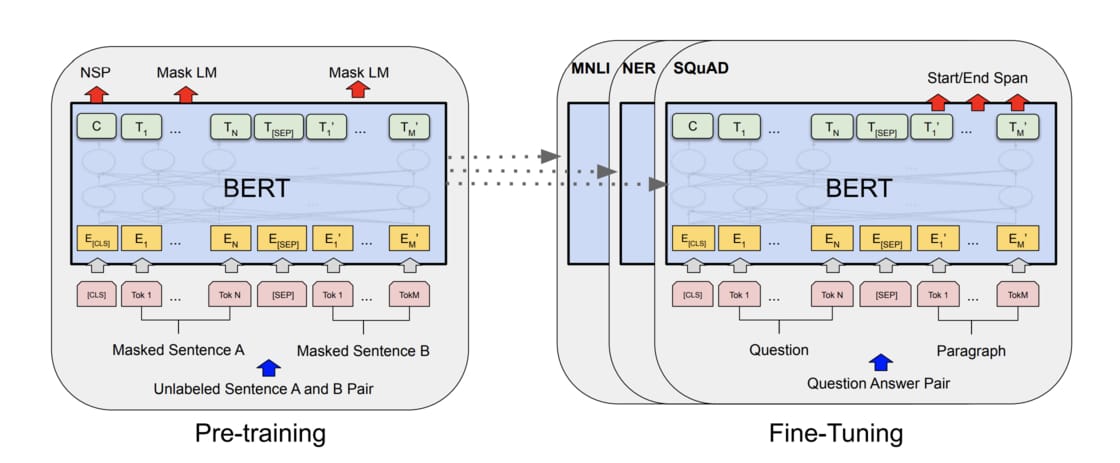
1.1 无监督预训练
预训练BERT时让它同时进行两个任务:
- MLM:漏字填空(Masked Language Model)
- NSP:判断第2个句子在原始文本中是否跟第1个句子相接(Next Sentence Prediction, NSP)
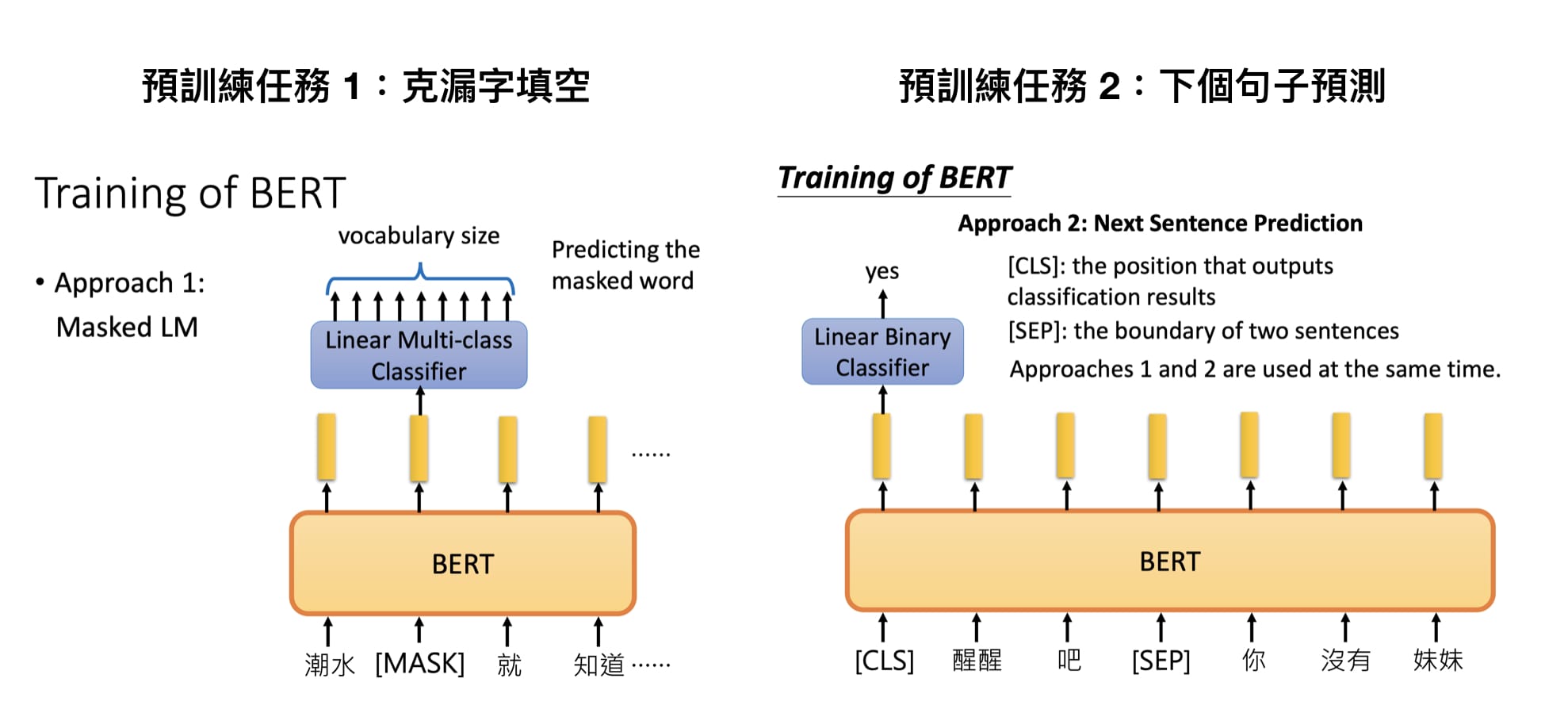
MLM 具体采用的方法是,随机选择 15% 的 tokens 出来,但是并非把它们全部都 MASK 掉,而是:
- 其中的 80% 被替换为 [MASK],类似
my dog is hairy -> my dog is [MASK]。 - 其中的 10% 被替换为一个随机 token,类似
my dog is hairy -> my dog is apple。 - 剩余的 10% 不变。
许多 NLP 任务(比如问答、推理等等)都涉及到句子之间关系的理解,这不会被一般性的语言建模过程学习到。NSP 预训练任务所准备的数据,是从单一语种的语料库中取出两个句子 Si 和 Sj,其中 50% 的情况下 B 就是实际跟在 A 后面的句子,50% 的情况下 B 是随机取的。这样语言模型就是在面对一个二元分类问题进行预训练,比如:
INPUT: [CLS] the man went to [MASK] store [SEP]
he bought a gallon [MASK] milk [SEP]
LABEL: IsNextBERT中的文本处理
BERT使用当初Google NMT提出的WordPiece Tokenization,将本来的words拆成更小粒度的wordpieces,有效处理不在字典里头的词汇(OOV)。中文的话大致上就像是character-level tokenization,而有##前缀的tokens即为wordpieces。
以词汇fragment来说,其可以被拆成frag与##ment两个pieces,而一个word也可以独自形成一个wordpiece。wordpieces可以由搜集大量文本并找出其中常见的pattern取得。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('bert-base-cased')
text = "[CLS] 等到潮水 [MASK] 了,就知道谁沒穿裤子。"
tokens = tokenizer.tokenize(text) #中文断句
ids = tokenizer.convert_tokens_to_ids(tokens) #转换为文本id除了一般的wordpieces 以外,BERT 里头有5 个特殊tokens 各司其职:
[CLS]:在做分类任务时其最后一层的repr. 会被视为整个输入序列的repr.[SEP]:有两个句子的文本会被串接成一个输入序列,并在两句之间插入这个token 以做区隔[UNK]:没出现在BERT 字典里头的字会被这个 token 取代[PAD]:zero padding 遮罩,将长度不一的输入序列补齐方便做batch 运算[MASK]:未知遮罩,仅在预训练阶段会用到- 如上例所示,[CLS]一般会被放在输入序列的最前面,而zero padding在之前的Transformer文章里已经有非常详细的介绍。[MASK]token一般在fine-tuning或是feature extraction时不会用到
代码实例
transformers库设计:
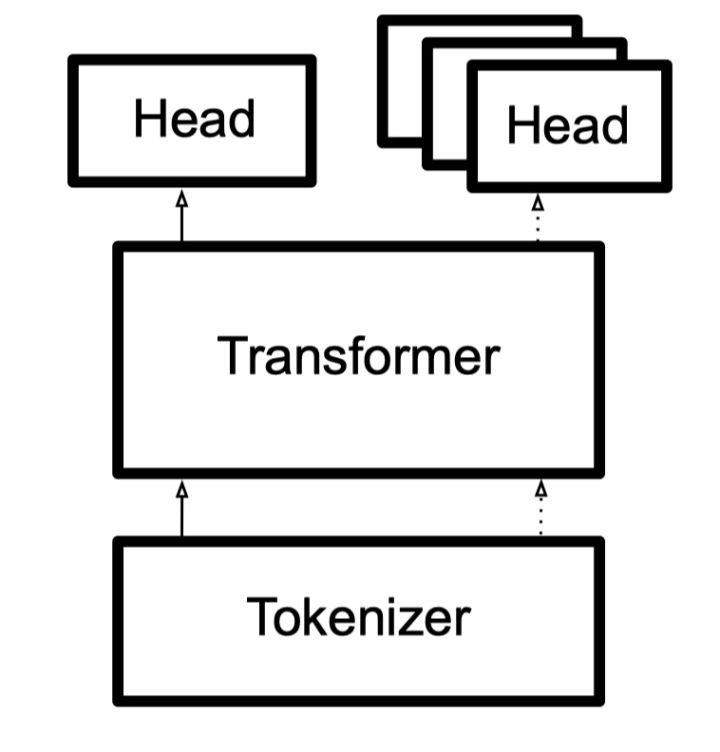
- Tokenizer 类支持从预训练模型中进行加载或者直接手动配置
- transformers 提供 一系列的Auto classes,使得快速进行模型切换非常方便。
- Head 不同于attention的head,这边的 head 指的是下游任务的输出层,它将模型的contextual embedding 转化为特定任务的预测值
- Pretraining Head
- Casual Language Modeling(普通自回归的语言模型):GPT, GPT-2,CTRL
- Masked Language Modeling(掩码语言模型):BERT, RoBERTa
- Permuted Language Modeling(乱序重排语言模型):XLNet
- Fine-tuning Head
- Language Modeling:语言模型训练,预测下一个词。主要用于文本生成
- Sequence Classification:文本分类任务,情感分析任务
- Question Answering:机器阅读理解任务,QA
- Token Classification:token级别的分类,主要用于命名实体识别(NER)任务,句法解析Tagging任务
- Multiple Choice:多选任务,主要是文本选择任务
- Masked LM:掩码预测,随机mask一个token,预测该 token 是什么词,用于预训练
- Conditional Generation:条件生成任务,主要用于翻译以及摘要任务。
#导入模型和对应分词器
from transformers import BertModel, BertTokenizer, CTRLModel, CTRLTokenizer, TransfoXLModel, TransfoXLTokenizer, XLNetModel, XLNetTokenizer, XLMModel, XLMTokenizer, DistilBertModel, DistilBertTokenizer, RobertaModel, RobertaTokenizer
from transformers import AutoTokenizer, AutoModelForMaskedLM
#载入预训练数据
tokenizer = AutoTokenizer.from_pretrained("bert-base-chinese")
model = AutoModelForMaskedLM.from_pretrained("bert-base-chinese")
vocab = tokenizer.vocab #字典大小
#进行下游的文本分类任务
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(checkpoint, num_labels=2encode和encode_plus和tokenizer的区别
Tokenizer 返回的是一个字典,里面的列表包含了int类别的数据。
encoded_input = tokenizer("Hello, I'm a single sentence!")
print(encoded_input)
# {'input_ids': [101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102],
# 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
# 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}- “input_id”是对应于文本序列中每个token的索引(在vocab中的索引);
- “token_type_ids”是对应于不同的文本序列,例如在NSP(BERT及某些语言模型中的“Next Sentence Prediction”)任务中需要输入两个文本序列。
- “attention_mask”是对应于注意力机制的计算,各元素的值为0或1,如果当前token被mask或者是只是用来作为填充的元素,那么其不需要进行注意力机制的计算,其值为0;
tokenizer解码:
tokenizer.decode(encoded_input["input_ids"])
# "[CLS] Hello, I'm a single sentence! [SEP]"[CLS]字符就是大多数预训练语言模型会自动加入的特殊token。tokenizer会自动添加了模型期望的一些特殊token。可以通过传递add_special_tokens = False来禁用加入特殊token
tokenizer也可输入列表:
batch_sentences = ["Hello I'm a single sentence",
"And another sentence",
"And the very very last one"]
encoded_inputs = tokenizer(batch_sentences)
print(encoded_inputs)
# {'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
# [101, 1262, 1330, 5650, 102],
# [101, 1262, 1103, 1304, 1304, 1314, 1141, 102]],
# 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0],
# [0, 0, 0, 0, 0, 0, 0, 0]],
# 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1],
# [1, 1, 1, 1, 1],
# [1, 1, 1, 1, 1, 1, 1, 1]]}填充(padding)和截断(truncation)
一个batch中的序列长度不一致时,
三个参数padding,truncation和max_length
encode和encode_plus的区别
1. encode仅返回input_ids
2. encode_plus返回所有的编码信息,具体如下:
’input_ids:是单词在词典中的编码
‘token_type_ids’:区分两个句子的编码(上句全为0,下句全为1)
‘attention_mask’:指定对哪些词进行self-Attention操作
import torch
from transformers import BertTokenizer
model_name = 'bert-base-uncased'
# a.通过词典导入分词器
tokenizer = BertTokenizer.from_pretrained(model_name)
sentence = "Hello, my son is laughing."
print(tokenizer.encode(sentence))
print(tokenizer.encode_plus(sentence))
#[101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102]
#{'input_ids': [101, 7592, 1010, 2026, 2365, 2003, 5870, 1012, 102],
#'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0],
#'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1]}学习率预热
from transformers import get_cosine_schedule_with_warmup,
get_linear_schedule_with_warmup
sch = get_linear_schedule_with_warmup(
optimizer, #优化器 包含lr参数
num_warmup_steps= 0, #预热阶段的步骤数
num_training_steps, #训练的总步骤数
last_epoch=-1 #恢复训练时最后一个epoch的索引
)Ⅲ. NLP对抗训练
对抗训练有两个作用,一是提高模型对恶意攻击的鲁棒性,二是提高模型的泛化能力。
对抗训练旨在对原始输入样本 x 上施加扰动 r_adv,得到对抗样本后用其进行训练:
- 最大化扰动:挑选一个能使得模型产生更大损失(梯度较大)的扰动量,作为攻击;
- 最小化损失:根据最大的扰动量,添加到输入样本后,朝着最小化含有扰动的损失(梯度下降)方向更新参数;
这个被构造出来的“对抗样本”并不能具体对应到某个单词,因此,反过来在推理阶段是没有办法通过修改原始输入得到这样的对抗样本。
常用的几种对抗训练方法有FGSM、FGM、PGD、FreeAT、YOPO、FreeLB、SMART。
一、FGM算法
- 首先计算输入样本x(通常为word embedding)的损失函数以及在x 处的梯度:
- 计算在输入样本的扰动量:
,其中 ϵ 为超参数,默认取1.0;
- 得到对抗样本:
- 根据得到的对抗样本,再次喂入模型中,计算损失,并累积梯度;
- 恢复原始的word embedding,接着下一个batch。
import torch
class FGM():
def __init__(self, model):
self.model = model
self.backup = {} # 用于保存模型扰动前的参数
def attack(self, epsilon=1.,
emb_name='word_embeddings' # emb_name表示模型中embedding的参数名
):
'''
生成扰动和对抗样本
'''
for name, param in self.model.named_parameters(): # 遍历模型的所有参数
if param.requires_grad and emb_name in name: # 只取word embedding层的参数
self.backup[name] = param.data.clone() # 保存参数值
norm = torch.norm(param.grad) # 对参数梯度进行二范式归一化
if norm != 0 and not torch.isnan(norm): # 计算扰动,并在输入参数值上添加扰动
r_at = epsilon * param.grad / norm
param.data.add_(r_at)
def restore(self,
emb_name='word_embeddings' # emb_name表示模型中embedding的参数名
):
'''
恢复添加扰动的参数
'''
for name, param in self.model.named_parameters(): # 遍历模型的所有参数
if param.requires_grad and emb_name in name: # 只取word embedding层的参数
assert name in self.backup
param.data = self.backup[name] # 重新加载保存的参数值
self.backup = {}
训练的时候再添加五行:
fgm = FGM(model) # (#1)初始化
for batch_input, batch_label in data:
loss = model(batch_input, batch_label) # 正常训练
loss.backward() # 反向传播,得到正常的grad
# 对抗训练
fgm.attack() # (#2)在embedding上添加对抗扰动
loss_adv = model(batch_input, batch_label) # (#3)计算含有扰动的对抗样本的loss
loss_adv.backward() # (#4)反向传播,并在正常的grad基础上,累加对抗训练的梯度
fgm.restore() # (#5)恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()
二、PGD算法
Project Gradient Descent(PGD)是一种迭代攻击算法,相比于普通的FGM 仅做一次迭代,PGD是做多次迭代,每次走一小步,每次迭代都会将扰动投射到规定范围内。形式化描述为:
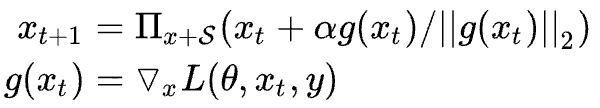
扰动约束空间为一个球体,原始的输入样本对应的初识点为球心,迭代多次后,避免扰动超过球面。
import torch
class PGD():
def __init__(self, model):
self.model = model
self.emb_backup = {}
self.grad_backup = {}
def attack(self, epsilon=1., alpha=0.3, emb_name='word_embeddings', is_first_attack=False):
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
if is_first_attack:
self.emb_backup[name] = param.data.clone()
norm = torch.norm(param.grad)
if norm != 0 and not torch.isnan(norm):
r_at = alpha * param.grad / norm
param.data.add_(r_at)
param.data = self.project(name, param.data, epsilon)
def restore(self, emb_name='word_embeddings'):
for name, param in self.model.named_parameters():
if param.requires_grad and emb_name in name:
assert name in self.emb_backup
param.data = self.emb_backup[name]
self.emb_backup = {}
def project(self, param_name, param_data, epsilon):
r = param_data - self.emb_backup[param_name]
if torch.norm(r) > epsilon:
r = epsilon * r / torch.norm(r)
return self.emb_backup[param_name] + r
def backup_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.grad_backup[name] = param.grad.clone()
def restore_grad(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
param.grad = self.grad_backup[name]
训练的时候添加:
pgd = PGD(model)
K = 3
for batch_input, batch_label in data:
# 正常训练
loss = model(batch_input, batch_label)
loss.backward() # 反向传播,得到正常的grad
pgd.backup_grad()
# 累积多次对抗训练——每次生成对抗样本后,进行一次对抗训练,并不断累积梯度
for t in range(K):
pgd.attack(is_first_attack=(t==0)) # 在embedding上添加对抗扰动, first attack时备份param.data
if t != K-1:
model.zero_grad()
else:
pgd.restore_grad()
loss_adv = model(batch_input, batch_label)
loss_adv.backward() # 反向传播,并在正常的grad基础上,累加对抗训练的梯度
pgd.restore() # 恢复embedding参数
# 梯度下降,更新参数
optimizer.step()
model.zero_grad()
三、VAT虚拟对抗训练
抽取一个随机标准正态扰动,加到embedding上,并用KL散度计算扰动的梯度,然后用得到的梯度,计算对抗扰动,并进行对抗训练,实现方法跟FGM差不多。特别提到的一点是,因为其思路也有额外的一致性损失的loss,因此可以用于半监督学习,在无监督数据集合上计算一致性的loss。
Ⅳ. NLP比赛提分技巧
1. EMA指数移动平均
EMA在深度学习的优化过程中,是t时刻的模型权重weights,是t时刻的影子权重(shadow weights)。在梯度下降的过程中,会一直维护着这个影子权重,但是这个影子权重并不会参与训练。基本的假设是,模型权重在最后的n步内,会在实际的最优点处抖动,所以我们取最后n步的平均,能使得模型更加的鲁棒。
EMA对第i步的梯度下降的步长增加了权重系数 ,相当于做了一个learning rate decay。
在保存模型或者评估模型时,会利用影子权重进行评估,如果效果比当前效果好,则保存影子权重的参数,但是之后在继续训练的时候会还原之前的参数进行训练。
class EMA():
def __init__(self, model, decay):
self.model = model
self.decay = decay
self.shadow = {}
self.backup = {}
def register(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
self.shadow[name] = param.data.clone()
def update(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
new_average = (1.0 - self.decay) * param.data + self.decay * self.shadow[name]
self.shadow[name] = new_average.clone()
def apply_shadow(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.shadow
self.backup[name] = param.data
param.data = self.shadow[name]
def restore(self):
for name, param in self.model.named_parameters():
if param.requires_grad:
assert name in self.backup
param.data = self.backup[name]
self.backup = {}
# 初始化
ema = EMA(model, 0.999)
ema.register()
# 训练过程中,更新完参数后,同步update shadow weights
def train():
optimizer.step()
ema.update()
# eval前,apply shadow weights;eval之后,恢复原来模型的参数
def evaluate():
ema.apply_shadow()
# evaluate
ema.restore()
2. UDPLoss, RDropLoss
在正常的监督学习损失外,增加一个一致性损失((一般是kl散度)),也有多drop层这种
Ⅴ. 实战汇总
Ⅵ. 提分策略
SWA, Apex AMP & Interpreting Transformers in Torch | Kaggle
1.文本特征token:长度(Seq Length)限制进行截断
- pre-truncate
- post-truncate
- middle-truncate (head + tail)
2.增加特征(附加信息)
- Bert 输入端,添加 special tokens(如类别信息 [CAT=CULTURE])
tokens : [CLS] [CAT=CULTURE] question [SEP] answer [SEP]
input_ids : 101 1 3322 102 9987 102
segment_ids: 0 0 0 0 1 1- Bert 输出端,直接做 embedding, 然后与文本特征的 Vector Representation 进行融合
emb = nn.Embedding(10, 32) # 初始化一个 Embedding 层
meta_vector = emb(cat) # 将类别编码成 vector
logits = torch.cat([txt_vector, meta_vector], dim=-1) # 文本向量和类别向量融合3. Pseudo-labeling
1. 训练集上训练得到 model1;
2. 使用 model1 在测试集上做预测得到有伪标签的测试集;
3. 使用训练集+带伪标签的测试集训练得最终模型 model2;伪标签数据可以作为训练数据而被加入到训练集中,是因为神经网络模型有一定的容错能力。需要注意的是伪标签数据质量可能会很差,在使用过程中要多加小心,比如不要用在 validation set 中。
4. pooling技巧
Transformers 三种输出形式:
- pooler output (batch size, hidden size) : 句嵌入,即CLS token的embedding
- last hidden state (batch size, seq Len, hidden size) 最后隐藏层
- hidden states (n layers, batch size, seq Len, hidden size) - 所有的隐藏层
Weighted Layer Pooling
5. 随机权重平均(SWA)
SWA通过对训练过程中多个时间点的模型权重(checkpoint)求平均达到集成的效果,并且该方法不会为训练增加额外的消耗,也不会增加计算量,同时该方法还可以嵌入到Pytorch中的任何优化器类中。
Stochastic Weight Averaging in PyTorch | PyTorch (即插即用?)
6. Multi-Sample Dropout
可以看做是对传统dropout的一种改进,同一样本经过多次dropout, 由于dropout具有随机性,可以得到多个不同的样本。基于连续的dropout,加快模型收敛,提升泛化能力。
7. 分层学习率
def get_grouped_params(args, model):
no_decay = ["bias", "LayerNorm.weight"]
group1 = ['layer.0.', 'layer.1.', 'layer.2.', 'layer.3.']
group2 = ['layer.4.', 'layer.5.', 'layer.6.', 'layer.7.']
group3 = ['layer.8.', 'layer.9.', 'layer.10.', 'layer.11.']
group_all = ['layer.0.', 'layer.1.', 'layer.2.', 'layer.3.', 'layer.4.', 'layer.5.', 'layer.6.', 'layer.7.','layer.8.', 'layer.9.', 'layer.10.', 'layer.11.']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.bert_named_params() if not any(nd in n for nd in no_decay) and not any(nd in n for nd in group_all)],'weight_decay': args.weight_decay},
{'params': [p for n, p in model.bert_named_params() if not any(nd in n for nd in no_decay) and any(nd in n for nd in group1)],'weight_decay': args.weight_decay, 'lr': args.bert_lr 2},
{'params': [p for n, p in model.bert_named_params() if
not any(nd in n for nd in no_decay) and any(nd in n for nd in group2)],
'weight_decay': args.weight_decay, 'lr': args.bert_lr},
{'params': [p for n, p in model.bert_named_params() if
not any(nd in n for nd in no_decay) and any(nd in n for nd in group3)],
'weight_decay': args.weight_decay, 'lr': args.bert_lr * 2},
{'params': [p for n, p in model.bert_named_params() if
any(nd in n for nd in no_decay) and not any(nd in n for nd in group_all)], 'weight_decay': 0.0},
{'params': [p for n, p in model.bert_named_params() if
any(nd in n for nd in no_decay) and any(nd in n for nd in group1)], 'weight_decay': 0.0,
'lr': args.bert_lr 2},
{'params': [p for n, p in model.bert_named_params() if
any(nd in n for nd in no_decay) and any(nd in n for nd in group2)], 'weight_decay': 0.0,
'lr': args.bert_lr},
{'params': [p for n, p in model.bert_named_params() if
any(nd in n for nd in no_decay) and any(nd in n for nd in group3)], 'weight_decay': 0.0,
'lr': args.bert_lr * 2},
{'params': [p for n, p in model.base_named_params()], 'lr': args.learning_rate, "weight_decay": args.weight_decay}]
return optimizer_grouped_parameters
optimizer_bert_parameters = get_grouped_params(args, model)
optimizer = torch.optim.AdamW(optimizer_bert_parameters, lr=args.bert_lr, eps=args.eps) Ⅶ.模型加速
- 梯度累加(Gradient Accumulation):调整更新步长,模拟大批量
- 自动混合精度(AMP):梯度缩放
Ⅷ. Tokenization
1. Word Presentation -> Word Embeddings
- 一词多义问题:word2vec 或 GloVe中,词嵌入(Word Embeddings)方法都是在语料库中词之间的共现(co-occurrence)统计进行预训练的。但一个词可能有多个意思,完全没有考虑上下文语境
![]()
![]()
ELMo 会根据上下文信息给一个词编码出一个词向量。这样的词表示方法被称为「Contextual Word Representations,CWRs」。GPT、BERT 也都是用关注上下文的方法做词表示(只不过关注的范围有差异)
- See-Themselve 问题:在预训练的词向量生成过程中,当学习输入的文本语料时,其中已经包含了自己,则在词表示上形成了递归
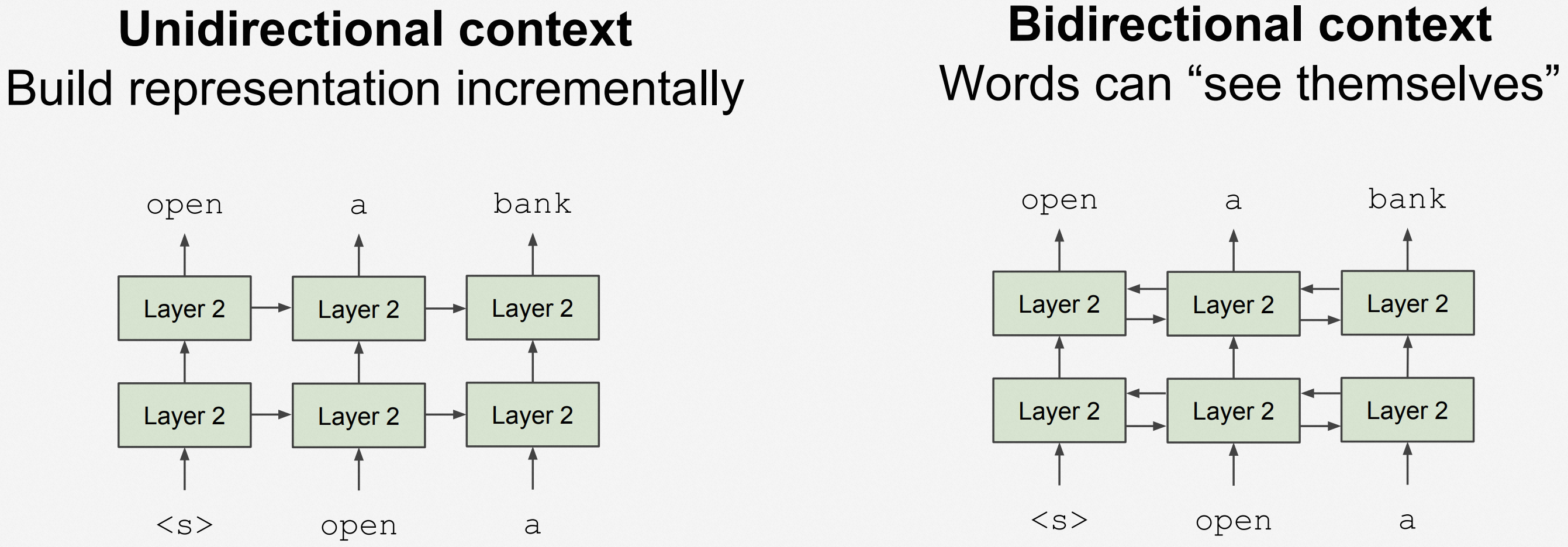
ELMo 用了 BiLSTM,对于任何一个输入文本,用一个 Left-to-Right 的单向 LSTM 模型和一个 Right-to-Left 的单向 LSTM 模型,从而避免了「See-Themselves」问题
















 3685
3685











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









