






数据库:DataBase(DB),存储和管理数据的仓库 数据库管理系统:DataBase Management System(DBMS),操作和管理数据库的大型软件 SQL:Structured Query language,操作关系型数据库的编程语言,定义了一套操作关系型数据库的统一标准
英文:
Columns字段
Duplicate重复
generated产生(自动增长)数据类型:
数值类型
tinyint 1byte -128~127 tinyint unsigned 0~255
smallint 2byte
mediumint 3byte
int 4byte
bigint 8byte
float 4byte float(5,2)整个数字长度5,小数位个数2
double 8byte double(5,2)
decimal 按字符串处理小数 decimal(5,2)
字符串类型:
char 0~255byte 定长字符串
varchar 0~65535byte 变长字符串
tinyblob blob mediumblob longblob 二进制数据 视频/音频等
text... 文本数据
日期类型:
date
time
year
datetime 1000-01-01 00:00:00 - 9999-12-31 23:59:59
timestamp 1970-01-01 00:00:01 - 2038-01-19 03:14:07 时间戳
SQL通用语法:
指令结束须加上分号
注释:-- 或#(MySQL独有#) 多行:/**/DDL
DDL:Data Definition Language数据定义语言,定义数据库对象(数据库、表、字段)
数据库:database=schema
查询:
查询所有数据库show databases;
查询当前数据库select database();
创建:
创建数据库:create database [if not exists]数据库名
使用:
use 数据库名;
删除:
drop database[if exists]数据库名
表:
创建:
create table 表名(
字段1 类型 [约束][comment 注释],
字段2 类型 [约束][comment 注释]
)[comment 注释]
约束:
非空约束 not null
唯一约束 unique
主键约束 primary key 非空唯一
默认约束 default 默认值
外键约束 foreign key 让两张表建立连接,保证数据一致性和完整性
查询:
查询所有表:show tables;
查询表结构: desc 表名;
查询建表语句:show create table 表名;
修改:
字段相关:
添加字段:
alter table 表名 add 字段名 类型(长度) [comment][约束];
修改字段类型:
alter table 表名 modify 字段名 新数据类型(长度);
修改字段名和字段类型:
alter table 表名 change 旧字段名 新字段名 类型(长度) [comment][约束];
删除字段:
alter table 表名drop column字段名;
修改表名:
rename table 表名 to 新表名
删除:
drop table if exists 表名;
show databases ;
select database();
use fruitdb;
show databases ;
use first;
create table tb_user(
id int primary key auto_increment comment 'ID',
username varchar(64) comment '英文名',
name varchar(32) comment '姓名',
age tinyint unsigned comment '年龄',
gender char(1) comment '性别'
)comment '用户表';
show tables;
desc tb_user;
show create table tb_user;
alter table tb_user add column create_time date;
alter table tb_user add column update_time datetime;
DML
DML:Data Manipulation Language数据操作语言,对数据库表中的数据进行增删改
增:insert
指定字段添加数据:insert into 表名(字段1,字段2) values(值1,值2)
全部字段添加数据:insert into 表名 values(值1,值2...)
批量添加数据(指定字段):insert into表名(字段1) values (值1,值2),(值1,值2)
批量添加数据(全部字段):insert into 表名 values (值...),(值...)
删:delete
delete from 表名[where条件]
注意:不能删除具体某个字段的值
改 :update
update 表名 set 字段1=值1,字段2=值2... [where条件]
常用函数:
now() 当前时间
insert into tb_user(username, name, age, gender,create_time) values ('wujiu','张无忌',14,1,now());
insert into tb_user values (null,'xiexun','谢逊',23,1,now());
update tb_user set username='zhangsan',name='张三' where id=2;
update tb_user set update_time=now();DQL
DQL:Data Query Language数据查询语言,用来查询数据库表的记录
select [distinct去重]字段列表[as别名] from 表名列表 [where条件][group by分组字段列表][having分组后条件列表][order by排序字段列表][limit分页参数]
条件查询
比较运算符:
> >= < <= =
<>或!= 不等于
between..小.and..大. 某个范围之内,闭区间
in(...) 在in之后列表中的值,多选一,满足其中一个就可以
like 占位符 模糊匹配(_匹配单个字符,%匹配任意字符)
is null 是null
and 或 &&
or 或 ||
not 或 !
分组查询:
聚合函数:
count、max、min、avg、sum
聚合函数不对null进行计算
where和having的区别:
执行时机不同:where是分组之前的过滤,不满足where条件,不参与分组,而having、是分组之后对结果进行过滤
判断条件不同:where不能对聚合函数进行判断,而having可以
where>聚合函数>having
排序查询:
asc:升序(默认)
desc:降序
分页查询:
limit 起始索引(0开始),查询记录数
起始索引=(页码-1)*每页记录数
首页起始索引可以省略
方言
# 基础查询
select name,entrydate from tb_emp ;
# 不推荐* 性能低/不直观
select * from tb_emp;
# 加引号 别名就可以写特殊字符
select name '姓 名' ,entrydate 入职日期 from tb_emp;
select distinct job from tb_emp;
# 条件查询
select * from tb_emp where name='杨逍';
select * from tb_emp where id<=5;
select * from tb_emp where job is null;
select * from tb_emp where entrydate between '2000-01-01' and '2010-01-01' and gender=2;
select * from tb_emp where job=2 or job=3 or job=4;
select * from tb_emp where job in (2,3,4);
# 姓名两个字
select * from tb_emp where name like '__';
# 姓张
select * from tb_emp where name like '张%';
# 分组查询
# 统计企业员工数量count(字段/常量(0/'a'等)/*)
# 聚合函数不对null进行计算
select count(0) from tb_emp;
select min(entrydate) from tb_emp;
# 根据性别分组,统计男性和女性员工数量
select gender,count(*) from tb_emp group by gender;
# 先查询入职时间20150101之前的员工,并对结果根据职位分组,获取员工数量大于等于2的职位
select job,count(*) workerNum from tb_emp where entrydate<='2015-01-01' group by job having workerNum >=2;
# 案例:完成员工职位信息统计
# if(条件表达式,true,false)
# case 表达式 when 值1 then 结果 when...else...end,
select if(gender=1,'男性','女性') 性别,count(*) from tb_emp group by gender;
select case job when 1 then '班主任' when 2 then '讲师' when 3 then '学工主管' when 4 then '教研主管' else '无工作' end ,count(*) from tb_emp group by job;
# 排序查询
select * from tb_emp order by entrydate desc;
# 第一个字段值相同,第二个生效
select * from tb_emp order by entrydate,update_time desc ;
# 分页查询
# 第二页
select * from tb_emp limit 5,5;多表设计
多表设计
一对多(多对一):多的外键
一对一:任意一方设置外键关联对方主键,并且设置外键唯一
多对多:借助中间表,两个外键关联对方主键
外键约束:
物理外键:foreign key
create table 表名(
字段名 数据类型,
[constraint] [外键名称] foreign key(外键字段名) references 主表(字段名)
)
alter table 表名 add constraint 外键名称 foreign key(外键字段名) references 主表(字段名)
缺点:
1.影响增删改的效率(需要检查外键关系)
2.仅用于单节点数据库,不适用分布式、集群场景
3.容易引发死锁问题,消耗性能
逻辑外键:在业务逻辑中,解决外键关联
Diagrams->show Visualization多表查询
多表查询
笛卡尔积:A集合和B集合所有的组合情况
连接查询:
内连接:相当于查询A、B交集部分数据
隐式内连接:select 字段列表 from 表1,表2 where
显式内连接:select 字段列表 from 表1 join 表2 on 连接条件
外连接:
左外连接:查询左表所有数据(包括两张表交集部分数据)
select 字段列表 from 表1 left join 表2 on 连接条件
右外连接:查询右表所有数据
子查询:查询中嵌套查询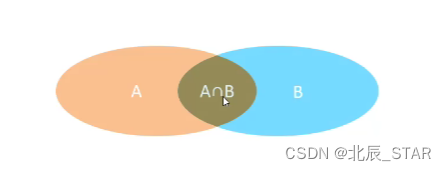
# 多表查询
# 内连接
# 查询员工姓名和部门名称
select e.name 员工姓名,d.name 部门名称 from tb_dept d,tb_emp e where e.dept_id=d.id;
select tb_emp.name 员工姓名,tb_dept.name 部门名称 from tb_emp join tb_dept on tb_emp.dept_id=tb_dept.id;
# 外连接
# 查询所有员工姓名和部门名称
select te.name,td.name from tb_emp te left join first.tb_dept td on te.dept_id = td.id
# 查询所有部门名称和员工姓名
select te.name,td.name from tb_emp te right join first.tb_dept td on te.dept_id = td.id
# 子查询
# 标量子查询
# 查询教研部的员工信息
select * from tb_emp where dept_id=(select id from tb_dept where name='教研部');
# 查询方东白入职之后的员工信息
select * from tb_emp where entrydate>(select entrydate from tb_emp where name='方东白');
# 列子查询
# 查询教研部和咨询部的员工信息
select * from tb_emp where dept_id in (select id from tb_dept where name='教研部' or name= '咨询部');
# 行子查询
# 查询与韦一笑的入职日期和职位相同的员工信息
select * from tb_emp where (entrydate,job)=(select entrydate,job from tb_emp where name='韦一笑');
# 表子查询
# 查询入职日期20060101之后的员工信息及其部门名称
select e.*,d.name from (select * from tb_emp where entrydate>'2006-01-01')e,tb_dept d where e.dept_id=d.id;
事务
事务
事务:一组操作的集合,是一个不可分割的工作单位。事务会把所有操作作为一个整体一起向系统提交。即这些操作,要么同时成功,要么同时失败。
开启事务:start transaction /begin
提交:commit
回滚:rollback
四大特性:
原子性 Atomicity 事务是不可分割的最小单元,要么全部成功,要么全部失败
一致性 Consistency 事务完成时,必须使所有的数据都保持一致状态
隔离性 Isolation 数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行
持久性 Durability 事务一旦提交或回滚,他对数据库中数据的改变是永久的
索引
索引
索引index 帮助数据库 高效获取数据 的 数据结构
占用存储空间,提高查询效率,降低增删改效率
数据结构:B+ Tree 多路平衡搜索树
语法:
创建:create [unique]index 索引名 on 表名(字段名)
查看:show index from 表名
删除:drop index 索引名 on 表名
默认会创建:
主键约束 主键索引 性能最高
唯一约束 唯一索引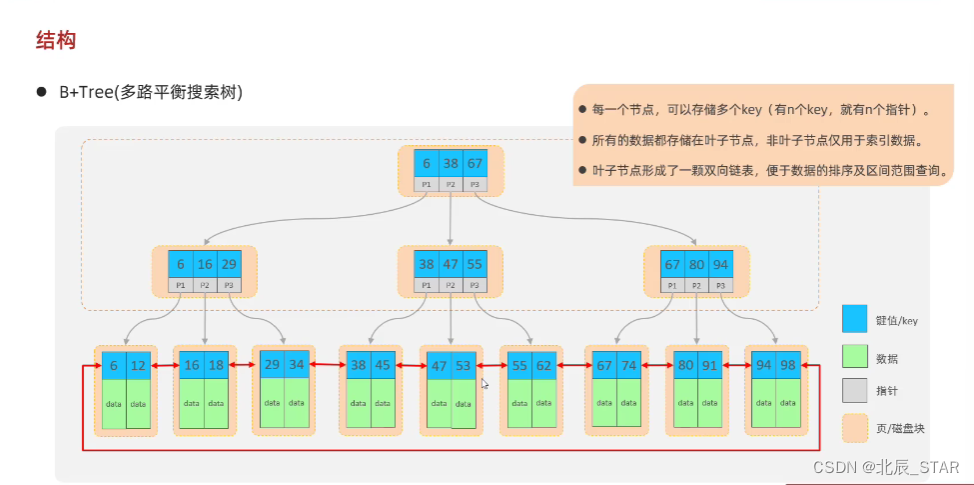
















 8926
8926











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









