






RDD其他算子
小文件处理算子
wholeTextFiles:该算子用于读取一个目录下的多个小文件,
并将每个文件的内容作为一个键值对的RDD返回,
其中键是文件的路径,值是文件的内容
# 合并小文件
file_path = "/path/to/files"
files_rdd = sc.wholeTextFiles(file_path)
result = files_rdd.collect()
for file in result:
print(file)其他聚合类算子
1.aggregateByKey:根据键对RDD中的值进行聚合操作,并返回一个新的键值对的RDD
data = [("Alice", 1), ("Bob", 2), ("Alice", 3), ("Charlie", 4), ("Bob", 5)]
aggregated_data = sc.parallelize(data).aggregateByKey(0, lambda x, y: x + y,
lambda x, y: x + y).collect()
print(aggregated_data)
输出结果:[('Alice', 4), ('Bob', 7), ('Charlie', 4)]2.foldByKey:根据键对RDD中的值进行折叠操作,并返回一个新的键值对的RDD。
data = [("Alice", 1), ("Bob", 2), ("Alice", 3), ("Charlie", 4), ("Bob", 5)]
folded_data = sc.parallelize(data).foldByKey(0, lambda x, y: x + y).collect()
print(folded_data)
输出结果:[('Alice', 4), ('Bob', 7), ('Charlie', 4)]#### 区别
reduceByKey:不支持初始值,分区内聚合逻辑与分区间聚合逻辑一致
foldByKey:支持初始值,分区内聚合逻辑与分区间聚合逻辑一致
aggregateByKey:支持初始值,分区内聚合逻辑与分区间聚合逻辑可以不一致
前提:都是针对KV类型的RDD才能操作。Join类算子
join / fullOuterJoin / leftOuterJoin / rightOuterJoin
实现两个KV类型的RDD之间按照K实现关联,将两个RDD的关联结果放入一个新的RDD中keys算子
keys算子是用于从键值对的RDD中提取出所有的键,返回一个新的RDDvalues算子
values算子是用于从键值对的RDD中提取出所有的值,返回一个新的RDDmapValues算子
mapValues算子是用于对键值对的RDD中的值进行映射操作,返回一个新的键值对的RDD
data = [("Alice", 25), ("Bob", 30), ("Charlie", 35)]
rdd = sc.parallelize(data)
mapped_rdd = rdd.mapValues(lambda x: x + 5)
print(mapped_rdd.collect())
[('Alice', 30), ('Bob', 35), ('Charlie', 40)]分区处理算子
map和foreach是针对每个元素做操作,每个元素调用一次
mapPartitions和foreachPartition是针对每个分区做操作,每个分区调用一次综合案例
RDD算子使用案例
数据:tianchi_user.csv
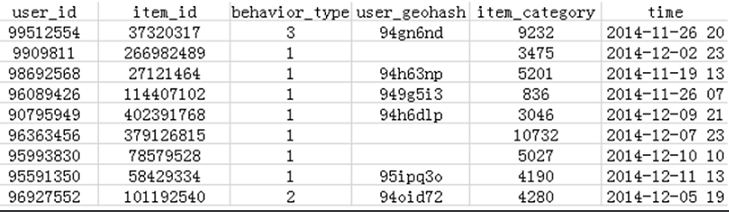
#需求1
统计每天的PV,并按照日期升序排序
(天,数量)
#需求2
统计每天的UV,并按照UV个数降序排序
from pyspark import SparkContext, SparkConf
import os
# 1.构建SparkContext
conf = SparkConf().setMaster("local[2]").setAppName("AppName")
sc = SparkContext(conf=conf)
# 2.数据输入
input_rdd = sc.textFile('../data/tianchi_user.csv')
# 3.数据处理
#3.1 把数据中的time字段转换为日期(天)的格式
def map_line(line):
#'3607854,95585882,1,,6513,2014-11-28 06'
lines = line.split(",")
#line[5]:取时间
#[0:10],0:起始下标,10,长度。把2014-11-28 06的年-月-日截取出来
return (lines[0],lines[1],lines[2],lines[3],lines[4],lines[5][0:10])
filter_rdd = input_rdd.filter(lambda line:len(line.split(",")) == 6).map(lambda line:map_line(line))
#3.2统计PV
result_rdd1 = (filter_rdd
#获取时间(天)
.map(lambda line:line[5])
#把时间转换为(时间,1)
.map(lambda x:(x,1))
#分组聚合
.reduceByKey(lambda x,y:x + y)
#降低分区
.coalesce(1)
#对时间按照天排序
.sortByKey(ascending=True))
#3.3统计UV
result_rdd2 = (filter_rdd
#获取数据中的日期和user_id
.map(lambda line:(line[5],line[0]))
#去日期和user_id进行去重,保证每一天每个用户只有一条数据
.distinct()
#把数据【time,user_id】转换为(time)
.map(lambda x:x[0])
#把(time)转换为(time,1)
.map(lambda x:(x,1))
#对相同日期的数据进行聚合统计
.reduceByKey(lambda x,y:x + y)
#降低分区
.coalesce(1)
#排序、指定按照UV个数降序排序
.sortBy(lambda x:x[1],ascending=False))
# 4.数据输出
#collect()算子会把数据全部收集到Driver内存中,数据量过大容易造成内存溢出,不推荐使用
#input_rdd.collect()
print(input_rdd.take(2))
print(filter_rdd.take(2))
print(result_rdd1.count())
print(result_rdd1.collect())
print(result_rdd2.count())
print(result_rdd2.collect())
# 5.关闭SparkContext
sc.stop()
日志分析案例
数据文件:Sogou.tsv
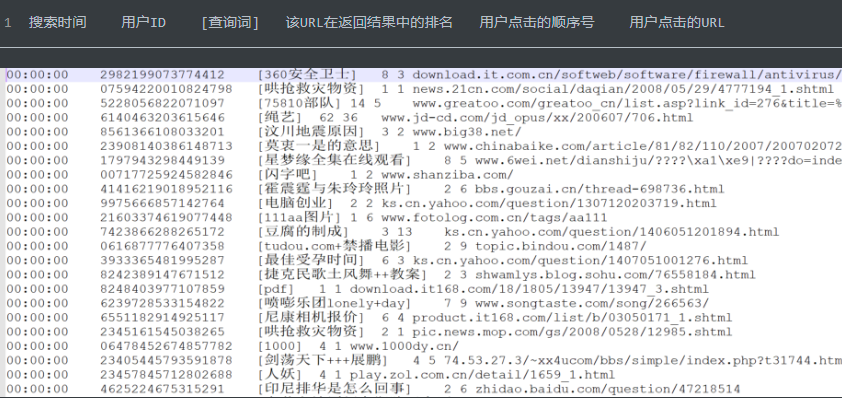
需求1:统计热门搜索词Top10【出现次数最多前10个搜索词】
需求2:统计所有用户所有搜索中最大搜索次数、最小搜索次数、平均搜索次数
需求3:统计一天每小时搜索量并按照搜索量降序排序【统计每个小时数据量,按照数据量降序排序】# 需求一
#1.分析
预期结果:(搜索词,出现次数)
#2.实现思路
step1:读取数据,数据清洗:过滤不合法数据【filter】,将每一行字符串转换成元组【6个元素】【map】
step2:将所有搜索内容【查询内容】通过分词器将所有搜索词提取出来【每个搜索词作为一个独立元素:flatMap】
step3:对每个词构建标记,标记出现一次【map】
step4:按照搜索词进行分组聚合【reduceByKey】,排序取最高的前10【sortBy + take】
#3.SQL实现
select
word,
count(1) as cnt
from table
group by word
order by cnt desc
limit 10# 需求二
#1.分析
语义:一个用户搜索某个词,最多搜索了多少次,最少搜索了多少,平均搜索了多少次
预期结果:最大搜索次数、最小搜索次数、平均搜索次数
#2.实现思路
step1:读取数据,数据清洗:过滤不合法数据【filter】,将每一行字符串转换成元组【6个元素】【map】
step2:将每条数据构建每个KV结构:K【(userid, word)】 V:1
step3:按照K进行分组聚合,得到每个用户搜索每个词的总次数
step4:获取所有搜索次数,取最大、最小、平均
#3.SQL实现
with tmp as (
select
userid,
word,
count(1) as cnt
from table
group by userid, word
)
select max(cnt), min(cnt), avg(cnt) from tmp# 需求三
#1.分析
预期结果:小时 搜索量(最多24行)
#2.实现思路
step1:读取数据,数据清洗:过滤不合法数据【filter】,将每一行字符串转换成元组【6个元素】【map】
step2:将每一条数据构建一个KV : K【hour】, V:1
step3:按照小时分组聚合【reduceByKey】
step4:降序显示【top】
#3.SQL实现
select
substr(time, 1, 2) as hour,
count(1) as cnt
from table
group by substr(time, 1, 2)
order by cnt descJieba中文分词器
全模式:将句子中所有可以组成词的词语都扫描出来, 速度非常快,但可能会出现歧
jieba.cut("语句", cut_all=True)
精确模式:将句子最精确地按照语义切开,适合文本分析,提取语义中存在的每个词
jieba.cut("语句", cut_all=False)
搜索引擎模式:在精确模式的基础上,对长词再次切分,适合用于搜索引擎分词
jieba.cut_for_search("语句")import jieba as jieba
from pyspark import SparkContext, SparkConf
import os
import jieba
# 1.构建SparkContext
conf = SparkConf().setMaster("local[2]").setAppName("AppName")
sc = SparkContext(conf=conf)
# 2.数据输入
line = '我来到北京清华大学'
# TODO:全模式分词
seg_list = jieba.cut(line, cut_all=True)
print(",".join(seg_list))
# TODO: 精确模式
seg_list_2 = jieba.cut(line, cut_all=False)
print(",".join(seg_list_2))
# TODO: 搜索引擎模式
seg_list_3 = jieba.cut_for_search(line)
print(",".join(seg_list_3))
# 5.关闭SparkContext
sc.stop()
Prefix dict has been built successfully.
我,来到,北京,清华,清华大学,华大,大学
我,来到,北京,清华大学
我,来到,北京,清华,华大,大学,清华大学数据加载清洗

清洗数据
# 对数据进行过滤
filter_rdd = (input_rdd
# 对数据进行切割
.map(lambda line : re.split("\s+",line))
# 对切割后的数据进行过滤,过滤掉长度不为6的
.filter(lambda line : len(line) == 6)
# 对搜索词进行切割
.map(lambda line : (line[0],line[1],line[2][1:-1],line[3],line[4],line[5])))
# 数据输出
print(filter_rdd.take(3))搜索关键词TopN统计
# 统计热门搜索词Top10
result_rdd1 = (filter_rdd
#对输入的搜索词进行分词,使用flatMap扁平化
.flatMap(lambda line: jieba.cut(line[2],cut_all=False))
#把分词后的单词,转换为(单词,1)的形式
.map(lambda word : (word,1))
#对单词进行聚合
.reduceByKey(lambda x,y: x + y)
#降低分区,方便全局排序
.coalesce(1)
#倒序排序
.sortBy(lambda x:x[1],ascending=False)
.take(10))
# 数据输出
print(result_rdd1)用户搜索点击统计
# 计算所有用户搜索过程中点击最大次数,最小次数,平均次数
result_rdd2 = ( filter_rdd
# 每个用户查询每个查询词做上标记,表示这个用户查询这个词,点击了1次((用户id, 查询词), 1)
.map(lambda tuple: ((tuple[1], tuple[2]), 1))
# 统计每个用户对每个查询词的点击次数
.reduceByKey(lambda tmp,item: tmp+item)
# 获取每个用户每个查询的次数
.values()
)
print(result_rdd2.max())
print(result_rdd2.min())
print(result_rdd2.mean())搜索时间段TopN统计
# 统计每个小时的搜索量,并按照搜索量降序排序
result_rdd3 = (filter_rdd
#切割时间,保留小时,并且转换为(小时,1)的格式
.map(lambda line:(line[0][0:2],1))
#对小时内的数据进行聚合
.reduceByKey(lambda x,y:x+y)
#把分区设置为1,方便全局排序
.coalesce(1)
#根据次数排序,倒序
.sortBy(lambda x:x[1],ascending=False))
)
print(result_rdd3.collect())Spark的容错机制
Spark就是通过RDD之间的依赖关系来进行容错的,即Spark通过RDD的血缘进行容错。
persist缓存机制
问题:RDD依赖血缘机制保证数据安全,那每调用一次RDD都要重新构建一次,调用多次时性能就特别差,怎么办?
解决:将RDD进行缓存, 如果需要用到多次,将这个RDD存储起来,下次用到直接读取我们存储的RDD,不用再重新构建了
cache: 将RDD缓存在内存中
persist: 将RDD【包含这个RDD的依赖关系】进行缓存,可以自己指定缓存的级别
unpersist: 将缓存的RDD进行释放
cache和persist的区别:
cache:缓存在内存,底层调用的是persist算子
persist:数据可以缓存在内存或者磁盘,可以自己自定义缓存级别。
缓存级别:内存MEMORY、磁盘DISK、内存&磁盘MEMORY_AND_DISKcheckpoint检查点机制
将RDD的数据【不包含RDD依赖关系】存储在HDFS上
# 设置一个检查点目录
sc.setCheckpointDir("../data/chk/")
# 将RDD的数据持久化存储在HDFS
rs_rdd.checkpoint()persist和checkpoint有什么区别
#1.存储位置不同
Persist:利用Executor的内存和节点磁盘来存储
Checkpoint:利用HDFS存储
#2.生命周期不同
Persist:如果程序结束或者遇到了unpersist,内存和磁盘中的缓存会被清理
Checkpoint:只要不手动删除HDFS,就一直存在
#3.存储内容不同
Persist:缓存整个RDD,保留RDD的依赖关系
Checkpoint:存储是RDD的数据,不保留RDD的依赖关系总结
Spark的容错是依据RDD来容错的
RDD的完整的容错机制:
RDD的某个分区的数据如果丢失,
则先去内存找回数据,如果内存没有,则去磁盘寻找,
如果磁盘没有则去HDFS找,如果HDFS也没有,则从头计算出这部分数据。














 832
832











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









